back to index
[DLHLP 2020] Audio BERT (2/2) (由助教紀伯翰同學和助教楊書文同學講授)
link |
那等一下就會講一下說 Albert 上面
link |
第一個點是 factorize embedding matrix
link |
每一個 layer 之間它 share
link |
它的 model 的 configuration
link |
把 BERT 的 embedding matrix
link |
你會有一個 embedding matrix
link |
是一個 3萬乘以 768 matrix
link |
vocabulary 的 matrix
link |
它去這個 vocabulary 的 matrix 裡面
link |
那那個 vocabulary 的 size 是一個
link |
就是它有3萬個 vocabulary
link |
然後每一個 vocabulary 的 dimension 都是 768
link |
今天我雖然說我的 vocabulary
link |
我把原本的 dimension 從 768
link |
就是這個 projection layer 把 128
link |
因為原本你的 embedding matrix
link |
簡單的 linear transform
link |
3.898M 的 parameter
link |
原本 BERT 有 12 個 layer
link |
每一層都是一個 transformer
link |
那 transformer 裡面原本的 BERT
link |
12 個 transformer 裡面
link |
那在這裡 Albert 他這個 walk 裡面
link |
那讓這一層的 transformer
link |
然後他發現說其實我在 pre-train 的時候
link |
他把 12 層的 parameter
link |
那我只要對這一層 code 12 次
link |
就是他的 configuration
link |
跟 large 的 parameter
link |
你可以看到說 Albert 他有四個 setting
link |
是 base, large, x large
link |
就比較像是他的 hidden size
link |
那其實他最大的 contribution
link |
還是在 parameter sharing
link |
他在幾個 downstream task 的表現
link |
因為 hidden size 變大了
link |
Albert xx large 只有一層的參數
link |
marking j的 size 是一樣的
link |
那換在我們 audio albert 裡面
link |
就是 male spectrogram
link |
marking j 的做法是一模一樣
link |
那我們的 reconstruction 這裡就會變成是
link |
linear spectrogram
link |
那 linear spectrogram
link |
我們的 input 是 mask 的 male spectrogram
link |
會有一個 prediction head
link |
那這個 prediction head 會去
link |
做 linear spectrogram
link |
就是要 male spectrogram 對應到的
link |
linear spectrogram 做 reconstruction 的動作
link |
把 mask 的 token 還原回來
link |
albert 有做一個 factorized matrix
link |
那他還會再多一個 projection head
link |
只是差在說跟 albert 不同的點
link |
文字的 reconstruction
link |
變成 spectrogram reconstruction
link |
那跟 marking j 的差異是差在說
link |
marking j 的 linear large 相比
link |
那 linear large 是有 12 層
link |
我們的 audio albert 就會有 3 層 6 層
link |
那 marking j 我們也有對應的
link |
audio albert 都是 share parameter
link |
那在 marking j 3, 6, 12 層
link |
好 那在 pre-training 的時候
link |
的 male spectrogram
link |
我們會再經過一個 prediction head
link |
然後去 reconstruct 我們
link |
就是如果沒有 mask 沒有 spectrogram
link |
對應的 linear spectrogram
link |
的 output 就是有這個 ground truth
link |
那這是在 pre-training 的時候
link |
pre-training 的 stage
link |
那在 downstream task 裡面
link |
那風鈴 classification 裡面我有做兩種 setting
link |
每一層 representation
link |
乘起來之後再 aggregate 出來
link |
representation 這樣子
link |
我們在 downstream 的時候會動到的
link |
feature extraction 的時候 雖然我
link |
我 pre-trained model 裡面
link |
freeze 的 那在 fine tune 裡面
link |
不管是 pre-trained model
link |
還是我們對應的 classifier
link |
那在風鈴 classification
link |
我們除了做微提上跟 fine tune 的
link |
不同 proportion 的 data 下的
link |
那在風鈴 classification
link |
classifier 是一個 multi-layered
link |
那在這裡我們是用兩層的 classifier
link |
去做風鈴的 classification task
link |
微提上跟 fine tune 的環境
link |
Audio Albert 的實驗結果
link |
那這邊都是 Marking J 的實驗結果
link |
然後咖啡色的是 fine tune 的結果
link |
即使我們今天 training data 可能
link |
在 Marking J 跟 Albert 的實驗裡面
link |
跟 Marking J 的 model
link |
跟實心的是 Audio Albert
link |
有用於幫助 downstream task
link |
