back to index
[DLHLP 2020] Deep Learning for Constituency Parsing
link |
我們來講一下Parsing,今天要跟大家講的是Constituency的Parsing,Dependency的Parsing也許我們下次有空再講。Parsing有兩種,一種是Constituency的Parsing,一種是Dependency的Parsing。
link |
為什麼特別要把Parsing拿出來講呢?我們剛才已經講過,NLP的幾大類任務,其實多數你都知道怎麼train一個end-to-end的model,但是有一些任務感覺有點複雜,如果叫你馬上逗一個deep learning的model,你一時間可能會不知道怎麼解它,所以我們把這一些特例拿出來跟大家講。
link |
我們剛才已經講了coreference resolution,那我們這邊來講一下Parsing。我們今天只講Constituency Parsing,什麼是Constituency Parsing呢?
link |
Constituency Parsing,它假設在一個句子裡面,某一些spend,某一些token組成了一個constituent。那什麼是constituent呢?假設你不知道constituent是什麼,你就把它想成是一個單位,有一些詞彙組起來就是一個完整的單位,有一些詞彙組起來就不是一個完整的單位。
link |
舉例來說,下面這個句子,deep learning is very powerful,learning is very……這三個詞彙拼起來,你就覺得它不是一個單位。但deep learning這兩個詞彙拼起來,它是一個單位。very powerful拼起來,它是一個單位。
link |
你可能會問說,怎麼知道幾個詞彙組起來到底是不是一個單位,是不是一個constituent呢?在語言學上,有一系列的方法來檢定說,一串詞彙組起來是不是constituent。
link |
不過我們這邊就不講這個部分。其實有時候,你憑著直覺判斷就還蠻準的。就算你沒有受過什麼語言學的訓練,情直覺判斷也八九不離十。你覺得它是一個constituent的東西,八成就是一個constituent。
link |
constituency policy就是要把一個句子裡面,所有這些可以組成constituent,可以組成一個單位的span,通通都找出來。
link |
每一個單一的詞彙其實也算是一個constituent,比如說powerful是一個constituent,deep也是,learning也是,is也是,very也是,單一的詞彙都是constituent。每一個constituent它都有一個label。
link |
舉例來說,deep learning,它的label是什麼呢?它的label就是名詞片語。very powerful,它的label是什麼呢?它的label就是形容詞片語。
link |
那有哪些可能的label呢?那這邊就是從pentrybank這個做parsing的corpus裡面,它有標註的label,把它找出來給大家看一下。比如說有形容詞片語,有副詞片語,有名詞片語,有介系詞片語,s代表說一個子句,等等等等。
link |
那因為所有的詞彙也都是constituent,所以所有的詞彙的POS tag,動詞、名詞、形容詞、介系詞等等,它們也都是可能的label,就這樣。
link |
那在constituency parsing裡面要做的事情是什麼呢?首先給你一個句子,在這個句子裡面,每一個詞彙都是一個constituent,那它們的label就是它們的POS tag,就是它們詞性的標註。
link |
然後接下來,相鄰的constituent可以組合起來,變成一個更大的單位。舉例來說,deep跟learning可以組合起來,deep learning是一個更大的單位,它的label是名詞片語。
link |
very跟powerful可以組合起來,變成一個更大的單位,它們的label是形容詞片語。ease跟very powerful這個形容詞片語,ease跟這個形容詞片語可以組起來,變成一個動詞片語。
link |
而這個名詞片語跟這個動詞片語可以拼起來,變成一個句子。那我們把這些所有組合出來的constituent放在一起,你就可以形成一個樹狀的結構,你就可以形成一個樹。
link |
