back to index
[DLHLP 2020] Audio BERT (1/2) (由助教劉廷緯同學講授)
link |
例如說像 Siri 或 Alexa 的 ASR
link |
但是有 Self-Service 的話
link |
那我就可以 Pre-Train 一個 Model
link |
然後這個 Model 是可以從這些大量語音獲得知識
link |
就可以從這個紫色的 Pre-Train Model 得到幫助
link |
那他就會做得比原本只有上面這樣子來得更好
link |
那這就是 Self-Service Learning 的精神
link |
所有的 Self-Service Learning
link |
那今天大概會講24個不同的 Self-Service 的方法
link |
這樣子的 Self-Service 的 Model
link |
那 CPC 是這種 Contrastive Loss
link |
這個 Reconstruction Loss
link |
他是 DeepMind 發表的一篇 Paper
link |
那可能是有若干個 Frame 這樣子
link |
那我有一個 Encoder 的 Network
link |
他是由 CN 組成的 5 層的 CN
link |
上面有一個 GRU 的 Recurrent Context Network
link |
那最終 GRU Output 這個粉紅色的 Vector
link |
他就會跟下面這一群藍色的 Vector
link |
所以他在 Training 的時候呢
link |
他就會隨機地 Sample 一些假的
link |
藍色的這種給紅色去做 Predict
link |
如果這個紅色跟這個 CT 加 1 呢
link |
他是同一個句子的 Encoding 的話
link |
只要是屬於同一個 Input 句子的
link |
Contrastive 的 Representation
link |
他是在 Maximize 他們之間的 Mutual Information
link |
那這個 Pre-training 好的 CPC
link |
那他就會得到 Performance 的提升
link |
Foam 的分類跟 Speaker 的分類
link |
是還蠻 Standard 的 Setup
link |
那 ASR 的 Input 就是吃這個
link |
Word3 Journal 跟 Timmy 上面
link |
這個 Bidirectional CPC
link |
是 Forward Direction
link |
再加上一個 Backward 的版本
link |
CL Network 是 Shared 的
link |
Backward 跟 Forward 是分開的
link |
就是把這個 Forward 跟 Backward 的
link |
Representation Concate 起來
link |
那他也是用 ASR 來 Evaluate
link |
改成 Channel-Wise Normalization
link |
原本的 Prediction Layer 是 Linear
link |
就是 Performance 好上一些這樣
link |
用 Reconstruction 的 Loss
link |
Reconstruction Loss
link |
就是文字上可以做 Language Model
link |
就是我 Input 一個 Word 1
link |
那我就是 Input 是第一個 Frame
link |
是用 Reconstruction 去還原
link |
那就是把 Softmax 的 Layer
link |
原本那個文字的 Language Model
link |
Softmax 換成 Regression
link |
這個 Phone 跟 Speaker 的
link |
這些 Representation 的好壞
link |
好 那這個 Multitarget APC
link |
我這一個 Time Step T 呢
link |
HT 這 Hidden State T
link |
然後 Predict T 加 1 之外
link |
Hidden State Initialization
link |
然後一路 Predict 回 T-1
link |
也都是用 Reconstruction
link |
就是 Deep Contextualized Acoustic Representation
link |
那經過 Forward 跟 Backward 的 LSTM
link |
前項跟後項的這個 Representation
link |
還原一個 Window Size 的 Frame
link |
有點像 APC 的 Reconstruction
link |
全部都 Reconstruct 一次
link |
基本上就是 Reconstruction Based 的方法
link |
去 Reconstruct Frame
link |
這三個是用 Reconstruction Lot
link |
別的也是用 Reconstruction Lot 去 Learn
link |
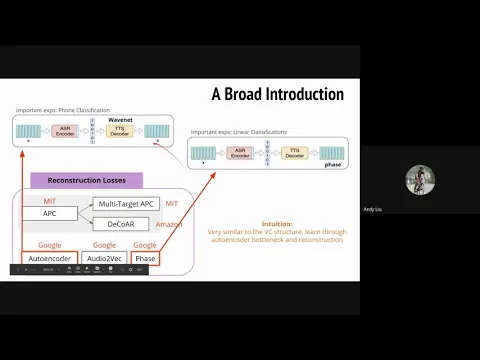
那先講這兩個 Autoencoder
link |
跟這個 Phase Autoencoder
link |
那這邊是用 WaveNet 當作這個 Decoder
link |
算一個 Reconstruction Lot
link |
那學到 Representation 就是中間這個
link |
應用在 Downstream Tasks 上面
link |
那這個 Autoencoder 是這樣子
link |
那這個 Phase Autoencoder
link |
Reconstruction Target
link |
跟那個 Voice Conversion
link |
就是很多 Voice Conversion
link |
就是一個 ASR 的 Encoder
link |
那也是用一個 Autoencoder 的方式
link |
