back to index
[DLHLP 2020] Vocoder (由助教許博竣同學講授)
link |
好,那我是助教許柏駿,然後今天要跟大家分享的是neurovocoder的部分。
link |
首先呢,會簡單介紹一下這個主題在幹嘛。
link |
然後會講幾個neurovocoder常見的模型。
link |
好,首先之前我們就講過TTS model跟voice conversion model。
link |
那之前在講的時候有提到說我們是把我們的TTS model是把text當作input。
link |
最後再透過vocoder轉成聲音訊號。
link |
所以他的output不是直接是聲音訊號。
link |
那voice conversion的model也是一樣。
link |
是先input一個spectrogram,A語者的spectrogram可能轉成B語者。
link |
那他也是聲音的特徵,還不是聲音訊號。
link |
最後我們還是要透過vocoder才可以轉成人聽得到的聲音訊號。
link |
那在這裡使用的聲音特徵大部分都是spectrogram。
link |
那接下來講一下為什麼我們把spectrogram沒辦法直接轉成聲音還要再透過一個vocoder呢?
link |
這邊就要先講一下我們的spectrogram是從何而來的。
link |
你要從裡面找出spectrogram,你必須先把它通過short time Fourier transform。
link |
那通過這個SDFT之後呢,你會得到一個對應跟時間還有頻率相關的函數。
link |
那我們知道我們做完Fourier轉換之後,它裡面的值都是負數嘛。
link |
那負數就可以表示成A exponential iθ的形式。
link |
前面這個A就是正負,那θ就是它的相位。
link |
那表示成這個形式之後呢,一樣不同的時間、不同的頻率,它會有自己的正負跟自己的相位。
link |
那如果我們把這個A畫出來的話,就是剛才我們提到的spectrogram。
link |
所以我們之前一直提到的spectrogram這個聲音的特徵,其實只是正負的部分而已。
link |
你要還原一段完整的聲音,你還缺少了相位的資訊。
link |
那為什麼我們之前生成的時候都只生成spectrogram而已,不順便就生成個phase呢?
link |
我們把這個phase畫出來看,會發現它長得跟雜訊就是差不多像。
link |
所以你要直接生成這個phase,或是從spectrogram去還原這個phase,都是非常困難的。
link |
那你可能會問說,這個phase真的有那麼重要嗎?
link |
會不會它就是隨便給,反正你spectrogram很好,還原出來的聲音訊號就很好了呢?
link |
那我們把這段聲音中的phase設成0之後,它的聲音就會變成這樣。
link |
那如果把phase設成隨便一段Gaussian noise之後,它的聲音會變成這樣。
link |
可以看到後面這兩個phase隨便給的時候跟原本的聲音其實差異還蠻大的。
link |
所以到這邊我們可以知道phase這個東西非常重要,但它不好生成。
link |
那我們到底要怎麼生成我們聽得到的聲音的波形呢?
link |
那在TTS或voice conversion的model,它生成的是聲音的特徵。
link |
那我們現在要生成波形,我們就不去重建它的phase了。
link |
我們直接從這些聲音特徵用一個vocoder直接生成波形。
link |
那比較傳統的方法有一個叫做Griffin Link的演算法。
link |
它是可以直接從spectrogram去重建聲音訊號。
link |
這個是真實的錄音檔,那可以看看Griffin Link重建之後的結果。
link |
可以發現它的聲音還是有一點點悶悶的,聽起來怪怪的。
link |
那最近就是很流行有什麼問題就拿neural network來硬 train一發嘛。
link |
所以假設我們今天用neural network來當作vocoder,就叫neural vocoder。
link |
它的input就是spectrogram,output希望就是聲音的waveform,就是它的波形。
link |
那接下來要講的是,為什麼我們要把vocoder當作一個獨立的研究主題呢?
link |
我們為什麼不把vocoder接在TTS上,然後end-to-end硬 train一發就好,或接在VC上硬 train一發就好?