或者是我們把這邊的每一個constituent用一個樹裡面的節點來表示的話,你就產生一個樹狀的結構,然後每一個constituent就是樹裡面的一個node。
link |
在這個課程裡面,我們假設說每一個node都只會有兩個分支,這個樹狀結構的最頂端,就是葉子的部分,就是詞彙。
link |
當然其實在constituency parsing裡面,也有可能一個node可以分出多個分支,也就是多個小的constituent可以拼成一個大的constituent。
link |
但我們現在都假設說,無視那個狀況,constituent兩兩間可以拼成一個更大的,我們只考慮binary tree的狀況。
link |
但是我們這邊在講的時候,我們就是採用比較簡單的講法,有關更深入的,比如說我們甚至沒有講說什麽叫做CFG。
link |
假設有同學不知道CFG這個縮寫指的是什麽的話,那也可以自己看一下Danger Refugee的教科書。
link |
我們這邊就是用最簡單的講法告訴你說deep learning怎麽用在parsing上面,我們儘量省略一些語言學上的專有名詞,然後就很快進入deep learning的主題。
link |
直接告訴你說,我們現在解的問題就是這麽回事,就是要決定哪些詞彙組起來會變成一個constituent,然後每一個constituent它屬於什麽label。
link |
那這個問題怎麽解呢?有兩大類的解法,一個叫做chart based的方法。
link |
那chart based的方法呢,我想它這個名字的由來是來自於CKY的chart parsing。
link |
那我們不會講到CKY的chart parsing,反正我們不會講chart parsing這個東西,但是這一套方法通常就被歸類為chart based的方法。
link |
好,怎麽做呢?怎麽做constituency parsing呢?現在既然我們的目標是要把這個句子裏面所有的constituent都找出來,那我們要怎麽做呢?
link |
我們就是訓練一個classifier,這個classifier給它一串token的sequence,給它一個span,它決定說這個span是不是一個constituent,就結束了。
link |
那在constituency parsing裏面,除了決定一個span是不是一個constituent以外,我們還要決定這一個constituent的label。那怎麽決定這個constituent的label呢?
link |
你就把這個span丟到classifier裏面,這個classifier output說這個span應該算是哪一個label,就結束了。
link |
決定一個span是不是constituent這件事情,很簡單,它就是一個binary classification的problem,是或不是。
link |
把一串文字丟給classifier,它判斷它是一個constituent或不是一個constituent,就結束了。
link |
然後決定說,這一個constituent到底是哪一個label,是動詞片語、形容詞片語還是名詞片語,那也很簡單,它就是一個multiclass classification problem,把一個span丟到classifier裏面,它會output一個label,名詞片語、動詞片語、形容詞片語,output一個label,就結束了。
link |
然後呢?然後你就把這個classifier跑在一個句子上面,把這個句子所有的span統統丟給這個classifier跑出結果,就結束了。
link |
所以今天給你一個句子,那你就說,我把deep learning丟到這個classifier裏面,這classifier就會告訴你說,它是不是constituent呢?它是。
link |
那它是constituent的話,它的label是什麼呢?是名詞片語。你把very powerful這一串文字丟到classifier裏面去,那classifier就會說它是constituent。
link |
那它的label是什麼呢?它是形容詞片語。那不是constituent的東西,比如說deep learning is,你丟到classifier裏面,classifier就會output no,它不是constituent。
link |
