back to index
[DLHLP 2020] Voice Conversion (2/2) - CycleGAN and StarGAN
link |
上週我們講了feature disentangle的技術,那麼有說在做feature disentangle的時候,你其實就是在訓練一個像是autoencoder一樣的架構,你有content的encoder,你可能有speaker的encoder,然後你有decoder,把聲音訊號產生出來。
link |
那像這樣子的架構,像這樣用autoencoder的訓練方法,會有什麼樣的問題呢?那我們發現說,其實你用這種autoencoder的訓練方法,你在產生聲音的時候,產生出來的聲音未必都非常理想。
link |
那一個可能的原因是,其實model在training的時候,他從來沒有考慮過要做voice conversion這件事情。為什麼這麼說呢?你想想看,你的model在training的時候,你的content encoder跟speaker encoder,其實你吃的是同一個speaker的資訊,甚至你吃的是同一個句子的資訊。
link |
你是把同一個句子,它的content丟到content encoder裡面去,它的speaker的資訊丟到speaker encoder裡面去,然後在training的時候,你是用autoencoder的方法去minimize reconstruction error。
link |
但是在testing的時候,你的model第一次知道說,原來現在我們要做voice conversion,我們不是要做autoencoder。你的model第一次知道說,原來content跟speaker的encoder,他吃的可以是不同speaker的來源。
link |
那你期待說,雖然training的時候沒有做過voice conversion,但testing的時候,如果content encoder跟speaker encoder給他不同的speaker,也許還是可以得到我們要的結果。
link |
但是往往事與願違,因為training跟testing是一樣的狀況,所以在testing的時候,你不一定能夠得到你想要的、理想的結果。
link |
所以怎麼辦呢?我們發現你可以做一個second stage的training,這個second stage的training對你得到好的voice conversion的結果是蠻有幫助、蠻關鍵的。
link |
那這個second stage的training是什麼呢?我們剛才說在train這個feature disentangle,一般trainingfeature disentangle的方法,在training的時候,他從來沒有把voice conversion這件事情考慮進來。
link |
那我們能不能夠在training的時候把voice conversion這件事情考慮進來呢?是有可能的。我們可以給content encoder跟speaker encoder不同的speaker。
link |
我們可以在training的時候sample一個句子給content encoder,sample一個speaker給speaker encoder,這樣子讓你的decoder看到來自於不同句子、來自於不同speaker的content跟speaker,然後讓他synthesize聲音出來。
link |
但是這樣做會遇到問題是什麼呢?為什麼之前我們都不這樣做呢?因為如果你今天你的content encoder跟speaker encoder,他的speaker是不同的,那decoder應該要synthesize什麼樣的聲音訊號?
link |
我們是沒有正確答案的,我們是沒有quantum的。沒有quantum、沒有正確答案,你根本就沒有辦法做訓練這件事情。
link |
之前feature disentangle的model encoder decoder可以訓練,所以我們用類似auto encoder的方法來進行訓練。
link |
我們讓content encoder跟speaker encoder吃的是同一個句子,然後你叫decoder產生同一個句子回來。但現在問題是,如果你要讓content encoder跟speaker encoder吃不同的句子,他們是來自於不同的語者,那synthesize的結果,這個decoder output出來的聲音訊號,他的正確答案是什麼,你不會知道,那你就沒辦法訓練了。
link |
