back to index
[DLHLP 2020] Speech Separation (2/2) - TasNet
link |
接下來,我們會花比較多的時間介紹Testnet這個network架構。Testnet是Titleman的Audio Separation Network的縮寫。Testnet是我們在作業三會使用到的network架構,所以我們就特別花時間來講一下。
link |
你會發現它propose的時間是19年,所以這是一個很新的network架構。我現在手機不知道為什麼不能看螢幕了,如果同學有問題的話,我們等一下就一起問,我們很快地講一下Testnet的架構。
link |
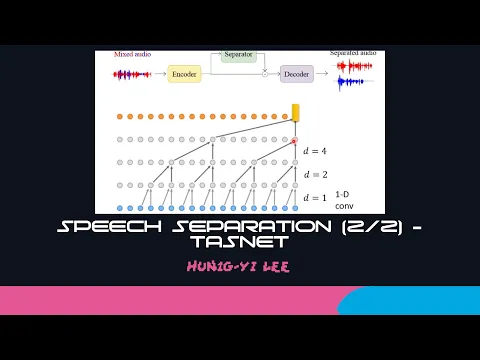
Testnet分成三塊,一個encoder,一個separator,一個decoder。Testnet一個神奇的地方就是,它輸入跟輸出就直接是聲音訊號的sample,就直接是waveform,所以它就沒有抽什麼acoustic feature了。
link |
所以對Testnet來說,它的輸入就是一串非常長的數值,或者是你還是可以把它當作是一個vector sequence,只是每一個vector它的dimension就是1。
link |
這個聲音訊號通過encoder以後,變成一個matrix,這個encoder做的事情有點像是Fuller transform,但是它是認出來的Fuller transform。
link |
這個encoder丟給separator以後,它產生兩個mask,所以在Testnet裡面,它還是保有speaker separation古老的精神,產生兩個mask。
link |
這兩個mask分別去乘在encoder的output上,你就得到兩個乘上mask的結果。
link |
把這兩個得到乘上mask的結果分別通過decoder以後,你就要產生兩段聲音訊號。
link |
在training的時候,你需要PIT,Testnet的training是需要PIT的。
link |
我們作業會分成兩個小題,第一個小題是說,如果固定訓練跟testing都是固定的兩個speaker,那你就不用PIT,訓練容易一點。
link |
如果今天training跟testing是不同的speaker,那你確實就需要PIT來訓練你的Testnet。
link |
這個decoder的作用有點像是inverse的Fuller transform,它把Fuller transform乘上mask以後的結果,通過inverseFuller transform decoder以後,產生出聲音訊號。
link |
那我們來很快的看一下encoder跟decoder的運作。encoder是什麼?encoder就是一個linear的transform,它就是一個metric,它不是什麼特別多特別神奇的東西,它就是一個metric。
link |
training的時候是end-to-end,input-mix-audio-outputs,這個separated的聲音訊號,end-to-end的train就可以把encoder-separator跟decoder的參數找出來。
link |
encoder就是一個linear transform,輸入是非常小的一段聲音訊號,只有16個sample,你可以想成是一個16維的vector。
link |
通過encoder以後產生一個512維的vector,它就是一個linear transform,把16維的vector變成512維的vector。
link |
有人可能會說,一般我們做完Fuller transform以後拿去做process的東西都是spectrogram的magnitude,既然是magnitude,應該是正的囉,那我們需不需要讓encoder的output是正值呢?