link |
原因是因為這個vocoder我們是拿來做spectrogram跟聲波的一個mapping嘛。
link |
所以今天不管你spectrogram從何而來,我應該都可以把它mapping成一個完整的聲音。
link |
所以如果你有一個訓練好的vocoder的話呢,你可以把它應用在TTS上面,用在VC上,用在speech enhancement上,都是沒問題的。
link |
那如果你今天把vocoder,就是聲程波形的任務獨立出來的話,前面專注在處理spectrogram,就是比較簡單的任務上。
link |
好,那接下來就會介紹一些常見的vocoder的模型。
link |
首先是webnet,webnet是最早最早被提出來直接聲程波形的model。
link |
那你現在如果去查Google的TTS,它會告訴你它裡面用了webnet的技術。
link |
那webnet呢,它主要就是一個autoregressive的model。
link |
這是一段聲音訊號的波形,就是我們聽到的聲音訊號的波形。
link |
那它裡面其實就是一堆點串起來的結果,那每一個點有,比如說這是比較大的值,這是比較小的值,那這就是我們聽到的聲音波形。
link |
那autoregressive model啊,你今天想要output Xt的data的時候,你必須要拿X1到Xt-1當作input。
link |
那你要output Xt加1的時候,你要拿X1到Xt當作input來output下一個時間的data。
link |
那如果畫成動態圖的話,就像右邊這樣子,下面是input,上面橘色部分是output。
link |
那可以看到,上面橘色的output出來之後,馬上被拿去當作input,再產生下一個output。
link |
那在WebNet裡面,它主要的組成呢,是causal convolution,就是一堆CNN,等一下會詳細介紹。
link |
好,這邊講一下WebNet它的model架構。
link |
首先呢,這底下的input呢,指的就是剛剛我們說X1到Xt-1的data。
link |
那這邊input進來之後呢,會經過causal convolution跟dyadic convolution,這等一下會介紹。
link |
那這邊會通過不同的activation function,這個XX是點程的意思。
link |
就是kernel size是1的CNN,那這樣呢,叫做一個layer。
link |
這個layer的output呢,會傳到下一個長得一樣的layer。
link |
那在這裡面,每一個kernel size是1的convolution,算出來的東西會再拉出來,相加起來,這叫做skip connection。
link |
所以會通過relu,1-1 convolution,relu,1-1 convolution,最後通過softmax,就產生我們的output。
link |
這是很簡單的講一下WebNet的模型架構。
link |
那首先我們要來細講的部分是這邊的softmax。
link |
在WebNet裡面,它的input跟output都是one-half vector,它就不是scalar。
link |
所以我們剛剛說聲音訊號,一個點一個點是一堆的數字嘛。
link |
但它這邊全部把它轉成one-half vector。
link |
那轉成one-half vector之後呢,我們就可以把整個產生聲音的問題,寫成下列的式子。
link |
假設你今天給了x1到dxt-1的data當作input。
link |
那你的model要做的事情呢,就是output一個機率的分布,告訴你dxt的data最有可能是哪一個。
link |
那在這裡會遇到一個問題,我們的聲音的data儲存在電腦裡面通常是用16bit的整數。
link |
那16bit的整數的範圍就會是-32768到32767。
link |
也就是說呢,假設你用16bit的整數來train這個model的話,
link |
你的WebNet就會變成一個有65536個class的classification的問題。
link |
那這65536顯然是很大嘛,對model來說當然是不好學。
link |
所以呢,我們希望把這65536個class壓到256個就好了,也就是16個bit壓到8個bit。
link |
那最簡單的方法就是把你input的範圍從-32768到32767壓到0到255。
link |
這樣你就從16bit的整數變成8bit的整數了。
link |
那你當然可以很直覺的用linear的mapping直接把它對應過去。
link |
我們會先把這個-32768到32767的範圍把它壓到-1到1,這邊是linear的過程。
link |
那在這裡會通過一個function,它叫MULO的algorithm。
link |
那它的function就寫在下面給大家參考。
link |
這個sine函數是input是負的時候它會產生-1,是正的時候產生1,然後是0的時候產生0。
link |
那這MULO呢,因為我們今天希望最後出來的是8bit,所以我們MULO在255。
