back to index
[DLHLP 2020] Speech Synthesis (1/2) - Tacotron
link |
好,那這一堂課呢,我們要講 Speech Synthesis,我們要講語音合成。
link |
好,在這堂課裡面呢,在這門課裡面,我們已經講過語音辨識,輸入聲音輸出文字。
link |
我們已經講過Voice Conversion,Speaker Separation,輸入聲音輸出聲音。
link |
接下來,我們要講語音合成,Text to Speech的Synthesis,輸入文字,
link |
那在下課之前呢,我們來回顧一下語音合成的歷史。
link |
當然今天語音合成就是end to end,硬吹一發,今天沒有什麼東西不是硬吹一發,每一個東西都是硬吹一發。
link |
但是在硬吹一發之前,語音辨識是怎麼做的呢?
link |
所以在下課之前,我們來講語音合成是怎麼做的呢?所以在下課之前,我們來講一下在有硬吹一發之前,
link |
語音合成是怎麼做的?然後接下來進入硬吹一發的時代。
link |
然後我們還會講說在硬吹一發之後,硬吹一發的後時代我們做的事情是什麼?
link |
然後再講說我們怎麼控制TTS語音合成合出我們要的聲音。
link |
好,我們先講過去在還沒有硬吹一發的時候,人們是怎麼做語音合成的。
link |
其實在18世紀就有人嘗試過語音合成了啦,不過那個是太久遠以前的東西,我找不到任何的demo。
link |
那我找到語音合成最早的demo是1939年有一個東西
link |
叫做Voder,Voder這個東西它是在紐約的世博會上展示的一個
link |
語音合成的系統,它聽起來像是這樣的。
link |
Let's see how you put expression into a sentence. Say she saw me with no expression.
link |
She saw me. Now say it in answer to these questions.
link |
Who saw you? She saw me. Whom did she see? She saw me.
link |
Did she see you or hear you? She saw me.
link |
所以你會看到說1939年就有語音合成,不過這個語音合成感覺有點像這種
link |
那有一個知名的語音合成系統是用IBM的computer做的,它是1960年代
link |
在Bill Lab做的,它是一個最早的早期的語音合成的demo
link |
它應該是最早嘗試讓機器做唱歌這件事情。
link |
你可以在網路上找到當年的demo,當年的demo聽起來像是這個樣子。
link |
Mr. Watson, come here, I want you.
link |
To be or not to be, that is the question.
link |
Whether it is nobler in the mind to suffer the slings and arrows of outrageous fortune
link |
or to take arms against a sea of troubles,
link |
and by opposing end them, to die, to sleep.
link |
Singing in purely physical terms is essentially a matter of pitch and timing.
link |
In the next selection, the computer sings a familiar ditty.
link |
Daisy, Daisy, give me your answer too.
link |
Yes, Daisy, all for the love of you.
link |
It won't be a stylish marriage. I can't afford a carriage.
link |
But you look sweet upon the seat of a bicycle built for two.