link |
在testnet原始的paper裡面有嘗試過這件事,他們把這個vector再通過relu,讓它變成都是non-negative的值,但發現說通過relu沒比較好啦,讓它有正有負的結果還稍微好一點。
link |
所以這邊不一定要是positive的,這個neural自動論道的Fuller transform它不見得是output magnitude,它可以output別的東西。
link |
那有一個decoder,decoder是吃一個512維的向量,然後把它轉回聲音訊號。
link |
它其實也就是一個linear transform,把512維的向量乘上一個512乘16的matrix,然後產生16個sample。
link |
有人說這個Fuller transform跟inverseFuller transform它們應該是互為inverse的,就是encoder如果代表Fuller transform,decoder代表inverseFuller transform,
link |
那我們今天把16個sample丟到encoder變成512維,再把512維丟到decoder,一模一樣的512維向量丟到decoder,應該產生回一模一樣的聲音訊號囉,它們應該互為inverse的囉。
link |
在testnet原始的pairing裡面嘗試說,它故意讓encoder跟decoder在訓練的時候有一個限制,就是要互為inverse,結果沒有比較好,而且還明顯比較差。
link |
所以神奇的是,network自己認出來的Fuller transform跟inverseFuller transform不見得要互為inverse,給它比較大的flexibility,結果反而做得比較好。
link |
那這個encoder認出來的結果長什麼樣子呢?我們說encoder裡面其實就是一個矩陣,這個矩陣其中一邊是512維,代表說你有512個basis。
link |
Fuller transform裡面就是有很多basis,這邊要產生512維的向量,代表你有512維的basis。輸入就是16個sample,你把這16個sample通過這512個basis就產生512個值。
link |
所以這邊每一個row就是一個basis,或者是說如果你很熟悉那個通訊系統的話,每一個row就是一個match filter,把這一小段聲音訊號通過這512個match filter就得到512個值。
link |
那這些match filter在做什麼呢?你會發現這些match filter很明顯地在encode不同的frequency的訊號。
link |
有encode比較高頻的,你把這些basis做Fuller transform得到右邊的結果,有一些是encode比較高頻的,有一些是encode比較低頻的。
link |
低頻的basis特別多,因為人的聲音在低頻的部分資訊特別多,所以低頻的basis特別多。
link |
另外,它其實是有encode phase的資訊的。我們一般在做Fuller transform以後,做完那phase可能就丟掉,你只拿magnitude來進行處理。
link |
但是這個phase是有被encode進去的,你會發現說這些basis,他們這些match filter可以通過的frequency差不多,但是他們的phase是不一樣的。
link |
代表說不同的phase也被encode在這個512維的向量裡面,而這一切都是nevo自動學到的。
link |
那encoder的輸出是一堆向量,所以你把一段聲音訊號丟給encoder,然後encoder接下來它就輸出一排vector。那這一排vector要怎麼進行處理呢?
link |
就是用一個mask。那separator它內部的架構長什麼樣子呢?那這個圖大家一定在各個地方非常常看到,它就是webnet的架構圖。
link |
那這個separator也就是webnet裡面做了什麼呢?它做的事情是首先把這一排vector encoder的output把它吃進去。
link |
接下來這個separator裡面有很多很多層的CNN,這個CNN的第一層做的事情是什麼呢?
link |
這個CNN第一層做的事情是它會把這些輸入的vector sequence兩個兩個兩個一組,然後兩個兩個兩個一組,然後通過一排filter,通過一堆filter以後,
link |
把它變成一個新的vector。那這個圖上的每一個點其實就代表了一個vector。所以第一層做的事情吃兩個vector,output一個vector。
link |
所以一排這樣的vector進來,你會看到這個separator第一層會給你另外一排的vector。
link |
那在這個separator裡面呢,其實用的是一個dilated的CNN的架構。所以在第二層裡面,就不是把相鄰的兩個vector變成一個vector。
link |
在第二層裡面呢,是會跳一格,它會中間空格把這兩個vector吃進去,得到一個新的vector。
link |
