back to index
[DLHLP 2020] Speech Recognition (2/7) - Listen, Attend, Spell
link |
接下來我們就介紹我們今天要講的第一個拿來做語音辨識的模型,它叫做Listen, Attend, Spell, 縮寫是LAS。
link |
所謂的Listen指的就是Encoded, Attend我就不用解釋,就是Attention,然後Spell就是Encoded,就是你知道的那個Sequence to Sequence Model。
link |
大家可能會說,那你怎麼不直接叫它Sequence to Sequence Model就好了,你為什麼要叫它LAS呢?為什麼要把它縮寫成為LAS呢?
link |
首先,以第一篇比較成功的使用Sequence to Sequence Model在語音辨識上的Paper,它的Title就是Listen, Attend, Spell,那個時候就是流行說這個Paper要用三個動詞當作Title,
link |
就是某一陣子的流行,現在這樣子做會有點老派,以前有一陣子就是流行這麼做,把三個動詞當作你Paper的Title,所以它的縮寫就是LAS。
link |
那之所以不直接叫它Sequence to Sequence Model,是因為下面這些其他的模型,它也都是Input a Sequence, Output a Sequence。
link |
如果Sequence to Sequence Model顧名思義是Input a Sequence, Output a Sequence,那這些其他四個模型也都是Input a Sequence, Output a Sequence,它們其實也都是Sequence to Sequence Model。
link |
所以在語音領域跟別人講說,我用了一個Sequence to Sequence Model,別人會不知道你是用這邊的模型的哪一個,因為它們都是Sequence to Sequence Model。
link |
所以你要別人聽得懂,你通常會講說,我用的是LAS,你用的是那個不在語音領域常用的那個Sequence to Sequence,那其實還有很多其他的Sequence to Sequence Model。
link |
那我們來看一下LAS的Encoder, Attend跟Decoder分別是什麼?
link |
Listener的部分就是一個Encoder,Encoder做的事情是什麼呢?Encoder做的事情是,Input一串Acoustic Feature,Acoustic Feature就是一串像這樣,
link |
它也會輸出另外一串像這樣,那輸入和輸出的長度是一樣的,你輸入X1到X4,它們是Acoustic Feature,比如說NMCC,比如說Filter Bank的Output,它輸出H1到H4,是另外一團像這樣。
link |
那我們期待說從Input的X1到X4到輸出的H1到H4,這個Encoder可以把語音裡面的雜訊去掉,只抽出跟語音電視比較有相關的資訊。
link |
你期待說你的Encoder可以把語者和語者間的差異抹掉,可以把雜訊去掉,只抽出跟語音內容本身比較相關的資訊,這是Encoder的目標。
link |
那怎麼做一個Encoder呢?有很多的做法,比如說你可以用RNN,RNN不只是單向的,它可以是雙向的,這是一個做法。
link |
你可以用CNN,比如說CNN怎麼做呢?CNN你會採用1D的Convolution,1D的Convolution怎麼做的呢?
link |
就把一個Filter沿著時間的方向掃過這些Acoustic Feature,每一個Filter會吃一把Acoustic Feature進去,每一個Feature會吃一個範圍之內的Acoustic Feature進去,得到一個value。
link |
比如說這個紅色的三角形代表一個Filter,這個Filter吃這些Acoustic Feature進去,它會吃連續三個Acoustic Feature進去,得到一個數值。這個Filter往右移一點,吃三個Acoustic Feature進去,得到一個數值,再往右移一點,吃三個Acoustic Feature進去,再得到一個數值。
link |
Filter不只一個,這個紅色的Filter給你一排數值,你會有別的Filter,黃色的Filter給你另外一排數值,所以現在每一個輸入的Acoustic Feature都會被轉成一排向量。
link |
但是產生這個向量的過程中,我們不只看了輸入中間的Acoustic Feature,我們會考慮它的連續。當我們在產生B6這個向量的時候,我們不是只看了X2這個Acoustic Feature,我們考慮了X1跟X3的秩序以後,才產生B2這個向量。
link |
當然這個Filter可以層層疊疊地不斷地疊上去,你可以在Filter上面再疊Filter,你可以疊另外一層Filter,這個Filter是看B1、B2、B3當作輸入,得到它的輸出。
link |
因為它看的是B1、B2、B3,而產生B1的時候看的是X1、X2,產生B2的時候看的是X1、X2、X3,產生B3的時候看的是X2、X3、X4,所以當你用這個Filter來看B1、B2、B3的時候,你等於已經看了X1到X4完整的聲音訊號。
link |
