back to index
[DLHLP 2020] Multilingual BERT
link |
接下來,我們要講的是Multilingual的BERT。我們知道世界上有五千到七千種語言。有這麼多的語言,我們要每一個語言都訓練一個BERT嗎?
link |
我們現在已經知道說,我們有BERT這麼強大的model,它可以做pre-training,pre-training好以後可以解各式各樣NLP相關的任務。但是,我們需要每一種語言都訓練一個BERT model嗎?
link |
其實看起來不見得需要。我們可以訓練一個精通多個語言的BERT,這個就是Multilingual的BERT。Multilingual的BERT簡單來講就是把所有語言的資料通通倒在一起去訓練一個BERT model。
link |
比如說你手上有英文的資料,你就把英文的資料倒到BERT裡面去,用MASK的方法來訓練BERT做reconstruction。你有中文的資料,也把中文的資料丟到BERT裡面去,然後用MASK的方法來訓練BERT的model。
link |
當然,中文跟英文有不同的token的sequence,所以如果你要訓練Multilingual的BERT的話,你可能會需要準備一個比較大的token的set。這個token的set是包含所有的語言,所有你現在要拿來訓練的語言裡面所包含的全部的token。
link |
你有這個token的set,包含所有語言的token以後就結束了,就用我們訓練BERT的方法,只是把所有的語言的資料通通倒在一起去訓練一個BERT的model。訓練完就結束了,你就有一個會多國語言的BERT。
link |
訓練多國語言的BERT,相較於每一個語言都訓練一個BERT,有什麼樣的好處呢?我們發現,Multilingual的BERT可以做到一件非常神奇的事情。Multilingual的BERT其實是publicly available的,就是Google有拿104種語言來訓練BERT,然後你在網路上就可以找到一個publicly available的Multilingual的BERT。
link |
那這個Multilingual的BERT它神奇的地方是它可以做到zero-shot的reading comprehension,什麼意思呢?我們有了這個Multilingual的BERT以後,接下來我們要拿它去做downstream的task。
link |
BERT只是pre-train完,它其實也不會解那個NLV的任務,你還是要拿一些downstream task的資料來fine-tune它,才能夠讓BERT做你想要它做的事情。假設我們現在手上有一些英文的QA的訓練資料。
link |
那QA的訓練資料,每一筆資料裡面必須包含三個東西,就是你要有一篇文章、一個問題跟這個問題的答案。那通常收集這種資料effort還蠻大的,所以這種資料你其實也收集不了太多。而你手上有英文的QA的訓練資料,你拿這些訓練資料去fine-tune你的BERT以後,你當然就可以讓BERT來做英文的QA,給它英文的文章、英文的問題,它可以告訴你正確的答案。
link |
MultiBERT它神奇的地方就是,我們現在把MultiBERT在英文的QA資料上面做training,但是在英文訓練完以後,它可以直接跑在中文的QA資料上。
link |
這邊就直接呈現一個真正的實驗結果給大家看。這邊我們用的英文的資料是來自於SQUAD這個Corpus,中文的資料是來自於DRCD這個Corpus。SQUAD是英文的QA資料,DRCD是中文的QA資料。
link |
如果今天我們是直接訓練一個QANet,在有BERT之前,那時候還比較不流行pre-train,所以我們就訓練一個QANet,直接在中文的資料上訓練一個QANet。這個時候得到的F1 score是78.1%的分數。
link |
EM跟F1如果你不知道是什麼的話,你就想像說這個F1的分數越大,代表現在我們的model回答是越正確的。進入BERT時代以後,當然你都會想要先用BERT pre-train。
link |
如果你今天有一個BERT是pre-train在中文上,然後fine-tune在中文的QA資料上面,你可以得到89.1%的F1,那其實人在這個Corpus上也只能達到93%的F1分數而已。
link |
如果你今天有一個multilingual的BERT,這個BERT是有104種語言圈的,如果你fine-tune在中文上,當然比純粹只pre-train在中文上的BERT還稍微差了一點點。