link |
那我們把16bit的整數壓到-1到1,然後再通過MULO之後它的範圍還是-1到1。
link |
那通過MULO之後我們就可以把它拉回到0到255,然後再把它變成整數,它就是一個8bit的結果。
link |
我們今天把16bit變成8bit是一個quantization的過程。
link |
那這個MULO是以前在訊號處理裡面為了要減少quantization error而提出來的演算法。
link |
那它的效果就是會比你直接linear mapping再好一些。
link |
好,接下來講WebNet裡面最主要的架構,就是一堆CNN。
link |
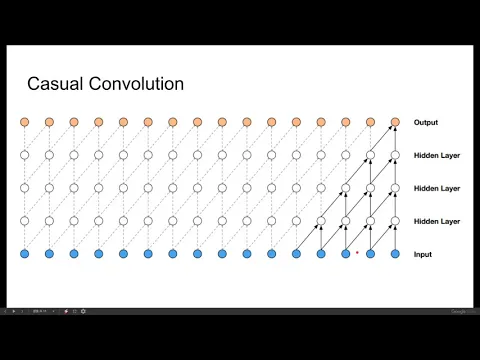
先講什麼是causal convolution。
link |
在這張圖裡面,這個藍色是input,橘色是output,那裡面是每一個hidden layer。
link |
那這個就是一個kernel size是2的CNN,所以它是一次吃兩個input,output一個,然後一次吃兩個,然後output一個。
link |
那你今天causal convolution的意思是說,我在dt秒的output,我看到的data最多只會到dt秒,我不會看到未來的資訊。
link |
所以這個CNN在掃的時候就會像一個直角三角形的樣子。
link |
那另外一個東西叫做dilated convolution。
link |
左邊這個是一般的CNN,藍色是input,綠色是output。
link |
這個灰色在動的就是CNN的kernel,它是3x3的。
link |
那我們可以看到這個kernel每掃過一個地方就會拿出9個點,然後跟它的kernel做運算之後,output一個數字來。
link |
那這是一般的convolution的情況。
link |
那右邊這個是有加dilation比較大一點的CNN。
link |
可以看到它的kernel size一樣是3x3,但是它的9個點就不是相鄰的排在一起了,它是中間有間隔的。
link |
那如果把causal跟dilation這兩件事把它合在一起就會變成dilated causal convolution。
link |
那畫成圖就是剛剛大家看到那個動圖了。
link |
可以看到這邊第一層它做的CNN是相鄰的,然後這邊會空一格,然後再上去會空三格,然後再來就是空七格這樣。
link |
那做dilation這件事有什麼好處呢?
link |
右邊這個,下面這個圖是一般的causal convolution的樣子。
link |
那一樣下面是input,上面是output。
link |
大家可以看到說我今天產生橘色這個output,我看到了哪些input,就是這五個點嘛。
link |
所以我有這五個點,我就可以產生一個橘色的output。
link |
可是如果你今天是dilated causal convolution的話呢,你一樣output這個timestamp的這個點,我一樣疊四層。
link |
它看到的input data卻有16個之多。
link |
那在這裡面的dilation分別是1,2,4,8,把它這樣上去。
link |
那你就可以發現同樣的深度,有加dilated的CNN,它可以exponential的增加它的input看到的範圍。
link |
也就是這邊講的receptive field,會把它拉得很寬。
link |
今天我們說一段聲音訊號,比如說一秒鐘有一萬六千個點。
link |
那你如果產生某一個點,只看了這短短的相鄰的幾個點就來產生這裡,那是看非常非常local的資訊的。
link |
那如果你用dilated的CNN的話,在疊一樣多層的情況下,你可以看到比較長時間的資訊,再來決定你這個點的output要是多少。
link |
好,那剛才我們就講完了causal convolution跟dilated convolution的部分。
link |
那剛才也提到了這邊會有一個residual,然後每一層的1-1 convolution之後結果會拉出來,這叫skip connection。
link |
最後會通過右邊的運算產生我們的output。
link |
剛剛有提到這邊通過dilated convolution的output會分別通過sigmoid還有hypertangent這兩個不同的activation function,最後點成出來。
link |
那這個東西有一個名字叫做gated activation unit。
link |
我的input x通過兩個不同的CNN之後,過不同的activation function,最後點成,然後z就是output。
link |
好,到這邊其實已經把webnet的架構大致上講完了。
link |
但不知道大家有沒有發現我們到現在都還沒提到spectrogram。
link |
在webnet裡面input,下面的input是前幾個time state的data,x1-xt-1,output是xt。
link |
那我們今天要拿來當vocoder的時候,我們的spectrogram要從哪裡塞進來呢?
