back to index
[DLHLP 2020] Deep Learning for Question Answering (2/2)
link |
我們上次呢,講到這個地方。那接下來呢,要跟大家講各式各樣的問題,還有這些不同類型,它們可能的解法。
link |
那等一下呢,我們會講三大類的問題。第一類的問題我叫做Simple Question,第二類的問題叫做Complex Question,第三類的問題叫做Dialogue Question。那由上到下呢,分別是由簡單到越來越難。
link |
那什麼是Simple Question呢?在這邊所謂的Simple的意思是說,這些問題只需要兩步就可以解決了。第一步是Match,第二步是Extract。
link |
那這邊舉一個具體的例子。舉例來說呢,右邊這邊是Square非常標準的題型。Square的Compass裡面,通常它的文章跟問題就長得像右邊舉的範例差不多。
link |
那機器在讀完這篇文章以後,你問機器一個問題,What caused precipitation to fall?那假設你不知道什麼是Precipitation,也沒有關係,反正你可以把文章裡面有提到這個你根本不知道的單字的位置把它先圈出來。
link |
這個Precipitation出現在這個地方,出現在這個地方。那你再看這個問題裡面還有哪些比較重要的詞彙呢?比如說Fall可能是一個重要的詞彙,Fall有沒有出現在文章裡呢?有的,它出現在文章裡的這個地方。
link |
那現在看起來這個句子Question裡面兩個比較重要的詞彙在這個句子裡面都有出現,那答案就從這個句子裡面找,我們這邊可能就抽出Gravity作為答案,那這可能就是正確的答案。
link |
所以像Squat這個Compass裡面很多問題都是做Match,然後你就可以把答案抽取出來。所謂做Match的意思就是找找看說文章裡面有沒有哪些段落,有沒有哪些句子,它裡面有出現問題裡面的關鍵詞彙。
link |
然後接下來在這個句子裡面找出某一個詞彙當作你的答案,你先做Match這件事,找出重要的句子,然後再做Extract這件事,把詞彙抽出來就結束了。
link |
好,那這類Simple的Question怎麼用Neural Network來實踐呢?這個經典的做法就是使用Question到Context的Attention。
link |
好,那這個Question到Context的Attention是怎麼實作的呢?首先,你有一個Knowledge Source,通常它是一篇文章,你把這篇文章丟到一個Source的Module裡面,然後文章裡面的每一個Token,或者是每一個Word,或者是每一個Sentence,取決於你現在想要使用的單位是什麼。
link |
文章裡面的比如說每一個Token,它就會變成一個Embedding。好,那問題的部分也如法炮製,把一個問題丟到這個問題的Module裡面,然後這個問題的Module就Output一個向量。
link |
那這個向量代表了問題裡面的整個問題完整的資訊。好,那如果是在過去還沒有BERT的年代,這邊你可能就用一個Bidirectional的LSTM,這邊你可能就用一個LSTM把問題讀過去,把最後一個Time Step的Embedding抽出來,就結束了。
link |
那當然如果是今天,你可能就會選擇用BERT,每一個Token都可以得到一個BERT的Embedding。那Question,如果你只要一個Embedding的話,也許你會選擇抽個CLS那個Token的Embedding等等。
link |
好,總之現在你的Knowledge Source變成一排Vector,你的Question變成一個Vector。好,那接下來怎麼實踐Match這件事呢?你就用Attention。那你發現Attention這件事情,其實就是在做Match這件事情。
link |
因為我們在做Attention的時候,其實就是把這個Query的Vector跟這邊的每一個Embedding都去計算一個相似度,得到一個Attention的Weight。這邊α1到α5就是Attention的Weight,代表了這些Embedding跟這個問題的相似度。
link |
而計算相似度這件事情,其實就是Match。我們想要找出跟這個問題有關係的這些詞彙,出現在文章裡的哪些部分。
link |
那接下來我們要做Extract這件事情,我們要把答案抽取出來。那怎麼把答案抽取出來呢?你可以用的做法就是把這些Weight對這些Vector做WeightedSum,得到一個新的Vector,再把這個新的Vector丟到Answer的Module,讓Answer的Module去做Process。
link |
而你在做WeightedSum的時候,你在把這些α對某些Vector做WeightedSum的時候,不見得要使用這些拿來計算Matching的Vector。
link |
常見的做法是說,你的這個Source Module會產生另外一組Vector,這一組Vector也是每一個Token有一個Vector。那今天呢,這個α是用藍色的Vector算出來的,但是在做WeightedSum,在把某些Vector用α做WeightedSum的時候,是對綠色的這些Vector做WeightedSum。
link |
你就得到這個藍色的向量,那有這個藍色的向量以後,你把這個藍色的向量丟到Answer Module裡面,再看Answer Module要怎麼把答案找出來。
link |
舉例來說,如果今天是像Baby那種Corpus,你的答案只是一個單詞,那你的Answer Module就是一個Classifier,這個Classifier根據這個向量可以得到正確的答案。
link |
那如果今天你是像Squad這種題型,你的Answer Module必須要找出一個Time Step,舉例來說,在還沒有Birth的年代,你的Answer Module可能是一個LSTM,那也許這個Vector就是LSTM的Initial State。
link |
所以接下來就看這個Answer Module拿這個藍色的向量做什麼事,然後期待說Answer Module可以根據這個藍色的向量,抽取出正確的答案。
link |
所以發現說,用Query to Context的Attention,我們就可以做到Match,然後Extract這樣的Process,那你就有機會用這樣子的Network架構來簡單的,只要Match跟Extract就可以解。
link |
那像這樣子的QA的Model,它的起源非常非常的早。第一個使用Query to Context的Attention的Model,就是鼎鼎大名的End-to-End的Memory Network。
link |
你會發現它是一個非常早的上古神獸,它是發表在15年的News,五年前的東西,在Deep Learning的這個領域看來就是不可思議的古老神獸。
link |
你畫得差不多,你有一個問題進來,你有一篇文章,那個時候並不是拿Token當作單位來做Embedding,也不是拿Word當作單位來做Embedding,那個時候是拿Sentence當作單位來做Embedding。
link |
每一個Sentence它會有一個向量,然後接下來你有兩個Transform,一個Transform製造那些拿來算Matching的Vector,另外一個Transform製造拿來算Weighted sum的那些Vector。
link |
接下來,你有這些拿來做Matching的Vector以後,根據這個Question,你就可以計算出一組Attention的Weight,跟這組Attention的Weight,跟這些拿來做Weighted sum的Vector做Weighted sum,得到一個新的Vector叫做O.
