back to index
The Next Step for Machine Learning
link |
接下來,我們想要講說機器學習下一步,就剛才講的那些技術,在過去的課堂上,或多或少都已經有提到過。
link |
其實今天這個學期,我想要講一些過去從來沒有講過的技術,這些技術我看作是機器學習的下一步,
link |
就是假設我們今天要把機器學習的技術真的用在日常的生活中,還有哪些技術是我們需要的,還有哪些難題是我們需要克服的。
link |
第一個問題就是機器能不能夠知道我不知道這件事情,這個是一個很型額上的問題,你知道你不知道,機器能不能知道這件事情呢?
link |
因為很多時候,你可能訓練一個比如說動物的classifier,它看到這張圖片,它知道是一隻貓,它的正確率可能非常非常高。
link |
但是你真的把這個系統上線的時候,你以為人家只會乖乖丟一個動物給你嗎?它可能就丟一個涼宮春日給你。
link |
這個時候,你的機器到底是會硬是把這個涼宮春日塞成某一隻動物,覺得它其實長得還是最像貓,
link |
還是說你的機器有能力知道這個是我不知道的怪東西,它回答說我巨大,或是我不知道這個東西是什麼。
link |
那這樣的技術叫做anomaly detection,機器能不能夠知道我不知道。
link |
再來下一步是,機器能不能夠說出我為什麼知道。今天我們看到了各式各樣機器學習非常強大的力量,感覺機器好像非常聰明。
link |
但它看起來這麼聰明,它實際上真的那麼聰明嗎?過去有一個例子叫做神馬漢斯的例子,我不知道大家有沒有聽過這個例子。
link |
這個例子是講說,動物很聰明,有一隻馬叫做漢斯,它甚至聰明到它可以做數學。
link |
舉例來說,你跟它講根號九是什麼,然後它就會敲它的馬蹄,然後大家就歡呼,得到正確的答案了。
link |
這顯然是一個會算數學的馬,甚至可以解開根號的問題,大家都覺得非常的驚嘆。
link |
後來有人就懷疑說,難道漢斯真的這麼聰明嗎?所以後來有人就說,不要有任何觀眾,在沒有任何觀眾的情況下,叫漢斯自己去解一個數學的題目。
link |
這個時候它就會一直剁它的馬蹄,然後永遠都不停。為什麼呢?因為它之前是學到了它觀察旁邊的人的反應,它知道它什麼時候應該停下來,然後接下來它就可以有蘿蔔吃。
link |
它可能不知道現在在幹嘛,它根本不知道數學是什麼,但是你認它的時候就是,你只要踏對正確的題目的數目,踏對正確的數目,你就可以得到蘿蔔吃。
link |
它如何踏對正確的數目跟它有沒有智慧,沒有關係,它只是看了旁邊的人的反應,得到正確的答案。
link |
今天我們看到種種驚人的機器學習的成果,難道機器真的有那麼聰明嗎?會不會它跟漢斯一樣,只是用了非常奇怪的方法來得到答案而已?
link |
這個東西其實是有可能發生的。舉例來說,這個是來自於某一個GCPR的2021屆某一個tutorial,有人做了一個馬的辨識器,馬的辨識器的正確率很高,有八十幾%,他做了兩個不同的model,兩個不同的model都有八十幾%的辨識正確率。
link |
接下來他就想分析那兩個model,有一些機器學習的方法可以告訴我們說,今天機器它知道這張圖片裡面有馬,它是根據什麼標準、根據什麼樣的特徵、根據什麼樣的暗號,知道說圖片裡面有一隻馬。
link |
它得到的結果是這樣,它先分析了第一個模型。這個紅色的地方代表說,機器看到這些地方,這些地方跟機器判斷這張圖片裡面有沒有馬是特別有關係的。
link |
所以第一個模型是一個正常的模型,顯然機器看到這個馬,它覺得說,所以它才說圖片裡面有馬。
link |
但第二個模型是這樣子的,機器看這個圖片的左下角,覺得是有一隻馬。為什麼看左下角會發現有馬呢?因為這些馬的圖片,左下角都有一個英文啊,因為這些馬的圖片都是從同一個網站上截下來的,所以它左下角都有一串一樣的英文啊。
link |
所以機器只是學到說,看到左下角的英文,它就是一個馬,它並沒有真的學會馬長什麼樣子。
link |
所以我們不知道今天的AI是不是有那麼聰明,所以我們需要有一些技術,讓AI不只是做出決定,還要告訴我們說它為什麼做出這樣的決定。
link |
我們知道說,人是有錯覺的。舉例來說,這邊有兩個圈圈,我們來問一下大家,你覺得哪一個圈圈顏色是比較深的?你覺得左邊這個圈圈顏色比較深的同學舉手一下。
link |
好,手放下。你覺得右邊這個圈圈顏色比較深的同學舉手一下。好,手放下。你覺得這兩個圈圈顏色一樣深的同學舉手一下。
link |
好,這個好像是最多的。但事實上呢,左邊顏色比較深啦。這是一個計中計。你可能以為這是一個錯覺的實驗,但是我知道你以為這是一個錯覺的實驗,所以左邊確實是比較深的。
link |
但是你看,人是很容易被騙的,對不對?人是很容易被騙的。所以機器跟人一樣,也很容易被騙啊。
link |
所以這個也許就是機器的錯覺。我們可以加一些noise,就讓機器本來覺得這是熊貓,然後接下來就覺得它是長臂猿。這個技術叫做adversarial attack,我們要如何防止這種技術發生?