link |
其實就是放在gated activation function的那邊。
link |
今天你如果用webnet產生聲音的時候,你可以給它一些額外的條件來限制它產生的聲音。
link |
那你今天丟進來如果是spectrogram,它是會隨時間變化的,我們就叫它local condition。
link |
那這邊用y來表示,那你不同的時間會有不同的聲音。
link |
那就跟x一樣,它會通過一個CNN,然後跟x通過CNN加起來,然後hypertangent。
link |
y會通過另外一個CNN,然後x也會通過另外一個CNN過sigmoid,那最後點成起來。
link |
那你如果今天給的condition不是像spectrogram這種,而是比如說speaker icon,
link |
那你如果今天給的condition不是像spectrogram這種,而是比如說speaker icon,
link |
而是比如說speaker id,你希望它產生某一個speaker的聲音,
link |
或者是你告訴它產生的是什麼語言,或者是今天講某一段話的什麼情緒。
link |
就是整段聲音裡面不變,維持一樣的condition的時候,我們叫它global condition。
link |
那這邊可能是一個值啊,或者是一個one-half vector之類的。
link |
好,以上就是webnet的架構,以及它如何拿來用作vocoder的部分。
link |
好,以上就是webnet的架構,以及它如何拿來用作vocoder的部分。
link |
那webnet是很早提出來,就是用NN來產生webform,直接產生聲音訊號的一個model。
link |
那它用了deleted causal convolution來達成這件事。
link |
但它這裡面有一個很大很大的問題,雖然它產生的聲音、音質一直都是非常好的。
link |
但還有一個問題,剛剛有提到它是auto-regressive model嘛。
link |
那在我們的聲音訊號裡面,一秒鐘就有16000個點。
link |
那表示說你要拿webnet來產生聲音訊號,產生一秒鐘的聲音訊號,你就要運算16000次。
link |
所以接下來提到的幾個vocoder啊,大部分都是想要解決這個生成速度很慢這個問題。
link |
那fft-net呢,它跟webnet一樣是auto-regressive model。
link |
那不一樣的是,它把webnet裡面的架構,那疊很深的一堆CNN改掉了,改得比較簡單一點。
link |
讓它每次運算可以簡單一點,可以算得比較快一點。
link |
好,那除此之外呢,它也提出了一些training跟生成的時候的技巧。
link |
那這個技巧呢,不只可以用在fft-net,是你要用auto-regressive來生成聲音都可以拿來用的一些小技巧。
link |
好,左邊這張圖呢,就是fft-net它運算時候的大概的流程。
link |
首先,這邊一樣是input,是x1到xt-1的data。
link |
那你今天input進來呢,在fft-net裡面,它會先把它切成兩段。
link |
那這兩段呢,會各通過一個CNN之後加起來。
link |
也就是這邊的第一條式子,通過不同的CNN之後加起來產生z。
link |
那產生z之後呢,它會通過relu,然後1-1 convolution,然後再relu,然後再傳到下一層。
link |
那也是在做一樣的運算,切一半,通過兩個CNN,然後加起來。
link |
那在這裡呢,你可以發現,假設我一開始input是8,它每通過一層,它的長度就會減半。
link |
那8,然後變4,然後變2,那這些還就會變1。
link |
那最後變成1的時候呢,就是這個model的output。
link |
它就會把它當成下一個time state,也就是xt當作output這樣。
link |
那一樣,就是你今天要把spectrogram拿進來當condition的時候要加在哪裡呢?
link |
今天我x會切成xl跟xr,我的spectrogram同樣會切成hl跟hr,然後通過不同的CNN之後跟前面這個加起來。
link |
那到這邊,其實fftnet的架構就是講完了。
link |
可以發現它比webnet簡單非常非常多。
link |
你不用在這邊疊一堆CNN,還有gated activation unit來達到同樣的效果。
link |
好,那接下來呢,講一下為什麼這樣可以達到跟webnet一樣的效果呢?
link |
大家可以看這個紅色的點,假設我今天要output這個紅色的點,它是看到前一層的哪兩個點呢?
link |
那同樣這兩個點的output是從哪裡來呢?