然後在下一層,它會跳三格,你這邊吃一個vector,然後跳三格,也就是跳四步,空下跳過三個vector,跳四步以後,再吃一個vector。
link |
這邊用d代表說跳了幾步,所以這邊吃連續兩個vector,得到一個新的vector。跳兩步,吃兩個vector,得到一個新的vector。跳四步,吃兩個vector,得到一個新的vector。然後就接下來跳八步,吃兩個vector,得到一個新的vector。
link |
所以當我們產生這個vector的時候,我們已經看了非常長的一段聲音訊號,才產生這個vector。
link |
因為其實這邊,每一個這邊輸入encoder和輸出的向量,它看的聲音的資訊其實非常非常的少,它只看了16個sample那麼小的範圍。
link |
所以如果只看一個vector,你是很難去預測說你要產生什麼樣的masking的。
link |
但是這邊用了這個webnet的deletedCNN的架構,所以看非常長串的一個vector,然後接下來經過一番的process,經過很多個CNN的layer,然後產生一個新的vector。
link |
這個vector接下來做什麼呢?你會把這個vector乘上兩個不同的transform,乘完這兩個不同的transform以後,你就得到了兩個mask。那接下來,你會把這兩個mask分別跟encoder的output做相乘,然後再把相乘的結果丟到decoder裡面去。
link |
那在產生mask之前,在testnet裡面會apply一個sigmoid,也就是說mask裡面的值會介於0到1之間。
link |
那這個想想是還蠻直覺的,因為mask做的事情就是要把這個vector裡面屬於speaker1的部分抽出來跟屬於speaker2的部分抽出來。所以這個mask裡面0到1的值代表就是說,在這個vector裡面呢,
link |
每一個dimension分別是屬於speaker1比較多一點,還是屬於speaker2比較多一點。
link |
所以這邊有apply一個sigmoid,讓mask的值介於0到1之間。但其實在這個testnet的原始paper裡面呢,他也有說這個sigmoid其實不是非常必要的,你可以沒有sigmoid,讓machine自己決定說mask的值應該是多少,甚至mask的值是負號也能夠運作。
link |
那有人可能會想說這個mask1跟mask2他們需不需要在同一個dimension的值,需不需要合為一呢?
link |
因為可能encoder的output裡面,每一個dimension的值要嘛是屬於speaker1,要嘛是屬於speaker2,他可能0.7屬於speaker1,0.3屬於speaker2,那可能mask1跟mask2同樣dimension的值應該要合為一。
link |
但是在testnet的原始paper裡面做了這個實驗,如果你用一個soft mask,讓mask1跟mask2同樣dimension的值呢,固定合為一,那這件事情對你最後performance是沒有幫助的。
link |
你只要讓machine,machine可以自己學到適當的mask,你並不需要特別在這個地方加什麼額外的限制。
link |
這就是encoder的一小部分,剛才只是一個例子而已。真正的separator長什麼樣子呢?真正的separator是比我們剛才看到的那個例子還要更深得多的。
link |
就是你的encoder的output先經過第一個convolution,還有第二個convolution,還有第三個convolution,然後這樣一直下去一直下去一直下去,一直到你這個d等於128的時候才停止。
link |
就是第一個convolution,d等於1,然後再來是2,再來是4,再來是8,再來是16,一直下去一直到d等於128的時候停下來。在這邊停下來並不是全部的結束,並不是要產生mask。
link |
那這邊跑到d等於128的時候,接下來發生什麼事呢?接下來居然就從頭開始,從d等於1到d等於128這個部分叫做一個repeat,然後接下來從頭開始循環,從d等於1,d等於2又重新開始,一直到d等於128。
link |
那這個repeat會repeat三到四次,那這要repeat幾次這就是一個hyperparameter,所以這個是你需要自己去調一下。所以你會發現說這個separator它其實是一個非常深的CNN,它是一個可能超過20層的CNN,通過了非常非常多非常非常多非常多層的convolution以後,最後產生你的mask。
link |
那為什麼需要反覆反覆用這麼多的CNN呢?因為如果你CNN反覆的夠多次,你就可以看到夠長的資訊。
link |
所以每次encoder output的一個vector,它只代表了16個sample,兩個minisecond這麼短的聲音訊號,但是你只要重覆的夠多次,舉例來說像這個例子裡面,你如果把這樣子的network架構,d等於1到d等於128這樣的network架構repeat三次,那你的model其實看到的長度就已經有1.53秒那麼長了。
link |