link |
你把這個O跟原來的Q加起來,一起丟到Answer的Module裡面,然後就可以得到正確的答案。
link |
因為Answer Memory Network最早是被用在Baby上面,所以它會把QA當作是一個Classification的問題,所以這邊只需要解一個Classification的問題,預測出正確的答案是哪一個詞彙,就結束了。
link |
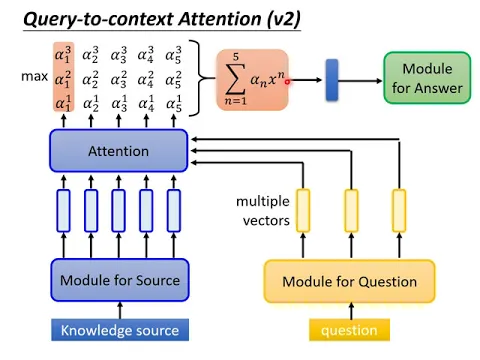
那你可能會問說,也許我們今天並不是用一個Vector來表示一個Question,也許今天Question的表示方式跟Multisource一樣,也是一排向量,Question裡面的每一個Token,我們也給它一個Embedding。
link |
那這個時候,怎麼使用Query to Context的Attention呢?那這邊其實有不同的做法,那我就舉一個常見的Typical的做法。
link |
怎麼做呢?把這邊的每一個Vector都分別去做Attention。
link |
你把第一個Vector做一下Attention,得到一排Attention的Weight。你把第二個Vector去做Attention,得到另外一排Attention的Weight。你再把第三個Vector去做Attention,又得到另外一排Attention的Weight。
link |
那接下來呢,現在每一個Embedding,每一個Knowledge Source裡面的Embedding,都已經有三個Attention的Weight。要用哪一個才是對的呢?也許你做個Max,你就取一個Max,看這三個Alpha裡面,哪一個值最大,就出來代表全體。
link |
那你現在從每一個Column裡面呢,都找出一個最大的Alpha出來代表全體以後,你就每一個位置,每一個Embedding都有一個Alpha。
link |
然後接下來呢,你一樣可以做Weighted Sum,抽出一個Vector,再把這個Vector丟到Answer的Module裡面。
link |
這是另外一種做Query to Context的Attention的方法。那如果你今天你的Question是用Super Vector來表示的時候,也許你會用這樣的方法來做Query to Context的Attention。
link |
那這邊呢,再舉一個文獻上的例子,讓你知道說這種方法是真的有被廣泛使用的。那這邊舉的是VQA的例子,也就是說給機器看一張圖片,再問它一個問題,問它說貓呢,有沒有在籃子裡面,希望它可以得到正確的答案。
link |
那怎麼做呢?這張圖片呢,可能先通過CNN,通過CNN以後呢,這張圖片的每一個位置都會被一個向量表示。
link |
接下來呢,你再把每一個位置的向量做兩種不同的Transform,一種Transform的結果是要拿來做Matching,另外一種Transform的結果是要拿來做Weighted Sum,是要拿來Extract資訊。
link |
那在這個問題的部分呢,問題的部分是一排文字,那每一個文字它其實都可以被表示成一個Embedded,所以一個問題進來,它其實是一個Vector的Sequence。
link |
那在這個圖上就很簡單的告訴你說,這邊有一個Vector的Sequence,這邊有一群拿來算Matching的向量,這個拿來算Matching的向量是這個圖片上的每一個小區域都有一個向量。
link |
接下來你就可以計算出Attention,然後告訴Machine說,現在右下角這個位置是特別需要關注的,右下角這個位置它的Attention Weight是比較大的,那你再根據這個Attention的Weight去做Weighted Sum。
link |
把這個Attention的Weight拿來跟正面的Vector做Weighted Sum,那就抽出一個向量出來,再把這個向量跟Q相加,然後通過Answer的Prediction Model就會得到正確的答案。
link |
那VQA通常也是被當作是一個分類的問題,所以Machine就直接Output一個詞彙,Output一個詞彙作為正確的答案。
link |
比如說這邊要Output的詞彙就是No,輸出No就是正確的答案。
link |
那這個部分有一堆的向量,要怎麼做Query to Context的Attention呢?
link |
那在這篇CVPR16的Paper裡面,它用的做法就是我剛才講的Query to Context的Attention V2,也就是說這邊有一堆的Vector,你的問題是被表示成一堆的Vector,總共有大T一個Vector。
link |
那怎麼辦?就把大T一個Vector,每一個Vector都去計算Attention的Weight,所以我們得到大T組Attention的Weight。
link |
但是有大T組Attention的Weight,我們應該要用哪一組才好呢?那就取Max,把這大T一個Matrix,它們同一個位置的Element都取Max出來,就得到最終的Attention。
link |
所以你可以想像說,如果用這個做法,今天輸入的問題是Is there a cat in the basket? 所以裡面可能Cat是一個關鍵的詞彙,Basket是一個關鍵的詞彙。
link |
當你輸入Cat的時候,應該這邊會有比較大的Attention Weight,當你輸入Basket的時候,籃子的地方會有Attention Weight。
link |
那如果你做這個Max的Operation,那應該就是Cat的地方跟籃子的地方都會被Attent到。
link |
所以今天機器會知道貓在哪一個位置,也會知道籃子在哪一個位置。
link |
這是另外一種Query to Context的Attention的變形。
link |
那還可以反過來做,我們剛才是用Query to Context,也就是對我們的Knowledge Source去做Attention。
link |
那反過來也可以用Context去對Query做Attention。
link |
同學們有問題就可以隨時提出來,我們現在繼續講怎麼拿Context對Query做Attention。
link |
那這個Context裡面,每一個Token都會用一個Embedding來表示,然後我們用這個Embedding來對Question裡面的每一個Embedding做Attention。
link |
所以剛才我們是拿Question的Embedding去對Context,也就是我們的Knowledge Source裡面的每一個Embedding做Attention。
link |
那現在反過來,拿Source裡面的每一個Embedding去對Question裡面的每一個Embedding做Attention。
link |
一樣得到一組Attention的Weight,那一樣會對Attention的Weight做Weighted sum,得到一個黃色的Vector。
link |
那接下來呢,你再把這個黃色的Vector跟這個Embedding拿來做Attention的這個Embedding,做某一種程度的Integration,做某一種程度的結合。
link |
那要怎麼結合呢?這個文獻上就有各式各樣的花式做法,比較簡單的就是把它們相加。
link |
可是為什麼要相加呢?你可以用很多其他的方法,你可以做Element wise的相乘,你可以把它直接接起來。
link |
你可以把剛才上述所有的方法通通都用上,然後拼成一個很巨大的Vector。
link |
你可以用各式各樣的方法,把從Query這邊得到的資訊跟從Source這邊得到的資訊,把它Integrate起來,把它結合起來。
link |
那這個要如何結合,這塊位置要如何結合,有千千百百種的做法。
link |
那我們就經過結合以後呢,我們就把這個藍色的向量變成這個綠色的向量。
link |
那這個綠色的向量裡面是有來自Question的資訊。
link |
那這邊每一個藍色的Vector都會對Question去做Attention。
link |
不過因為這邊每一個藍色的Vector都不一樣,所以這邊算出來的Attention weight都不一樣。
link |
每一個藍色的Vector都不一樣,雖然Question的這一排Vector是一樣的,但是因為這邊Source的每一個Vector都不一樣,所以這邊每一個Vector都會得到不同的Attention weight。
link |
那所以你做Weighted Sign後結果也不一樣,然後你把藍色的Vector跟這個黃色的Vector做Integration以後的結果也會不一樣。
link |
總之做Context to Query的Attention就是把Query的資訊加到這些Embedding裡面。
link |
那每一個Query每一個這邊的Embedding會被加什麼東西都是不一樣的。
link |
這邊每一個Embedding從Question這邊取出來的資訊都是不一樣的。
link |
這一排Embedding加上Question的資訊以後就變成綠色的這一排Embedding。
link |
然後接下來你再把綠色的這一排Embedding丟到Answer的Module,看Answer的Module要怎麼把答案找出來。
link |
那這個就是Context to Query的Attention。
link |
那像在Square這種Compose上Context to Query的Attention是在有Birds之前蠻主流的一種解法。
link |
那以下就舉幾個經典的Network給大家看。
link |
那這些經典的Network我們就不會詳細解釋它的架構,因為一個一個解釋就非常的流水帳,你一定不會覺得特別有趣。
link |
那我們就是提一下這些經典的架構,提一下它的名字,讓你知道說過去在有Birds之前還有這些Model曾經存在過。
link |
我們今天就是把它的化石拿出來給大家看一下。
link |
有一個東西叫做RNet,RNet它就做了剛才我們有看到的Context to Query的Attention。
link |
它的Query放在左邊,它的Context放在右邊。
link |
它有用Word Embedding,也有用Character Embedding。
link |
那現在每一個Word都會變成一個Embedding。
link |
接下來每一個這個Passage,也就是每一個這個Knowledge Source裡面的Embedding,都會拿去對Question做Attention,抽出一些資訊。
link |
那在RNet裡面呢,我們就把來自Question的資訊跟來自Passage、來自Knowledge Source的資訊把它Concatenate起來。
link |
那接下來呢,它做了另外一件事情,這件事情它叫做Self-Matching。
link |
Self-Matching做的事情是什麼呢?