link |
可以看到它每過一層就會看的資訊就會張開變得更多一些。
link |
所以它跟webnet是一樣的,就是隨著你的深度增加,它看到的receptive field是exponentially的越來越大。
link |
好,接下來講一下在fftnet裡面提到的幾個訓練autoregressive的vocoder的一些技巧。
link |
首先第一個是zero padding,作者說你在train autoregressive model的時候,在你的聲音訊號前面加一些零,會讓訓練的時候比較穩定一點。
link |
那第二個是conditional sampling,這件事呢,前面我們提到webnet的output是一個分類問題。
link |
那你今天要如何選擇dxt的output應該是什麼值呢?我們通常是找機率最大的那個嘛。
link |
那作者說在這裡我們想要讓我們的output比較接近training data的distribution。
link |
所以根據不同的情況,我們有時候不是找機率最大的那個,我們是根據你output的機率去random sample一個值出來。
link |
好,那第三個小技巧呢是injecting noise,在webnet跟fftnet裡面它是autoregressive model嘛。
link |
那training的時候很簡單,它是teacher forcing,or input ground truth真實data的x1到xt-1,然後output,希望它的output越接近真實data的xt越好。
link |
但是我們真的拿來實際的情況在用的時候呢,我們的model,它的input,x1到xt-1都是之前model自己產生出來的。
link |
你可以想像如果這個model在第一個時間點產生了一筆很爛的data,然後在下一個時間點又產生了一筆不那麼好的data。
link |
這樣一直累積下去,它的model是不是會越來越爛,整個爛掉了這樣。
link |
好,所以injecting noise就是為了要解決這個問題,就是我在training的時候,我的input不要給那麼好的品質那麼好的data,會加一些noise到input x上面。
link |
好,那這件事呢可以讓你在生成的時候會穩定一點,產生的聲音會穩定一點。
link |
不過作者有說,就是你加了injecting noise之後,生成出來的聲音會有一點點的噪音,所以他就又用了以前訊號處理的方法來給它做denoising。
link |
好,就總結一下來說呢,FFTNet是把WebNet裡面的架構很大幅度的簡化,那它一樣是autoregressive的方法。
link |
那在原本的論文裡面,作者提到說FFTNet可以產生跟WebNet一樣好的、差不多好、幾乎一樣好的聲音,那用在一個比較快的速度。
link |
他說他們在CPU上可以達到real time,所謂real time就是假設你今天要生成一秒鐘的聲音訊號,然後花不到一秒鐘。
link |
這件事是作者說的,實際上在inferment的時候呢,網路上好像大家都做不太出來達到那個速度啊。
link |
不過,就是他的速度還是比起WebNet快上非常多。
link |
那他後面提出來的幾個訓練的技巧啊,也是非常有幫助的。
link |
下面就是附個分數的表,給大家參考看看這個幫助到底有多大呢。
link |
我們稍微提一下說,今天我們在做生成聲音的這個任務,比如說之前提過的TTS,Voice Conversion,包括這邊的Vocoder。
link |
我們通常沒有一個metric可以直接告訴你你生成的聲音有多好。
link |
我們測它有多好的方法呢,就是找一堆人來給聲音打分數。
link |
那在這叫MOS Test,那在這個MOS Test裡面呢,會找一堆人來給生成的聲音打分數打1到5分。
link |
所以這邊分數就是越接近5分就是越好。
link |
那可以看到原本的FFTNet,他的分數其實沒有比WebNet還要高。
link |
但是這兩個啊,這個有加的就是加了他的Training小技巧之後的結果。
link |
可以看到加了他的小技巧之後,這兩個分數都突飛猛進的暴增了。
link |
好,那第三個Model呢,我們要介紹的是WebRNN。
link |
那這個東西呢,也是Google提出來的。
link |
好,那WebRNN用一句話去概括就是,我們不要用CNN來Handle時間的資訊了,我們用RNN來處理這件事。