link |
神奇的地方是,這個multilingual的BERT,你fine-tune在英文上,它從來沒有看過中文的QA資料,但是它直接裸考,它去中文上裸考,它居然得到了78.8%的F1。當然比不上它有看過中文的QA資料,但是它居然跟QANet直接訓練在中文上的performance是差不多的,甚至還要稍微好一點。
link |
如果你今天是把中文和英文的資料統統倒給multiBERT去做fine-tune的話,當然結果會是最好的。神奇的地方就是,這個multilingual的BERT只看過中文的句子,它沒有看過中文的QA資料,那你拿英文的QA資料去fine-tune,它直接會做中文的QA的問題。這個就是multilingual的BERT神奇的地方。
link |
講到這種multilingual的問題,假設你現在想要做中文的QA,但你手上只有英文的QA資料,通常你最直覺的想法是做翻譯。你就把你手上的英文資料翻譯成中文,然後來看看結果怎麼樣。
link |
我們這邊試了三種不同語言的corpus,有英文的corpus、中文的corpus和韓文的corpus。現在如果你要做QA的話,其實你可以找得到更多不同語言的QA資料,不過這個是比較舊的文章,是去年的文章,那個時候我們只找得到中文、英文和韓文的QA資料。
link |
訓練的時候,我們分別是訓練在英文上,測試在另外三個語言上,訓練在中文上,測試在三個語言上,訓練在韓文上,測試在三個語言上。當然,如果你訓練和測試是同一種語言,結果一定是最好的。
link |
但是你發現說,Multilingual BERT神奇的地方是,往往你訓練在某一個語言,測試在另外一個語言上,結果也不會太差,尤其是中文和韓文可能是比較接近的,所以你訓練在韓文上,測試在中文上,結果居然還可以。
link |
如果你有做翻譯的話會怎麼樣呢?今天有人可能會想說,也許也用不上Multilingual BERT了,我們今天如果說你要測試,你手上只有中文的訓練資料,但是你要測試在英文和韓文上,那你就把中文的訓練資料翻譯成英文和韓文就好了。
link |
但我們發現說,翻譯的結果還比不上直接用Multilingual BERT的結果。如果你今天說,我把中文翻成英文,手上我就有英文訓練資料了,不過它是中文翻譯過來的,然後直接跑在英文上,你的測試資料是英文的,你的訓練資料是中文翻過來的英文,所以你可以訓練一個英文的模型跑在英文上,結果這個結果還比不上Multilingual BERT直接串在中文上跑在英文上的結果。
link |
如果你有做翻譯,反而結果還差一點,可能是因為翻譯的正確率其實還不夠高,那你與其翻譯一個錯的結果,還不如直接用Multilingual BERT讓它做跨語言的學習,讓它直接學在中文上,就跑在英文上。
link |
主持人問:「老師,他有去看翻譯的BlueSkull嗎?」這邊沒有,這邊翻譯是直接拿Google Translate去跑的,這個不是我們自己做的翻譯。
link |
好,而且仔細想想,我們也沒辦法量BlueSkull,因為我們也不知道中文翻成英文怎樣的英文才是正確的,所以當時就是直接跑Google Translate就結束了。
link |
也就是說,這邊這個翻譯是直接套Google Translate,但你用Google Translate去做翻譯,還不如就是Multilingual BERT直接學。那不是只有QA有這樣的現象,各式各樣的NLP的任務都有觀察到類似的現象。
link |
在NER,Name Entity Recognition上,有這樣的現象可以做到Zero-Shot的NER,訓練在某一個語言上測試在另外一個語言上是可以的。PoS Tagging,雌性標記也可以。這種機器學會做英文的雌性標記,就學會做其他語言的雌性標記。
link |
甚至這邊有一篇EMNLP的paper,它做了一個非常完整的實驗,它試了五種不同的任務。在這五種不同的任務上,都是訓練在英文上測試在各式各樣其他不同的語言上,縱軸是哪一個任務的正確率。
link |
當然,如果訓練在英文上測試在英文上,你會發現英文的正確率,在不同的任務上英文的正確率當然都是最高的。但是其他語言的正確率跟英文的正確率也沒差那麼多,至少它不是全部都壞掉。
link |
這個橫軸是哪一個語言跟英文有多少共同的詞彙,它們共同的詞彙有百分之多少是overlap的。所以,在橫軸越靠近右邊的語言,你可以想像它跟英文是越接近的。
link |
你會發現,跟英文越接近的語言在做這種跨語言學習的時候,結果當然是比較好。這也不一定,比如說如果你看XMLI,跟英文是否接近這件事跟XMLI的performance就沒有那麼大的關係。