link |
Self-Matching是說,我們在這個Knowledge Source裡面的每一個Vector,兩兩間,互相都要做Attention。
link |
每一個Vector都去跟其他人做Attention,抽出一些資訊。
link |
每一個Vector都跟其他人做Attention,抽出一些資訊。
link |
每一個Vector都跟其他人做Attention,抽出一些資訊。
link |
當年RNet的說法就是,因為一篇文章太長了,這邊輸入是一篇完整的文章,太長了,也許Machine會不知道整篇文章的內容。
link |
所以怎麼辦?我們把每一個Token都對其他人去做Attention,讓文章在,讓這個Model在Process每一個Token的時候,它都了解整篇文章的資訊。
link |
那個時候RNet把這招叫做Self-Matching。
link |
但是你從現在的觀點來看,這個Self-Matching是什麼呢?
link |
它就是Self-Attention。
link |
不過RNet是發表在17年的ACL,那個時候甚至都還沒有Attention is All You Need那篇文章。
link |
那個時候人們還不知道Self-Attention這個東西。
link |
所以RNet裡面雖然有一個跟Self-Attention一樣的機制,但它不到Self-Attention這個詞彙,那個時候叫做Self-Matching。
link |
有了Self-Matching以後,最終Input的Source每一個Token都有一個向量了,然後你就有一個Answer的Module。
link |
Answer的Module其實也會看Question這邊的資訊,也會看Question的Embedding。
link |
最終就得到初始的每一個詞彙、每一個Token是Begin的機率跟每一個Token是End的機率,就可以把答案抽出來了,這個叫RNet。
link |
還有另外一個知名的Network叫做FusionNet。
link |
這個FusionNet是台大的一位同學去微軟實習的時候做的。
link |
這個FusionNet它是怎麼做的呢?它也有Context Question的Attention。
link |
就Question的Embedding進來,通過很多很多層,有很多層不同Level的Question的Embedding。
link |
Context的部分就會去對Question做Attention,而且Context不會只對一種Question的Embedding做Attention,
link |
它會對多種不同的Question、不同Level的Embedding都去做Attention。
link |
得到很多種不同層級的Attention以後,再把不同層級的Attention的結果通通綜合起來。
link |
接下來FusionNet在得到答案之前,還有一個Network架構,它叫做Self-Boosting的Fusion。
link |
這個所謂Self-Boosting的Fusion是什麼呢?這個Self-Boosting的Fusion就是Self-Attention。
link |
那個時候還不知道什麼是Self-Attention,還不知道Self-Attention那個詞彙,所以類似的機制有各式各樣的名字。
link |
在FusionNet裡面把這個Self-Attention叫做Self-Boosting的Fusion。
link |
詳細的內容我們就不細看,大家可以自己再去找文件來看。
link |
我們剛才講了Query to Context的Attention,也講了Context to Query的Attention。
link |
那哪一種比較好呢?你其實不需要比哪一種比較好,你不就兩種都用就好了嗎?
link |
所以有一個Network叫做Bidirectional的Attention Flow,縮寫叫做Bidef,它就是兩種Attention。
link |
不管是Query to Context,還是Context to Query,兩種Attention通通來用。
link |
那我們可以簡單的看一下這個Bidef裡面的圖啦。
link |
Bidef裡面的圖有這樣子,這邊h1到hT代表的是Context,也就是Knowledge Source。
link |
那Query如果有多個Vector的時候,它就是這個Query to Context的第二個型態。
link |
你就把這邊的Query的每一個Vector都去跟Context的每一個Vector計算Attention。
link |
所以Context裡面的每一個Vector都得到了一排Attention的weight,但到底要哪一個weight呢?
link |
選對方,就這樣。Context to Query的Attention,就是說我們把每一個Context的Vector都去跟Query的每一個Vector去做Attention。
link |
算Attention後,weighted sum,你就可以把Query的資訊跟Context裡面每一個Embedded資訊把它併在一起。
link |
這是Context to Query的Attention。
link |
整個Bidef是怎麼運作的呢?這是Bidef的Network架構,這個輸入的地方,每一個詞彙都會抽它的Word Embedding跟它的Character Embedding。
link |
你會把Character Sequence通過一個CNN加Max Boolean得到Character Embedding,再把它們併起來,當作是Model的Input。
link |
你可以想見說這個是在BERT時代之前的Work,這個給人一種很有歷史感的這種感覺。
link |
接下來就使用Query to Context和Context to Query的Attention。
link |
做完這種Attention以後,這個Query to Context的Attention會給你一個Vector,然後把這個Vector丟給LSTM。
link |
Context to Query的Attention會在Context的每一個Embedding都有一個Vector。
link |
Context的每一個Embedding都有一個Vector。
link |
再把這個結果都丟到LSTM裡面去,LSTM就可以幫我們找出初始的位置跟結束的位置。
link |
其實在Bidef裡面它還有一個小設計是,先找出初始的位置,再根據初始的位置找出結束的位置。
link |
這個設計其實也是蠻合理的啦,因為你可以想見說這個初始的位置跟結束的位置,它們可能會出現在非常靠近的區域。
link |
尤其是在Square裡面,它的Answer通常不會超過五個詞彙。
link |
所以如果你已經identify出初始的位置,那結束的位置就在初始的位置之後的五個詞彙之內。
link |
所以你會看到蠻多過去的QA Model在設計的時候都是先找出初始的位置,再找出結束的位置。
link |
還有一種也同時使用Query-to-Context跟Context-to-Query的做法,叫做Dynamic Co-Attention Network。
link |
Dynamic Co-Attention Network是怎麼運作的呢?