那CNN跟RNN哪一個比較好呢?其實在文獻上你常見的一個使用方式是把CNN跟RNN綜合使用,也就是前幾層用一些CNN,後面幾層再用RNN,其實就是用LSTM。
link |
今年還有一個趨勢是用Self-Attention Layer,我們這邊不會細講它是什麼,如果你不知道什麼是Self-Attention Layer的話,可以參見之前機器學習那一門課上課的錄影。
link |
那Self-Attention Layer它可以做到的事情跟LSTM很像、跟RNN很像,就是輸入一串向量,輸出一台向量。那每一個向量在輸出的時候,都是考慮了整段輸入的資訊才產生這邊每一個輸出。
link |
有關Self-Attention的細節,我們今天就不細講,請參見之前那一門課的上課錄影。那在做語音辨識,有一件很重要的事情是,我們通常會對輸入做Downsampling。
link |
為什麼要對輸入做Downsampling呢?因為一段聲音訊號,如果你把它表示成Acoustic Feature,它往往太長了。我們剛才說一秒鐘的聲音訊號就有100個向量,它太長了。而且相鄰的向量之間,其實它們帶有的資訊量的差異不會說差異非常大。
link |
所以今天在做語音辨識的時候,為了要節省你的計算量,讓你的訓練更有效率,有一招叫做Downsampling。那Downsampling有很多種不同的實踐方法。
link |
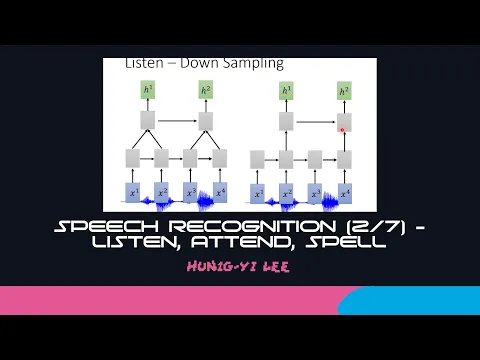
舉例來說,最早的,也就是LANS裡面原始的論文,它是發表在2016年的ITAS。那在那Paper裡面,就有一招叫做Pyramid RN。Pyramid RN是說,本來輸入是四個向量,那RN照理說就會輸出四個向量。
link |
但是在第二層的RN,我們把這些向量兩個兩個一起,把它作為一個乘縫,變成一個向量。我們把兩個向量變成一個向量,就叫做三層的RN。
link |
所以在第二層的RN來說,輸入不再是四個向量。第一層RN的輸入是四個向量,第二層RN的輸入就變成兩個向量。所以輸出就會比較短,這樣就可以節省你的運算量。
link |
雖然說輸出比輸入短,但是輸入跟輸出中間還是會成為一個倍數的關係。
link |
那像這樣子當三層的技術,其實對於實踐這個原變式的系統是不可或缺的。
link |
印象非常深刻的就是,Google在發表LAS paper的時候,那個作者有說,一開始不知道要用Pyramid RN這一招,就用正常的RN,勸了好幾個月,都勸不起來啊。
link |
我第一次聽到Google的人說,它有勸不起來的東西啊,就好像說天山同老,要砍兩刀人才會死啊,就好像奇遇要揍兩拳人才會死啊,這樣子讓人驚奇。
link |
一開始不知道Pyramid RN的時候,勸不起來啊,然後就要用Pyramid RN了,就做得起來,顯示非常重要的技術。
link |
那在同一年的ITX的同一個session裡面,也有另外一篇用LAS這樣的架構的文章,不過它就不叫LAS了,
link |
不過它們是非常非常類似的sequence-to-sequence model,它裡面用了另外一種類型的downsampling,叫做pooling over time。
link |
你看這個圖,一看就可以理解了,左邊跟右邊其實非常的像,只是說左邊是把兩個timestamp的東西加起來,結合起來丟到下一個layer。
link |
這邊是從兩個timestamp裡面只選一個送到下一層,從兩個timestamp裡面只選一個送到下一層。
link |
剛才講的是減少RN的運算量,其他比如說CNN或self-attention,也會想辦法減少運算量。
link |
以CNN為例,在語音這邊,CNN常用的一個變形叫做time-delay的CNN,縮寫的是PDNN。
link |
所以它的名字叫time-delay的PDNN,其實它就是1D的CNN,你說為什麼不叫1D的CNN?當初誰先用這個方法,然後他想要取消time-delay的PDNN就是time-delay的PDNN。
link |
它跟CNN其實是非常類似的事情,它一樣就是我們現在有一個filter,這個filter是一個範圍之內的聲音訊號,然後產生一個output。
link |
只是一般你在做CNN的時候,這個範圍裡面所有的資訊你都會考慮,但PDNN說,為什麼要考慮所有範圍裡面的資訊呢?這邊每一個項量其實感覺長得都差不多啊,所以我們就考慮第一個跟最後一個就好,這樣大幅節省運算量跟參數量。
link |
有人看到這邊說,這個不就是dilatedCNN嗎?對哦,這個就是名字不同而已嘛,不要太計較這些,這是不同的名字,不同人講類似模型的時候,他會使用不同的名字。
link |
在self-attention的地方,有一個東西叫做truncated self-attention,就我們一般在做self-attention的時候,我們每一個時間點,每一個feature都會去attach整個input sequence裡面所有的feature。
link |
所以你要把x3變成h3,你要考慮這整個input sequence裡面所有的資訊,你會對這整個input sequence都做attention。但問題是在語音上面,這招在translation上面沒什麼問題,因為在做翻譯的時候輸入可能就十來個詞彙而已。
link |
在語音不是,語音輸入的這個向量非常非常長,一秒鐘就一百個向量,太長了,你沒有辦法做什麼self-attention,太長了。所以怎麼辦?