link |
用multi-bit可以做跨語言學習這件事,基本上今天算是common sense了,每個人都知道有這樣子的現象。甚至Google還做了一個benchmark corpus,這個benchmark corpus就是要測試你的模型跨語言的能力。
link |
他們把這個benchmark叫做cross-lingual transfer evaluation of multi-lingual encoder,合起來就是extreme。extreme有點不知道是什麼東西,好像也不是什麼特別的東西,跟bit的加嘴沒什麼關係,我想說現在怎麼不湊梗了。
link |
這個extreme裡面有九個任務,每一個任務都有四十種不同的語言。你要參加這個比賽,你要做的事情就是在英文上訓練你的模型,然後測試在剩下三十九種不同的語言上,這個叫extreme。
link |
這個顯示說,這種cross-lingual可以work這件事是多麼的普遍,大家都知道說cross-lingual是可以work的。
link |
為什麼這個cross-lingual可以work呢?為什麼機器可以訓練在英文上,然後測試在中文上呢?
link |
也許一個可能的原因是,在multi-bit裡面,它學到了把不同語言的資訊去掉,只保留語意的資訊。
link |
也許對multi-bit而言,當你給它中文跟英文的時候,它看起來是一樣的。
link |
當你給multi-bit中文跟英文的時候,也許中文的兔子的embedding跟英文的rabbit的embedding是很接近的,也許中文的魚的embedding跟英文的fish的embedding是很接近的。
link |
也許multi-bit去掉了語言的資訊,只保留語意的資訊。對它來說,不同的語言都是同一個語言,所以你只要教它某一個語言的任務,它就可以在另外一個語言上學會同樣的任務。
link |
那multi-bit真的有做到把不同的語言同樣意思的詞彙line在一起嗎?所以我們這邊就做了一個實驗來驗證這個結果。
link |
這個實驗是想要量說,如果今天你把英文丟在multi-bit裏面,得到英文的每一個詞彙的embedding。
link |
當然,因為今天用的是bit,那bit會考慮它的context。所以,其實每同一個詞彙的context不同,它的embedding是不一樣的。
link |
我們就把同一個詞彙的embedding都平均起來,把那個context的資訊平均起來。每一個中文的character,我們也計算它的embedding。
link |
接下來,我們去計算英文的每一個token跟中文的每一個方塊字之間embedding的相似度,看看是不是意思一樣的token,雖然是不同語言,但意思一樣的token,它們就會有比較高的相似度。
link |
那你需要有一個bilingual的dictionary,你要先知道英文裏面某一個詞彙對應到中文裏面,應該是要對應到哪一個character,比如year就對應到年,month就對應到月,village就對應到村頂,date就對應到大等等。
link |
接下來就看year跟哪一個中文的character它最近,來發現year跟年最近。如果year跟年最近的話,那就給year這個詞彙一分,就給它一分。
link |
接下來看month跟哪一個中文的character最近,那你會發現說month雖然它正確應該要對應到月,month跟月的意思是一樣的,但它並沒有跟月最接近,但是月是排在第三名,那這時候你分數就給它三分之一分,這個東西叫做mean reciprocal ranking,你得到rank多少,你得到的分數就是1除以你的ranking,你得到的分數就是ranking的導數。
link |
所以對每一個英文的詞彙或者對每一個英文的token,你就可以得到一個ranking,然後你就可以得到一個分數,把這些分數平均起來,就代表中文跟英文它們align的關係是怎麼樣。
link |
這個分數越高,就代表這兩個語言的embeddingalign的越好。所謂align的越好,意思就是說語意一樣的token,雖然是不同語言,但是它們的距離是比較接近的。
link |
這個是真正的實驗結果,就是測試了英文跟另外十種不同語言它們之間align的關係如何。這些語言雖然是不一樣的,但是multi-bit有沒有辦法真的知道中文裡面的狗就是英文裡面的dog的align的關係怎麼樣呢?