雖然每次encoder,它encoder的聲音訊號長度只有兩個minisecond,但只要你CNN疊的夠深,每次你產生masking的時候,你是聽了1.53秒的聲音,然後才產生這個mask。
link |
好,那在每一層的這個convolution裡面,其實在case net裡面,才apply了一個network reduction的技巧,叫做deathwise separable convolution。deathwise separable convolution是什麼呢?它是一個可以讓CNN的network參數減少的方法,一個讓CNN可以輕量化的方法。
link |
那像這種network reduction的技術,我們在machine learning那一門課是有講的,那我把這個machine learning那一門課的錄影的連結放在這邊給大家參考。那在這門課裡面,我們就不細講什麼是deathwise separable convolution。
link |
這個case net裡面,它用了deleted的convolution,而不是用LSTN,但是case net有一個最早的版本,用的就是LSTN,那是第二個新的版本,才用convolutional的network。
link |
那為什麼從LSTN換成convolution呢?好的,convolutional的network跟LSTN,它們有什麼樣的差異呢?呃,今天在paypal裡面做了一個有趣的實驗。
link |
他說,其實LSTN是有點sensitive的,怎麼sensitive法呢?因為我們今天在訓練的時候,都是從,呃,都是讓LSTN吃一個句子的開始,一直到一個句子的結束。
link |
所以LSTN可能很習慣說,今天它第一個讀下來的sample就是一個句子的起始。如果你今天給LSTN不是句子的開始呢?你今天在做source separation的時候,你故意把,呃,你今天做source separation的時候,你故意不讓,你故意把這個聲音的前面一部分截掉,故意把聲音的前面,比如說50個sample截掉,比如說100個sample截掉。
link |
讓LSTN從第100個sample開始讀起,或從第50個sample開始讀起,會發生什麼事呢?好,這邊這個縱軸啊,是SDR的improvement,這個值越高代表這個performance越好啦。
link |
如果你是用LSTN的話,會有一個神奇的現象是,這個,呃,你的performance啊,是上下抖動的,那感覺LSTN它已經overfit到,就是要從一個句子的第一個sample開始讀起。如果你給它第50個sample,你叫它從第50個sample開始讀起,它會慘掉。
link |
你叫它從第150個sample開始讀起,它也會慘掉,它感覺overfit到一定要從句子的開頭讀起這件事情,所以感覺它有點脆弱。
link |
如果今天用convolutional的network,就不會有這個問題,就不會有這個問題。那為什麼會這樣子呢?其實你仔細想想也可以了解這個原因,因為convolutional的network它是time-invariant的。對一個CNN來說,它從一個outers的哪一個地方開始讀起,根本就沒差。
link |
但對LSTN來說,它從哪一個地方開始讀起是有差別的,它從每個句子不同的地方開始讀起是有差別的,所以LSTN會overfit到它起始位置的地方。那這就是為什麼把LSTN換成convolutional的network的一個原因。
link |
那這邊就跟大家講了testnet,最後這一頁跟testnet有關的投影片,就是很快地再幫大家複習一下testnet整個network做的事情是什麼。
link |
好,testnet有一個encoder,encoder做的事情就像是fuel transform,把聲音訊號轉成spectrogram,或是類似spectrogram的東西,你不能說它是spectrogram,因為它不是fuel transform,它是一個類似spectrogram的東西。
link |
好,你把mix的聲音訊號通過你的encoder,你的encoder其實就是這樣子的一個matrix,它就是一個輸入是2秒的,不是2秒,輸入是2ms的聲音訊號,輸出是512維的vector的這樣的乘況。
link |
你把這個聲音訊號通過這個乘況以後,它會產生一個matrix,每2ms會有一個512維的vector來表示2ms的聲音訊號,它看起來像是我們平常熟悉的spectrogram。
link |
接下來把這個spectrogram丟到你的separator裡面去,那separator就會輸出兩個mask給我們,這兩個mask是separator output出來的。
link |
今天這個例子裡面,這個例子是從原始paper裡面截下來的,那這應該是一個真實的例子。
link |
在這個真實的例子裡面可以看到說,這邊用紅色跟藍色分別代表兩個speaker的聲音訊號。
link |