link |
好,在開始講WebRNN裡面的Model架構之前呢,我們先來講一下Softmax Layer的問題。
link |
前面提到,因為我們16bit的範圍會有6536種可能嘛。
link |
那這個做分類實在是太麻煩了,太困難了。
link |
所以我們會把它壓成8bit做256種可能的分類問題。
link |
那在WebRNN裡面呢,他並沒有把它變成只有256種可能,他是把16bit拆成兩個8bit。
link |
好,那就是你今天一個16bit的Data,我可以做兩次8bit的分類來達到16bit的結果。
link |
好,那這邊就叫一個叫做Course 8bit,一個叫做Find 8bit,分別就寫做CT跟FT。
link |
簡單來說這個Model會有兩個Softmax Layer,然後分別做256的分類問題做兩次。
link |
好,接下來來講一下Model的架構。
link |
那這個是你今天要產生Course 8bit,也就是CT的時候的情況。
link |
中間這四個Block,這四個運算,你可以把它直接想成它就是一個類似GRU的運算。
link |
那下面這邊是他的Input,左邊這個是Hidden State,上一個時間的Hidden State,那就會Output一個這個時間的Hidden State。
link |
那這東西會通過Linear,兩層的Linear,然後之後Softmax就可以得到我們的Course 8bit,也就是CT的結果。
link |
那這個GRU除了會吃上一個時間的Hidden State之外,他的Input會吃上一個時間的16bit,就是XT-1的結果。
link |
那上一個時間的16bit可以拆成兩個8bit,所以就是CT-1跟FT-1。
link |
那這是Course的8bit得到的方法。
link |
那Find的8bit其實也是一樣的方法,我會有另外一個GRU來Handle這件事情。
link |
那唯一不同的是,在這邊的Input不只吃上一個時間的CT-1跟FT-1,
link |
我還會把前面產生的CT拿來當作Input。
link |
好,那上面呢,就是整個衛法案的架構。
link |
實際上在原本的論文裡面,也就這些圖而已,並沒有詳細的跟你說Model用了什麼東西,用了幾層這樣。
link |
所以網路上有各式各樣的Implement的方法,大家有興趣可以上去看看。
link |
好,那接下來提一下,就是在WebRNN裡面有提到一些把Model再加速的方法。
link |
那第一個呢,叫做SparseWebRNN,這個做法就是對他做Weight的Printing。
link |
我們把一些比較小的Weight,設成0,直接去掉,那減少在運算上面的時候的消耗這樣。
link |
好,另外一個方法呢,叫Subscale的WebRNN,可以看右邊這張圖。
link |
原本我們在產生上面這段聲音訊號的時候,是先產生第一個,再產生第二個,再產生第三個,再產生第四個,這樣一個一個Auto Regressive的方法的生成嘛。
link |
那Subscale呢,是把這段聲音訊號折成下面這樣,這是1到8,9到16這樣子。
link |
那我們現在就不是生成1,再生成2,再生成3了,我們現在是生成1,再生成9,再生成17這樣生下去。
link |
那這邊是生成5,再生成13,再生成21這樣生下去。
link |
那這8個呢,就可以同時進行,也就是說他的速度呢,就可以快8倍這樣。
link |
那你用上了這些加速的方法之後呢,原本的論文裡面說啊,他們的WebRNN加速之後,可以在你手機的CPU上達到Real Time。
link |
就你現在GPU也不用了,我用手機的CPU就可以有很快很快的結果了。
link |
好,這是簡單的一個結論,就是一個很簡單,但是非常強的RNN來做WebFrom的生成。
link |
好,那以上講的3個Model都是Auto Regressive,從WebNet有很好的音質,接下來FFTNet跟WebRNN想要進一步加快他的速度。
link |
那速度之所以會慢呢,很大的原因就是因為Auto Regressive的方法。
link |
所以就有人想說,我們可不可以不要用Auto Regressive來生成聲音,於是後來有了WebGlow這樣的一個生成模型。
link |
好,在開始講WebGlow之前呢,要先提一下Flow Based的Model是什麼。