link |
早年的1960年代的語音合成,合成出來的聲音就比較像是我們一般
link |
所以我們通常想像說機器人講話就要講說我是機器人這樣的感覺。
link |
這個感覺聽起來才像是機器人講話。其實今天語音合成合出來的聲音都太真實了。
link |
它的機器感實在太少了。我相信過幾年就會開始有人做一些復古的語音合成。
link |
明明可以合出很好的聲音,但是我們用Voice Conversion的技術把它轉成奇怪的機器人風格。
link |
也許有人就會開始說,這樣有什麼用呢?這樣的用處就是也許機器合出來的聲音
link |
太像真人會讓人聽起來不舒服,所以故意給它合一些機器人的聲音,讓大家聽起來
link |
會比較舒服。剛才我們聽到說這個iVM的電腦
link |
Daisy這首歌,其實在一個知名的科幻電影《太空漫遊2001》裡面
link |
就有致敬了類似的橋段。在《太空漫遊2001》裡面有一個人工智慧的電腦
link |
叫做HAL,中文翻譯成HAL,英文是HAL
link |
HAL就是iVM的字母-1,HAL就是iVM-1
link |
HAL其實它也有出現在《腦念涅羅》裡面
link |
《腦念涅羅》這不重要,它出現在《太空漫遊2001》裡面
link |
這個人工智慧最終想把人類都殺了,但是卻被人類反殺
link |
在臨死之前,他就唱了一首歌,是他這一生第一次學到的歌,就是那個Daisy
link |
HAL就是在致敬iVM這台電腦。而這個iVM這個電腦
link |
是那種需要打卡的電腦,有房間那麼大的電腦,我相信在座各位可能都沒有
link |
真的用過這種電腦,我也沒有用過,我只是在灣區的計算機博物館看過
link |
那邊還有實際有iVM的員工在操縱那些電腦
link |
那個電腦是有人在展示的,然後有一個老爺爺在那邊
link |
他說他是一個iVM的員工,然後展示操作那個電腦可以看
link |
給你看,這樣我覺得說也許50年之後我就要去科工館做這個工作啊,然後就是展示說
link |
怎麼train deep learning給大家看啦,然後就會拿出一個2080Ti,然後所有人就很震驚
link |
哇,居然有這麼大的processing unit,SPU現在都是像米粒一樣大,然後就會講一些
link |
這個2080Ti它的processing能力只有你指甲上的SPU的1%喔
link |
然後大家就哇,這樣,然後2080Ti上有個風扇,然後就轉起來了
link |
哇,上面居然有風扇,好可怕喔,會不會把人捲進去啊,然後我就開始寫個程式
link |
Import個TensorFlow,然後大家就覺得,哇,太可怕了,這個人居然是用手寫程式
link |
因為那時候人都用意念在寫程式了,就是這個樣子
link |
你可能覺得用意念寫程式也許太超過了,但是50年後至少應該用natural language寫程式吧
link |
雖然不過現在教授都是用natural language在寫程式了
link |
好,這不太重要,好,那下一個這個語音合成,就一般如果你是商用的系統啊
link |
是用一個叫做concatenative approach
link |
那concatenative approach是什麼意思呢,這個概念非常的簡單,一講你就聽得懂了
link |
如果今天你要合一段聲音出來,比如說你要機器說你好嗎
link |
可是你可能會想說,直接把聲音訊號挑出來
link |
再串起來會不會聽起來很怪啊,會不會聽起來很不自然啊,會
link |
所以怎麼挑出聲音訊號讓他們串起來是順的
link |
怎麼挑出合適的訊號讓他串起來是順的,這個就是一個可以研究的問題
link |
所以很多研究都集中在怎麼挑出聲音訊號
link |
讓他聽起來是順的,這個就是這個投影片上寫的
link |
Concatenative Loss,怎麼把它接起來
link |
完全可以想像,它其實沒有你想像的那麼容易,因為你要把這個concatenative的部分做好,其實沒有你想像的那麼容易
link |
不過這個技術你完全可以想像大概是要怎麼做的
link |
在網路上不是有很多影片都是把政治人物的聲音就截一個一個詞彙下來就可以讓他說出他本來
link |
那你得要在Database裡面有接近那個人的聲音才辦得到
link |
你要合男生的聲音那你的Database要有男生的聲音
link |
你要合女生的聲音你的Database要合女生的聲音
link |
很豐富的他講的話要很有異樣頓挫要非常豐富那你必須要收集一個
link |
那你在離線的時候要做合成的時候顯然你的Local端必須要存在一個非常大的資料庫才有辦法
link |
所以Concatenative這個做法
link |
進入了機器學習的時代以後大家就會想說那能不能夠用Machine Learning的方法
link |
Deep Learning Base
link |
那其中最知名的一套這種Parametric Base的語音合成的Toolkit
link |
但是這種Parametric Base的方法
link |
這個下面是這個從HTS的官網上截下來的圖啦
link |
那你可能會想像說HAM就是一個Generative的Model啊