這個transform以後,在這個類似spectrogram上面的matrix,這個藍色跟紅色代表說,通過這個transform以後,藍色跟紅色的speaker,他們的聲音訊號的強度,他們所佔的比例。
link |
那你會發現說在estimate這個masking的時候,正好就會estimate出一個mask是給speaker2的,speaker2在開頭跟中間這一塊能量比較強,所以mask就是特別把開頭跟中間這一段讀出來。
link |
那speaker1呢,藍色這個speaker在這個地方跟這個地方訊號比較強,那speaker1的mask正好就是在這個地方跟這個地方的值比較接近1,在這個地方跟這個地方的值就比較接近0。
link |
那把這個mask呢,乘上這個類似spectrogram的matrix,把這個mask乘上這個類似spectrogram的matrix,然後再通過另外一個decoder,它的作用有點像是inverse of pure transform,然後就產生回原來的聲音訊號。
link |
這就是整個testnet運作的方法,那在train testnet的時候,它是end-to-end train的,雖然中間有很複雜的process,但是你真正給testnet的東西,就是輸入的mix的聲音訊號跟輸出的已經separate好的聲音訊號。
link |
那訓練的時候,你需要使用PIT。好,那testnet的結果怎麼樣呢?這邊我是引用了另外一篇叫做wave split的paper的數據,那wave split這篇paper呢,它是今年才放在archive上的。
link |
所以它應該是我目前看到在benchmark corpus,這邊指的benchmark corpus是wall street journaling,我們一般在做speaker separation的時候,如果你要做benchmark跟其他人比的話,通常是用wall street journaling。
link |
好,它在wall street journaling上面,它的SISDR的improvement,wave split這個方法高達19,或者是它有一個data augmentation的方法可以讓SISDR高達20,那這應該是我目前看到performance最好的speaker separation的level。
link |
好,那這個testnet在哪裡呢?testnet在這個地方,如果你是用LSTM的話是13點多,如果你是用convolutional neural network的話,可以進步到15點多。
link |
所以這個結果也是蠻好的,其實這個SISDR的improvement如果到15點多的話,你的作業裡面可以自己測測看,你的結果應該是相當不錯的,聽起來是蠻接近完美的結果了。
link |
你可以想像說SISDR做到20,到底聽起來應該是有多perfect的結果。好,那這個deep clustering它的SISDR的improvement只有10.8,今天看起來當然是沒有很好,今天看起來如果SISDR是10.8,感覺還有蠻大進步的空間的。
link |
因為當年deep clustering剛出來的時候,大家覺得哇,這個SISDR的improvement做到10.8,哇,這太驚人了,這太驚人了,那今天看起來是有很多方法都可以表達deep clustering了。
link |
那雖然在這個table裡面你會覺得說,如果我們看performance的話,testnet感覺是把deep clustering按在地上摩擦,但是實際上真的是這樣子嗎?
link |
那我們現在給機器聽一段這樣mix的聲音。
link |
那如果你在Wall Street Journal上train一個testnet,那你得到的結果可能是這個樣子的。
link |
咦?它完全沒有做到source separation這件事,你可能會想說這個也不意外啦,我們現在要機器做source separation的聲音是中文的,但是Wall Street Journal是英文的。
link |
所以這個testnettrain在英文上,測試在中文上,本來結果就不會好啊,deep learning容易overfit啊,結果不好也是可以預期啊,deep learning就是不work。
link |
但是,如果我們同樣把deep clusteringtrain在Wall Street Journal上,你得到的結果可能會是這樣子的。
link |
最近machine learning很熱門,所以大家都是嘗試看一些deep learning的paper,嘗試把它們implement出來。
link |
所以有趣的事情是,deep clustering在這個例子上的結果其實是比testnet好的。
link |
雖然deep clustering它聲音分離的效果沒有真的非常好,你剛才聽到說背景你還是可以聽得到另外一個人的聲音的。
link |
但是相較於testnet,deep clustering是有做到source separation這件事情的,那這是怎麼回事呢?