link |
一個簡單的方法就是,今天在attention的時候,只准attention在一個範圍之內,那超過這個範圍就不看,節省運算量。
link |
比較常見的setup可能是說,我現在在考慮的這個acoustic feature在attention的時候,是attention未來四個acoustic feature跟之前比如說三十個acoustic feature,只看未來多少,過去多少,這個是你要調的一個參數。
link |
就像network架構一樣是一個需要調的參數,但是如果只看整個聲音訊號,整句聲音訊號在運算上,可能是會讓你成效的。
link |
這個attention是怎麼做的呢?這個attention跟你用在其他應用上的sequence-to-sequence的model其實並沒有什麼不同。
link |
在LAS裡面,這個attention是怎麼做的呢?首先你要有一個vector叫做z0,然後你要用這個z0跟encoder的輸出去計算attention。
link |
這個計算attention的感覺就像是搜尋一樣,就像你透過google搜尋整個web,你透過關鍵字查詢資料庫一樣。
link |
這個z0就是關鍵字,這個encoder的output就是資料庫的內容。
link |
然後在做attention的時候,會有一個function,這個function叫做match,這個match這個function它會吃z0這個vector當作input,
link |
它會吃來自encoder的一個vector當作input,它吃這兩個vector當作input,然後會輸出一個scalar,會輸出一個數值。
link |
這邊我們用alpha來表示。那match這個operation,match這個function是怎麼運作的呢?
link |
你其實可以自己define,反正只要能夠input兩個vector,output一個scalar就可以了。
link |
那在文獻上有哪些常用的match這個functiondefine的方式呢?
link |
一個常用的方式叫做大product的attention,大product的attention它做的事情是這樣,h跟z是match這個function的輸入,
link |
那h跟z它們都分別乘上一個matric,乘上一個linear的transform,你把h乘上一個transform得到一個新的vector,
link |
把z乘上一個transform得到一個新的vector,然後把這兩個vector做大product,這個叫做大product的attention,
link |
所以我們把這兩個vector做大product得到一個scalar叫做alpha。
link |
所以你可以很明顯的看到說,這個match的function在大product的attention裡面,
link |
它很明顯做的事情就是計算z0跟h的相似度,它把h跟z0做一個transform以後計算它們的相似度得到alpha,
link |
這個alpha可以說是h跟z的相似度。
link |
那這個z0會跟encoder每一個kind step的output都計算attention,
link |
這邊還有第二個attention的方式叫做additive的attention,
link |
那這個additive的attention做的事情是什麼呢?這個additive的attention它的運作是這樣,
link |
把h跟z當作輸入,然後分別又多做一個transform,
link |
但是現在不是在做大product,而是把這兩個vector把它們加起來,
link |
把它們加起來以後,再通過一個hyperbolic tangent的activation function,
link |
然後得到一個vector,這個hyperbolic tangent的activation function這邊輸出會是一個vector,
link |
把這個vector乘上一個linear transform,然後會得到一個scatter。
link |
所以這個additive的attention它輸入是兩個vector,它輸出會是一個scatter,
link |
這是另外一種常用的attention的方式。
link |
我們剛才有講說這個z0就會跟encoder每一個kind step的output計算attention,
link |
所以z0會跟h1得到一個alpha,也會跟h2得到一個alpha,也跟h3得到一個alpha,也會跟h4得到一個alpha。
link |
所以encoder的每一個kind step的output,
link |
encoder會input一串acoustic feature,然後每一個acoustic feature都有一個對應的encoder的output,
link |
每一個output現在都會得到一個alpha。
link |
接下來你會做softmax,讓這些alpha它們的總和為1。
link |
接下來你會把這邊normalize以後,通過softmax以後的alpha,
link |
去乘上這些encoder的output h做weighted sum,然後得到一個vector叫做c0。
link |
所以你會把這邊的每一個h,這邊用hi來表示,乘上這邊每一個h所對應的alpha,這邊用alpha i來表示。
link |
你把hi乘上alpha i,然後做softmax,接下來就得到c0。
link |
這邊是舉一個具體的例子,假設alpha1是0.5,alpha2是0.5,alpha3,alpha4都是0,
link |
那你得到c0是多少呢?你這邊輸出的這個vector c0是多少呢?