link |
就說adversarial attack,今天甚至可以做到一個圖片,你改圖片裡面的一個pixel,機器的判斷就完全錯掉了。
link |
顯然,如果我們未來要把影像辨識的模型放到真實的場域裡面,如果adversarial attack的技術今天可以做到改一個pixel,就讓機器的判斷錯誤,那顯然這個會有治安的問題。
link |
你可以想像,未來自駕車開在路上,路邊有人拿一個旗子一揮,自駕車就撞車了,這是有可能會發生的。所以我們要問的問題是,如何防止機器發生錯覺?
link |
我們也要讓機器能夠終身學習,我們知道人就是終身學習。你上個學期可能修了線性代數,那這個學期你就修機器學習。
link |
那修過線性代數,可能會更容易讓你了解機器學習這門課的內容。但是機器能不能跟人員一樣,它也做終身學習。
link |
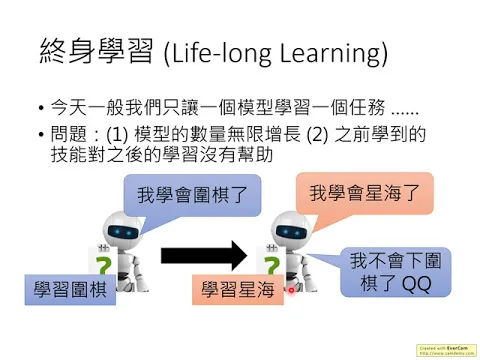
今天其實機器並沒有做終身學習這件事情,因為alpha go它就是下圍棋,alpha start它就是玩星海。
link |
alpha go並不會玩星海,alpha start並不會下圍棋,它們並不是同一個模型。
link |
今天我們通常是一個機器學習的任務,我們就為那個機器學習的任務去學一個模型,但這顯然最終事情不同了。
link |
假設我們有一個機器人,它真的要在日常生活中運作,它要解的任務絕對不止一兩個,它不只要下圍棋,它不只要會玩星海,它還要能夠做影像辨識,還要能夠做語音辨識,它要解的任務非常非常多。
link |
如果我們為每一個任務都需要學一個模型的話,那這個模型的數量會無限制的增長,直到我們的記憶體沒有辦法存下那麼多模型為止。
link |
而且如果不同的技術就需要不同的模型,那不同的技術間就沒有辦法互通有無,機器在某一個任務學到的技能就沒有辦法幫助它在另外一個任務學得更好。
link |
但是為什麼我們今天不讓機器做終身學習這件事情呢?因為假設你讓機器先去學下圍棋,它學會下圍棋,接下來你再用同一個模型讓它學習玩星海,它也會玩星海,但是它就不會下圍棋了,這個叫做catastrophic forgetting。
link |
今天如果你要讓機器做終身學習,同一個模型,它不斷地學新的任務的時候,一個還尚待解決的問題。我們之後的課程會講一下,現在有什麼樣的life-long learning的技術。
link |
我們也要讓機器學習如何學習,過去我們是寫一個程式讓機器具有學習的能力,接下來我們能不能夠寫一個程式,這個程式可以寫一個具有學習能力的程式,然後讓機器去做學習。
link |
這樣聽得懂嗎?我們寫了一個可以寫出有學習能力的程式,然後這個程式會寫出有學習能力的程式,然後讓機器具備有學習的能力,這個技術叫做meta-learning,或者叫做learn-to-learn,學習如何學習。
link |
過去我們設定了學習的演算法,讓機器按照學習的演算法進行學習。今天,我們能不能讓機器自己學出學習的演算法,再根據它自己學出來的學習演算法去進行學習,可以做出過去根據人類所設定的學習演算法沒有辦法做到的事情。
link |
我們知道說機器學習就是需要很多訓練資料,但是往往有一天,比如說你畢業以後,你的老闆可能說,聽說你修過機器學習這門課,來幫我做個影像分類的東西吧,我要你辨識比如說什麼是草泥馬。
link |
這時候你可能會問說,那有幾張資料呢?你可能期待說,給我個一十萬張差不多,然後老闆說,大概就這一張差不多,然後你自己回去想辦法這樣子。這個時候你有兩個選擇,一個是把老闆的頭打爆然後辭職,
link |
另外一個選擇就是,你可以考慮用一下few-shot learning的方法,能不能讓機器只看非常少量的example,接下來它就學會這個任務。甚至有沒有可能做zero-shot learning,也就是不給機器任何的訓練資料。
link |
你只告訴它說,馬萊摩就是有包著尿布的白色體毛,其他部位貼成黑色,然後機器看到一個馬萊摩,它過去從來沒有看過馬萊摩,但它根據馬萊摩的文字描述就認出說,這是一隻馬萊摩,這個是zero-shot learning的基礎。
link |
Reinforcement learning,今天大家一講再講,感覺好像每一個任務你不用reinforcement learning解就不夠潮一樣,但是reinforcement learning真的有那麼強嗎?