那有關它是哪一個label就不care了,這邊output什麼都沒關係,反正我們也不會去讀它。然後learning is very powerful,它不是一個片語,不是一個constituent,所以這邊就output no。
link |
然後它是哪一個label呢?我們也就不會去在意在multiclass classification,在label的prediction這個部分會output什麼label了。
link |
那講到這邊,我們的classifier長什麼樣子呢?其實這個classifier跟我們剛才在講co-reference resolution的classifier真的是大同小異。
link |
給你一串文字,把這串文字丟到一個bit裏面,得到一堆embedding的sequence,把你現在在意的那個span用一個span feature extraction抽出一個vector,你在意的是W4到W7是不是一個constituent。
link |
那你就把W4到W7對應的embedding用一個module抽出一個代表的vector,然後把這個vector丟到一個比如說幾層的fully connected的layer裏面,然後output就是yes no。
link |
根據這個vector決定現在是不是一個constituent,然後把這個vector丟到另外幾個fully connected的layer裏面,決定說這個vector如果它是一個constituent的話,那它的label應該是什麼。
link |
然後接下來呢,就end-to-end的train就結束了,因為在train的時候會給你1-2的parsing tree,給你一個句子,還會給你它的parsing tree的正確答案,還會告訴你說它的constituent的parsing tree長什麼樣子。
link |
所以你完全知道說在訓練的時候,你完全知道說一個span它是不是constituent,如果是的話,它是什麼label。所以end-to-end的train,你的classifier就結束了。
link |
所以這個parsing感覺好像還蠻簡單的,你有n個token,你只要跑剛才講的那個classifier,n乘以n-1-2,也就是Cn取2次,就可以把所有的textband通通都抓出來,就把所有的textband通通拿來決定一下它是不是constituent。
link |
但實際上,這整個問題沒有那麼簡單。你馬上就會發現說這裡有一個天大的問題,什麼樣天大的問題?因為你的classifier並不是完美的,所以你可能跑完classifier以後,你會發現你製造了一些矛盾的狀況。
link |
你可能會把deep learning is丟到classifier裡面,它說它覺得這是constituent,然後你又把is very powerful丟到classifier裡面,它也說這是constituent,你就陷入一個矛盾的狀況了。
link |
如果deep learning is是一個constituent,is very powerful也是一個constituent,那你就沒有辦法把你找出來的那些constituent,把你找出來的那些unit拼成一棵樹了。它組不成一棵樹,因為這兩個constituent居然重疊了,這樣是不行的,這樣是矛盾的狀況。
link |
怎麼避免矛盾的狀況發生呢?其實實際上在做training的時候,實際上你train出這個classifier以後,你是這樣使用classifier的。
link |
給你一個句子,你會先窮舉出所有可能的constituency parsing的結果,你會先窮舉出所有可能的樹狀結構。
link |
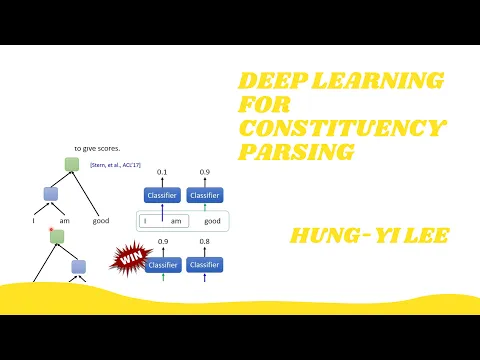
舉例來說,給你一個句子I am good,有什麼樣可能的樹狀結構呢?可能i跟n先拼成一個constituent,再把good跟in組成的constituent拼成一個更大的綠色的constituent,可能把n跟good拼成一個constituent,再把藍色的constituent跟i拼成綠色的constituent。
link |
因為今天這個例子很簡單,你就只有三個詞彙,所以可能就有兩種可能的樹狀結構。
link |
接下來,你就用你剛才訓練出來的classifier去看哪一個樹狀結構得到的分數比較高,也就是你先舉出合法的樹狀結構,再用classifier去評量哪一個樹狀結構是最好的。這樣就可以避免你單純執法classifier的時候可能會產生矛盾的狀況。