那 fine tune 你是有 tune 到所有的 model
link |
那這是第一個 downstream task
link |
可是封你的 classification
link |
就是 speaker identification
link |
那 speaker identification
link |
是做 utterance label 跟 frame label
link |
然後以及他們 overall performance
link |
這個 utterance label 裡面
link |
utterance label 的環境其實是
link |
那我們會把這一排 representation
link |
直接 apply 一個 mean pooling
link |
然後再過我們簡單的 linear classifier
link |
mean pooling 的 operation
link |
這個 utterance 的 representation
link |
去做我們的 speaker identification
link |
你可以看到說這種 utterance label
link |
做 speaker identification
link |
我只要用 utterance label representation
link |
然後我只要 train 這個 classifier
link |
我就可以達到 98 到 99 的 accuracy
link |
utterance label 的 identification
link |
98 到 99 的 accuracy
link |
假設我們把這樣的 representation
link |
我們把它用 teasing 去 visualize
link |
在 utterance label representation
link |
target 去做 training
link |
它只是做了 pre-training
link |
它在 teasing visualization 上
link |
就是同一個顏色代表同一個 speaker
link |
它在左邊 utterance label representation
link |
或 AudioAlbert 的 representation 之後
link |
我們達到它的 MarkingJ 跟 AudioAlbert 的
link |
utterance label representation
link |
實驗是 utterance label 是
link |
然後我再做 mean pooling 變成一根
link |
很簡單的 linear classifier
link |
那現在 frame label 就會變成
link |
我每一根都要去 classifier
link |
不是不用再做 mean pooling
link |
linear classification 這樣子
link |
第二個實驗 frame label 實驗
link |
不管是 AudioAlbert 還是 MarkingJ
link |
然後雖然 AudioAlbert 是
link |
即使今天你是要 classifier
link |
其實也是有 251 個 speaker 這樣子
link |
那在 AudioAlbert 的 paper 裡面
link |
我們就是做 phoning 的 classification task
link |
identification 的這兩個 task
link |
MarkingJ linear large 的
link |
comparable 的 performance
link |
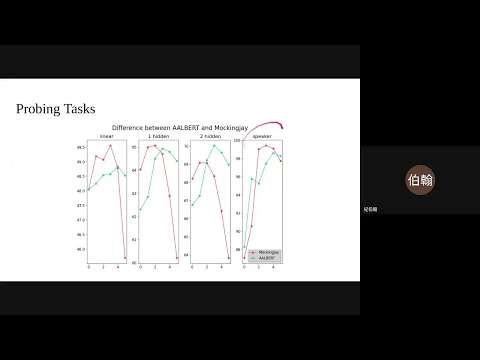
probing task 那probing task 是什麼呢
link |
我想知道每一層 representation
link |
把每一層 representation 抽出來
link |
然後去做 phoning 或 speaker 的表現
link |
linear 1 hidden 跟 2 hidden
link |
我後面 apply 的 downstream model
link |
很簡單的 linear classifier
link |
還是一個 hidden 還是兩個 hidden
link |
在不同深度的 downstream model 裡面
link |
綠色的點是 AudioAlbert 的
link |
pre-trained model 那在
link |
那其實我們這個實驗裡面可以看到一個點
link |
都是 phoning 的 setting
link |
那你可以知道說中間層的 representation
link |
understand self-attention 在做什麼
link |
self-attention 裡面的
link |
self-attention 的 model
link |
在 train 這個 reconstruction
link |
speaker recognition 的 model
link |
你的 loss 是專門給 speaker
link |
你的 attention 會去認哪些東西
link |
這個 birth 用的是 reconstruction loss
link |
representation learning 的呢
link |
這個 self-attention 的機制
link |
這個 speech 的 representation 上面
link |
就是 self-attention 還有 reconstruction
link |
我們把全部的 attention 圖畫出來呢
link |
先講 attention map 有哪些
link |
基本上大概不出這三個 category
link |
代表的是 sequence length
link |
第10個 query 第20個 query
link |
就是一個 attention distribution
link |
這個 diagonal 的 attention
link |
key factor 還有 value factor
link |
我就拿第30個 value factor
link |
vertical attention 它就是說
link |
alterns 中我永遠都只 attend 在
link |
不同的 alterns 你不同的 alterns
link |
根據你的 content 你整個 alterns 的 content
link |
attention map 就是我們
link |
vertical 或它多 diagonal
link |
不管上面這個 H 跟 U 這個不重要
link |
一個 attention distribution 呢
link |
那它這個 globalness 就越大
link |