所以怎麼辦呢?我們這邊引入了gain的概念。你再train一個discriminator,這個discriminator的任務是判斷這句聲音訊號聽起來像是真正的聲音訊號,還是語音合成出來的聲音訊號。
link |
有了這個discriminator以後,decoder就要想辦法去騙過這個discriminator。雖然我們不知道說,現在合成出來的聲音訊號應該聽起來像是什麼樣子,它的one truth正確答案應該是什麼。
link |
但有了這個discriminator以後,我們至少可以確保說decoder輸出來的聲音訊號聽起來像是真正的聲音訊號,它聽起來至少可能是比較清晰的,像是人講的一個句子。
link |
那你這邊還可以加一個speaker classifier,speaker classifier在這邊存在的目的是什麼呢?speaker classifier在這邊存在的目的是判斷一段聲音訊號是不是某一個人講的。舉例來說,如果你這邊這個speaker encoder的部分告訴decoder說,我們要合成A的聲音。
link |
雖然我們並不知道A說這個,這邊假設content encoder的輸入是hello,speaker encoder的部分輸入是A,雖然我們不知道A說hello的聲音訊號是長什麼樣子。
link |
但至少有了這個speaker classifier以後,decoder會想辦法希望讓speaker classifier會把它合成出來的這段聲音訊號分類成屬於A這個語者的聲音。
link |
所以先train好一個speaker classifier,decoder要想辦法合一段聲音訊號,讓decoder覺得這段聲音是A講的。雖然你不知道A說hello的聲音訊號是怎樣,但至少你可以讓這段聲音訊號聽起來像是A講的。
link |
我們發現說,這個方法對於讓你的voice conversion系統的品質變好是蠻有幫助的。我們還發現說,如果你今天直接update decoder的參數,去騙過discriminator,去讓speaker classifier得到正確的分類結果,那其實你很容易不小心一訓練就壞掉了。
link |
所以怎麼辦呢?我們發現一個有效的tip是你加一個patcher。patcher的意思是說,我們也有一個model,這個model吃的input跟decoder一樣,那decoder就是吃content encoder的輸出跟speaker encoder的輸出得到一段聲音訊號。
link |
那這個patcher,這個打補丁的東西,它吃的input跟decoder一樣,它也是產生一段聲音訊號。那它產生的這段聲音訊號會加到原來decoder的輸出上面,再去給discriminator跟speaker classifier看。
link |
所以這個patcher,它的作用就是打補丁,覺得本來decoder輸出的結果不太好,所以patcher把一些補丁在丁到decoder的output上面去,然後期待說patcher產生出來的輸出丁到decoder的輸出上面去,
link |
然後丟到discriminator丟到speaker classifier,會讓discriminator覺得合成出來的聲音訊號聽起來是真實的,會讓speaker classifier知道說這段聲音訊號應該是A的聲音。
link |
我們發現說不直接確認decoder,而改缺另外一個額外的model,會讓訓練的結果比較容易成功,會讓訓練的結果比較穩定。
link |
這個是feature disentangle的方法。
link |
那我們接下來要談下一個方法,下一個方法是直接把A的聲音轉成B的聲音。剛才我們在講feature disentangle的時候,我們說我們要把聲音訊號裡面跟speaker、跟content有關的訊息把它解離出來。
link |
現在我們不想那麼多,直接train一個model,輸入A的聲音訊號,希望直接輸出就是B的聲音訊號。那怎麼做到這件事呢?這邊直接就借用了在影像上非常常被拿來做影像風格轉換的psycho game。
link |
所以你會發現說等一下介紹的內容其實跟psycho game是一模一樣的。如果你有聽過我講game的課程的話,你會發現說這個部分的內容根本跟在講psycho game的內容是一模一樣的。
link |
只是在講psycho game的時候,我們都拿影像作為例子,這邊唯一不同的地方就只是把影像換成聲音,然後就結束了。
link |
psycho game是怎麼運作的呢?假設我們收集了兩個人的聲音,一個是心元節的聲音,另外一個是一個死肥仔的聲音。然後我們要train一個generator,它可以把X的聲音轉成Y的聲音。那怎麼做呢?