link |
我們今天HAM的聲音不就從一個Hidden Mark of Model裡面去
link |
但是你想想看假如我們今天叫HAM Generate聲音訊號
link |
因為每一個State都是一個固定的Gaussian Distribution
link |
固定的Gaussian Distribution裡面
link |
一個Gaussian Distribution裡面機率最大的Sample
link |
那如果你今天要讓機器產生他覺得機率最高的那段聲音
link |
其實會有很長一段聲音都是同樣的Vector
link |
當然有用HAM DMN的方法來做Speed Synthesis
link |
他們不是M2M的他們叫Parametric Approach
link |
那在進入M2M的時代硬券一發之前有一個最接近硬券一發但
link |
第一個Module叫做Graphing to Phoning的Module
link |
Graphing to Phoning的意思是說給機器看一段文字的時候
link |
舉例來說你輸入一串字母你輸入CAT這三個字母
link |
需要由Graphing to Phoning這個Module來判斷
link |
假設今天Graphing to Phoning這個Module把CAT判斷說他就是發音
link |
一個叫做Duration Prediction的Module
link |
這個Duration Prediction Module他做的事情就是
link |
舉例來說他可能說這個K我要發0.1秒
link |
這也是一個Network這個Network自己決定說每一個封鈴他要唸多長
link |
還有一個東西叫做Fundamental Frequency的Prediction Module
link |
這個Fundamental Frequency是什麼呢
link |
這個Fundamental Frequency
link |
那這邊Output就Output個XX
link |
好那你這邊Output了Fundamental Frequency
link |
把這三個東西湊起來丟到語音合成的一個Module
link |
這也是一個Network他吃這三個東西當作輸入然後就吐出一段聲音
link |
只要把他串起來M to M的Trend
link |
M to M的硬Trend一發的Module
link |
不過在第一版的Deep Voice裡面呢
link |
不是M to M的Trend的每一個Module是分開Trend的
link |
Deep Voice的第一代就是一個兩棲類他已經爬到陸地上
link |
休息休息一下我們11點半再回來然後接下來呢就要講真正
link |
好那接下來呢我們要來講Tekotok
link |
Tekotok的這個Teko是什麼意思呢Teko呢
link |
是一種食物啊就可能中文翻譯成墨西哥捲餅吧反正就是類似這樣子的
link |
沒有什麼意思這個Tron只是為了要增加他的科技感而已
link |
王宇軒我有聽過他的talk他的talk裡面有說這個Tekotron本來並沒有要叫Tekotron
link |
再加Tron一樣沒有任何意思就是為了要增加他的科技感
link |
後來覺得叫做Tekotron更有感了所以就叫做Tekotron
link |
然後在這個文章裡面呢他們還很有趣的加了一個註解
link |
是喜歡Susie的這樣子他們很認真的告訴我們他們的食物偏好是什麼
link |
那Tekotron他有兩個版本第一個版本發表在InterSpeech的17年的InterSpeech
link |
就已經有一些end-to-end TTS的嘗試
link |
跟Waveform啊他其實只差了一個face的資訊
link |
所以你要從Spectrogram轉成Waveform
link |
你不見得需要非常強的recorder你不見得需要Machine Learning Base的recorder
link |
你用一些raw base的方法比如說Graphenly
link |
你就可以直接把Spectrogram
link |
那其實在Tekotron之前就已經有一些end-to-end的語音合成的嘗試
link |
舉例來說有人嘗試說直接inputphony
link |
他的acoustic feature
link |
那phony跟character比起來當然還是差了一層啦
link |
deep voice的第一個版本的時候他就有一個module
link |
先把character轉成phony然後再去做接下來的事情
link |
所以用phony可能還是比character還要容易一些
link |
是straight的acoustic feature
link |
也就是他不是一般的acoustic feature
link |
所以acoustic feature要丟到一種叫做straight的recorder裡面
link |
那還有另外一個嘗試叫做character-to-wave
link |
那如果是character-to-wave的話呢