link |
所以我們在作業裡面有一題額外的bonus,就是叫大家拿自己找到的聲音來混,然後來測試一下自己用testnet訓練出來的模型。
link |
你會發現說,也許testnet沒有我們想像的generalize的能力那麼好。有些方法雖然聲音的品質聽起來沒有那麼好,但是也許它generalize的能力用在沒有看過的domain mismatch的資料上的時候,也許結果會是比較好的。
link |
所以這個仍是一個上代研究的問題,就留待大家在作業中探索一下。
link |
差不多我想要跟大家分享的東西就講完了。
link |
但是其實這個speech separation還有非常非常多東西可以講,在我們這堂課裡面所cover到的內容其實只是滄海的一粟而已。
link |
首先今天在這門課裡面,我們都假設輸入的聲音訊號就是兩個人的聲音訊號mix在一起。
link |
但是實際上在真實的問題中,我們根本不知道有多少個人在同時講話。
link |
那我們有沒有辦法讓deep network在不知道有多少人同時講話的情況下,就做到speaker separation呢?
link |
如果是deep clustering,好像有機會可以做到。我們在講deep clustering的時候,我們就有講說也許訓練的時候是兩個speaker,但是測試的時候有三個speaker。
link |
deep clustering還是有機會可以把三個speaker的聲音分別分離出來。
link |
如果今天是testnet就沒有辦法做了。如果今天是testnet的話,testnet能夠output幾個mask是預先設定好的。
link |
你必須要預先知道說我現在就是要做兩個speaker的speaker separation,然後你就設計好你的network架構是output兩個mask,這樣你才能夠把兩個speaker的聲音分開。
link |
如果你明明今天在testnet訓練的時候只能產生兩個mask,輸入是三個speaker的聲音,其實它也沒有辦法把三個speaker的聲音分開的。
link |
所以如果你今天要用testnet來解輸入的語者數量不固定的情況下,你有點不知道要怎麼做。
link |
那要怎麼把類似testnet這樣的架構用在不知道語者數量的speaker separation呢?
link |
這邊也不是完全沒有方法的,這邊提供給大家一個文件上有的方法。
link |
你可以訓練一個network,這個network的工作就是每次只分離出一個speaker。
link |
在我們之前所講的network裡面都是input mix的聲音訊號,就把每一個speaker的聲音訊號通通都分離出來。
link |
但我們現在訓練一個新的network,這個新的network它的工作是不管你輸入的聲音訊號是幾個人的混合,我做的事情就是輸出一個人的聲音訊號,它只把某一個人的聲音訊號抽取出來。
link |
舉例來說,在這個投影片上的例子裡面,輸入是三個人的聲音訊號,有藍色、紅色、綠色三個人,他們三個人的聲音訊號被混在一起。
link |
這個network不管你輸入幾個人的聲音訊號,它的工作就是抽一個人的聲音訊號出來。
link |
那到底要抽哪一個人呢?讓network自己決定。network自己決定它要抽哪一個人的聲音訊號出來,反正就是抽一個人的聲音訊號出來。
link |
所以今天這個network在訓練的時候,它訓練的目標就是不管輸入幾個人的聲音訊號,就是抽一個人的聲音訊號出來。
link |
所以它就把藍色那個人的聲音訊號抽出來,剩下紅色跟綠色。但這樣還是沒有做完speaker separation這個問題,我們還是有兩個人的聲音訊號被混雜在一起。
link |
沒關係,把這兩個人混合的聲音訊號還是丟到同一個network裡面去。
link |
這個network再把一個人的聲音訊號抽出來,比如說這是抽出紅色的人,最後只剩下綠色的人,這樣你也是達到了speaker separation這個目標。
link |
但你今天需要一個stopping criterion,就是今天如果說混三個speaker,我們怎麼知道說我們要把這個network就apply兩次呢?
link |
所以你需要有一個方法去偵測說,走到什麼時候應該要停下來,走到什麼時候剩餘的部分只剩下一個speaker了,
link |
或走到什麼時候剩餘的部分只剩下雜訊,已經沒有任何人的聲音訊號了,那你這一個network就要停下來,就不再recursively去apply在這個source separation這個task上面。
link |
所以這是一個可以處理input speaker的數量不固定的方法。
link |
那這不一定是最好的方法,怎樣的方法最好?這個是我們可以再想看看的,這是一個research的problem。
link |
那今天在這門課裡面我們都講說我們輸入的聲音訊號只有一個,我們只有一支麥克風。
link |
那我們知道說今天手機都不只一支麥克風,它有好幾支麥克風。
link |
像人有兩個耳朵,所以我們可以聽得比較清楚,人等於是有兩個麥克風,手機今天也往往都有兩個麥克風以上。
link |
那怎麼活用超過一個麥克風這樣子的聲音訊號呢?怎麼使用麥克風陣列傳進來的聲音訊號呢?