中間可能會加一些 Constraint
link |
Google 這瓶 Autoencoder
link |
不同的 Constraint 的變化
link |
好 那這個 Audio2Vec 就是
link |
就是有 NLP Word2Vec 有兩種
link |
就是 Seabold 跟 Skipgram
link |
來學中間這個 Hidden Representation
link |
所以這個 Self-Sort By 的架構
link |
他主要在訓練的是這個 Encoder
link |
當作他的 Initialization
link |
抽一些 Speech Representation
link |
那這邊就是 Audio To Fab 的做法
link |
那這邊這個 CPC 跟 Reconstruction Loss
link |
就是很強的這個 Language Model
link |
那就是有 11 個 Sota 在 Publish 的時候
link |
比如說 How are you today?
link |
變成 How are masks today?
link |
他就是要從這個 representation
link |
去預測說這個挖空的這個 mask 是什麼
link |
那 BERT 裡面就是 Transformer Encoder
link |
那有 Multi-Head Self-Attention
link |
跟 Feed-forward Network
link |
最後會得到 Hidden State
link |
也就是這個 Transformer Encoder Output
link |
就是原本的我這個 QA 的 model 呢
link |
是需要一堆的這種 pair data
link |
也就是 passage 跟 question
link |
還有 answer 去做訓練這種 pair
link |
那這個 BERT 拿來當作 QA model 的
link |
initialization 去做 fine tune
link |
那我 QA model 就可以很強這樣
link |
self-service learning 的這個
link |
都是 Facebook 的作品這樣子
link |
就是 CPC 的 CNN 跟 GRU
link |
然後我的 loss 是 CPC 的 loss
link |
hidden state 這個 vector
link |
一個 codebook 的 size
link |
假如我的 codebook 是大小的 4
link |
continuous 的 vector
link |
就是說 vector quantized
link |
它就可以 train 一個文字版的 burden
link |
得到 quantized 後的語音的表示
link |
然後我就可以訓練一個文字版的 burden
link |
word level 的 dictionary
link |
那這個 burden 是 operate 在
link |
三萬個 dictionary size 的大小當中
link |
因為它這裡的 codebook 是三萬
link |
跟文字一樣去做 burden 的訓練
link |
所以這個 bqa2vec 跟這個 bqa2vec fine tune
link |
拿來 train 文字的 burden
link |
兩階段的 self-service learning
link |
就是一次就把 burden 直接應用在上面
link |
就是用到 reconstruction loss 的
link |
它有一個 input 的 audio
link |
它經過一個 acoustic model
link |
CTC alignment 的 loss
link |
先用 CTC 跟 label train 好之後
link |
那這個 BERT 的 input 呢
link |
就是這個 acoustic model
link |
得到的 phoneme 的 posterior 這樣子
link |
所以那如果再做 masking 的話
link |
然後它是一個 placeholder phoneme
link |
所以它是這樣子做 BERT 的 training
link |
那這裡就是 transformer encoder layer
link |
那這邊就是算 BERT 的 loss
link |
那這個 work 跟其他的最大的不同
link |
就是它不是全然的 self-supervised
link |
然後 ASR 的 output 再拿來當
link |
transformer encoder input
link |
用 reconstruction loss 的
link |
都是在 ICAPS 2020 的時候
link |
這個 speech 查爾納跟這個 MPC
link |
那接下來就來講這個 MarkingJ
link |
要怎麼直接變成 speech 版的 BERT
link |
就是 pre-trained 在文字上
link |
就是直接 pre-trained 在 speech 上面
link |
output 就是 representation
link |
input word token output representation 一樣
link |
然後跟 pre-trained 模型
link |
phone 跟 speaker 的分類
link |
來 pre-trained 一個 MarkingJ
link |
phone 跟 speaker classification
link |
那我就有一個 masking 的 policy
link |
transformer encoder
link |
得到這樣子的 representation
link |
經過一個 prediction head
link |
output 要還原出原本的 frame
link |
reconstruction loss 的計算
link |
這個藍色的 representation
link |
好 那具體的 masking 怎麼做
link |