link |
舉例來說,當你用reinforcement learning這個技術去打一些Atari的電玩,打一些簡單的小遊戲的時候,reinforcement learning的技術也許確實可以跟人做到差不多的performance,
link |
但是你看看它玩這個遊戲所需要的時間,它需要玩九百多個小時才能夠得到四千分左右,而人類的能力在哪裡呢?人類在兩個小時以內就可以得到四千分左右。
link |
所以機器感覺就是一個勤奮不懈的人,但是它很笨,所以它需要花非常多的時間來學習,才有可能跟人做得一樣好。
link |
或者是我們舉另外一個例子,我們剛才講了Alphastar,機器現在可以在星海上痛電人類,雖然它的手速比人慢,但是它可以痛電人類。
link |
但是Alphastar它花了兩百年的時間在玩星海,它實際上玩的時間就是兩百年,只是因為它玩星海是用模擬的,所以它就像進入了精神時光物一樣。
link |
所以實際上玩著星海,它就玩兩百年了。如果讓你進入精神時光物,玩兩百年,你不吃不睡,就只能夠玩星海的話,你應該也是有Alphastar那麼強的。
link |
所以我們今天要問的問題是,reinforcement learning為什麼這麼慢?有沒有辦法讓它學得快一點?
link |
接下來,如果我們要把機器這個深度學習的模型應用在日常生活中,我們知道很多edge專的device,它的運算能力是很有限的,它的memory的資源是匱乏的。
link |
所以我們接下來要問的另外一個問題是,我們能不能夠把network的架構縮小,但讓它仍然有同樣的能力?
link |
我們能不能夠把一個大的內神經網絡縮小,減掉多餘沒用的參數?或者是我們能不能夠把一個內神經網絡的參數二元化,本來內神經網絡的每一個參數都是continuous number,
link |
你顯然需要很大量的運算來做continuous number的加減乘除,你顯然需要很大量的memory才能存這些continuous number,
link |
我們能不能把所有的參數都變成正一跟負一,這樣運算起來就快,儲存network的時候,你需要的記憶體也會少很多,那這個是我們這學期會講的其中一件事情。
link |
再來要告訴大家一個機器學習的謊言,就所有教科書都會告訴你說,我們今天在訓練跟測試的時候,我們假設訓練資料跟測試資料的data,它的分佈是一樣的,或者至少是非常類似的。
link |
但實際上在真實的應用裡面,這就是一個謊言。如果今天你在做手寫數字的辨識,你的訓練資料長這樣,你的測試資料長這樣,
link |
它們非常的像,它們有它們的distribution,你可以輕易地得到99%以上的正確率。
link |
但是今天,假設你在工作的時候,你的老闆可能會給你這樣的任務,這是我們公司的訓練資料,測試資料差不多就是這個樣子,你給我想個辦法處理一下。
link |
這個時候你有兩個選擇,一個是你拿出筆下那一本書,有六百頁,然後砸在老闆的臉上跟他說,這個數字研究告訴我們說,訓練資料跟測試資料的distribution是一樣的,這個問題沒有辦法解。
link |
但是你想想,你家裡有老婆孩子,所以你知道,喊累了還是解一下這個問題。如果你訓練在這樣子的訓練資料上,真的測試在這樣子的測試資料上,你可能覺得說這個問題也許機器還是做得到吧。
link |
因為雖然說背景我們加了一些顏色,但是假設機器可以真的認識數字的形狀,忽略那些顏色的話,應該結果也不會太離譜。
link |
但實際上你自己做做看,你就會發現說,今天假設訓練資料是這樣,測試資料是有顏色的數字,正確率變成57%,整個就是爛掉。
link |
機器不知道怎麼回事,你加了一些背景顏色以後,它就認不得這些數字了。那怎麼讓機器在測試資料跟訓練資料的分佈不太一樣的時候,它還能夠稍微做一些事情,這邊有一些技術是可以跟大家分享的?
link |
總之,這是這學期想要跟大家分享的東西。我們就先不下課,然後如果你想上廁所的話,你就自己去上廁所。我們就講一下這門課的相關規定,然後就休息十分鐘,然後讓助教來講一下作業儀。