link |
這個generator就吃X的聲音訊號進來,你希望通過一連串的轉換,也不知道怎麼轉換,反正network自己會幫我們做到這件事情,然後就得到Y的聲音。也許裡面也做了feature distinctangle之類的,反正不知道。
link |
一個network反正就是可以把X的聲音轉成Y的聲音。但是我們並不知道X的聲音轉成Y的聲音應該聽起來像是什麼樣子,我們沒有ground truth,那怎麼訓練這個generator呢?你需要一個discriminator。
link |
你只需要提供給discriminator很多Y的聲音,然後discriminator就會去學會去鑑別說一段聲音訊號是Y的聲音還是不是Y的聲音。那這個discriminator吃一段聲音訊號當作輸入,會output一個scalar,這個scalar代表輸入的這段聲音訊號聽起來像不像是Y的聲音。
link |
那這個generator訓練的目標就是要去想辦法騙過discriminator。如果這個generator成功地騙過discriminator,那就代表說這個generator輸出的聲音訊號聽起來像是Y的聲音。
link |
但是,如果我們只是訓練一個generator、訓練一個discriminator是不夠的,那我們在講Cycle Game的時候也已經提過類似的問題,也已經提過這樣的問題。
link |
這個generator可能會學到說,我們就不要管這個輸入X的聲音訊號是什麼,我們不要管這個死肥宅在說什麼。
link |
不管死肥宅在說什麼,我們就合出《新人結衣》最常講的一句話。但我Google了半天也不知道《新人結衣》最常講的一句話是什麼了,也許有人比較清楚你老婆講的話,最常講的話是什麼,你再告訴我。
link |
這個generator可能會完全無視這個死肥宅講的話,反正輸出一段聽起來像是《新人結衣》講的聲音就結束了。那這個可能不是我們要的。
link |
那怎麼辦呢?我們還需要加另外一個generator,這個generator會把Y的聲音轉回X的聲音,那我們要讓輸入的聲音訊號跟輸出的聲音訊號越接近越好。
link |
所以我們把X的聲音轉成Y的聲音,再把Y的聲音轉成X的聲音,要讓輸入跟輸出越接近越好,這個東西叫做cycle consistency。
link |
你可能會問說,怎麼讓兩段聲音訊號越接近越好呢?其實我們知道聲音訊號,對你的network來說,聲音訊號其實就是一個vector sequence。
link |
所以大家看到在這門課裡面提到說把一段聲音訊號丟進network的時候,實際上你真正做的事情是把一段聲音訊號表示成一個acoustic feature sequence,把一段聲音訊號表示成一個vector sequence,也就是一個matrix,丟到你的network裡面去。
link |
所以吐出一段聲音訊號其實是吐出一個acoustic feature sequence,也就是吐出一個matrix。你要讓兩個matrix越接近越好,其實就是算它L1、L2的distance。
link |
至於這個matrix到底是什麼玩意兒,這個acoustic feature到底是什麼玩意兒,你可以用各式各樣不同的acoustic feature。
link |
我們在座位裡面也有一題就是問你說你現在用的程式,它的acoustic feature用的是什麼。
link |
那在train CycleGAN的時候還有一個小小的tip,這個小小的tip是說你想要train一個X轉成Y的generator,那你在訓練的時候不只要丟給它X的聲音讓它轉成Y的聲音,你在訓練的時候還可以再多加一個訓練的目標,這個訓練的目標是直接給這個generatorY的聲音,希望它可以合成出一模一樣的Y的聲音,這個讓你的訓練比較穩定一點。
link |
你輸入Y的聲音,然後因為這個generator本來就是要把X的聲音轉成Y的聲音,所以輸入Y的聲音,吐出來應該是一段一模一樣的聲音。
link |
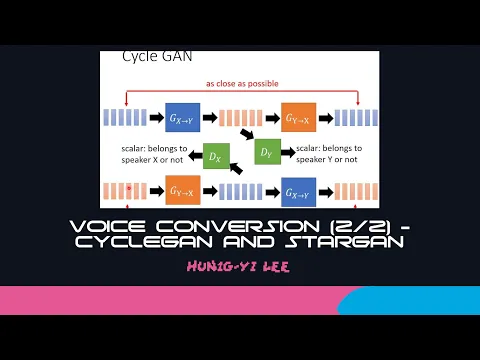
那這個CycleGAN它還可以是雙向的,就這邊上半部是把X轉成Y,Y轉成X,那你同樣可以先把Y的聲音轉成X的聲音,然後加一個discriminator,這個discriminator判斷說現在這個橙色的generator它輸出的這個聲音像不像是X的聲音。
link |
然後你要另外一個generator把X的聲音轉回Y的聲音,你一樣要有cycle consistency的loss,讓Y的聲音變成X的聲音以後,再通過第二個generator要從X的聲音變回Y的聲音,輸入跟輸出要越接近越好。
link |
那這個是完整的CycleGAN,接下來下一個要跟大家講的是StarGAN,這個StarGAN是CycleGAN的一個進階版。那這個StarGAN做的事情是什麼呢?剛才我們是說我們有一個speakerX,有一個speakerY,然後這個CycleGAN可以把X轉Y的聲音,Y轉X的聲音。