link |
最右邊的這個bar是Google所釋出的multi-bit的結果。你會發現說,這個Minresaprocal的ranking算出來的值,其實在某些語言上是驚人的高。
link |
比如說泰文,這個還蠻高的,超過0.75。El好像是希臘文吧,這個值也是很高啊。而且多數語言,你算出來的這個Minresaprocal的ranking,這個叫做縮寫式NRR,值都超過0.5。
link |
你知道,你今天要得到0.5分,要把另外一個語言的詞彙排在第二名才有0.5分。所以,你平均高過0.5分,代表說,每一個詞彙不是排第一名,就是排第二名。所以,這個是相當驚人的一個結果。
link |
最右邊這個是Google的BERT。我們就想說,如果我們自己訓練一個BERT,我們自己把好幾十種不同語言的資料倒在一起,每一個語言如果選200K的資料、200K的句子來訓練,能不能訓練出像Google一樣的結果呢?
link |
我們得到的結果是橙色這一條線,發現不行,沒辦法。想說到底是什麼原因呢?後來一發狠,把資料變成5倍,然後Align的結果就起飛了。
link |
當然還是沒有Google那麼好啦,不過就起飛了。你可以比較右邊所來的第二條線跟橙色這一條線,你會發現說資料變5倍,Align的結果就起飛了。
link |
簡介就是要讓Machine學到Align這件事情,資料的量是很重要的。資料量不夠,你拿Multilingual BERT來訓練,它也學不到把不同的語言Align在一起。所以,資料量是一個關鍵的因素。
link |
看到這個結果,我就想說,資料量既然這麼關鍵,會不會其實對不是BERT的一般的Word Embedding,只要資料量夠多,把不同的語言倒在一起訓練一個Globe或訓練一個Word Vector,
link |
也可以得到Align的結果呢?Align的結果是,這一兩年有Multilingual BERT以後才發現不同語言可以Align在一起。
link |
但會不會其實我們早就具備可以讓不同語言Align在一起的技術,以前的Globe或Word Vector本來就可以做到這件事,只是過去沒有那麼多的資料,所以沒有人發現這個現象呢?
link |
我們就試了跑過去的Word Vector和Globe,也給它大量的資料,跟訓練BERT一樣多的資料。
link |
發現說,在多數的狀況,當然有少數例外,泰文是個例外,但多數的狀況,BERT的結果還是比Word Vector和Globe在Align的結果上面還要好。
link |
這顯示說,今天這種跨語言的Align可以成功,一方面取決於資料量增加了,但是也不單純是因為資料量增加。
link |
你就算有大量的資料,一樣多的資料,如果是用過去不是BERT的Model,而是用Word Vector或Globe的Model,其實也做不到Align這件事。
link |
要BERT加上大量的資料,才可以做到Align這件事。
link |
Multilingual BERT有一個神奇的現象,就是不同語言意思同樣的Token,Multilingual BERT居然可以知道要給它們同樣的Embedded。
link |
Multilingual BERT居然可以把不同語言同樣意思的Token拉在一起,把它們Align在一起,這件事情是怎麼做到的呢?