link |
因為你只先舉出合理的樹、合法的樹、正確的樹,就是你先舉出合法的樹,在合法的樹裡面挑一個最好的,這樣可以避免你挑到矛盾的狀況。
link |
所以像上面這個例子,i跟n組成一個constituent,就用classifier量一下,classifier覺得是constituent的機率很低,它只給它0.1的分數。因為你如果訓練一個binary classifier,它不只是可以offer yes or no,它還可以offer一個分數,它可以offer一個介於0到1之間的分數代表它的信心。
link |
所以in對classifier來說,它是一個constituent的信心是很低的。把ing則是一個完整的句子丟到classifier,它的信心分數是很高的。
link |
接下來再看下面這個case,n跟good組成一個constituent。你把ng丟到classifier,classifier覺得ng合起來是一個constituent,信心分數很高,給它0.8分。
link |
然後ing跟上面這個case一樣,也是給它0.9分。接下來就看說,上面這個樹狀的結構得到的分數是多少,classifier跑兩次總共給它0.1加0.9分。
link |
下面這個樹狀的結構得到的分數是多少,classifier跑兩次總共給它0.9分加0.8分。所以合起來,下面這個樹狀的結構得到的分數比較多,它贏了,它得到的分數比較多。
link |
所以最後,你跑出來的parsing tree就會是下面這個樹狀的結構。
link |
講到這邊,大家可能會問的一個問題就是,怎麼窮舉所肯的樹狀結構呢?今天這個例子很簡單,這是一個簡單的例子,只有三個詞彙,你當然可以窮舉所有樹狀結構。
link |
如果是一個很大的句子、很長的句子,怎麼窮舉所有可能的樹狀結構,再用classifier去評量那個樹狀結構的分數呢?這個時候,你就需要用到我們今天不會講的CKY的parsing algorithm。
link |
CKY的parsing algorithm是一個dynamic programming的algorithm,這個dynamic programming的algorithm可以讓你在合理的時間之內窮舉所有的樹狀結構,並用classifier得到這個樹狀結構的評分。詳細節你可以參考一下過去的文獻。
link |
既然我們今天在inferent在產生樹狀結構的時候,其實是把窮舉所有可能的樹再看哪一個樹的分數最高,所以實際上我們在training的時候也不完全會把這個parsing的問題formulate成簡單的binary classification的問題。
link |
因為假設你training的時候是train,classifier,但是你在inferent的時候是窮舉樹狀結構評估哪一個樹狀結構最好,那你訓練跟testing,你的training跟inference不是就有些mismatch了嗎?
link |
training跟inference做的事情不一樣啊,如果你training的時候只是train classifier,inference的時候是評估樹狀結構的好壞,那training跟testing就不match了。
link |
所以實際上,你可以自己去看一下文獻,實際上在training的時候是更為複雜的。在training的時候,實際上你training的目標是期待訓練出classifier,給一個正確的樹會給它最高的分數,而給錯誤的樹會給它比較低的分數。
link |
所以實際上在訓練的時候,它的loss並不只是單純的cross entropy,那種binary classifier的cross entropy,實際上在訓練的時候,真正的loss是會考慮樹狀結構的,真正的loss,classifier的output的目標,其實是希望給正確的樹比較高的分數,給錯的樹比較低的分數。
link |
不過因為這個部分講起來就比較複雜了,這個就跟我們課程的主軸比較不一樣,我們只是想跟大家講一下說,這些NLP的任務通通都是可以用deep learning硬train一發,真的是有機會做的,那細節就留給有興趣的同學自己去研究。
link |
另外一個方法叫做transition based的方法,transition based的方法它的精神是什麼呢?它的精神是說,我們有一個句子,我們怎麼用這個句子來產生它的constituency parsing呢?