attention distribution 先做一個
link |
都會有一個 attention distribution
link |
每一個 query 出來的 distribution 先做一個平均
link |
這每一個 distribution 它都會
link |
得到比較大的 attention weight
link |
出現這樣子 vertical 的性質
link |
它的 attention weight
link |
所以其實就是說每一個 attention weight 呢
link |
就是它距離你的 main diagonal
link |
就是我們希望讓這個 attention weight
link |
它離這個 main diagonal
link |
那我們這個 outline 主要就是
link |
還有這個 vertical 還有 global
link |
還有這種 block diagonal 的 pattern
link |
focus 的這種 attention map
link |
我們在 pre-training 階段
link |
mask language model
link |
就是我們變成 mask acoustic model
link |
就代表說我們這個 pre-training 階段的時候
link |
我們 attention 呢它學會說
link |
在正中央 main diagonal 這一條線
link |
就是被 mask 的那些 frame 呢
link |
去 reconstruct 我正中間
link |
這個 frame 呢它 reconstruct 的時候
link |
所以你用這樣的 reconstruct
link |
只有三個 frame 的時候是不會出現的
link |
右邊幾個這種 attention 呢
link |
它會長得這個 block diagonal 的樣子
link |
還有這種 vertical 的 attention 呢就是大概長這樣
link |
左邊這種 pattern 看起來就是
link |
它大部分都是有 attention 位的嘛
link |
特別的沒有 attention 位的
link |
那這種 block diagonal 的 attention 呢
link |
phoneme 的 boundary
link |
或是 phoneme 的 interval
link |
同一個 phoneme 的 interval
link |
我都可以拿來 reconstruct
link |
我的 attention distribution
link |
是利用 phoneme interval 的話呢
link |
phoneme boundaries
link |
它是不是剛好就是 boundaries
link |
它真的有認到這個 phoneme 的
link |
就是有 label 好的 boundary 去畫出來的 map
link |
一個 similarity 的 matrix
link |
現在 sequence length 是100
link |
那這個 parameter 的用意是什麼呢
link |
這樣算完之後呢 就會產生一個 map
link |
column 三的位置呢 就是第三根
link |
這樣算出來呢 也可以得到一張 map
link |
對 就是 peer wise 然後它會是對稱
link |
attention map 也可以做這件事情
link |
很明確的 block diagonal 的樣子
link |
做 phoneme segmentation 的時候
link |
基本上是最常拿來用的 feature
link |
用我們的 attention 作為一個
link |
predicted boundaries
link |
有 label 好的 true boundaries 去算這個
link |
三個 frame 啊 六個 frame 還是九個 frame
link |
diagonal attention 然後呢
link |
它跟 phoneme boundaries 的
link |
self-attention 應用到
link |
因為畢竟這個 speech 的 frame 的
link |
model 都是 down sample 三個 frame
link |
就是我們在算這個 boundaries
link |
這個 boundaries 呢 它是 label 在
link |
sequence length 上面 如果我們把
link |
這個 phoneme boundaries
link |
有一些 boundaries 直接就不見了
link |
這個 attention map up sample
link |
對 所以原本的 attention map 可能是長這樣
link |
那我們就把 attention map up sample
link |
attention map 它看起來就是
link |
這個 similarity metric 這麼
link |
對 我們可以看到這邊有一些比較大的方塊
link |
我有一排 true boundaries
link |
precision recall 就是
link |
通常在做這個 phoneme segmentation 的時候呢
link |
predicted boundary 只要跟 true boundary 呢
link |
那這個 tolerance window
link |
predicted boundary 只要有出現在
link |
這一根 true boundaries 呢
link |
做 phoneme segmentation 的時候
link |
專用的 evaluation 的方法
link |
做 segmentation 的時候發現
link |
block diagonal 這種 attention 呢
link |
representation 不管是
link |
phoneme segmentation 的時候呢
link |
similarity representation
link |
的 similarity matrix 長得會像這樣
link |
可是呢 我只要把 alpha 調得越來越大呢
link |
的人比呢 就會發現 欸 其實旁邊的人
link |
block diagonal 的樣子
link |
存在這種 phoneme interval 的資訊
link |
marking trait representation 也存在
link |
這種 phoneme interval 的資訊
link |
是我們來套 segmentation
link |
algorithm 的時候呢 表現的
link |
可是我們從這兩張我們就可以看得出來說
link |
我現在要把 segmentation 做得好
link |
到底跟我像不像的那個 threshold 呢