link |
你就是把0.5乘上h1加0.5乘上h2,然後就結束了。
link |
接下來,c0會被當作decoder的input,
link |
decoder會是一個recurrent network,然後這個c0會是decoder的input。
link |
這邊這個c,在文線上常常被稱之為context vector。
link |
接下來,有了這個c0以後,我們就進入LAS的第三個步驟。
link |
LAS不知道大家還記不記得它是什麼的縮寫,它是Listen, Attend, Spell。
link |
Listen就是decode, Attend就是我們剛才講的,Spell就是開始decode,Spell就是拼字的意思。
link |
所以它開始根據它聽到的東西,開始寫出它聽到的文字。
link |
這個c0就是decoder的輸入,其實c0有不一樣的用法,當作decoder的輸入只是比較常見的一個用法而已。
link |
c0當作decoder的輸入,然後就輸出一個distribution。
link |
c0當作decoder的輸入,decoder是一個RNN,然後Z1是它的hidden state的output,
link |
然後根據hidden state的output再乘上一個transform,會得到一個distribution。
link |
這個distribution是給每一個token,就是說我們在做speech recognition的時候,
link |
你要決定說你的ASR系統,你的語音辨識系統,它輸出的token是什麼樣的單位。
link |
我們上次有說你有很多選擇,你可以選graphic,你可以選morphing,你可以選word,你可以選forming。
link |
這邊的output的token是什麼,就取決於你選擇了什麼樣的單位當作你的token。
link |
這個decoder就會給每一個token一個機率,假設你現在選英文的字母當作你的token的話,
link |
那就是A有一個機率,B有一個機率,C有一個機率,D有一個機率。
link |
代表說現在這個decoder看到這個C0,看到這個來自encoder output的C0,決定它要輸出哪一個字母,決定它要輸出哪一個token。
link |
所以今天這個decoder它的輸出的dimension就會是跟它的vocabulary size,也就是你的token裡面有的token的數目是一樣的。
link |
我們說token的數目我們用大V來表示,所以現在這邊的輸出它是一個大V尾的向量,那這個向量是有通過softmax的,
link |
所以它是一個distribution,這邊所有token的機率的核會是1。
link |
那假設現在輸的這段聲音訊號是cat,那現在你的model如果要正確的做出語音辨識的話,
link |
它就要先輸出C,再輸出A,再輸出D。所以首先看到C0以後,你的model應該就要輸出C。
link |
那這個model到底會輸出什麼呢?這個spell到底會拼出什麼樣的字母呢?
link |
就看這個distribution裡面,簡單來說就看這個distribution裡面哪一個token的機率最大,比如說現在C的機率最大,那它就輸出C。
link |
那這個是輸出第一個字母,那我們做了這麼久只輸出了第一個字母,那接下來要輸出第二個字母。
link |
怎麼輸出第二個字母呢?你把Z1再去做attention,剛才是拿Z0做attention,得到了C0,然後再輸出C。
link |
那現在改拿hidden state現在的value Z1去做attention,那你就算出新的alpha的值,然後再做一次softmax。
link |
再根據做完softmax以後,alpha的值去做weighted sum,對這些h做weighted sum,你又得到C1。
link |
那現在假設呢,這個alpha2是0.3,alpha3是0.6,alpha4是0.1,那你得到C1的值是多少呢?就是0.3倍的h2加0.6倍的h3加0.1倍的h4。
link |
0.3倍的h2加0.6倍的h3加0.1倍的h4,做weighted sum就得到C1,C1就變成你的decoder的輸入。
link |
C1變成decoder的輸入以後,得到hidden state的value h2,然後呢,這個前一個timestamp所decode出來的字母,所decode出來的token會變成下一個timestamp的輸入。
link |
所以我們這邊呢,不只是看C1,也看前一個timestampdecode出來的C,得到Z2。然後再把這個Z2呢,通過transform做softmax以後,得到一個distribution,然後從這個distribution裡面選機率最大的出來,得到A。
link |
然後這個process呢,就反覆的繼續下去,根據這個Z2,再做一次attention,這邊就不把attention的過程畫出來了,根據這個Z2,再做一次attention,會得到C2。
link |
然後呢,C2跟這個A,會得到Z3,然後Z3呢,再產生一個新的distribution,希望呢,它是E,那就拼出CAT這個詞彙了,語音辨識的系統就跑出CAT這個詞彙了。
link |
好,那接下來呢,根據Z3,你會再產生新的attention,然後你會產生新的attention的結果,attention的結果啊,我們叫做context vector,context就是上下文的那個意思,context vector。
link |
好,我們把這個C3呢,再丟到這個decoder裡面,然後呢,現在會有一個特殊的符號叫做end of sentence,代表辨識結束。那如果把C3丟進去,得到end of sentence,就代表辨識結束,那我們的辨識呢,就跑完了,你的decoder就把它所有想要輸出的東西都輸出完了,你就得到語音辨識最終的結果了。
link |
好,那這個是有關build的部分。好,我們現在是在假設說我們的model的參數都已經知道的前提之下啦。好,那其實在decode的時候啊,你會做一件事情叫做bin search,那我們在作業裡面呢,也有叫大家做bin search。
link |
那你知道是什麼也沒有關係,因為程式註解到呢,都已經幫你寫好了,對你來說,你只是下一個參數,然後看看bin search的紫色的不同會有什麼樣的結果。好,那bin search是什麼呢?bin search是這樣,假設啊,我們現在世界上只有兩個token,A跟B這兩個token。
link |
當然實際上我們在做語音辨識的時候,絕對不會只有兩個token,就算你是用英文字母做單位,你也有比26還要多的token,你至少要說的英文字母再加上空白跟標點符號。