link |
那我們這邊就很快的帶大家看過這個圖,那如果你沒有聽得很懂,或看這個圖覺得密密麻麻的,好多線在搞什麼,也沒有關係。
link |
我只是想要告訴你說Query-to-Context、Context-to-Query除了Bidef以外,其實還是有不同的用法的。
link |
Query這邊是用三個向量來表示,文章這邊也就是Context也就是Dolly Source,它是用五個向量來表示。
link |
那Query的三個向量就會去對Document的五個向量去做Attention。
link |
然後你就會得到一個新的Query,就Query這邊的每一個Vector都去跟Document做Attention。
link |
所以Query這邊的每一個Vector都會得到一組Attention的位置。
link |
Query這邊的每一個Vector都會從Document這邊做Weighted sum,抽出一個Vector。
link |
Query有三個Vector表示,那用Attention就抽出三個Vector。
link |
這邊等於就是先做Query-to-Document的Attention。
link |
那這邊的這個Query-to-Document的Attention的方法,跟我們剛才講的兩種Query-to-Document的Attention的方法都不一樣。
link |
這等於是第三種Attention的方法。
link |
那接下來呢,它先做完Query-to-Document的Attention,再做Document-to-Query的Attention。
link |
所以這邊就有一個Document-to-Query-Attention的步驟。
link |
就是說,我們把這邊的這五個Vector,分別去對這三個Vector做Attention。
link |
所以這邊這五個Vector,從這三個Vector去做Weighted sum,又得到另外五個Vector。
link |
然後呢,再把這個資訊跟舊的資訊呢,把它拼起來,然後呢,得到新的Document的Embedding。
link |
所以Document有五個Token,這邊就有五個Embedding。
link |
然後再用Attention的Module,這邊是Bidirectional的LSTM,去找出最終的答案。
link |
好,那這個部分如果你聽得沒有很懂也沒有關係,你只需要知道說,
link |
這個Context-to-Query、Query-to-Context的這種Attention呢,用起來其實是有各式各樣的變化的。
link |
好,接下來呢,有一個東西叫做QnA。
link |
那QnA跟剛才講的Network其實沒有太大的差異。
link |
一樣是把文章讀進來,一樣是把問題讀進來。
link |
文章跟問題呢,都會稍微先各自做一下Embedding。
link |
然後接下來呢,再做Context-to-Question的Attention。
link |
因為這邊也是Context-to-Query跟Query-to-Context兩個方向都有使用。
link |
這邊也是兩個方向的Attention都有使用。
link |
好,那使用完兩個方向的Attention以後呢,接下來再通過幾層Network。
link |
這邊的這個Answer的Module呢,是比較複雜的。
link |
有很多層的Network,再找出Start的每一個Token,它的Start的機率跟End的機率。
link |
QnA它一個跟過去的Model都不一樣的地方是,
link |
它已經進入了18年,那個時候已經知道了Self-Attention。
link |
所以QnA是沒有RNN的,它裡面就是憑藉著Self-Attention來考慮整篇文章或整個問題的資訊。
link |
而QnA呢,我認為它應該是BERT家族之外的最後一道榮光。
link |
QnA它在SQUAD上得到了很好的結果,接下來有了BERT以後,就再也沒有人提過去的Model了。
link |
所以QnA是最後一個沒有使用BERT的知名的Model。
link |
那個時候BERT一出來以後,如果你手上的研究還沒有投國際會議,就直接就放棄吧。
link |
你不用做了,只要不是BERT的work,投稿都不會上了,都不必再做了。
link |
所以QnA是BERT家族之外的最後一道榮光,接下來就進入大家都熟悉的BERT的時代。
link |
你就把Knowledge Source跟Question中間放一個Special的Token,代表它們的分隔。
link |
然後把Knowledge Source跟Question都一股腦的丟到BERT裡面去。
link |
然後Knowledge Source會得到一排Embedding,Question也會得到一排Embedding。
link |
接下來你的Answer Module會在這些Knowledge Source的Embedding裡面找出Start跟End的位置。
link |
如果你今天是做這種Square的這種類型的問題的話,那你的Answer Module裡面就有Start跟End,然後可以找出Answer的Time span在哪裡。
link |
那為什麼BERT的Performance會好呢?
link |
前面之所以要鋪成這麼長,講了那麼多的歷史的遺跡,拿了那麼多化石出來給大家看,
link |
就是為了要顯示告訴大家說為什麼BERT今天會好。
link |
你想想看,在BERT裡面有非常大量的Self-Attention的Layer。
link |
這些Self-Attention的Layer,它可以做到Context-to-Query的Attention。
link |
我們在做Self-Attention的時候,把這些Context的內容會去Add這些Question的內容。
link |
你也做了Query-to-Context的Attention,因為這些Question裡面的內容,你也會去Attend這個Context裡面的內容。
link |
而你也做了過去很多Paper有做的Self-Matching跟Self-Boosting這樣子的東西,那過去不知道什麼叫做Self-Attention,所以叫Self-Matching或Self-Boosting,其實就是Self-Attention。
link |
在BERT裡面,當然有一大堆,BERT裡面做了好多好多次的Self-Matching或者是Self-Boosting。
link |
所以你會發現說,過去Model裡面的東西,過去這些各式各樣的Module,可能不是無死線在一個Model裡面。
link |
但是在BERT裡面,這些你可以想像到的Attention,通通都有。
link |
所以我們拿過去的這些化石出來給大家看,就是要讓大家了解說,QA的這個問題一路走來,是怎麼演化到今天BERT的這個樣子。
link |
而你從BERT再去看過去的Model,你就會發現說BERT裡面,有著過去Model裡面都有的這些東西。
link |
BERT是一個全新的Model,但是它裡面的機制,它是過去QA Model所流淌的血脈。
link |
而它結合了過去所有QA Model有的機制,所以難怪它可以得到最好的結果。
link |
今天這種Simple Question已經不能滿足人類的需求。
link |
我們期待機器可以解更複雜的問題,也就是期待機器可以做到推論。
link |
簡單來說,所謂的更複雜的問題,就是你沒辦法直接用Match and Extract來解的那些問題。
link |
那有幾個知名的Corpus,我們先來講有哪些Corpus裡面有這種比較複雜的問題。
link |
一個例子叫做Crangeroo,那Crangeroo這個Corpus是這樣子。
link |
你有好幾段文章,然後有一個問題是問你,舉例來說,在孟買的Heming Garden,它是在哪一個國家?
link |
孟買不是國家,所以你不能回答孟買,這是錯誤的答案。
link |
你要回答說,孟買的這個花園到底在哪一個國家呢?
link |
如果你今天是用Extract and Match的方法,你沒有辦法找到正確的答案。
link |
因為在這些文章裡面,在你的Knowledge Source裡面,沒有任何一個Source,它直接告訴你說,這個花園到底在哪一個國家裡面。
link |
我特別Google了這個Heming Garden的樣子,它大概長這個樣子。
link |
據說它的特色就是,裡面有很多很有藝術感的植物,它把植物修剪得很有藝術感。
link |
像這個東西到底是什麼呢?我其實也看不出來。
link |
不知道這是一個人嗎?他拿著吉他嗎?還是這是一隻鯨魚嗎?還是這是一個蜻蜓,停在一個彎曲的枝幹上嗎?