link |
以 phoneme interval 的角度來說呢
link |
的 attention map 就發現 欸
link |
就是比較 local 的 phoneme structure
link |
第一件事情是 block diagonal
link |
attention 呢 它跟我們這個
link |
phoneme interval 還有
link |
的 frame 這樣子 好 這邊就有兩個
link |
diagonal attention 的部分的時候呢
link |
vertical 的 attention 還有 global
link |
的 attention 它們到底在做什麼
link |
事情 比方說 global attention
link |
different input alterance 我們就會產生
link |
attention map 已經很雜亂了 然後
link |
how to summarize the operation of a hat
link |
phoneme 的 relations
link |
n 這個 phoneme 它的 attention weight
link |
phoneme relation 呢 它
link |
raw 都是一個 attention distribution
link |
就是先把這一張 attention map
link |
先做成一個 joint distribution
link |
每一個 attention distribution 呢
link |
它多麼在認這樣一個 relation
link |
的話呢 我就在這一張 map 裡面呢
link |
d 的 attention weight
link |
每一個 joint distribution 的那個機率值呢
link |
根據它的 phoneme distribution
link |
這個機率值的 reallocation
link |
每一個 all trans 它長度都不一樣
link |
這個 attention map 呢 它可能是
link |
比方說 39 個 phoneme 的話
link |
的這個 phoneme relation map
link |
39x39 phoneme relation
link |
看起來什麼事都沒 就是我們看不出來它在
link |
然後就發現說 欸 這個 head 呢
link |
它都去 ignore silence
link |
綠值 reallocation 的做法呢
link |
attention weight 去
link |
我整個 speech corpus 裡面呢
link |
這些 ortrans 裡面有出現過的
link |
比方說假設我整個 speech corpus 裡面
link |
其他人的 attention weight
link |
speech corpus 裡面呢 大部分
link |
attention weight 試圖去描述
link |
機率值 reallocation 得出來的
link |
那個新的 joint distribution
link |
對到 o y 這個 relation
link |
然後 silence 對到 silence
link |
比方說在某一個 ortrans 上面
link |
它 silence 對到 silence
link |
的 attention weight 可能其實
link |
整個 speech corpus 裡面
link |
silence attend silence
link |
它得到的 attention weight
link |
整個 speech corpus 裡面
link |
哪些 phoneme relation
link |
它們各自的 distribution
link |
每一個 ortrans 它這個 silence 對 silence
link |
silence 對 o y 出現的次數也很多
link |
這個 head attention weight
link |
我們原本以為 silence 對 silence
link |
我們原本以為 silence 對 silence
link |
跟真正的 silence 對 silence
link |
它都是不去 attend silence to silence
link |
那一旦我出現 a w 對 o y 的 relation
link |
我分配到的 attention weight 都很多
link |
我們真的可以 characterize
link |
function relation distribution 去
link |
去做一個 normalization
link |
就是剛剛這個 reallocation
link |
直接 reallocation 的結果
link |
這個 function relation distribution
link |
normalization 去減掉它
link |
這是 normalized 過的結果
link |
還是說它是比 corpus 原有的低
link |
就是我們發現的一些 operation
link |
當我 query 是 silence 的時候呢
link |
我就只 focus 在 silence
link |
這條值的就是我都忽略 silence
link |
我去 attain speech part
link |
那如果我不是 silence 的時候呢
link |
我 attain 在 silence 上面
link |
我 global 的那些 attention 位呢
link |
跟我 query 是同一個 phone name 的人
link |
跟我 query 的 phone name 是
link |
就是一些 vertical attention
link |
不管我的 query phone name 是什麼
link |
它也都 attain 在 silence
link |
或是它都不 attain 在 silence
link |
或是不 attain 在一些 phone name
link |
在 vertical attention 這邊呢
link |
是不是當我的 attention 呢
link |
認特定的 phone name 這樣
link |
或是不認特定的 phone name
link |
ceh 這是叫 concentration
link |
這張 phone name relation map 呢
link |
如果我這個 phone name relation map
link |
的那幾個 phone name 比方說
link |
它的 concentration 的值應該要
link |
它應該就要在 silence 上面呢
link |
它的 concentration 是負的
link |
如果當我的 attention map