link |
Multilingual BERT為什麼可以做到這麼神奇的事情呢?
link |
一個比較直覺的想法是,也許是因為不同的語言其實還是有同樣的Token,很多不同的語言,但它們是比較相近的,它們是屬於同樣語系的,而這些語言可能會有一樣的Token,而這些一樣的Token在不同的語言中可能也對應到同樣的意思。
link |
所以Multilingual BERT憑藉著這些不同的語言中同樣的Token,它可以把兩個不同的語言Align在一起,這些不同語言同樣的Token就提供了一個類似Anchor的作用,把這兩種不同的語言的不同的TokenAlign在一起。
link |
但是真的是這樣嗎?你仔細想一想,其實中文跟英文也是可以Align在一起的,如果你看我們之前講的那個實驗,你會發現說,就算是中文跟英文差距這麼大的兩個語言,Multilingual BERT也可以把它們語義一樣的Token連在一起。
link |
Multilingual BERT可能可以知道說,中文的年就對應到英文的year,那怎麼這麼神奇呢?中文跟英文明明就沒有共用的Token,中文是方塊字,英文就是英文字母所組成的,它們根本就沒有一樣的Token。
link |
Multilingual BERT怎麼可以自動學到說,看過一堆中文、看過一堆英文,它就把中文跟英文Align在一起呢?
link |
而一個可能的推想是,也許是因為co-switching的關係,所謂co-switching的意思就是中英交雜。舉例來說,在中文的句子裡面,其實是有摻雜到一些英文的。
link |
舉例來說,可能有一個中文的句子像是這樣,DNA的結構很像螺旋梯,那憑藉著這樣子的句子,憑藉著這種co-switching的現象,憑藉著這種中英交雜的現象,也許Multilingual BERT就可以學到說,英文的DNA跟中文的螺旋是有關係的。
link |
就算說,我們現在的資料裡面完全沒有這種中英交雜的現象,中文跟英文還是可能有共同的Token的。
link |
怎麼說呢?中文跟英文裡面都有阿拉伯數字,阿拉伯數字就不是中文獨有的,也不是英文獨有的,在中文和英文的文章裡面都可能出現阿拉伯數字。
link |
而同樣的阿拉伯數字,可能就代表了同樣的意思。舉例來說,1789年發生法國大革命,可能中文跟英文裡面都有跟法國大革命有關的文章,他們都會提到一個數字叫做1789。
link |
雖然我們沒有告訴Multilingual BERT,中文的法國大革命跟英文的法國大革命是同一件事,但是看到兩篇文章裡面都有提到1789,也許Multilingual BERT就可以知道說,這是同樣的事件。這是一個迴響。
link |
還有另外一個猜測是說,會不會有一些中介的語言?也就是說,中文跟英文雖然他們沒有任何共用的token,但也許有一種很神秘的語言,它叫做X,X跟中文有一些共用的token,X跟英文也有一些共用的token。
link |
雖然中文跟英文間沒有共用的token,但是X跟中文有共用的token,所以Multilingual BERT可以把中文跟X連接在一起,align在一起。
link |
那英文雖然跟中文沒有共用的token,但是英文跟X有共用的token,所以英文也可以跟Xalign在一起。那因為中文跟英文都跟Xalign在一起了,所以中文跟英文就間接的被align在一起了。有可能是這樣子嗎?