link |
你再把這個句子裝到一個buffer裡面,再加上一連串的操作,一連串的action,就可以做到constituency parsing了。這個圖是從paper裡面截下來的,我們這邊實際舉一個例子來告訴你說這種transition based的approach是怎麼操作的。
link |
在這種transition based的方法裡面,你要有一個stack,那stack在最開始的時候它是空的,它裡面什麼都沒有,那你等一下可以放一些東西進去這個空的stack裡面。
link |
你要有一個buffer,buffer裡面放的是什麼呢?buffer裡面放的就是你現在準備要來做parsing的句子。那有三個可以採取的action,第一個可以採取的action是創造一個constituent。
link |
你會採取一個action叫create一個x,那這個x可以是什麼呢?這個x可以是np,可以是vp,可以是任何你想要create的某一種constituent。
link |
還有一個動作叫做shift,shift做的事情就是從buffer裡面把一個token移到stack裡面。第三個可以做的動作叫做reduce,代表我們已經產生了一個完整的constituent,用reduce來結束一個constituent的生成。
link |
那這樣講呢,你可能一定覺得非常的抽象,所以下一頁我們有一個具體的例子來告訴大家,現在假設有一個空的stack,有一個buffer裡面有一個這樣的句子,用這三個action怎麼製造一個在stack裡面製造出一個constituency的parsing tree。
link |
現在我們要parsing的句子就是the deep learning is very powerful,一開始我們的stack是空的,然後deep learning is very powerful這個句子會被讀到我們的buffer裡面去。
link |
那接下來呢,我們就要根據stack裡面存的東西跟buffer裡面存的東西決定要採取什麼樣的action。那現在第一個要採取的action叫做create,要create什麼呢?create一個s,s代表的就是一個句子。
link |
你在做parsing的時候,這個是個起手式,就是我們一定要create一個句子。採用這個action以後呢,你就把create句子這個token放到你的buffer裡面,代表我們現在要來創造一個句子了。
link |
那接下來呢,你要說在創造這個句子裡面我們要創造什麼呢?我們還要再創造一個名詞片語,我們要在這個句子裡面創造一個名詞片語。
link |
然後接下來呢,我們決定要採取shift這個動作,根據你現在存在buffer裡面的值,根據你存在stack裡面的東西,我們要採取shift。
link |
shift做的事情就是把buffer裡面的東西挪到stack裡面去,所以我們就把buffer裡面的第一個token,就是dip,放到stack裡面去。那因為stack裡面有兩個還沒有產生完畢的constituent,產生完畢特殊的符號。
link |
所以現在那個符號還沒有出現,還沒有執行那個action,所以這兩個constituent都還沒有產生出來。那dip被放進來以後,它就等於被放到了這個名詞片語裡面去,也等於被放到了這個句子裡面去。
link |
那接下來呢,再執行一次shift,那就把learning拿進來,learning就被放到名詞片語裡面去。那接下來呢,接下來根據stack跟buffer要決定什麼動作呢?
link |
現在決定要採取reduce。reduce的意思就是我們完成了一個constituent。好,我們現在把reduce這個動作執行了以後,我們最近一個被產生出來的constituent就會被完結。
link |
所以np這個nonface就被完結,就產生完了。所以nonface裡面就包含了dip跟learning這兩個token。
link |
接下來呢,我們再決定要產生下一個動作是什麼,然後根據這個stack跟buffer裡面的值,下一個動作是什麼呢?下一個動作是要創造一個動詞片語。
link |
創造一個動詞片語。創造完這個動詞片語以後,接下來呢,你的model決定要shift,就是把stack裡面的一個東西放到這個動詞片語裡面,所以ease就被放到動詞片語裡面。
link |
接下來你的machine要做什麼呢?現在動詞片語的產生還沒有結束,但是你的machine覺得它想要創造一個形容詞片語。
link |
在這個動詞片語裡面,就會再被創造了一個形容詞片語。接下來你的machine決定要shift,它就把buffer裡面的vary放到stack裡面,那這個形容詞片語裡面就多了一個vary。
link |
接下來你的model決定要再shift一個東西,就把buffer裡面的東西挪到stack裡面,現在buffer就空掉了,buffer裡面已經沒東西了,把buffer裡面的東西放到stack裡面去。