link |
是sample RN這個recorder的
link |
所以過去已經有一些end-to-end TTS的嘗試
link |
那Tabletron呢他是最狂的他的輸入跟輸出是最end-to-end的
link |
等於就你直接把文字丟進去沒有做任何處理
link |
希望never自己知道這每一個character每一個字母
link |
輸出他雖然不是直接產生waveform
link |
spectrogram跟waveform中間也只差了一個linear的transform而已
link |
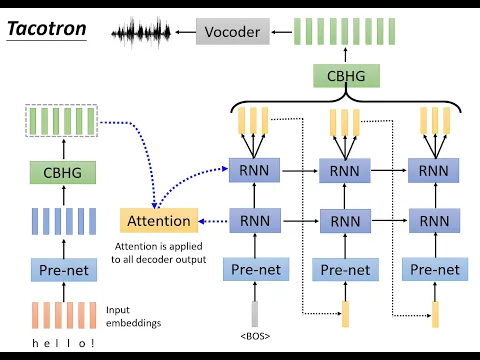
好那Tabletron他到底是什麼樣的network架構呢其實
link |
講的大致一點大略說來他就是sequence-to-sequence model
link |
那除了這個typical sequence-to-sequence model加attention的架構以外他還有一個
link |
post-processing的架構
link |
好那接下來呢我們就是來看Tabletron裡面的每一個module
link |
轉成latent representation
link |
再丟給attention的module
link |
所以這個encoder他扮演的角色啊
link |
類似graphic-to-phonic的module
link |
我們剛才有看到說在deep voice裡面有一個graphic-to-phonic的module
link |
轉成音速然後接下來的module才知道根據音速要怎麼發音
link |
告訴接下來的decoder的module還有attention的module說
link |
所以encoder的輸入啊直接就是字母
link |
好那這些字母呢通過一個transform變成input的embedding
link |
然後通過一個prenet沒有什麼神奇的就是幾層Fully Connected
link |
Feedforward Network那prenet裡面呢
link |
會再丟給一個叫做CBHG的module
link |
好這個CBHG的module是什麼樣子呢
link |
他這個是CBHG module input
link |
然後他通過這個1D的convolutional的filter bank也就是說他有一大堆的filter
link |
receptive fill啊大小還是不太一樣的
link |
好接下來呢他有一個max pooling along time
link |
這個smoothing這樣的動作讓相鄰的feature比較像一點有點像是平滑化這樣的動作
link |
然後這邊有一個1D convolution layer然後做一個residual的connection
link |
然後再把他丟給highway的network然後再丟給bi-directional的GRU然後最終呢
link |
如果這部分你聽得不是很懂的話反正沒有關係就記得說
link |
輸出就是每一個character變成一個相鄰就結束了
link |
convolutional的bank
link |
好那我們這邊呢就不打算細講CBHG啊你可能會問說為什麼要用CBHG啊要用CBHG
link |
可以不用CBHG在第二個version的tabletrump裡面CBHG就默默的消失了
link |
input文字然後呢產生character embedding再通過三層的convolutional layer
link |
再通過bi-directional的LSTM
link |
不是非常必要的所以我們就不會花太多時間講CBHG這個東西
link |
那今天在做語音合成跟語音辨識他們的attention有一個共同的地方就是
link |
等一下我們之後還會再來回頭來看attention的問題
link |
今天你輸入呢這一個timestamp的東西這一個
link |
character他對應的embedding
link |
今天在這個attention的metric上
link |
就代表了encoder輸出的一個embedding
link |
有點像是model duration
link |
我們剛剛在講deep voice的時候我們看到說
link |
Machine需要去預測說每一個phony
link |
每一個character所代表的embedding
link |
如果你今天你的attention的matrix長得像是這樣子
link |
如果你今天感覺怪怪的他不是一條斜線感覺很糊那往往就代表你今天合出來的結果
link |
你的model在訓練的時候出了什麼問題
link |
這個是attention的部分我們之後會再細講
link |
他就是一般sequence to sequence model裡面的decoder
link |
你丟一個zero vector進去代表其實
link |
產生attention的context vector
link |
decoder有一個比較特別的地方是
link |