link |
所以就有很多文章開始探討這個問題,但以下我只講一個實驗,這個實驗來自ICLR2020的一篇paper,這個paper破解了我們在這一頁投影片裡面講的兩個猜想。
link |
這個作者做了一個這樣的實驗,他說,我們有英文,然後我們把英文的所有的token都換成另外一個絕對不存在於英文中的token。
link |
比如說我們就規定說,把的通通換成假,ket通通換成已,等等。我們把英文裡面所有的token都換成英文裡面絕對沒有的token,製造另外一種語言叫做Fake English。
link |
所以我們現在會有一個英文的corpus,有一個Fake English的corpus。它們絕對沒有任何的coswitching,它們沒有任何共用的token。
link |
接下來,這群作者他們自己訓練了一個BERT,他們在訓練的時候只拿英文跟假的英文,這樣就可以破解我剛才說的兩個語言。因為我們今天在train multilingual BERT的時候是把很多個語言倒在一起,所以也許會有一些中介的語言把沒有共用token的語言拉在一起。
link |
但因為現在這群作者在訓練他們自己的BERT的時候,他們只拿兩個語言來train,所以其實不是multilingual BERT,他們自己叫做Bilingual BERT,他們只拿兩個語言出來train,所以就沒有這種中介語言的存在,而這兩個語言又沒有共用任何的token。
link |
在這種情況下,multilingual BERT它可以知道把兩種語言align在一起嗎?看起來有可能是可以的。這群作者的實驗是這樣顯示的,他說,現在我們train了一個Bilingual BERT,用英文跟假英文train一個Bilingual BERT,這是pre-train。
link |
接下來在fine-tune的時候,我們把這個Bilingual BERT fine-tune在假英文測試在假英文上,在XNLI跟NER這兩個任務得到的正確率,我們就把它放在這個投影片上,一個是78,一個是78.9。
link |
接下來,我們把用假英文fine-tune的Bilingual BERT直接測試在真正的英文上。Bilingual BERTtrain訓練的時候是用英文跟假的英文,在fine-tune的時候只用假的英文,沒有用真正的英文,在測試的時候測試在真正的英文上,發現在XNLI的正確率是77.5,在NER的正確率是76.6。
link |
當然,如果是在用假英文做fine-tune的結果是最好的,但是用真的英文去fine-tune performance也沒有差太多,顯示說這種跨語言的能力,不需要兩個語言有同樣的token,也不需要中介語言的存在。
link |
這個就是一個神奇的現象跟大家分享。至於這種alignment的狀況,到底是怎麼在沒有中介語言、又沒有code-switching的狀況下,Multilingual BERT怎麼學到這件事,這是一個上代研究的問題。
link |
但是講到這邊,你有沒有覺得有什麼地方聽起來怪怪的?我們一直強調說Multilingual BERT可以把不同語言line在一起,也就是說不同語言的token如果有同樣的意思,它們就會有一樣的embedding。
link |
但這樣一個想法合理嗎?好像不太合理,為什麼?因為Multilingual BERT在訓練的時候,它訓練的目標是,如果我們輸入英文的句子,它就要recontract出英文的句子,如果我們輸入中文的句子,它就要輸出中文的句子。
link |
如果今天Multilingual BERT把語言間的差異抹掉,把不同的語言都align在一起,那它怎麼能夠做到輸入英文就輸出英文、輸入中文就輸出中文呢?
link |
如果語言間的差異都已經被拿掉了,Multilingual BERT怎麼能夠記得它原來輸入的語言到底是哪一個語言,怎麼能夠做到正確的reconstruction?