link |
因為這個形容詞片語還沒有結束,所以powerful就是形容詞片語的一個部分。
link |
接下來你的model看了看buffer,現在整個空掉了,看了看stack,決定它要做reduce,那就把最近的還沒有reduce、還沒有結束的constituent把它結束掉,所以形容詞片語就結束掉了。
link |
接下來它再決定要再reduce一次,剛才這個動詞片語還沒有結束掉,再reduce一次,動詞片語就結束掉了,再從這邊到這邊,這個範圍之內的東西都屬於動詞片語。
link |
最後再執行一次reduce,把還沒有結束掉的東西結束掉,還沒有結束掉的是這整個句子還沒有結束掉,所以執行了這個reduce以後,把這整個句子結束掉,從這邊到這邊都屬於這個句子的範圍。
link |
那你就產生一個constituency的partition tree了。總之,如果你剛才聽得沒有很懂,也沒有關係,總之透過一連串的操作,而只需要定義三種action,create、shift跟reduce,你就可以創造出一個constituency的partition tree。
link |
好,建成說了一句話,我看一下,這邊分享一個之前聽過的說法。
link |
Transition based好像跟RN的設計構想還是誕生有一些關係,因為我們好像可以把這些transition based的各種操作map到某種latent state,不知道是不是真的。
link |
我猜建成的意思是說,是先有transition based的parsing,然後人們根據transition based的parsing這個想法,設計出了RNN這樣子的架構。
link |
建成,如果你有更好的資料來源的話,其實歡迎你在社團上分享。這個聽起來還蠻有趣的,但我真的是沒聽過這個故事。
link |
我們到目前為止,在這個transition based的方法裡面還沒講到deep learning的部分,我只告訴你說這個transition based的方法是怎麼操作的。
link |
現在這個transition based的方法裡面的重點就是,怎麼決定什麼時候要採取哪一個action,所以你顯然就需要一個deep learning based的model來決定要採取哪一個action。
link |
但是那種transition based的方法不是有了deep learning才有啦,在deep learning的時代之前當然就有transition based的方法,只是過去你可能不是用deep learning的方法來決定你的action的。
link |
後來就有一個東西叫做RNN grammar,它就是用一個RNN來決定要採取哪一個action。
link |
那怎麼做呢?現在我們就是要根據stack裡面放的東西跟buffer裡面放的東西來決定我們要採取哪一個action。
link |
所以你可能就有一些RNN,把stack裡面的東西讀過,因為stack是一個sequence嘛,用個RNN把它讀過去,buffer也是一個sequence,用個RNN把它讀過去。也許之前已經採取過的action其實也是一個sequence,也用RNN讀過去。
link |
RNN都把它最後一個typeset的output拿出來,丟給一個network,這個network最終去決定說要採取哪一個action。
link |
聽到這邊,有人可能會覺得很興奮還是很困惑,就說要怎麼train呢?這些東西叫做action吧,聽到action是不是要用到reinforcement learning呢?這邊完全不需要用reinforcement learning,跟reinforcement learning沒半毛錢關係。
link |
這邊你實際上要怎麼做呢?你實際上的做法就是,因為你在training的時候其實已經有光truth了,你有正確答案,所以其實你知道說在每一個狀況應該要採取什麼樣的action才是對的。
link |
你已經知道說,現在你的buffer裡面有is very powerful,你的stack裡面有沒有結束的句子、沒有結束的名詞片語跟deep learning。你現在已經採取過的action有這些,那下一個正確的action你是知道的,因為下一個正確的action就是要結束這個名詞片語。
link |
所以根據你的training data的標註,你其實是有光truth,你知道接下來看到這樣子的狀況,應該要採取reduce才是對的。
link |
所以你要訓練你的RNN,訓練的目標就是,你的RNN把這些東西都讀過,把stack的東西讀過,把已經採取的action讀過,把buffer裡面的東西讀過,把他們讀出來的結果再通過一個network,它的output應該要是reduce。
link |