link |
那我們現在呢,假設B等於2,也就是只有兩個token,A跟B。好,那現在呢,假設在第一個timestamp,在你的decoder產生第一個token的時候,第一個distribution的時候,A的機率是0.6,B的機率是0.4。
link |
那麼剛才有講過,在做decode的時候,你就選機率最大的那個,這個其實叫做greedy decoding,就選機率最大的那個。
link |
所以在第一個timestamp,看到做第一次attention的時候,我們最後做完第一次attention以後,我們得到的distribution是A是0.6的機率,B是0.4的機率。然後我們發現說A的機率比較大,然後呢,他就往左邊走。
link |
那選擇out輸出A以後,因為輸出的結果會是下一次產生輸出的時候的輸出。我們在第一個timestamp,decode出來的第一個字母如果是A的話,會影響到接下來decode的結果。
link |
如果你還記得剛才那個decoder的樣子的話,你前一個timestamp的輸出會變成下一個timestamp的輸出。所以如果我們選擇了A跟選擇了B這兩條路徑,接下來你會看到的輸出,會看到的結果是不一樣的。
link |
你會看到A跟B的distribution是不一樣的。那如果我們選擇A,那接下來呢,假設我們看到下一個distribution,A的機率是0.4,B的機率是0.6,我們選機率大的那一個,你就會選擇0.6。
link |
而你選擇了A跟B,然後接下來呢,A的機率是0.4,B的機率是0.6,你又選機率大的那一個,那你就輸出ABB。每一次都選機率大的那一個,每次都選distribution裡面機率最大的那個token當作輸出,這個叫做Greedy Decoding。
link |
那事實上你做Greedy Decoding,有時候也會給你不錯的結果,但是你可以做得更好。Greedy Decoding會有什麼樣的問題呢?Greedy Decoding不見得能夠幫你找到機率最大的那一個輸出的結果。
link |
為什麼Greedy Decoding不一定能夠幫我們找到機率最大的那個輸出的結果呢?我們這邊舉個例。假設我們在第一個step選的不是A而是B,B機率比較低,但不知道為什麼我們選了B,B的機率是0.4。
link |
選了B以後,我們看到的第二次看到的第二個distribution其實就不一樣了。選了A以後,它的人生是這樣子發展的,distribution是長這個樣子的。
link |
但選了B以後,distribution是不一樣的。假設選了B以後,我們在接下來看到B的機率會變成0.9。那我們選B,然後再看下一次第三個time step,看到B的機率也是0.9。
link |
我們如果選這一條路徑,第一步先做一個犧牲,選一個機率比較小的token,但接下來我們可以看到機率比較大的token。所以如果你走紅色這一條路,Greedy Decoding,跟綠色這一條路,你會發現綠色這一條路,它的機率其實是比較高的。
link |
這個就像什麼呢?這個就跟念博班是一樣的。我知道現在大家都不怎麼想念博班,為什麼不想念博班呢?因為你覺得簽下去感覺蠻辛苦的。
link |
左邊這一條路就是,你簽下去,你沒簽下去,你短時間內是快樂的,但是也許你畢業以後就沒有那麼快樂了。
link |
但是如果你簽下去,短時間內你覺得是痛苦的,但是未來你會是快樂的。所以整體說來,搞不好簽下去你會得到比較好的結果,雖然短時間內有些犧牲。
link |
但是我們其實在實作上沒有辦法真的搜尋過所有的可能性,找出機率最大的那一個路徑。怎麼辦呢?我們解決這個問題的方法就叫做bin search。
link |
這個bin search是怎麼做的呢?bin search就是每一次我們都保留大於一個最好的路徑。以下的那個例子就是bin size等於2的狀況。
link |
我們一開始有兩個可能的路徑,我們一開始可以選擇A,也可以選擇B。我們說每次我們都保留兩個最好的路徑,現在只有兩個可能,所以就把A跟B都保留下來。
link |
選了A以後,接下來你可以選A也可以選B,選了B以後,接下來你可以選A也可以選B。所以整體說來,現在你總共有四個可能的選擇。
link |
我們在這四個可能的選擇裡面只會保留機率分數算出來最高的那兩個可能。所以現在假設A、B跟B、B是這四個可能的路徑裡面,A、A、A、B、B、A跟B、B四個可能的路徑裡面分數最高的兩個選擇,你就把A、B跟B、B保留下來,然後繼續走下去。
link |
A、B後面有兩個選擇,B、B後面也有兩個選擇。所以現在總共還是有四個選擇,你就把四個選擇裡面分數最高的那兩個路徑再把它保留下來,繼續走下去。
link |
這個就是bin search,保留幾個路徑就是bin的size,就是bin的大小。所以在作業裡面會叫大家調bin的大小,你就設五十、十五、二十。這個就是你在搜尋的時候,每一次產生一個distribution的時候保留了多少的路徑。
link |
但保留的路徑多,你可能會找出來的結果,你比較有可能找出分數比較大的decode的結果,你比較能夠找出分數比較大的路徑。但保留的路徑多,你的計算量就會比較大。所以bin size的大小到底要設多少,這個是你自己要去考量的,你自己要去嘗試的。
link |
接下來就講訓練的部分。在訓練的時候,我們需要告訴機器說,現在給這一段聲音,我們要輸出什麼樣的文字,你要把訓練資料先給好。現在輸出一段聲音,它輸出就是要輸出CAT這三個字母。
link |
我們如果已經知道要輸出CAT這三個字母,我們就知道說,在第一個time step,在產生第一個distribution的時候,我們希望產生出C的機率越大越好。
link |
或者換句話說,實際上你做的事情是,你會把C表示成一個one-hot vector,所謂one-hot vector的意思是說,你有一個向量,這個向量的長度就跟你的token的數量是一樣的,但是在這個向量裡面只有一個維度是1,其他維度都是0,只有對應到C的那個維度是1,其他都是0。
link |
接下來,你會去計算你現在輸出的這個distribution跟這個C之間的cross entropy,你會想要minimize它們的cross entropy。
link |
如果你已經忘記cross entropy是什麼的話,那就記得說,我們會讓現在輸出的distribution跟one-hot vector越接近越好。
link |
或者是假設你不知道one-hot vector是什麼的話,再換句話說,我們這邊實際上做的事情就是,我們知道正確答案的第一個字母是C,那我們就告訴machine說,現在訓練的目標是什麼呢?