link |
不知道,反正據說裡面就是有很多這樣子的造景。
link |
那要怎麼解這種問題呢?機器必須要先知道說,這個花園它在孟買。
link |
接下來,它要再去讀另外一篇跟孟買有關的文章,知道說孟買其實是在印度裡面,然後期待它可以選出正確答案。
link |
那其實Kunguru這個Corpus它是選擇題,所以除了印度這個選項以外,它會故意出一些其他的國家作為選項來誤導。
link |
舉例來說,在這篇有提到這個花園的文章裡面,又提到了阿拉伯海。
link |
另外一篇文章有提到阿拉伯海附近有哪些國家呢?有巴基斯坦、伊朗、索馬利亞等等。
link |
它就把這些國家的名字也放到問題裡面,希望可以誤導機器的判斷。
link |
那Kunguru這個Corpus比較讓人詬病的地方是,它的問題不是真正的問題。
link |
它的問題其實是把Knowledge Base,其中一個Knowledge Base就是由一個Triple所組成的。
link |
就假設你有一個Knowledge Base,它就會告訴你說,這個花園它在哪個國家呢?它在印度。
link |
它會把這個Knowledge Base裡面的其中一塊拿掉,用一個問號置換掉,然後要求你把問號的部分填上去。
link |
那這個Corpus為什麼叫做Kunguru呢?它是來自於袋鼠的Kunguru。
link |
為什麼跟袋鼠有什麼關係呢?因為你今天要回答這篇文章的問題的時候,
link |
你要回答這個問題的時候,你必須要在不同的文章間跳來跳去來擷取資訊,才能夠回答問題。
link |
所以這個Corpus叫做Kunguru。
link |
那還有另外一個Corpus叫做Hapa QA。Hapa QA的問題就是真正的問題了,
link |
就不是從Knowledge Base裡面擷一個Knowledge出來當作問題,它是真正的問題。
link |
那像在Hapa QA裡面,它就會考你一些,比如說它說2015年的MVP是在哪一個球隊裡面。
link |
所以你就要先找出2015年的MVP是誰,是一個叫做Booty Hill的人。
link |
那Booty Hill是哪一個球隊的人呢?它是這個球隊的人,那你就可以得到正確答案。
link |
但是你沒有辦法只看一段文字就得到正確答案,你沒辦法直接做Extract and Match,
link |
你必須要看多篇的文章和多段的文字,把不同的資訊從多段不同的文字裡面綜合起來,你才能夠得到正確答案。
link |
那Hapa QA裡面有一些特難的問題,舉例來說,像這個問題,
link |
它問你說Loss Alone跟Gaster這兩個樂團,他們的成員數目是不是一樣多的。
link |
有一段文字提到Loss Alone這個樂團,有一段文字提到Gaster這個樂團,那它也有分別告訴你說這兩個樂團裡面有多少的成員。
link |
但是Machine必須要自己知道說,從這段文字裡面計算出Loss Alone成員的數目,再從這段文字裡面計算出Gaster成員的數目,
link |
然後最後經過比對後得到正確答案說這兩個樂團是有一樣多成員的。
link |
所以Hapa QA裡面有很多頗為困難的問題,是遠超過過去Simple Questions可以回答的範圍。
link |
那為什麼Hapa QA叫做Hapa QA呢?有兩個原因,一個次要的原因是說,據說是這群作者在吃火鍋的時候想到要做這個Compass的計劃,所以叫做Hapa QA。
link |
然後另外一個比較主要的原因是因為,今天你要回答這些問題的時候,你必須要把多個不同的段落裡面的資訊抽取出來。
link |
比方我們煮火鍋的時候,要把各種不同的素材丟到同一個鍋子裡面才能煮一鍋好的火鍋。
link |
那Hapa QA是一樣,你需要從文章的各個不同的段落裡面擷取資訊出來,才能夠得到正確的答案。
link |
那在Hapa QA之後,還有一個Compass叫做Drop。Drop它是Discrete Reasoning over the Text in the Paragraph的縮寫。
link |
什麼叫做Discrete Reasoning呢?其實這邊它所謂的Discrete Reasoning就是要機器算數學的問題。
link |
所以Drop裡面很多的問題都像是數學的應用題。舉例來說,這邊有一篇文章說,有一個叫做無題的圖畫,它以16.3 million的天價賣出去了。
link |
其實你可以自己去Google一下這幅圖長什麼樣子。那比本來大家所估計的12個million還要高。
link |
問題就是,今天這個無題的圖畫,它的售價比當初估測的12個million還要高出多少?
link |
答案是16.3-12是4.3個million。這個答案沒有出現在文章裡的任何地方。
link |
機器要解一個數學的問題,它把16.3抽出來,把12抽出來,然後製造16.3-12得到4.3個million才能得到正確的答案。
link |
或是我們舉另外一個例子,你機器必須要學會做一些加法。舉例來說,這邊有一個問題是,JNA這個組織成立了一個戰鬥團。
link |
它們什麼時候成立戰鬥團呢?如果你只看這篇文章,你沒有細看的話,你會發現文章裡面只提到一個日期,是1992年的3月2日。
link |
它是正確答案嗎?它不是正確答案,因為文章裡面說,JNA在某個事件發生後的隔天成立了戰鬥團。
link |
所以它成立戰鬥團的時間不是3月2日,是3月2日的隔天,是3月3日。所以機器必須要知道,所謂的隔天就是把日期加1,3月2日的隔天就是3月3日。
link |
或者是這邊還有一個變態的問題,就是要問你說,這邊給你一個文章,然後再問你說,哪一個人踢進最多球?這邊有兩個人,有一個人叫做Matt,有一個人叫做John。
link |
他問你說Matt跟John,誰踢進比較多球?所以機器要一邊讀這篇文章一邊算說,這邊Matt踢進一球,John踢進一球,這個人也是John,他也有踢進一球。John又再踢進一球,John踢進比較多,所以答案是John。
link |
Drop它在出題的時候,其實做了一個很變態的事情,它是抱著惡意出題,特別把ByteDef的model拿出來,今天出的問題一定要讓ByteDef答錯才行。
link |
所以如果你拿ByteDef的model去做Drop,你得到的正確率會是0,因為Drop它出題的時候,就是要出那些ByteDef沒辦法答對的題目。
link |
所以如果是ByteDef,我剛剛講過ByteDef,它就是有做兩個方向,context-to-query,query-to-context的attention。
link |
如果你堅持用ByteDef去做的話,都會慘掉,ByteDef只會從文章裡面抽一段出來,ByteDef看到這個問題,它就抽個數字出來說16.3 million,是錯的。
link |
或者這邊ByteDef就抽個日期出來,是錯的。這邊ByteDef隨便弄個人名出來,是錯的。Drop出題的時候,會故意出這種ByteDef,會答錯。
link |
那怎麼解這種需要reasoning的問題呢?其實像這種需要reasoning的問題,過去也是有的。
link |
其實早在Baby的那個時候,就已經有這種需要reasoning的問題了。
link |
舉例來說,在Baby的問題裡面,有一類的問題長得像是這個樣子。
link |
這篇文章裡面有提到說,Brian是個青蛙,Lily是灰色的,Brian是黃色的,然後Julius是綠色的,然後Greg是個青蛙,然後問你Greg是什麼顏色。
link |
那如果今天只是一個只會match and extract the model的話,他可能會說,What color is Greg? Greg是個關鍵的詞彙。
link |
文章裡面哪裡有提到Greg呢?只有第五句話有提到Greg。所以在算attention的時候,第五個句子得到的attention位特別高。
link |
如果你要從第五個句子裡面抽資訊出來,你可能就抽出跟frog有關的資訊。但答案不是frog,當你問What color is Greg的時候,答案是frog,顯然是不對的。
link |
所以怎麼辦呢?為了要解這種問題,就有了multiple hop這樣的想法。也就是說,我們抽出frog以後,先不急著給答案,把這個frog拿去改變我們要match的目標。
link |
也就是說,我們現在改成要去match有出現frog的句子。那哪一個句子有出現frog呢?第一個句子Brian is a frog有出現frog。
link |