所以我們今天在訓練的時候我們就會要decoder呢
link |
male spectrogram的vector
link |
那在這個decoder的第一版裡面這個R
link |
那為什麼要讓這個decoder一次產生數個vector呢
link |
為什麼不是像一般的sequence to sequence model decoder一樣一次只產生一個vector呢
link |
每一個male spectrogram這種acoustic feature裡面的vector
link |
才代表了非常短的一段聲音訊號通常是代表了0.01秒的聲音訊號
link |
所以如果你今天要產生一段一秒鐘的聲音
link |
你要產生100個vector才是一秒鐘的聲音
link |
所以今天這個sequence to sequence的model
link |
一般sequence to sequence model應用的情境不一樣
link |
我們之前在講sequence to sequence model的時候
link |
你把sequence to sequence model用在語音辨識上的時候
link |
如果你要把decoder把sequence to sequence model用在語音和聲上
link |
超過上百個可以產生超過上百個vector的sequence
link |
那RNN在產生這種上百個vector的時候在產生這種非常長的sequence的時候
link |
你就要花多長的時間你要花多少的timestamp
link |
所以就有了這樣子的一個一次產生R的frame產生R的vector的想法
link |
如果你這個R是一次產生五個vector
link |
那你今天decode的sequence長度
link |
所以在今天在Tacotron裡面一個有趣的設計是
link |
Tacotron第一代的一個非常自豪的獨特的設計
link |
所以就跟一般的decoder一樣也沒一次產生多個vector
link |
好那這個decoder在第一個time step的輸出啊會變成第二個time step的輸入
link |
認為在第一個time step你是一次輸入三個vector
link |
當作下一個time step的輸入呢
link |
有各種不同的做法你可以直接把三個vector串起來當作下一個time step的輸入
link |
不過在第一代的Tacotron裡面就用了非常簡單的設計把最後一個vector
link |
如果你一次產生三個vector把第三個vector當作下一個time step的輸入
link |
把第二個time step吃一個vector當作進去然後就吐出接下來要產生的三個vector
link |
然後再把最後一個vector當作下一個time step的輸入
link |
就是Tacotron的decoder
link |
好那這個pre-net裡面呢一樣要有抓抱這個pre-net裡面的抓抱呢等一下會看到說它
link |
今天在訓練decoder的時候跟做語音辨識一樣我們一樣需要
link |
如果我們用teacher forcing
link |
每一次機器在產生sequence的時候呢
link |
它都會看到正確的答案但是因為在測試的時候是沒有正確的答案的啊
link |
所以會造成訓練跟測試的一個mismatch
link |
反正在Tacotron裡面的decoder你的pre-net裡面有抓抱
link |
Schedule sampling一樣
link |
它雖然說你這邊在training的時候輸入的是正確答案
link |
在training的時候你輸入的是正確答案那pre-net裡面有一些抓抱它可以模擬你在測試的時候
link |
在做這個decoder的時候你還要有一個module去決定說
link |
我們之前在講語音辨識的時候知道說我們只要產生一個特殊的token這個特殊的token代表
link |
那RNN decoder就不會再decode東西了
link |
在語音合成的時候我們產生出來的東西並不是
link |
token並不是token是continuous的vector
link |
所以decoder怎麼知道什麼時候應該要結束呢
link |
這個module叫做我們要不要結束了
link |
那這個module就是一個binary的classifier
link |
它把RNN的hidden layer把它接出來把RNN的
link |
memory裡面輸出的值把它接出來丟到這個classifier裡面
link |
然後這個classifier就去判斷說現在
link |
如果這個classifier判斷不要結束
link |
好那RNN的輸出就丟到下一個timestamp
link |
好那RNN的輸出再丟到下一個timestamp
link |
再產生新的output再判斷要不要結束現在要結束了
link |
這個綠色的module它就是一個binary的classifier
link |
它吃RNN的hidden layer然後
link |
決定說現在要不要結束它output就是一個數值
link |