link |
現在訓練的目標是,假設第一個字母是C,那C在第一個distribution裡面它的機率應該要越大越好。訓練的目標就是讓C的機率越大越好。接下來就重複一樣的步驟。
link |
我們知道說,現在這個聲音訊號已經有人去標註,告訴你說,第二個字母是A,這段聲音訊號是Cat,所以第二個字母是A。所以,你就要讓現在第二個distribution產生A的機率越大越好。
link |
或者是,換句話說,你把A表示成一個one-hot vector,你希望你現在輸出的這個distribution跟A這個one-hot vector的cross entropy越小越好。但如果你不知道cross entropy是什麼,你只要記得說,讓第二個distribution輸出A這個字母的機率越大越好。這個就是我們訓練的目標。
link |
但是在訓練的時候,我們會做一件事情跟我們剛才講的,在使用、在做語音辨識,也就是在做decode的時候,在使用這個模型的時候不一樣的地方。
link |
什麼樣不一樣的地方呢?我們剛才講說,在輸出第二個distribution的時候,我們其實會參考第一個distribution輸出的結果。我們會先產生第一個distribution,然後選機率最大的那個字母出來,然後變成第二個timestamp的輸入,再產生第二個distribution。
link |
但是在訓練的時候,你通常不會這麼做。訓練的時候,你通常會怎麼做呢?在訓練的時候,你會告訴機器,在看到A之前的正確答案是什麼。
link |
而在訓練的時候,第一個timestamp輸出的結果是什麼,不重要。是錯的、是對的,都不重要。我們就看說,現在在正確答案裡面,在輸出A之前,已經有什麼樣的字母。如果是C,那我們就直接給我們的decoder看這個C的字母,告訴它說,現在看到C這個字母,你接下來應該要產生A。
link |
那把正確答案放在訓練的process裡面,這件事叫做teacher forcing。當然,這個都是在助教程式裡面,都已經幫大家implement好了。
link |
為什麼teacher forcing是重要的一個步驟呢?它是這個樣子的。如果我們今天拿前一個timestamp的輸出當作下一個timestamp的輸入,會發生什麼事呢?
link |
在訓練的時候,假設我們會看前一個timestamp的輸出,那會發生什麼事情呢?因為今天在訓練的過程中,你的model一開始,它的參數是從隨機開始訓練的。所以一開始訓練的時候,你的decoder非常爛,它輸出的東西都是亂七八糟的東西。
link |
所以第一個timestamp本來應該輸出一個C,但它現在還不知道要輸出一個C,所以它現在就輸出一個X,然後這個X就變成第二個timestamp的輸入。
link |
所以現在你的RNN就會學到說,我看到X,接下來應該要輸出A。雖然實際上應該是看到C,接下來要輸出A,但一開始model還不知道要輸出C,所以它學到是看到X,要輸出A。
link |
經過一連串的訓練以後,現在model變厲害了,它知道說第一個timestamp的正確答案是C,所以它就會輸出正確答案C,然後跟後面的RNN說,現在看到輸入C,你應該輸出A。
link |
後面的RNN就會崩潰了,它就會發現說之前的訓練都白費了,之前學到的都是看到X要輸出A,但是現在突然改成看到輸出C,要輸出A。它就會說,如果你要輸出C,你要先講,好嗎?
link |
前面這個timestamp就會覺得很委屈,它就會說,我也要先去睡了。但是它其實不會這麼說,它會說,那我就先講。
link |
怎麼先講呢?先講的方法就是,不要管自己真正的輸出,自己的輸出可能是錯的,把正確答案拿進來,就是先講。
link |
所以這樣就是等於告訴第二個timestamp說,反正不管前面的timestamp輸出什麼,它有可能是錯的,不要理它,我們看正確答案是什麼?正確答案是C。
link |
你就專注在學,看到C產生A這件事就好。這招叫做teacher forcing,在訓練這種有encoder、decoder架構的sequence-to-sequence的model的時候,這個是關鍵的一步,當然助教程式裡面都已經幫大家寫好了。
link |
主持人問道:"如果答案太多的時候,我bin size太大一點,然後distribute太多的時候,我bin size太小一點。有沒有人這樣做?"
link |
有,有人這樣做。我們剛才講的那個bin size指的是bin的大小,但是你也可以用別的criterion來當作選擇。舉例來說,你會說第一名的分數是多少,比第一名的分數低90%以下的就把它濾掉。你完全可以這麼做,我們繼續看下去。
link |
我們剛才講說,我們的attention是怎麼被放到decoder裡面去的呢?是這樣子放的。我們把decoder的hidden state拿出來,然後做一下attention,然後產生出來的這個vector,根據attention產生出來的context vector,它是下一個type step的輸入。
link |
這個是我們剛才在介紹LAS的時候我們跟你講的decoder。但是其實還有另外一種做attention的方式,還有另外一種使用attention結果的方式。這種結果是怎麼做的呢?