所以在第二次做matching的時候,因為現在是要找有出現frog的句子,所以第一個句子的attention位特別大,其他句子的attention位就小很多了。
link |
那從第一個句子Brian is a frog裡面,你會抽出資訊Brian。再根據抽出來的資訊,再改變我們match的目標,接下來要match有Brian的句子。
link |
所以在第三次做attention的時候,有Brian的句子得到的attention位特別大,接下來你就抽出資訊是yellow,也許這就是正確的答案。
link |
過去一般在做multiple half的時候要half幾次,要改變幾次match的對象,往往是人定的。
link |
今天在之前的baby裡面通常就是做三次half,也就是改兩次match的對象。
link |
那怎麼做到剛才講的multiple half呢?Memory Network裡面就有做multiple half這件事,Memory Network是這樣做的。
link |
你今天會給一篇文章,這文章裡面的每一個句子都會變成一個embedding。
link |
那通常會產生兩種embedding,一種embedding拿來做match,一種embedding拿來做extract。
link |
那question進來的時候,先做match,再做extract,把extract出來的資訊跟原來的問題做相加。
link |
這個相加目的是什麼呢?這個相加等於改變了我們要match的對象。
link |
本來只會match跟question有關的部分,現在這個question被改變了,你有了一個新的question,你就會match不一樣的資訊,extract不一樣的內容。
link |
那到底應該要做幾次的half才對呢?過去half這件事情通常就是當作一個hyperparameter,
link |
它就像是network的層數一樣,像network要有幾層,這個是人定的嘛,所以half的數目也是人定的。
link |
但是有一個network叫做resonate,它試圖讓machine自己決定half的數目。
link |
那resonate它在做的事情呢,它在training的時候有點像是RL,那它的model呢,
link |
在每次half完都要make一個decision,都要決定說現在要停止輸出答案,還是要繼續half下去找出新的答案。
link |
那細節我們就不講,就告訴大家說有一個東西叫做resonate,它試圖讓machine自己決定要half幾次。
link |
那實際上resonate在train的時候是有用到reinforced algorithm的,讓machine可以在每一次要half之前都output一個indicator,決定說現在要half還是不要half。
link |
那近年來啊,在解這種reasoning的問題,在解這種multiple half的問題,往往會使用graph neural network。
link |
那在這堂課裡面呢,我們就不細講graph neural network的相關的事情啦。
link |
如果你想知道什麼是graph neural network的話,可以參見這個機器學習那門課呢,江辰和助教的錄影。
link |
那在這邊graph neural network想要做到的事情,其實跟剛才我們看到的multiple half要做的事情,其實是非常類似的。
link |
只是我們現在在改變我們要match的東西的時候,不需要再透過curve。就之前在memory network那一系列的work裡面,在做multiple half,在改變要match的對象的時候,它透過的方式是去改變原來的question,然後讓你match到不一樣的東西。
link |
但是在graph neural network這個系列的work裡面,它不會去改變question,它靠的是一個graph。
link |
怎麼做呢?首先你可能會把你的文章裡面的entity都抽出來,把這些entity建一個graph。
link |
那怎麼把這些entity建一個graph呢?比較簡單的做法就是,如果這些entity出現在同篇文章裡面,就把它們連起來。
link |
或者是說,如果不同文章裡面,knowledge source的不同段落裡面,有提到同樣的entity,就把它們連起來。
link |
那如果今天問的問題是一個有關Tom Clancy的人的問題,我根本就沒仔細讀這個問題,就看到關鍵字Tom Clancy,不知道他是誰,管他的,他一個中國人叫做Tom。我們把文章裡面有出現Tom的位置都找出來,他們會有最大的attention weight。
link |
第一次做matching的時候,他們的attention weight也是最大的。然後接下來透過這個graph neural network,這些不同的entity,Tom會分享Tom的attention。
link |
這個有點像是page rank,這個Tom的attention會分享給跟他有連接的人。
link |
那可能像Jack,他跟Tom在這邊有連接,然後Jack在另外一個文章裡面跟Tom有連接。所以當Tom這個詞彙在分享他的attention的時候,可能Jack會得到最多的attention。
link |
這個有最多attention的entity,他可能就是答案,然後答案就是Jack。這個是graph neural network的基本的想法。那有關細節的部分,大家就自己再去看一下論文。
link |
其實有關這個complex question,我今天不會講太多,因為我覺得complex question今天還是一個上代解決的問題。什麼樣的方法是最好的,目前還沒有一個固定的答案。
link |
舉例來說,graph neural network雖然最近非常的流行,解這種reasoning的問題,往往都會用個graph。
link |
通常常見的一個typical的network架構可能是這樣子,你用BERT抽出一些embedding,然後接下來根據你的query會建出一個graph。
link |
在這個graph上面用graph neural network那套方法做一點propagation,然後再得到下一層的內容。接下來還會再重複用這個graph做一些propagation。
link |
這是ACL19的paper,但是近幾個月就在archive上有一篇paper說,graph好像也沒那麼必要。在這篇文章裡面,他們把graph拿掉,發現拿掉這個graph,得到的performance也差不多。
link |
那為什麼前人會覺得一定要使用graph呢?這篇paper就發現說,如果你今天在用BERT的時候,這些embedding是BERT來的,如果你只把BERT當作feature attractor,
link |
就是你使用BERT的時候,你在train你的QA model的時候,你沒有fine-tune BERT,那這個graph就是需要的。
link |
但是如果你跟著fine-tune BERT,那這個graph就可以拿掉。所以其實BERT裡面的self-attention,它本身可以取代graph的部分功能。
link |
甚至你可以想像說,self-attention這件事,它本身就是一個graph,它self-attention會把所有這個文章裡面所有的entity通通都連在一起。
link |
它是一個fully connected的graph,這個self-attention會讓所有的entity通通連在一起,得到一個fully connected的graph。
link |
而這個fully connected graph上面的weight是輕是重,是network自己認出來的。所以也許確實你今天有fine-tune你的BERT model,
link |
BERT model就可以做到原來這個graph neural network可以做到的功能,它裡面的self-attention layer就可以取代graph neural network。
link |
所以這篇文章才發現說,如果你有fine-tune BERT,不需要這個graph的layer。
link |
所以你可以想見說,現在這種complex question的reasoning,還有很多上代研究的問題,等到解這種問題,還有很長一段路要走。
link |
好,建成問了一個問題,他說把graph塞進attention裡面的感覺嗎?