這整個process其實就是一個一般的分類任務,它不是什麼神奇的東西,它就是一般的分類任務,你只是把三種不同的action當作三種不同的類別。
link |
那訓練的方法呢,就跟一般訓練分類的方法是一樣的,你一般怎麼訓練這種classifier,你就怎麼訓練這個classifier,你就minimize course entropy而已,它是一個supervised learning的problem,因為你每一個狀況你都有正確的答案,知道採取哪一個action才是對的。
link |
這邊你是不需要用到RL的。還有另外一個做法是這個樣子的,這個方法其實我也把它歸類為transition based的方法,因為它跟transition based的方法非常非常的類似,只是講法上略有不同而已。
link |
這個方法是什麼呢?其實這一個方法,它比剛才講的RNN grammar出現的時間還要早,它是發表在2015年的NIPS。
link |
這一個方法就是直接用一個sequence to sequence的model,硬圈一個constituency的parser。
link |
Pepe的title也很有趣,他說,Grammar as a foreign language。為什麼取這樣的title呢?因為過去那個sequence to sequence model在2015年,當然現在不一樣了,現在sequence to sequence model已經滿街都是,任務都是用sequence to sequence model做的。
link |
但是在2015年那個時候,sequence to sequence model仍然不像今天這麼的流行,那時候sequence to sequence model的應用最常出現的都只有在translation上面。
link |
所以發明sequence to sequence model的團隊,當他們要把這個sequence to sequence model的技術用在parsing上的時候,他們就說,這個parsing的這個東西也很像是翻譯的問題。
link |
所以我們就用sequence to sequence model加attention,硬解,把parsing出來的parsing tree當作foreign language,所以他才會取這個title,說Grammar as a foreign language。
link |
這個想法是什麼呢?這個想法是這樣子的,我們今天要machine做的事情就是看這一串文字,根據這一串文字產生一個樹狀的結構,那我們其實可以把這個樹狀的結構表示成一個sequence。
link |
怎麼把一個樹狀的結構表示成一個sequence呢?其實有很多不同的方法,那我們這邊只是舉一個例子,這個例子是top-down的方法,你在表示這棵樹的時候,由上而下,由左而右,那你也不一定要由上而下,由左而右,你完全可以用自己喜歡的方法,反正可以把一棵樹表示成一個sequence就結束了。
link |
怎麼把樹表示成一個sequence呢?我們從這個樹的root開始,root有一個S,我們就放一個S,我們就在我們要把樹轉成的那個sequence裡面放一個S。
link |
然後接下來從左邊開始,每一個樹的每一個node都有左邊的node跟右邊的node,從都從左邊的node開始,左邊是NP,所以告訴我們說這個S下面的左邊是NP。
link |
NP下面也有左邊的node跟右邊的node,從左邊的node開始,左邊的node是deep,右邊的node是learning。
link |
這個NP下面的children都產生完以後,你要放一個符號代表children產生完了,所以我們放一個符號,用右括號代表這個NP裡面的東西都產生完了。
link |
接下來回到S這邊,現在S的左邊這個NP的部分都產生完了,都表示完了。
link |
接下來看右邊的部分,右邊的部分是一個VP,所以我們放一個左括號跟VP代表說我們現在進入了一個VP。
link |
VP有左邊的children跟右邊的children,VP左邊的children是什麼呢?左邊的children是一個is,那我們就把is放上來。VP右邊的children是什麼呢?右邊的children是一個形容詞片語,然後我們就把這個形容詞片語把它放上來。
link |
接下來我們再看這個形容詞片語裡面有什麼呢?它有very跟powerful,那我們就把very跟powerful放到sequence裡面。
link |
接下來這個形容詞片語產生完了,然後我們就把右括號補上去,代表這個形容詞片語產生完了。動詞片語產生完了,我們就把右括號補上去,代表動詞片語產生完了。句子產生完了,我們再把右括號補上去,代表這個句子產生完了。
link |