就結束小於0.5就是不結束大於0.5就代表結束
link |
在PanelTron裡面的decoder之後啊還有一個
link |
Post-processing的network
link |
這個Post-processing的network是什麼呢
link |
這個Post-processing的network啊
link |
它也是一個CBHG在第一代裡面是一個CBHG在第二代裡面呢就是一堆的
link |
這個CBHG啊它會把RNN輸出來的這些vector當作輸入
link |
那為什麼我們要把RNN的輸出丟到CBHG裡面再吐出另外一排vector呢
link |
這個Spectrogram裡面的這些acoustic feature
link |
所以今天每次它都只能夠看前面已經產生的vector然後產生後面的vector
link |
再產生新的vector以後它覺得想要回頭過來改
link |
那已經沒有機會了你看到後面的東西覺得之前產生的不太好想要做來改
link |
這個後處理的network再給你一次修正的機會
link |
整個句子都看過把整個句子讀進來再產生
link |
其實有兩個training target
link |
這兩個training target在
link |
第一代Tacotron跟第二代Tacotron裡面都有
link |
它的兩個training target是這樣子
link |
我們會希望RNN的decoder輸出來的
link |
就是male spectrogram
link |
跟正確答案我們訓練這個TTS的時候我們有正確答案嘛有pair的data有文字跟
link |
所以我們希望說RNN的decoder輸出來的這段聲音訊號
link |
male spectrogram跟你光tube正確答案越接近越好
link |
這個RNN的輸出通過CBHGCBHG是non-codal的它可以看整段聲音訊號
link |
也要跟male spectrogram越接近越好
link |
這個CBHG的輸出要跟male spectrogram越接近越好還是跟linear spectrogram越接近越好
link |
而現在TracTacotron的時候你就是同時minimize
link |
輸出的是male spectrogram
link |
去合出聲音的Acoustic feature
link |
我們產生male spectrogram或linear spectrogram以後它沒有辦法馬上聽
link |
有一個module就是可以吃Acoustic feature
link |
然後這個Acoustic feature會產生聲音訊號
link |
那在第一代的TracTacotron裡面
link |
它是一個raw base的vocoder
link |
它是一個network base的vocoder
link |
那TracTacotron做出來的結果
link |
我們來看一下第一代跟第二代的TracTacotron的結果
link |
我們現在看第一代的TracTacotron
link |
Mean Opinion Score
link |
那這個Mean Opinion Score MOS是什麼呢
link |
Parametric Approach
link |
Concatenative Approach
link |
所以如果你看第一代的TracTacotron
link |
它是贏過了過去用Machine Learning做出來的用Deep Learning Based Approach做出來的Parametric Approach
link |
但它贏不過Concatenative Approach
link |
所以Concatenative Approach的分數還是比較高的
link |
好進入了第二代的TracTacotron以後啊
link |
我們來看一下Parametric Approach
link |
這個分數我重新評啦不同人評分數本來就不太一樣嘛
link |
Concatenative Approach
link |
但WaveNet的方法不完全是end to end的
link |
因為它要給它一些Linguistic的feature
link |
你需要把輸入的文字做一些很複雜的處理以後
link |
才能丟給WaveNet去產生聲音訊號
link |
就是原來的原始的聲音不是語音合成的聲音
link |
神奇的是第二代TracTacotron的分數
link |
第二代TracTacotron的分數
link |
不只贏過了Concatenative Approach
link |
那為什麼第二代的TracTacotron這麼強呢
link |
其實第一代的TracTacotron跟第二代的TracTacotron都是end to end的
link |
都是Sequence to Sequence的model加上Attention
link |
那為什麼第二代的TracTacotron
link |
所以Vocoder其實扮演了蠻關鍵的角色
link |
如果一樣是第二代的TracTacotron
link |