link |
但是Multilingual BERT是可以做到正確的reconstruction的,就是它訓練的目標,它訓練的時候,輸入什麼句子就會輸出一樣的句子,輸入某個語言的句子就要輸出同一個語言的句子。
link |
Multilingual BERT顯然是知道語言的資訊的,它知道說今天輸入一段句子,這個句子變成embedding,這個embedding裡面是有語言的資訊的,只是這些語言的資訊沒有非常明顯地被顯示出來。
link |
如果你把Multilingual BERT裡面的embedding拿出來看,你把所有中文的embedding拿出來看,所有英文的embedding拿出來看,你會發現說它們是混雜在一起的,沒有特別明顯地說中文就是一群、英文就是一群。
link |
但是Multilingual BERT它一定有某些方法看出說,現在給它一個embedding,這個embedding是一個中文的token的embedding,還是英文的token的embedding,不然它不可能可以做到正確的reconstruction。
link |
所以我就想說,那我們來把這個語言的資訊找出來吧,我們來找找在Multilingual BERT裡面語言的資訊藏在哪裡。
link |
其實有關Multilingual BERT裡面有語言這件事情,也有一些其他文獻發現了類似的現象。
link |
舉例來說,有一篇文章說,它把各種不同語言的embedding平均起來,發現說不同語言還是有一些差異的。
link |
舉例來說,在這個投影片上,這張圖裡面,每一串文字就代表一個語言,它們的位置就代表這個語言所有token的embedding的平均。
link |
你會發現說,不只語言和語言間有一些差異,也會發現說,同樣語系的語言,它們是被cluster在一起的,同樣語系的語言,它們的embedding的平均就會比較接近。
link |
但是到底Multilingual BERT,它是把語言用什麼樣的方式儲存在它的embedding裡面呢?我想要把這種語言的embedding找出來。
link |
後來,劉繼良、許宗源和莊永松同學就想了一個很簡單的方法,這個方法我覺得聽起來好像太簡單了,一開始我覺得這個應該不work吧。
link |
他們的想法是這個樣子的,這個想法有多簡單呢?一秒就可以講完。把所有中文的embedding都平均起來,把所有英文的embedding都平均起來,英文的embedding它的位置假設在這裡,英文的embedding平均假設在這個地方,中文embedding的平均假設在這個地方。
link |
然後呢,中文跟英文間的差異,我們就用這個箭頭來表示。中文跟英文間的差異,我們就用兩者平均相減來表示。
link |
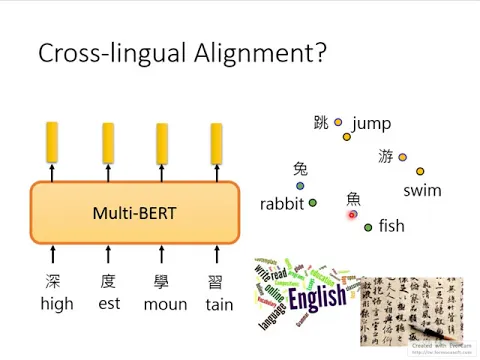
也就是說,雖然在multilingualbert裡面,表面上看起來中文跟英文的embedding是混雜在一起的,也就是說魚跟fish特別接近,跳跟jump特別接近,游跟swim特別接近。
link |
但是如果您再仔細看一下,會發現說,所有的中文的embedding也許都在英文同樣意思embedding的左上角,都在左上角。
link |
所以,如果您把所有的中文都平均起來,計算出它們之間的差異,這個差異我們用這個藍色的向量來表示,這個差異就代表了中文和英文間的不同。
link |
multilingualbert就是看這個差異,來決定說一個embedding是中文還是英文。
link |
如果真的是這樣子的話,理論上我們就可以做到以下這樣子神奇的事情,把一個英文的句子丟給multilingualbert,得到embedding。
link |
然後接下來把這些embedding都加上這一個向量,都加上英文和中文間的差異,藍色的這一個向量。
link |
因為輸入的是英文,這些是英文的embedding。那我們知道英文跟中文之間,它們就是有這個朝向左上的差距,我們把這個朝向左上的差距都加到embedding上面去,都加到英文的embedding上面去。
link |
對multilingualbert來說,他就會覺得他看到了中文的embedding,他把這些看起來像是中文的embedding,雖然本來是英文的embedding,
link |
但我們強制在他們上面加了藍色這個向量,讓multilingualbert覺得它是中文的embedding,做reconstruction以後,也許就產生中文。
link |
你輸入英文,在multilingualbert裡面加了一些藍色的向量,它輸出就變成一樣意思的中文了,有可能這樣嗎?