link |
你先把Z拿出來做attention,得到context vector C。這context vector不是保留到下一個type step才使用,它是這個type step立刻就使用。你就把C跟Z合起來,丟到你的RNN裡面,然後產生distribution。
link |
然後在下一個type step,你會產生ZT加1,然後ZT加1會再給你CT加1,然後立刻會影響這個type step的結果。所以左邊跟右邊的差異是,你attention得到的結果是下一個type step使用,還是這個type step立刻使用。
link |
到底哪一個東西比較好呢?這個不好說,但我可以告訴你,第一篇用sequence-to-sequence做語音辨識的論文,它是用哪一種attention呢?它就是我全都要,就是兩種都用。
link |
它是這樣做的,我們有一個Z以後,我們會做attention,然後得到context vector。這context vector一方面影響了現在的輸出,另外一方面又影響了下一個type step的輸出。
link |
所以這個C,這個attention得到的context vector C,它有兩個作用。它這個type step就會被用一次,下一個type step也還會被再用一次。這個是語音辨識比較早的論文,做sequence-to-sequence model比較早的論文,它就是這麼做的,就是兩種attention都用上去。
link |
那把有attention的這種sequence-to-sequence model用在語音辨識上好不好呢?我第一次看到有人這麼用的時候,我覺得這個會不會太過頭了,有點像是殺雞用了牛刀一樣。
link |
為什麼這樣說呢?我們知道這種有attention的sequence-to-sequence model最早是被用在translation上面,最早是被用在翻譯上面。在做翻譯的時候,你的輸入跟輸出沒有一致的對應的關係。
link |
也就是說,你翻譯出來結果的第一個詞彙可能是從輸入的句子的最後一個詞彙產生的,最後一個詞彙可能是第一個詞彙產生的。所以你需要attention這樣子的機制,讓你的decoder從encoder那邊自己去尋找它現在要decode哪一個詞彙出來。
link |
但是對語音來說,這麼做也許太多了,就是殺雞用了牛刀的感覺。對語音來說,你要decode第一個詞彙、第一個字母,那就是看聲音訊號的最前面,接下來再往右移一點,然後產生第二個字母,再往右移一點,產生第三個字母。
link |
所以像attention這個彈性這麼大的東西,好像在語音上其實不太需要。在語音上,我們會期待說我們的attention的weight,就是我們剛才講的那個alpha,它就是由左到右移動。
link |
所以一開始alpha的分佈可能在h1、h2最大,然後接下來可能在h2、h3最大,在h3、h4最大。在語音辨識裡面,我們覺得說attention的weight,那個alpha的變化應該就是這個樣子。
link |
當然實際上,我們在訓練的時候不見得會給這個control,所以那個alpha是可以自由亂跳的。所以我就會覺得說,好像用了太多的東西,好像給了這個model過分強大的能力而不必要的能力。
link |
如果今天這個alpha亂跳,比如說一開始它覺得h3、h4是它想看的,接下來它又覺得h1、h2是它想看的,接下來又覺得說h1到h4都是它想看的,你就會覺得說,這顯然有問題,這樣是不對的,不應該是這個樣子。
link |
在做語音辨識的時候,attention的改變應該就是由左向右改變。如果亂跳,顯然就是怪怪的,好像不應該是這個樣子。
link |
所以第一篇用sequence to sequence加attention,也就是用LAS來做語音辨識的paper,作者也這麼覺得。所以他加了一個機制,這個機制是什麼呢?
link |
他覺得說,在做語音辨識的時候,這個attention不能夠隨便亂跳,你的attention要考慮前一個timestamp得到的attention,你的attention的weight會受到前一個timestamp所得到的attention的weight的影響。
link |
怎麼說呢?假設你現在要用z1和h2去計算它的attention,在一般的attention裡面,在你所熟悉的那一套attention裡面,你就是有一個function,然後輸入h和z,然後輸出alpha。
link |
但是現在不是這樣。在第一篇拿LAS來做語音辨識的paper裡面,他提出來了一種location-aware的attention。location-aware的attention的意思是說,我們會把前一個timestamp所得到的那些alpha也拿出來。
link |
然後我們現在要考慮h2現在的alpha,我們把之前的前一個timestamph2的alpha拿出來,也把它前後相關的alpha,所謂相關的意思就是location很接近的意思,我們就以alpha2為中心,前面取一些alpha,後面取一些alpha。
link |
取一個window的alpha,也就變成一個向量,然後把它丟到一個transform裡面去。然後把這個向量通過transform以後得到一個vector,然後再把這個vector當作這個function的輸入。
link |
所以現在我們的這個match function不是只看z和h,它還會看在前一個timestamp的時候,在附近的位置到底得到了什麼樣的attention的位,然後合起來才得到alpha。
link |
所以今天你的model可能就會學到說,我每次的attention都應該要往右移一點,因為它會考慮過去的attention。
link |
這個是location-aware的attention。LaaS到底work不work呢?當然現在很多人都用LaaS,你的作業也是用LaaS。不過在五、六年前,這個聽起來就是,嗯,這個真的會work嗎?感覺好像不太會work哦。
link |
最早的一篇paper是做在Timmy上面,它其實得到了我覺得還蠻驚人的結果。這個是paper上面接下來的表格,這三個數字是LaaS跑出來的結果,最下面這個16.7%是傳統的,不是用LaaS,但是也有用deep learning的語音辨識跑出來的結果。
link |
所以你會發現說LaaS在那個時候打不贏傳統的方法,但是也頗接近。但是Timmy它並不是真正的語音辨識,它只叫你的語音辨識系統產生封領而已,它不是叫你產生真正人可以讀的文字。
link |
所以在Timmy上可以work的東西,不見得用到真正的語音辨識上可以work。後來就有人試在真正的語音辨識上讓機器產生文字,這是訓練在三百個小時的conference上面。
link |
這邊都是用LaaS跑出來的語音辨識的結果。你會發現說,舉例來說,在Switchboard這個conference上,它的錯誤率是38.8%。38.8%是好還是不好呢?