link |
上面這張圖啊,是Game的Model,這裡有一個Discriminator跟一個Generator。
link |
Discriminator要做的事情呢,是從一堆綠色的真實資料跟藍色的,就是生成的資料裡面去區分出真實資料應該要長什麼樣子,去把它分到正確的類別。
link |
那Generator要做的事情呢,就是想辦法騙過Discriminator,也就是讓他生成的這個X'啊,越接近X的distribution越好。
link |
那Flow Based Model要做什麼呢,Flow Based Model裡面呢,就不會有兩個Model了,它全部只有一個Model,我們這邊寫作F。
link |
那這個F呢,是一個你真實的Data跟你自己定義的一個某一個Distribution的Mapping,舉例來說這邊用Z就是Gaussian Distribution。
link |
那在訓練的時候,我們希望這個Flow Based Model啊,可以把X你的真實資料Mapping到Gaussian的Domain上面。
link |
就是你Input的是真實資料,我希望它Output越像Gaussian Noise越好。
link |
那在拿來用的時候呢,我們這個F是設計過的,它可以Inverse,也就是變成F-1,可以Inverse拿來用。
link |
那這種時候呢,你就可以把Z當作Input,那輸出呢,就是直接是一個X'了,就是生成我要的聲音訊號了。
link |
好,如果用數學的角度來解釋的話呢,就是像下面這樣。
link |
今天你的Z呢,就是F of X,所以你可以把它寫成X就是F-1 of Z。
link |
好,那今天我們的Z啊,我們把它定義成是在平均是0,然後標準差是1的Gaussian Distribution,所以我們可以把它的PDF就寫成右邊這個式子。
link |
這個就是Normal Distribution它的PDF啊,就是這個式子。
link |
所以這個QZ啊,就可以代表某一個Z,你丟進去的時候它會告訴你它出現的機率有多大。
link |
那我在training的時候呢,就是會把X丟到這個function裡面。
link |
因為我今天丟的是真實世界資料的X嘛,所以我會期待它X丟進去,你這個F如果train得很好的話,你給我的機率應該要很大。
link |
所以我如果從上面這條式子想要推出Q of X要怎麼算出來的話呢,就是把第一條式子跟第二條式子合起來,就會跑出上面第三條的式子。
link |
也就是在第二條式子的Z這邊啊,做變數變換,把Z變成F of X。
link |
那在機率裡面啊,我們學過你做變數變換的時候呢,不能只是就單單這樣把它變過去。
link |
後面啊,要再加一項這個是Jacobian Determinant的絕對值。
link |
好,那總之呢,今天你有一堆真實的data,我們叫X,那你有一個你自己設計出來的model,F。
link |
你今天train這個model的時候呢,會希望我把X丟進去,出現的機率越高越好。
link |
因為它是真實資料的X,所以希望它的機率越高越好。
link |
所以最後我們把這個Q of X取log之後,這就是我們training的時候的目標。
link |
那training的時候的目標就是把這個東西maximize它就好了。
link |
好,那講了上面那些之後,你在設計F的時候就會有兩個條件。
link |
首先第一個是,你設計的這個model啊,要很容易的可以invertible。
link |
這樣你才可以一下把它拿來用F of X運算,一下拿來用F-1 of Z運算這樣子。
link |
那第二件事呢,是這整個model裡面它的jacobian determinant要很容易可以算出來,就是這個部分。
link |
這樣你才可以很容易找到它的objective function。
link |
假設今天我們有一段X是input,那我們就把它切成X-1跟X-2。
link |
然後我們H是一次運算的結果,一樣是可以切成左右變成H-1跟H-2。
link |
那我們就定義說H-1就是X-1,H-2就是X-2加上X-1做了某個運算之後的結果。
link |
好,那這個一個H上標1就是做一次運算,那這個運算可以做很多很多次。
link |
那如果把它串起來之後呢,就會得到我們的Z。
link |
那像H這樣的運算是可逆的,假設你今天有H-1,你要怎麼推出X-1跟X-2呢?