link |
怎麼 characterize 從這樣子
link |
最一開始定義的那個 verticality
link |
query 的 attention distribution 平均之後
link |
再算 entropy 的就是那個公式
link |
這個大 V verticality 呢
link |
它的 phone name relation map 呢
link |
特別就 focus 在某個 phone name
link |
橫軸是 verticality 是說
link |
它產生的 attention map 是不是
link |
這個 phone name relation map
link |
concentration 的值越正
link |
越上就代表它越 focus 在某個 phone name
link |
就代表它越 neglect 特定 phone name
link |
attention map 開始出現一些直線呢
link |
focus 在特定的 phone name
link |
或是 neglect 特定的 phone name
link |
大概知道說 block diagonal attention
link |
它跟 phone name 的 interval 有關
link |
然後 vertical attention 呢
link |
altrance 的 level 下
link |
或者是有出現哪些 phone name
link |
然後我們 head 就是要去抓哪個 phone name
link |
對於我最後的 representation
link |
比方越 diagonal 的 attention
link |
這個就是有最高的大 d 值的 head
link |
就是說我直接把它的 output 全部設成
link |
就把那個 head 的 output
link |
然後看最後的那個 representation
link |
我們把那個 representation 呢
link |
拿去做兩個 downstream task
link |
一個是 phone name classification
link |
一個是 speaker recognition
link |
被操作過的 representation 呢
link |
attention 來開始 print
link |
diagonal 的 attention
link |
只有 diagonal 的 attention
link |
不管是 global 的 attention
link |
還是 vertical 的 attention
link |
print 然後這邊是 print 了24 個 head
link |
那三個 matrix 去排列我的 head
link |
print 24 個 vertical head
link |
不管是 vertical 還是 global 都變好
link |
我就是要把 alterance 裡面
link |
query 的這個 time step
link |
phone name classification 是有害的
link |
比方說我的 query phone name 可能原本是
link |
那最後在 classification 的時候呢
link |
那這樣 vertical attention 到底在幹嘛呢
link |
speaker classification
link |
speaker recognition 的 test 就可以發現
link |
這樣子的這種 vertical head 呢
link |
speaker identity 其實是比較相關的
link |
speaker 的 identity
link |
metric 找出三種不同的 head
link |
然後去看說它對我最後的 representation 有什麼樣的影響
link |
我這個 attention head 呢
link |
出來的 attention distribution 的
link |
最大的那個 attention weight
link |
很大的 attention weight 的話呢
link |
weight 的 pruning curve 就是說
link |
每次出來的 attention weight 呢
link |
他們在這個 speaker recognition
link |
的 tag 上面就是有一個還蠻明確的
link |
還有 weight 的這兩種 pruning 的
link |
所以對於 globalness 來說呢
link |
weight 來說呢 這個 head
link |
可是這個 head 對於 globalness 來說呢
link |
head 的時候呢 就出現一個明確的
link |
pruning 的方法呢 它們主要的
link |
根據 globalness 來 prune 二十四個 head
link |
是要根據 weight 來 prune
link |
head 的話呢 它會 prune 掉
link |
這個 silence 這個資訊呢 對於
link |
欸 這種 vertical head 呢
link |
形成 speaker identity 沒有
link |
對於這個 speaker identity 的
link |
我們現在把 self-attention
link |
用 reconstruction loss 來 train
link |
attention 有 diagonal
link |
還有 vertical 還有 global
link |
的 attention 那我們發現說
link |
diagonal attention 呢 它
link |
information 是 它是唯一有影響的
link |
就是 vertical 還有 global
link |
對這個 phonetic information 都沒有影響
link |
意識到我們在 pre-training 的時候的
link |
masking length 然後呢
link |
它也有意識到這個 phoneme 的
link |
這個 vertical 的 attention 呢
link |
它跟我們這個 speaker identity 特別的重要
link |
focus 在某些 frame 還有它
link |
neglect 某些 frame 對
link |
並不是說只有 focus 這種就是有
link |
很高的 attention weight 很重要
link |
儘管我這個 attention distribution 裡面
link |
很高的 attention weight 但它的
link |
operation 這件 它的這個 operation
link |
那最後就是 global 的 attention 呢
link |
就是目前我們還在 working on