但每次我都會選 15% 的 frame
link |
這個 acoustic feature
link |
mail 的 spectrogram
link |
就是這個 highlight 出來的
link |
那 representation 呢
link |
然後經過這個 prediction head 呢
link |
的 representation 變成這樣子
link |
一個是 discrete text token
link |
那個 showtime Fourier transform 的時候
link |
那個 window 是有 overlap 的
link |
跟著 consecutive masking
link |
我沒有丟失任何的 information
link |
transformer encoder 的
link |
這個 self-attention 的機制
link |
self-attention 在做 query 的時候
link |
全部整個 input 去做 query
link |
所以就要做這個 downsampling
link |
那這個 consecutive masking 呢
link |
剛剛如果只 mask 一個 frame 的話
link |
那如果在 downsampling case
link |
transform encoder 呢
link |
那在 Mockingjay 這個 paper 裡面
link |
分別是這個 base 跟 large
link |
它的 attention 的頭是十二個
link |
這個 feed forward 的 dimension
link |
hidden dimension 也就是
link |
你可以用越多的 data train 越好
link |
然後 pre-train 50 萬個 step
link |
就是 fine-tune 五萬個 step
link |
speech 版的 audio 的 BERT
link |
或者是拿來當 word embedding 等等
link |
feature 的 extraction
link |
就是抽 representation
link |
我右邊 pre-train 好一個 marking j
link |
然後拿過來做一個 freezing 的動作
link |
那我 input acoustic 的
link |
feature output representation
link |
然後這些 representation
link |
本來是吃 acoustic 的 input
link |
現在就是吃 marking j 的 representation
link |
是做這個 weighted sum from all layers
link |
我就從每一層都抽 representation
link |
然後再由一個學出來的 weighted sum
link |
那學到了這個 weighted sum 的 vector
link |
這個 model 是 freeze 的
link |
它會 learn from data 這樣子
link |
用少量的 paired data 去訓練
link |
那第三個方法就是這個 fine tune
link |
也是大家所熟知的 the bird 的 fine tuning
link |
那就是我這邊 pre-train 好之後
link |
全部 classifier 跟 marking j
link |
paired data 去做 fine tune
link |
也就是一般的這種 acoustic feature
link |
base model 比 male feature 好
link |
large model 又比 base 跟 male 好
link |
那如果做了剛剛的這個 weighted sum
link |
就是從各層去抽 representation 的話
link |
這個 weighted sum 就更好
link |
橫軸是我 label data 越來越少
link |
就是看說不同的 representation
link |
會怎麼樣的被少量的 data 影響效能
link |
因為 label data 越來越少
link |
那這個縱軸就是這個分類的 accuracy
link |
那可以看到這個一般的 male feature
link |
就是 label data 越少就越往下掉
link |
那 base 的這個 mockingjay model
link |
那 large model 在某些 case 下
link |
跟 base model 差一點這樣
link |
那有 weighted sum 就會比所有人都好
link |
就是有 weighted sum 的 mockingjay model
link |
就是這個最右邊的 large weighted sum
link |
用全部的 label 得到的成績還要好
link |
就是說其實這個 self-supervised
link |
pre-training 其實是非常有效的
link |
我只要拿一大堆的語音去做 pre-training
link |
那就是我只要做一個 BERT 這樣的訓練
link |
那如果有 fine-tune 的話就更厲害
link |
就是可以到 84% 的 accuracy
link |
那這個粉紅色的 base FT500
link |
但是如果是 fine-tune 兩個 Apple
link |
有 fine-tune 的話當然就是比所有的
link |
就比用 100% label 的 mail feature 還要好
link |
然後我 output 用 reconstruction loss 去算
link |
contextualize 雙向的理解
link |
然後包含在這個藍色的 vector 裡面
link |
就是所有的 audio BERT 的做法
link |
所有的 related work 這裡
link |
也就是這個 MarkingJ的進階版
link |
那這個 Terra 我就用兩三張 slide