link |
好,那這個很多很多次的H的運算呢,就是我們最後設計出來的F。
link |
如果畫成圖的話會比較好理解,假設我們今天有一段X進來,我切成X-1跟X-2。
link |
X-1呢,直接保留,直接當作output輸出,然後X-1會通過一個M-1的運算跟X-2加起來,那就叫做H-2。
link |
那同樣這樣的運算可以經過好多好多次,最後這邊我把它叫做Z。
link |
那一樣你的運算不一定要每次都保留上面嘛,你可以第一次保留上面,第二次保留下面。
link |
那總之不論你選擇上面這種或下面這種,它的運算都是invertible的。
link |
你給X-1、X-2,你可以推出H-1、H-2。
link |
你給H-1、H-2,你可以反推回X-1、X-2該長什麼樣子。
link |
好,那上面講完了flow based model,它的model設計上大概的樣子,還有它training的時候的objective會長怎麼樣。
link |
我們接下來講一下wave glow它的model該長怎麼樣。
link |
這張圖是wave glow model的架構。
link |
中間這一大塊啊,你可以把它想成就是我們剛才說的F,它是一個invertible的model。
link |
我今天input X,它可以輸出Z,那我在拿來生成聲音的時候呢,我可以input Z,然後輸出X。
link |
首先呢,你今天input X進來的時候呢,它會把它改變它的形狀。
link |
這個稍後會再提到,然後會通過一個invertible的1-1 convolution。
link |
那它其實就是1-1 convolution,只是它是一個可以可逆的這樣子,它有設計過讓它是可逆的。
link |
那applied coupling layer就是我們上一頁講的那一堆運算,可以把它圖放大來看,就變成右邊這個圖。
link |
你今天一段input進來,切成左邊跟右邊,左邊直接保留當輸出,然後左邊會丟給一個model做運算。
link |
那算出來的結果呢,會乘上XB變成輸出,就是XB Plum。
link |
那在WebGLOW裡面呢,這個拿來對XA運算的這個model,它是用WebNet。
link |
所以這就是WebGLOW它的名稱的由來。
link |
那同樣的,我的spectrogram也可以像之前input到WebNet的方法一樣接在這裡,就是從這邊輸出進來。
link |
好,那這樣是一個layer,那這個一層,那這個會有總共12層在WebGLOW裡面。
link |
那剛才說,我這邊input會把它改變形狀嘛。
link |
舉例來說,我今天在訓練的時候啊,我每次input是1秒的聲音,就是16000個點嘛。
link |
那在這邊呢,會先把它改成8乘以2000。
link |
為什麼要做這件事呢?因為剛剛我們說左邊這邊啊,要把一段input切成XA跟XB嘛。
link |
那你如果直接對16000去切的話,會變成左8000、右8000。
link |
那左邊的8000跟右邊的8000時間上是差非常非常多的。
link |
那我不如把它改個形狀,這樣切的時候是4乘以2000、4乘以2000。
link |
是比較接近的,只是就是一個subscale的架構而已。
link |
好,那上面的model就是WebGLOW它長的樣子。
link |
那training的時候呢,就是用剛才提到的objective function去train。
link |
想辦法讓那個maximize那個objective function。
link |
那在拿來用的時候呢,你可以把整個model反過來input noise,然後output就會是聲音了。
link |
好,那因為這樣的架構啊,你可以一次input一整段,比如說16000、比如說3200個點。
link |
那它的output一次就是一整段的聲音訊號。
link |
所以它生成的速度比autoregressive model快上非常非常多。
link |
但這種model啊,也有一個很大的問題就是它非常難train。
link |
在原本的論文裡面啊,NVIDIA,這是NVIDIA提出來的model。
link |
NVIDIA說他們用了8張GV100的GPU來train出這個model的。
link |
好,這GV100我去查了一下,一張大概要35萬左右。
link |
好,那這邊小結一下我們今天提到了一堆vocoder的model,它們之間的關係。
link |
首先你如果只看quality的話,最早提出來的webnet啊,其實是最強的。
link |
那在訓練時間的部分啊,autoregressive都蠻快的,相比waveglow都快上許多。
link |
你今天要達到real time,你必須要每秒可以運算16000次。
link |
那waveglow呢,它可以達到520kHz,這是遠大於real time所需要的速度。
link |
那在你沒有經過特別優化的wavern、fftnet、webnet,都是沒辦法達到real time的。
link |
但wavern跟fftnet都是比webnet快上許多的。
link |
那webnet的速度呢,大概就是你每秒鐘可以運算110次吧。
link |
這是什麼概念呢?這表示你今天要生成一秒鐘的聲音啊,你大概要花上兩分鐘來等它升量。
link |
那在前面呢,我們有提到一個傳統的方法叫做griffin algorithm。
link |
那這個東西啊,你如果很會寫code,那你可以把它optimize很好,它大概可以達到500多kHz的速度。
link |
那現在的neurovocoder的狀況啊,大概就是要嘛很難train,然後要嘛很慢。
link |
而且需要高度的優化才會有非常好的結果。
link |
所以現在的研究方向會比較偏向說,如何加快它的速度的同時還可以保持很好的quality。
link |
那在這個情況下呢,又不要太難train,不要花太多的運算資源。
link |
好,那今天的分享應該就差不多到這邊了。