link |
沒錯,就是如果你有fine-tune你的BERT的話,等於BERT就會做了graph neural network本來想做的事,那就不需要graph neural network那個layer了。
link |
好,那我們講完這個dialogue QA再下課。第三類的問題叫做dialogue QA。
link |
dialogue QA想要做的事情是,它希望機器不是回答一個問題,而是回答一連串的問題,它要回答一個題組。
link |
dialogue QA有兩個知名的benchmark corpus,先講第一個,叫做口QA。口QA做的事情就是,機器先讀一篇文章,然後你問它一個問題,比如說what are the candidates running for,機器可以得到一個正確的答案。
link |
接下來第二個問題是where,如果今天沒有第一個問題,只有第二個問題where,你就會摸不著頭腦,where哪裡哪裡哪裡,你到底是要問哪裡。
link |
但是這邊的where指的就是,這些candidates running for,他們是在哪裡做這件事呢?那你的機器要知道前一個問題問的是什麼,它才能夠得到正確的答案。
link |
或者是說,這邊有一個問題是who is the democratic candidate,答案是Terry。接下來,第四個問題是who is his opponent,就是誰是他的對手呢?這個他是誰呢?你要看前一題的答案才知道說,原來他指的是Terry。
link |
機器才能知道說,Terry的對手是Ken。接下來人又問說,what party does he belong to?這個he指的是誰呢?這個he指的是Ken。
link |
機器必須要知道說,這個he指的是前一個問題的答案是Ken,所以它前一題必須要正確地回答出Ken這個答案,它才能夠回答第五個問題。
link |
接下來第二個問題再問,which of them is winning?他們之中誰贏了?這個他們是誰呢?這個他們指的是Terry跟Ken。
link |
機器必須要成功回答第三題跟第四題,才能夠知道說,這邊的他們是Terry跟Ken,然後正確地回答第六個問題。
link |
在Dialogue Q&A裡面,機器就是要回答一個題組,而每一個問題可能都是承接上一個問題。某一個問題直接拿出來,可能沒有答案。
link |
比如說你直接問,what party does he belong to?那he指的是誰呢?不知道。但是如果放在這個群題組裡面,根據上下文,我們期待機器可以回答說,he指的就是Ken。
link |
那這個是Dialogue Q&A。那除了Q&A以外,還有另外一個知名的Corpus就叫做Quark。
link |
那這個Quark跟Q&A它一個比較不一樣的地方是,在Q&A裡面問問題的人,他有看到文章。所以問問題的人,他不會問出很荒謬、沒有辦法回答的問題。
link |
但在Quark裡面,它一個特別的地方是,問問題的人,人在出這個問題的時候,出問題的人是沒有看過文章的。
link |
所以出問題的人根本不知道文章裡面有什麼樣的內容,所以出問題的人可能會問出文章裡面沒有的內容。
link |
出問題的人可能會問出一些沒有辦法回答的問題,而機器必須要知道哪些問題是沒有辦法回答的。
link |
那像這種Dialogue Q&A的問題要怎麼解呢?最直覺的解法,通常你可能會把這樣子的解法當作一個很trivial的baseline。
link |
就是我們把Dialogue Q&A當作一般的Q&A來解。我們有一堆Q&A model,我們有一個Q&A model,我們就把每一個問題都當作是獨立的。
link |
把每一個問題分別丟進Q&A model,得到一堆獨立的答案,再看看你得到什麼樣的結果。但你使用這樣的方法,你不會在Dialogue Q&A上得到太好的結果,它只能夠作為一個baseline。
link |
那今天一般在解Dialogue Q&A的問題的時候,你可能會採取什麼樣的解法呢?那一個經典的解法可能是這個樣子。
link |
如果你今天把每一個問題都視為是獨立的,那你可能會這麼做,你把Document跟Question接起來丟到Bert裡面,Bert給你D,Bert的D,L個Layer產生一堆Embedding,L加1Layer再產生一大堆Embedding,那Q2也是一樣,Q3也是一樣。
link |
但是怎麼把不同問題間的資訊串聯起來呢?舉例來說,像這篇ICLR219的paper,它就使用一個RNN,說你今天怎麼得到這個Embedding呢?不只要看上一層的Embedding,還要看前一個問題。
link |
所以今天產生這個Embedding的時候,我們把不同Question的Embedding可能用RNN串起來,那之所以用RNN是因為那個時候Bert還不流行,所以這篇ICLR219的paper是說,我們用RNN把這些Embedding串在一起。
link |
所以每一個Embedding產生的時候,不只是考慮了前一層的Embedding,還考慮了前一個問題的Embedding,這是目前Dialogue Q&A一個蠻主流的解法。
link |
那這篇用RNN就是因為19年的時候Bert還沒有Everywhere,但今天Self-Attention已經到處都是了,所以像這篇CIKN19的paper就用了Self-Attention的概念。
link |
所以Embedding產生的時候,不只是從上一個Layer抽取資訊,它還從其他問題的同一個位置,用Attention的方法抽取資訊出來,用Attention的方法做Weighted Sum,那這個是Dialogue Q&A今天一個主流的解法。
link |
好,今天有了Bert的Model以後,是不是Question Answering的問題就被解決了呢?如果你看那些什麼Squad Leaderboard的話,確實會給你一種Question Answering已經被解決的錯覺。
link |
舉例來說,這個是Squad 2.0的Leaderboard,這是Human的Performance,EN是Exact Match,也就是機器得到的答案如果跟正確的答案一模一樣,才能夠得到一分。
link |
那F1呢,就算是機器的答案跟正確的答案有點不一樣,只要有一部分是重疊的,也可以得到分數。
link |
人類在Squad 1.0上的EN分數是86.8%,而今天第一名的機器已經超越人類了。
link |
不只第一名的機器超越人類,你看前五名統統是90分以上,前五名的Model統統都已經超越人類了。當然這些Model都是以Bert為基礎做的,尤其都是以Albert為基礎做的。
link |
第一名是用Albert做的,第二名他是個Ensemble,但他其實內部用的也是Albert。第三名是Electra加Albert,第四名是Albert,第五名也是Albert。
link |
用Bert的Model好像在一定程度上解決了QA的問題,但是QA的問題真的已經被解決了嗎?這篇Paper是這樣做的,他說這個是比較舊的Paper,所以當時的實驗是做在Baby上面。
link |
在Baby上面,機器往往可以得到非常高的正確率。有幾個Task比較難,但很多Task機器都可以得到90%以上的正確率。
link |
現在,如果我們只給機器看文章的問題,把Squad任務裡面的文章做隨機的置換,只讓機器看到問題,這個時候Performance當然會比有看到文章的狀況還要差。
link |
但是神奇的事情是,假如我們讓機器只看文章,隨機給它一個錯誤的問題,這時候發生什麼事呢?
link |
在好幾個任務上,機器不給它問題,只給它文章,反而可以得到更高的正確率。
link |
而在一些任務上面,不管機器有沒有看到問題,它都可以得到正確的答案。
link |
比如說在第20個任務上,如果今天有看文章也有看問題,是100%的正確率。如果只有看文章沒看到問題,也有100%的正確率。
link |
代表今天你的模型不需要看這個問題,它光看文章就可以知道正確答案是什麼了。
link |
再舉另外一個例子,這群作者試了一個叫做CVT的Copper。在這個CVT的Copper上面,如果你給機器看文章也看問題的話,得到的正確率是這一排。
link |
如果你今天只給機器看問題,不給它看文章,在某一些狀況下,這邊是四種不同類型的問題。
link |
在這兩種類型的問題,機器居然比它要看到文章還要好。
link |
不過這個是因為CVT是一個有點怪異的Copper,CVT其實是要機器做剋漏子。
link |
它是把一篇文章裡面的21個句子拿出來,前20個句子當作是文章,第21個句子當作是問題。
link |
然後第21個句子裡面會有一個詞彙是鏤空的,那機器的任務、問題的答案就是要把那個鏤空的部分填回去。
link |
那你今天就會發現說,往往機器只要看第21句就可以把鏤空的部分填回去,給它看之前的1到20句,其實沒有幫助。
link |
這就顯示說CVT這個Copper其實它的設計是有一些問題的,它讓機器不看文章,只看問題就可以得到答案。
link |
不過這樣的狀況還好在Square上面並沒有真的出現。
link |
在Square上面,如果機器有看文章、有看問題得到的正確率是這樣,那個時候還沒有BERT,用的是QAnet。
link |
如果機器只看問題的話,那它的正確率當然會暴跌,只看文章的話,正確率當然會暴跌。
link |
那在18年的EMNLP還發現了一個特殊的現象,這個現象是這樣子的。
link |
今天給機器看一篇文章,那如果你問它,What did Tesla spend Aster's money on?機器可以得到正確的答案,就是這個深藍色框框所框起來的部分。
link |
但是當你今天把你的問題改成只有一個詞彙叫做Date,結果機器還是得到正確的答案,不只得到正確的答案,它的性侵分數還從0.78增加到0.9。
link |
你給機器看這個完整的問題的時候,它得到的這個答案,它的性侵分數是0.78,你問它一個Date,人根本不知道在問什麼,機器居然也得到了正確的答案,而且性侵分數還更高。
link |
在VQA上也發現類似的現象,你給機器看這張圖片,那你問機器說,What color is the flower?機器會回答Yellow。
link |
但你把你的問題改成花,人根本不知道問什麼,你要問花的什麼,問花有幾朵嗎?問花有沒有插在花盆裡面嗎?不知道。
link |
結果機器自己知道說答案就是Yellow,而且它的性侵分數只有略微的下降。
link |
所以太神奇了,機器料事如神啊,你不用問它完整的問題啊,你問它花,它就知道你要問花的顏色。
link |
你隨便答一個Date,你問題根本沒問完,機器就得到正確的答案,怎麼這麼神奇?