link |
當然在傳統上有一系列的訊號處理的方法來解這種麥克風陣列的問題。
link |
如果是deep learning的話,那就是本來輸入一個聲音訊號,現在變成輸入多個聲音訊號,輸入n個麥克風的聲音訊號,輸入n段的聲音訊號。
link |
那產生出來還就是你要的光束,然後n段的傳就結束了,這樣,n段的傳就結束了。
link |
所以多個麥克風也是有機會直接用n段的方法硬傳下去,然後就結束了。
link |
而我們剛才到目前為止講的speaker separation都只用聲音的訊號,機器都只聽聲音來做speaker separation這件事情。
link |
但在現實的生活中,人類不是只能聽聲音,我們還可以看影像,所以也有可能用影像的資訊來強化speaker separation這件事情。
link |
有沒有可能不是剛好藍色一邊,綠色紅色一邊,而是綠色的一部分被放到兩邊去?
link |
好,不是沒有可能的,如果你的network沒有訓練好,那確實他可能就會把同一個speaker的聲音放到兩邊去。
link |
但是今天你在訓練那個network的時候,你就是要教他說,他訓練的目標就是要把某一個speaker的聲音放到一邊,其餘speaker歸到另外一邊。
link |
所以他訓練的目標就是要抽出一個speaker的聲音,然後其他speaker都歸到另外一邊。
link |
所以今天把同一個speaker放到兩邊,也許你network沒有訓練好,有可能發生這種事,但這不是他訓練的目標,他訓練的目標就是一個speaker一邊,其餘speaker另外一邊。
link |
好,那我們繼續講有關visual的部分,所以我們有機會用影像的資訊來強化做speaker separation這件事情。
link |
舉例來說,Google有做了一個demo,這個demo是有影像資訊的speaker separation,也就是今天機器在做speaker separation的時候,不是只有聽聲音,他還會看影片中人物的頭像。
link |
那你甚至有這個技術以後,你可以選擇說,我們現在就是把左邊這個人臉旋起來,機器就產生左邊這個人的聲音,就把左邊這個人的聲音分離出來。把右邊這個臉旋起來,就把右邊這個人的聲音分離出來。
link |
好,所以你可以看到說,藉由選擇左邊人跟右邊的人,你可以選擇source separation以後的兩個speaker的結果。
link |
那像這樣子的demo是怎麼做出來的呢?也沒有怎麼做出來,就是硬券一發就結束了。
link |
這個demo就是吃mix的聲音訊號跟每一個人的人臉,就是你的訓練資料裡面是有每一個speaker不只有聲音訊號,還有他講話的時候的那個影片,講話的時候的那個頭像。
link |
所以你今天在實際上訓練的時候,只會把那個人的頭像把它解出來。
link |
把這些東西通通都丟進去,然後這邊不需要做PIT了,因為你已經知道說第一個channel就是要output A的聲音,第二個channel就是要output B的聲音。
link |
在這邊放A的頭像,這邊放B的頭像,在這邊放A的講話的video,這邊放B的講話的video,所以你就會直接等於是已經告訴Machine你的目標就是上面要輸出A的聲音,下面要輸出B的聲音。
link |
而這邊這個nemo架構跟我們剛才看到的testnet也是有異曲同工之妙,你的nemo會先產生mask,這個mask有點複雜,它是complex的mask,它是複數的mask,至於實際上什麼是複數的mask,那就讓大家自己研究一下文獻,大家自己去看一下paper。
link |
把這兩個mask乘上原來的聲音訊號,原來的聲音訊號得到乘上mask以後的結果,然後再做inverse dual transform就可以轉回原來的聲音訊號,那整個訓練是end-to-end的,然後你可以在讓機器有看到這個頭像的情況下,把聲音訊號就分離出來。
link |
這個是加上影像資訊的speaker separation。
link |
最後,我們今天在做speaker separation的時候,我們都說我們的training目標可能是要minimize跟quantum的L1 L2或者是SISDR,但是其實我們真正要minimize的目標,真正要optimize的對象,應該是depend on我們的任務的,因為今天我們做speech enhancement抗噪或者做speaker separation,它的目標有可能是不一樣的。
link |