link |
這個讓我聯想到我們在講game的時候,其實有講過類似的現象。我們說,假設我們用game的技術可以幫每一個image、每一個人臉找到一個embedding,
link |
然後如果我們把短髮的人計算出它的平均,長髮的人計算出一個平均,就可以找到短髮和長髮間的差異。
link |
你把一個短髮的圖片加上短髮和長髮間差異的這個向量,就把短髮的人變成長髮的人,那詳見過去上課的錄影。
link |
那在multilingualbert裡面,有沒有可能做到一樣的事情呢?看起來還真的是有可能的。
link |
現在輸入的是一個英文的句子,中文的翻譯就是,能幫我的小女孩在小鎮的另一邊,沒有人能夠幫我。
link |
今天把這個英文的句子丟到multilingualbert裡面,然後在multilingualbert裡面的某一個layer加上這個藍色的embedding,輸出的句子就出現了一些中文。
link |
multilingualbert現在的輸出是,"I can lie all the way across the world, there is no one who can help me." 就變成一個津津體,那你會發現,他其實是達到了一點點翻譯的效果的,他知道說me就是我,no one就是無人,time就是事。
link |
所以顯然這個embedding的平均,確實代表了某一個語言的特徵到某一定的程度。
link |
我們還發現說,如果我們把這個兩個語言間平均的差異放大,本來在這個row的結果是加上一倍的藍色的向量,現在我們改成加上兩倍的藍色的向量,或改成加上三倍的藍色的向量。
link |
我們發現說,從英文變成中文的比例就越來越大。當我們加上兩倍藍色的向量的時候,其實輸入的英文句子輸出的時候會完全被轉成中文。
link |
當然,如果就翻譯而言,這是一個差勁到不行的翻譯,但是這其實顯示說,multilingual bird裏面確實有包含語言的資訊,而我們可以把這些語言的資訊做一點修改,就可以轉換multilingual bird輸出的語言,我們是有可能可以做到這件事的。
link |
但莊永松同學想到了一招,我們之前都說我們可以做cross-lingual training,也就是說,我們可以把某一個modeltrain在英文上,然後直接測試在其他語言,比如說直接測試在中文上。
link |
但是我們相信說multilingual bird會把不同的語言align在一起,不同的語言對multilingual bird來說看起來是沒有差異的,所以我們可以fine-tune在英文上,直接測試在中文上。
link |
但是從剛才的實驗上看起來,對multilingual bird而言,不同語言還是有一些差異的。那我們能不能想辦法把這個語言的資訊從multilingual bird裏面抹掉,讓這種cross-lingual的效果變得更好呢?
link |
我們做了一個非常簡單的嘗試。我們把multilingual bird fine-tune在英文上,接下來我們把它測試在中文上。
link |
但是測試的時候,因爲我們現在已經知道英文的token embedding跟中文的token embedding對multilingual bird而言還是有點不一樣,所以今天既然測試在中文上,我們就讓這些embedding看起來更像中文。
link |
我們讓它看起來更像中文,把剛才找到的中文和英文間的差異,那個藍色的向量,直接加到multilingual bird裏面。這個步驟跟訓練完全沒有關係,跟fine-tune完全沒有關係,我們只要在測試的時候做這件事就好了。
link |
在測試的時候,本來multilingual bird在英文上train得好好的,在中文上就特別加上這個藍色的向量,看看會發生什麽事。
link |
我們發現說,在各式各樣不同的語言上,這個是做了各種不同的語言上的嘗試,那這邊有中文,然後還有很多其他的語言。
link |
在各式各樣不同的語言上,如果你做NLI,一般的cross-lingual的NLI,得到的結果是第一個row。如果你加上上面塗藍色的向量,我們得到的結果就變成第二個row。
link |
那你會發現說,如果我們比較第二個row跟第一個row,是有一點的進步的。當然,我們現在用的抹掉語言的方法還很粗糙,那期待未來可以有更好的技術。
link |
好,那有關multilingual bird的神奇發現跟研究,就講到這邊。