link |
Transformer Encoder Representation from Alteration
link |
那也是一個 multi-target
link |
也是一個 acoustic feature
link |
它是不同的 acoustic feature
link |
這上面是 semel feature
link |
是用這個 FMLR 的 feature
link |
那我要怎麼做三個軸的 masking 呢
link |
就是原本的 original feature
link |
也就是 AudioBird 做的事情
link |
一整排的 channel 資訊都 mask 掉
link |
那因為 sample 出來的 noise
link |
time channel 跟 magnitude
link |
sample 出來的 noise 在上面
link |
這個 channel 軸的 masking
link |
那這個 magnitude 的增加跟減少
link |
或者是 foam 跟 speaker 的分類
link |
這個 self-sortify 的方法
link |
是這個 reconstruction loss 的方法
link |
Bird style 的 pre-training
link |
predict future 的做法
link |
past 跟 future 一起 predict
link |
這個 Interspeech 的 work
link |
拿來做 adversarial defense
link |
是 improve marking jet
link |
也就是 speech 版的 Albert
link |
理解這種 marking jet 裡面
link |
就是 marking jet 做 adversarial defense
link |
是這個 adversarial defense
link |
那 adversarial defense 是什麼呢
link |
adversarial attack
link |
然後有這樣子的 confidence
link |
然後甚至 confidence 才特別的高
link |
那這樣子的 attack 是可以用在
link |
不同的 AI 的 security system
link |
那基本上都是 gradient base
link |
然後要去 attack 這樣子的 image
link |
如果有一個 voice ID 這個聲紋鎖
link |
就應該要讓他 granted assess 這樣子
link |
但是如果今天我用 audio playback
link |
因為 audio playback 跟你
link |
就是 anti-spoofing 的 model
link |
在這個 speaker verification model 前面
link |
那這個 anti-spoofing model
link |
他就會給這個 speaker verification model
link |
那他就會辨識說他是 spoofing
link |
就不會給 speaker verification model
link |
那今天我們要怎麼 attack 這樣子的
link |
anti-spoofing model呢
link |
就是我有一個 audio playback
link |
想要他讓他辨識成是 non-spoofing
link |
就是我用 gradient descent
link |
這兩個 input 的 difference
link |
那這是一個 adversarial noise
link |
adversarial example
link |
未進 anti-spoofing model 呢
link |
我希望這個 f of x delta
link |
那我這 gradient descent 呢
link |
一般我們 gradient descent
link |
是用來 update model 的 parameter 嘛
link |
gradient descent 學出來的
link |
就是我可以用 gradient descent
link |
去學這樣子 adversarial noise
link |
那這個 attack 的方法的成功率
link |
擋在這個 anti-spoofing model 前面
link |
anti-spoofing model 的正確率
link |
所以可以看到這個 marking j
link |
這種 filter based 的方法
link |
medium、mean filter 或 gaussian filter
link |
gaussian filter 其實蠻強的
link |
他其實是在一定程度 attack 下
link |
兩個不同的 anti-spoofing model
link |
就是 random 的 marking j
link |
就是有 pre-trained 跟沒有 pre-trained
link |
所以其實有 pre-trained 是有差的
link |
而是因為他有 pre-trained 過才好
link |
那這個 train from scratch
link |
marking j 接在 anti-spoofing model 的前面
link |
然後直接這樣 train from scratch
link |
是跟 chance level 差不多
link |
原本的 hi 跟 attack 過的
link |
然後 normalized by 這個原本的
link |
然後再拿 attack 的聲音丟進去
link |
隨著 marking j 的層數遞減
link |
這個 attack 的這個 signal
link |
這個 attack 的 signal
link |
adversarial attack 之外呢
link |
是我們可以用 marking j 做的呢
link |
understanding self-attention
link |
就是 self-supervised 的學習呢