link |
其實在那篇paper裡面,它並沒有把LaaS跟傳統的方法比較,所以如果你是外行人,你就不知道它好還是不好。但是我可以告訴你說,在一年前同一個conference上,我就已經看到10.4%的error rate了。
link |
所以可見說這個整個就是壞掉了,就是沒有辨識起來了。後來過了一年之後,結果怎麼樣呢?就起飛了。
link |
後來Google在ICAS16年,它們用兩千個小時的data來train LaaS。LaaS最好可以做到10.3%的錯誤率跟12%的錯誤率。
link |
當然,它們自己內部更好的,不是LaaS一般的用傳統的deep learning方法的系統,可以得到8%跟8.9%的錯誤率。所以LaaS跟傳統的系統還是有一段差距,但是16年的時候,大家看到的結果是,哇靠,這樣也做得起來。
link |
後來18年的時候,Google用了一萬兩千五百個小時的data來train LaaS。它們的LaaS可以得到5.6%跟4.1%的錯誤率,這就兩個不同的任務了,得到這麼低的錯誤率。
link |
它們內部最好的,不是用N2N的傳統的用deep learning的語音編輯系統,是6.7%跟5.0%的錯誤率。所以在經過很長一段時間的努力,加上各種train model的trick以後,LaaS是有機會贏過傳統的方法的。
link |
在Google這篇文章裏面,它們還強調了這種N2N model的一個優勢。N2N model的優勢是什麽呢?就是它的model可以縮得很小。傳統的模型,你有acoustic model,你有pn,就是lexicon,你有language model。
link |
這個acoustic model、language model今天當然都是deep learning based的,但是這些model合起來非常大,它們說有7.2GB那麽大。但是如果你是用LaaS,把所有本來這些模型統統都硬塞在一個network裏面,它達到了一種壓縮的效果,所以可以跑出零點。
link |
所以它的模型其實比較小的,大家都以爲deep的network模型比較大,其實不是。N2N model的模型比較小的,它是零點4GB。
link |
我們來看一下LaaS的attention,這個是在google的icast paper裏面的attention。它說LaaS的attention長得什麽樣子呢?看起來通常都蠻合理的。現在給LaaS聽一段聲音訊號,然後它要開始輸出文字,它每次只輸出一個character而已。
link |
所以它現在先輸出一個h,它tend在這個地方輸出一個h,它tend在這個地方輸出一個o,它tend在這個地方輸出一個w,然後就產生how這個詞彙。
link |
接下來它還要產生空白,它會自動產生空白,然後再產生n,再產生u,再產生ch,再產生wo。這個是一個繞口令,但是聽不懂沒關係,這個繞口令,它想要顯示的是說,attention就是由左往右好好的跑出來,跟我們想象語音辨識該有的attention是一樣。
link |
而且有趣的是,它沒有location-aware的attention,machine自己學得到attention應該長什麽樣子。雖然說是殺雞用了牛刀,不過反正雞殺死了用牛刀也沒有什麽關係,machine自己學得到正確的attention應該長什麽樣子。
link |
在這個paper裏面還report了一個有趣的結果,它說,有一句話叫做call AAA roadside assistance,AAA是什麽呢?AAA並不是什麽重力可可的叫聲,AAA是一個道路救援公司的名字。
link |
有人說,我不知道說原始的句子到底是說AAA roadside assistance還是AAA roadside assistance,但是Google說,這個句子,它們語音辨識跑出來的結果,你用bin search找出來的分數最高的兩條路徑,分別一個就是AAA roadside assistance,一個就是AAA roadside assistance,所以很神奇。
link |
AAA跟AAA,它們的聲音當然完全是不太一樣,聲音差很多,但機器知道說,AAA跟AAA就是對應到一樣的聲音訊號,機器自己可以學到這件事情。
link |
所以LAS可以學到很複雜的輸入的聲音訊號跟輸出的文字之間的關係。
link |
您到時候自己在作業裏面可以試試看說,它會跑出什麽樣的attention。其實我也不知道這樣應該要跑出什麽樣的attention,但它學得到就是了。
link |
主持人問,Language Model是否加到語音辨識裏面的?
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。
link |
主持人回答,LAS可以學到很複雜的聲音訊號跟輸出的文字之間的關係。