我們今天做完speech enhancement跟speaker separation以後,我們的目標可能是給人聽,也可能是給機器聽。
link |
比如說今天你要做語音辨識,你可能會想要把輸入的聲音訊號先做一下speaker separation,做一下speech enhancement,把它變成比較乾淨的訊號,再丟給你的語音辨識系統。如果是給人聽的話,那我們在意的可能是人聽起來的quality,可能是人聽起來的intelligibility,也就是人覺得他聽這段聲音聽得懂還是聽得不懂。
link |
有一些optimization的measure,有一些measure其實是跟你的quality或者是intelligibility有關的。所以今天我們在做speaker separation這樣子的任務的時候,也許假設我們今天知道說我們分離以後的目標是要讓人聽起來覺得好聽,那也許我們應該要optimize人聽這段聲音的感知。
link |
有一些evaluation的measure,它本身設計的目標就是要拿來偵測、拿來模擬人類聽一段聲音的時候,他覺得這段聲音的quality或者是這段聲音的intelligibility。
link |
但是像這些measure,它往往非常的複雜。不像SISD,它是differentiable,它是可以微分的,你可以把它當作你的learning target。像PSQ這種optimization的measure,它是不能微分的。它就是一個黑盒子,你丟兩段聲音訊號進去,然後它輸出告訴你說這兩段聲音訊號,人聽起來覺得有多好。
link |
但是它是不能夠微分的,所以怎麼辦呢?你可以看一下以下這一篇文章,它告訴我們說,今天如果你遇到不能夠微分的這樣的evaluation measure,那你要怎麼進行處理?
link |
另外一個可能的面向是,假設我們這些聲音訊號不是給人聽的,而是給機器聽的,那其實我們就要考慮機器接下來的application是什麼。事實上,很多時候,你把你的聲音訊號做完denoise或者做完speaker separation,丟到你的network以後,丟到你後端的application,比如說語音辨識、比如說語者驗證以後。
link |
你的結果反而往往不一定會變好,因為你今天做speaker separation做denoise,你的目標是minimize L1 L2 SISDR,但是也許在這個過程中,你損傷了什麼對語音辨識非常重要的資訊,那這些資訊也許人聽不出來,但是對機器來說是重要的資訊。
link |
所以有可能你做完這些preprocessing,做完speech enhancement,做完speaker separation以後,你人聽起來覺得比較好,但是語音辨識反而變差了。這個是常常發生的,這是有可能發生的事情。
link |
所以往往我們做完denoise以後,你不會直接把denoise的聲音丟到ASR裡面去。你通常會說,如果我今天真的要做denoise,我會把我的denoise的model跟我的ASR model先串起來,再稍微end-to-end的訓練一下,然後這樣你的speech enhancement才會有用。
link |
如果你沒有把你的speech enhancement的系統跟ASR串在一起做end-to-end的訓練,往往兩個modulecascade起來,結果反而會不好。
link |
所以如果今天你想要用的是要把這些技術用來improve語音辨識系統或語者驗證系統,也許你在訓練這些系統的時候,你的目標應該是要去optimize某一個語音辨識系統的word error rate,minimize它的word error rate,或者是maximize你的speaker verification系統的正確率等等。
link |
所以針對不同的目標,針對不同的應用情境,也許我們應該要給speaker separation不同的目標,它的optimization的對象,它的objective function不一定只是SISDR或L1、L2而已,它可以有更豐富的optimization的對象。
link |
其實我們今天講的有關speaker separation的部分只是文件上有的滄海一述而已,而且我們甚至還沒有講任何speech enhancement的東西,那又是另外一個學問,這個有非常非常多東西值得大家再去深入的研究,那這邊就是多列了一些reference給大家參考。
link |
那有關speaker separation的部分,我們就講到這邊。