接下來我們就把這個樹狀結構已經轉成了一個sequence,你只需要一個sequence to sequence的model,把deep learning is powerful這個句子讀進去,期待這個sequence to sequence的model,就產生一個這樣子的sequence,就結束了。
link |
在剛才講的產生這個樹的方法,也就是這個tree traversal的方法,是由上而下,由左而右的。你能不能用別的方法呢?你完全可以用別的方法。
link |
你不一定要top-down,你可以bottom-up,你可以先產生deep,再產生learning,再產生NP。你也可以hybrid,先產生deep,再產生NP,再產生learning,這個都是可以的。
link |
你的這個tree traversal的方法其實有好幾個,你可以由上而下,你也可以由下而上,你也可以既由上而下,也是由下而上,一個hybrid的方法。
link |
到底哪一個方法比較好呢?這個前人有比較過了,由上而下就是見零不見樹,而由下而上就是見樹不見零,那要樹跟零都見,也許就是hybrid比較好吧。文獻裏面說hybrid比較好就是了,總之各種方法你都可以嘗試一下。
link |
其實你會發現,這個sequence-to-sequence的方法其實跟RMM grammar的方法沒有你想像的那麼不同。sequence-to-sequence的方法要產生這樣一串sequence,RMM grammar要決定action,但你也可以想成你的model其實就是產生了一串action的sequence。
link |
其實這邊的action sequence跟這個sequence-to-sequence方法裏面的sequence,它們是有一一對應的關係的。你要產生一個片語的時候,這邊就是有一個create,你要放一個詞彙進來的時候,這邊就是有一個shift,你要結束一個constitution的時候,這邊有一個用括號,這邊就是有一個reduce。
link |
所以你會發現說,其實sequence-to-sequence跟RMM grammar,它們要產生的東西根本就是一樣的,只是說法略有不同。一邊是說我們把tree轉成一個sequence,另外一邊是說我們要採取一連串的action。但這些action跟把tree轉出來的sequence,它們中間根本就是有一一對應的關係的。
link |
當然,如果我們直接看我們這些投影片,你會發現說sequence-to-sequence model跟RMM grammar還是略有不同。因為在sequence-to-sequence model裏面,你要把文字產生出來。但在RMM grammar裏面,你不用產生文字,你只要產生shift就好。你只要看到shift,就代表產生一個文字。
link |
但是事實上,在原始的sequence-to-sequence paper裏面,它就已經沒有要求要產生文字了。當時它就把所有的文字統統用叉叉來表示,它說這個是要一個normalization。
link |
所以今天它並不會要求你的model真的把這些文字產生出來,它只要產生叉叉就代表產生文字了。如果你要求你的model產生文字出來,到時候很麻煩,搞不好它把deep learning is very powerful讀進去,它output machine learning is very powerful,那你就到時候不知道算對還是算錯了。
link |
sequence-to-sequence model有時候難以掌控,你根本不知道它會output什麽東西。所以我記得,在最原始的paper裏面,它就已經沒有要求model產生詞彙了,它就要求model產生一個叉叉代表詞彙。
link |
有人可能會問說,用sequence-to-sequence model直接產生這個詞彙,會不會有什麽奇怪的問題呢?比如說還沒有產生足夠的誘發號,就整個生成的過程結束了呢?這件事不是沒有可能,但產生的機率非常非常低。
link |
你可以看一下原始的paper,它會告訴你說,這個機率大概1%或者甚至更低,所以幾乎不會產生。如果真的產生,反正你用一個規則把它修掉就是了。
link |
我們到目前為止講的parsing都是supervised parsing。有在訓練的時候,你要給每一個句子標上constituency的parsing tree,你的model才有辦法進行訓練。
link |
但有沒有辦法unsupervised學一個parsing呢?有沒有辦法給你的machine讀一大堆句子以後,你的machine自動就知道說deep learning合起來應該是一個constituent,very powerful合起來應該是一個constituent呢?
link |
其實是有可能的。這個部分我們就不細講,其實莊永松助教在去年的machine learning課有講過unsupervised parsing,我就把相關的連結放在這邊給大家參考。