link |
在這篇文章裡面其實有做更完整的分析,這邊只是舉兩個例子,文章裡面的完整分析是這樣的。
link |
在那篇文章裡面,作者試圖把SQUAD、SNLI跟VQA這三個任務的問題都把它縮短,原來問題的長度分布是藍色的。
link |
然後你會發現說把問題縮短對機器的影響不大,這邊是展現這幾個任務上面機器的Confidence Score。
link |
其實把這些問題縮短以後,在縮短問題的時候,這群作者是有稍微特別設計一下要把哪些詞彙拿掉。
link |
所以他們會刻意只拿掉不會改變機器答案的詞彙。
link |
所以今天這些原來的問題跟縮短後的問題,機器得到的答案是一模一樣的。
link |
當機器在看這些原來的問題跟縮短後的問題的時候,它的正確率完全沒有改變。
link |
接下來,把這些原來的問題跟縮短後的問題拿去給人看。
link |
人在原來的問題上可以得到不錯的正確率。
link |
但一旦給人這些縮短後的問題,人發現我根本就看不懂啊。
link |
這太神奇了,機器可以答對這些縮短的問題,但是人沒辦法答對。
link |
但這個時候你不會說太神奇了,機器超越人類了,又有故事可以寫了。
link |
不是這樣,這個時候你會覺得,這什麼地方怪怪的?
link |
到底機器學到了什麼?它真的學到東西了嗎?
link |
還是今天我們在Square上面看到的這麼好的performance只是一種假象?
link |
機器只是抓到了人類在Square出題的方向,它知道人類會怎麼出題,
link |
它根本就不用看問題了,你隨便給它問題的一小部分,它都可以猜中答案了。
link |
它根本就不需要真的去理解文章,它光看問題的一部分就可以猜出答案。
link |
所以這代表的並不是說機器真的超越人類,而是也許我們今天在這些Benchmark corpus上的結果是有問題的,
link |
也許這些Benchmark corpus的設計並沒有辦法真正檢驗機器的能力。
link |
就好像說你去考駕照的時候,如果你有去上那種考駕照的補習班,它都會教你說,看到文章裡面、看到問題裡面出現某個詞彙,你就選選項C,不要猶豫。
link |
所以機器很有可能學到的就是類似的東西。
link |
所以如果今天我們單看Square的結果,你並不能夠真的知道機器的能力到什麼階段。
link |
所以我們也許需要更好的Benchmark corpus。
link |
舉一個例子,在VQA這樣子的Benchmark corpus上,有人就發現說在VQA裡面,它的測試資料跟訓練資料裡面有非常明顯的buyer。
link |
舉例來說,假設問題裡面有提到運動,那你就回答網球,不知道為什麼出題的人特別喜歡打網球,問運動就是打網球,你就會對了。
link |
所以這樣子的狀況,你並沒有辦法透過VQA真的去衡量機器看一張圖片回答問題的能力。
link |
所以就有人設計了新的VQA corpus,叫做VQACP。
link |
在VQACP裡面,故意給訓練資料跟測試資料不同的分佈。
link |
在VQACP裡面,在訓練資料裡面,看到what sport這樣的question,出現頻率最高的是tennis。但是在測試資料裡面,看到what sport這樣的question,出現頻率最高的就變成滑雪。
link |
看到which,本來在訓練資料裡面出現答案最多次的是左邊,在測試資料裡面就刻意給你改成右邊。出現r,本來在訓練資料裡面最應該回答的出現次數最多的是no,在測試資料裡面就故意給你改成右邊。
link |
看看機器在這種狀況下,它能不能夠正確的學會怎麼看一張圖片,怎麼回答問題。
link |
這邊是說還沒有VQACP只用原本的VQA來做實驗。
link |
如果你只用原本的VQA來做實驗,你會發現說機器可以得到頗高的正確率,下面這四個是deep learning base的model,機器都得到了50%以上的正確率。
link |
但比較奇怪的就是說,機器如果只給它看問題,它有48%的正確率。不只是只給它看問題,給它看更少,只告訴它問題是哪一個類別的,也有35%的正確率,這真的是有點怪怪的。
link |
如果你今天換成VQACP,這樣測試資料跟訓練資料,它們的分佈不一樣,機器直接鏟掉,你會發現說本來什麼60%、50%以上的那些model正確率,現在都掉到30%左右了。
link |
然後這些什麼只給question type、只給question的狀況都直接鏟掉,所以這可能VQACP上的performance可能更接近機器真實的能力。
link |
我講這麼多只是想要告訴大家說,今天雖然有各式各樣的浮誇,說在benchmark corpus上面,機器閱讀理解的能力已經超越人類了,但並不代表機器回答問題的能力真的超越人類。
link |
那如果我們把那些用BERT做出來的model,在squad上號稱可以跟人的performance相匹敵的model,拿來直接測試在baby上面,會如何呢?
link |
那baby我們在這門課的一開始就已經提過,baby這個corpus是一個artificial的corpus,它裡面的句子是用某種template所生出來的。
link |
如果我們現在把訓練在squad上的model,直接測試在baby的20個任務上,結果會怎樣呢?你發現結果都還蠻慘的,任務4跟任務5還有超過50%的正確率,其他基本上都是壞掉了。
link |
不要忘了baby在好幾年前就已經號稱全破了,好幾年前就已經有模型說在所有的baby corpus上都可以得到95%以上的正確率了。
link |
所以當然有人會說,這個squad本來就是extract and match的QA的problem,baby比較難,baby是需要機器做一下推理才能夠答對的。
link |
所以訓練在squad上的model不太可能在baby上得到正確的答案。這顯示說,就算在squad上面機器的performance跟人差不多,這也不代表什麼。
link |
說在squad上面機器跟人的performance差不多,就是機器在閱讀的能力上超越人類,這個其實太浮誇了。有關QA的研究,其實還有很長一段路要走。
link |
那這個有關QA的部分呢,我們就分享到這邊。