link |
但是如果我們今天有多個語者的話,那CycleGAN那個想法就不太適用了,假設我們今天有四個語者,那你顯然就要在這個語者兩兩之間都做CycleGAN,你才有辦法把這四個語者的聲音進行互轉。
link |
所以在CycleGAN裡面,假設你有N個speaker,那你需要N-1個generator才能夠把這N個speaker的聲音互轉,所以就有了CycleGAN的進階版叫做StarGAN。
link |
那這個StarGAN是怎麼運作的呢?我們要改一下我們的generator跟discriminator,怎麼改generator跟discriminator呢?在剛才的CycleGAN裡面,你的generator只會做一件事,它只有一個專長,它只有一個能力,它會把X的聲音轉成Y的聲音,或把Y的聲音轉成X的聲音。
link |
在StarGAN裡面,你的generator是多才多藝的,它可以做各式各樣不同的事情,它可以把輸的聲音訊號轉成各式各樣不同的你要的語者的聲音。
link |
那怎麼操作這件事呢?怎麼告訴generator說你要產生的聲音訊號是誰的聲音訊號呢?
link |
那你就首先給generator一段聲音訊號,是你要被轉的那段聲音訊號,speaker Si的聲音訊號。如果你要把Si的聲音轉成Sj的聲音,那怎麼辦呢?
link |
你要告訴generator說,現在你要把輸的聲音訊號轉成誰的聲音訊號。你要給generator一個information,你要告訴它說,你現在要把進步的聲音訊號轉成Sj這個語者的聲音訊號。
link |
那怎麼把這個speaker的資訊給generator呢?其實在做feature disentangle的時候,在上一個部分在講feature disentangle的部分,我們也已經講過類似的問題。
link |
你可以把每一個speaker表示成one-hot的vector,每一個speaker都是一個向量,這個向量只有一維是1,其他都是0,你有一百個語者,那你這個向量就是一百維留給generator,這是一個方法。
link |
甚至你可以說,你有一個事先已經訓練好的,你有一個已經pre-trained好的speaker encoder,它可以把每一個語者的聲音的特徵用一個continuous的向量做表示,那也可以,你就給這個generator一個continuous,不是one-hot的向量。
link |
所以,一個speaker要怎麼來表示它?你是可以有各式各樣不同的方法的。如果你有一個已經pre-trained好的speaker encoder,你甚至可以給那個speaker encoder看在訓練的時候從來沒有看過的語者,它也可以抽出一個向量來,你可以把這個向量丟給generator,那這樣generator有可能可以把輸的聲音訊號轉成訓練的時候它從來沒有看過的語者的聲音訊號。
link |
總之,我們現在的generator的改變方式就是,我們需要告訴它現在要轉出來的聲音訊號應該是哪一個speaker的聲音訊號。這是generator的改變。
link |
discriminator,我們也做了一些改變。discriminator需要做什麼樣的改變呢?discriminator原來是吃一段聲音訊號判斷說這段聲音訊號是不是某個人講的,因為原來discriminator也只會做一件事,它只會判斷說輸的聲音訊號是不是某一個人講的。
link |
在這個start gate裡面,discriminator的改變是說,它也要吃一個speaker的資訊。你要告訴discriminator說,我們現在要鑑別這段聲音訊號是不是某一個語者講的,我們現在要鑑別說這段聲音訊號是不是speaker SI講的。
link |
discriminator會根據你輸的speaker的資訊去判斷說,現在這段聲音訊號聽起來像不像是某一個語者講的。這個是discriminator的變形。
link |
我們知道現在start gate裡面的generator跟discriminator長什麼樣子以後,我們就可以來看看start gate是怎麼運作。發現說它的運作方式跟cycle gate基本上就是大同小異。
link |
我特別把cycle gate的運作方式放在投影片的上方,讓你比較輕易可以做一下比較。
link |
我們來看一下start gate是怎麼運作的。在訓練start gate的時候,你先隨便sample某一個speaker的聲音,比如說你sample speaker SK的聲音,然後你再隨便sample某一個speaker,比如說你隨便sample到SI這個speaker。
link |
generator就知道說,現在我們要把speaker SK的聲音轉成SI的聲音,它就把SI的聲音合成出來。
link |
discriminator會去判斷說這段聲音訊號是不是SI的聲音。discriminator怎麼知道現在要判斷的這段聲音訊號是不是SI而不是SK而不是SJ而不是別的人的聲音呢?