你產生Linear的Spectral Grain以後用GL
link |
用Graphene Lin的這個Vocoder
link |
你的Analysis Score是3.9
link |
如果你今天不是Linear加WaveNet
link |
而是用Mirror Spectral Grain當作WaveNet的輸入的話
link |
把Graphene Lin換成WaveNet就從3.9暴增到
link |
因為Graphene Lin其實他沒有
link |
New Wave Network Based的方法他比較強他可以
link |
今天這邊還有一個有趣的問題就是WaveNet啊他是認出來的
link |
所以你今天在Train WaveNet的時候你需要一些Training Data
link |
那Train WaveNet這種Vocoder啊
link |
就是就跟你一般訓練一個Network是一樣的你就是需要輸入跟輸出啊你要給他Acoustic Feature當作輸入
link |
正確的Ground Truth的Waveform當作輸出然後給他這樣子Acoustic Feature
link |
跟Ground Truth的Pair Data
link |
所以在Tackle From 2裡面有一個很有趣的實驗是說
link |
我們把這個Tackle From合成出來的Spectrogram
link |
用真正的聲音訓練出來的WaveNet
link |
這個Tackle From合成出來的Spectrogram去訓練WaveNet
link |
這個Tackle From合成出來的Spectrogram
link |
其實Tackle From合出來的那個Spectrogram跟真正的Spectrogram
link |
你會覺得沒有什麼差別,但他還是有一些微妙的差異
link |
真正的Spectrogram跟Tackle From合成出來的Spectrogram還是有一些微妙的差異的
link |
產生出來的Spectrogram做訓練,讓WaveNet知道說現在Tackle From產生出來的Spectrogram長什麼樣子
link |
Inference的時候,也就是測試的時候
link |
Tackle From在Inference的時候要加抓包
link |
Tackle From在Inference的時候要加抓包
link |
Tackle From在Inference的時候要加抓包
link |
為什麼這件事情這麼奇怪呢,因為我們在講抓包的時候,你記不記得在Machine Learning課在講抓包的時候
link |
沒有人測試的時候在抓包的,訓練的時候要抓包讓你的model比較robust比較不overfitting
link |
如果有人測試的時候要抓抓抓包我就會斥責他
link |
Tackle From在測試的時候,在testing在用他的時候,你要把抓包加在你的decoder的primate裡面
link |
那我們現在來聽一下Tackle From的聲音,一般Tackle From
link |
Tackle From的聲音聽起來是這樣子的
link |
聲音可能有一些不自然的地方,不過這主要是來自於vocoder,那這邊vocoder用的是
link |
Neural Network Based Vocoder的話,聲音聽起來就會自然很多
link |
但是如果今天你把primate的抓包關起來
link |
在natural language的generation,在NLG裡面,當你用RNN要生成句子的時候
link |
那有人嘗試用GPET2來生成句子的時候,發現說
link |
所以我們今天在真的要用GPET2產生句子產生文章的時候
link |
所以我們不一定會是從每一個time step選擇機率最大的那個詞彙出來
link |
你會根據GPET2 output的那個distribution來做sample
link |
根據distribution來sample詞彙
link |
有時候sample出機率最大的token當作輸出
link |
有時候不見得輸出機率最大的token
link |
那每一次Tagotron output的東西
link |
那可能就會遇到跟用GPET2生句子的時候一樣的問題
link |
而在一般NLG裡面因為輸出是一個distribution
link |
你可以透過從那個distribution做sample
link |
因為我們的輸出不是distribution
link |
如果你把抓爆加在pre-net的地方
link |
怎麼用Tagotron做台語的語音合成呢
link |
這個台語是衰蝦應該就是美好的聲音的意思
link |
你就可以直接拿來訓練一個Tagotron
link |
你其實不知道他的台羅拼音是長什麼樣子啊
link |
再把台羅拼音丟到Tagotron裡面
link |
這邊呢我們就來做一下台語的聽力測驗啦看你聽不聽得懂Tagotron
link |
我不知道第二句這個講的台語是不是對的啦那如果這句話講的台語是不對的你再告訴我好了
link |
沒有一拳無法解決問題如果有那就是兩拳