link |
所以我們會告訴discriminator,我們會把這個speaker的資訊也丟給discriminator,discriminator看這個speaker的資訊,看這個generator合成出來的結果,去判斷說generator現在產生出來的這段聲音聽起來像不像是SI這個speaker的聲音。
link |
接下來你還會把同一個generator拿來,但是這一次你給generator不同的speaker的資訊,剛才generator是給他SI的speaker的資訊,輸入的這段聲音訊號是SK的聲音訊號,所以你給generatorSK的資訊。
link |
現在輸入不同了,所以這個generator做的事情就會不同了,他就會把這段聲音訊號轉成SK的聲音訊號。我們同樣要讓輸入跟輸出越接近越好。
link |
輸入是SK的聲音,那你告訴generator說要轉成SI的聲音,discriminator判斷這段聲音訊號好不好,然後接下來你告訴generator說轉回SK的聲音,然後就會把這段聲音訊號轉回SK的聲音,那你要讓輸入跟輸出越接近越好。
link |
這個就是stargame的訓練方式。那其實在訓練stargame的時候,你還會再加上一個classifier,然後今天在這個投影片上,我們就省略了加classifier的這個部分,你可以自己讀一下原始的論文看看這個classifier是怎麼被加進去的。
link |
講到這邊,可能有同學會問說,用stargame這個系列的方法,用直接做transformation的方法,跟前面做feature disentangle的方法,這邊有兩個方法,到底誰好誰不好呢?
link |
我覺得你其實不一定要把這兩個方法直接拿來比較,因為比較這兩個方法當然不太容易,在不同的文獻上用了不同的network架構來做不同的事情,所以有點難把不同的方法做side by side的比較。
link |
但問題是這兩個方法其實也沒有衝突,feature disentangle的方法跟直接轉換的方法其實也沒有非常大的衝突,你可以把這兩個方法整合在一起。
link |
怎麼把這兩個方法整合在一起呢?你可以把這邊這個generator換成我們在feature disentangle裡面看到的那個encoder跟decoder所組成的autoencoder,就是我們這邊沒有告訴你說你的generator的network架構應該長什麼樣子,但你能不能說在這個generator裡面,我們就有encoder、有decoder。
link |
我們這個generator裡面有encoder把這個SK的聲音訊號吃進來,decoder它吃encoder的輸出,也吃這個speaker的資訊,然後產生SI這個speaker的聲音訊號。
link |
所以你完全可以把feature disentangle的概念也放到這個cycle game裡面來。我在文獻上好像還沒有看過有人這麼做,不過我這邊想要講這一段的意思只是想要表達說,你不見得硬是要比較feature disentangle跟直接transform這兩個方法的差異。
link |
你其實可以把feature disentangle的方法跟cycle game跟star game的方法直接有機會把它結合起來。也許你可以在座位裡面試試看說這兩個方法結合起來會不會更好,然後再來告訴我結果怎麼樣。
link |
還有一個比star game更進階的做法叫做flow。flow是什麼呢?它是用flow-based model來做voice conversion。
link |
不過我知道說flow-based model,你大概就忘光了,所以我們這邊也就不細講flow這個技術,只是告訴你說有這個技術就是了。假設你想複習flow-based model的話,可以看一下過去機器學習這門課上課的錄影。
link |
好,那這個就是voice conversion的部分,就告訴大家說今天在研究上主要都專注於unparalleled data來做voice conversion,這樣子unparalleled data可以有兩種不同的方式來做到voice conversion這件事。
link |
好,那大家有問題的話就可以提出來,那如果沒有問題的話,我們就進入到新的篇章,我們要來講speech的separation,以這邊是reference,我看大家有沒有問題。