back to index
Anomaly Detection (3/7)
link |
我們來複習一下剛才整個framework是怎麼樣的。
link |
我們有訓練資料,這些訓練資料是大量的圖片,這些圖片都有標註是辛普森家庭的哪一個人物,因此我們可以訓練一個分類器。
link |
從分類器,不管你用什麼方法,你可以得到分類器對某一張輸入的圖片,它的信心分數。
link |
你可以知道今天分類器在做分類的時候,它覺得它的分類結果應該是非常正確,還是它其實是沒有什麼信心的。
link |
有了這個信心分數以後,你就可以根據這個信心分數來打造你的異常偵測的系統,如果信心分數高於某一個threshold的話,就說它是正常的,低於某一個threshold就說它是異常的。
link |
這個是訓練資料,再來我們要講關鍵的development set,我們在之前的錄影裡面已經有告訴大家development set的概念,你今天需要development set,你才能夠來調一些hyper的parameter,調一些訓練之後的模型的參數,你才會overfit在你的testing data上。
link |
今天在異常偵測的任務裡面,我們會需要什麼樣的development set呢?我們會需要有不只是大量的image,這些image還需要被標註說它是來自於辛普森家族的人物,還是不是來自於辛普森家族的人物。
link |
這邊要特別強調一下,在訓練的時候,我們所有的資料都是辛普森家族的人物,我們需要的label是它是哪一個辛普森家族的人物。
link |
但是我們要做development的時候,我們development set要模仿我們的testing set,我們development set要的並不是一張圖片,它是辛普森家族的哪一個人物,而是我們的development set裡面應該要有辛普森家族的人物跟不是辛普森家族的人物。
link |
我們不需要知道它是哪一個辛普森家族的人物,但是我們要有辛普森家族的人物跟不是辛普森家族的人物。有了這樣的development set以後,我們就可以把我們的異常偵測的系統用在這個development set上,
link |
然後計算這個異常偵測系統在這個development set上面的performance有多好,等一下會講說這個performance實際上要怎麼樣來衡量。
link |
而你能夠在development set上衡量一個異常偵測系統的結果好壞以後,你就可以拿來決定你的,比如說我們剛才講說在這個系統裡面有一個很顯然的,你需要決定的參數就是你的threshold。
link |
你可以用你的development set來調整你的threshold,找出一個可以讓系統最後算出來的結果最好的threshold。
link |
那你決定了總統hyperparameter以後,你就有了一個異常偵測系統,你就可以讓它上線,給它一張圖片,它決定它是不是辛普森家族的人物。
link |
這就是整個系統的流程。接下來我們要講的是,如何計算一個異常偵測系統的效能好壞。為了舉這個例子,我也是跑了一些實際的例子。
link |
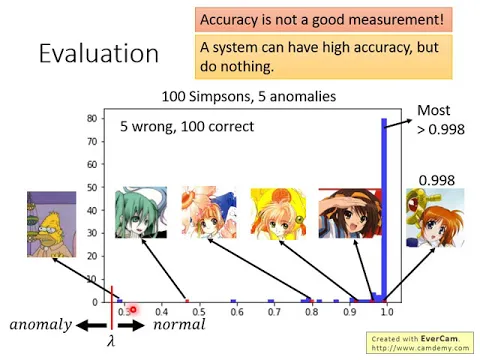
這邊就是有一百張辛普森家族的圖片跟五張不是辛普森家族的圖片。你可以想像說,這個就是我們的development set。辛普森家族的一百張圖片是用藍色來表示,
link |
你會發現說,他們的分佈通常集中在高confidence的區域。五張不是辛普森家族的圖片就在這邊,你算一下這個紅色的點,不是辛普森家族的圖片就用紅色來表示,正好有五張紅色的圖片。
link |
你會發現說,這邊有某一張藍色圖片,某一個辛普森家族的人物的confidence是特別低的。所以在做異常偵測的時候,其實檢察會在這個地方犯一個錯誤,會認為說他不是辛普森家族的圖片,而是一個異常的圖片。
link |
我也不知道為什麼會這樣,這張圖片是一個辛普森家族的老爺爺,我也不知道為什麼會這樣。
link |
那剩下這五張圖片是誰呢?看看你能不能認出這些人物。第一個這個是看起來像安娜貝爾的雛嬰,這個我隨便random sample,我也不知道為什麼sample到這一張。
link |
然後這個我不知道大家認不認得這個角色,這個是庫洛魔法使,這個是小櫻,然後這個也是小櫻,這個是涼宮春日,這個我不知道大家認不認得是誰,這個應該是魔法少女奈葉,她也是會用魔法,跟小櫻一樣。
link |
有人看到這邊可能會說,這個魔法少女她的confidence感覺非常的高,不知道是不是因為她看到這個黃色的魔杖,覺得這搞不好是辛普森家族人物的臉,她這個分數特別高,有0.998,好像這個方法沒有很強。
link |
但我這邊要強調一下,事實上,在這個Bar裡面有75%以上的圖片,她的confidence都是高於0.998的。你會發現,多數辛普森家族人物她可以得到的confidence都是1。
link |
所以很多人自己在使用這個方法的時候,他看到說,今天給你的classify一個異常的圖片,他都會給你什麼0.99加很高的分數,但你會發現說那些正常的圖片往往可以得到更高的分數,比如說1之類的分數。
link |
所以雖然這些異常圖片他們也可以得到很大的分數,但是因為這個分數是相對的,所以他們如果沒有正常的圖片的分數那麼高,你還是可以得到好的異常偵測的結果。
link |
好,那再來就是要講說,我們怎麼來評估一個系統的好壞呢?舉例來說,現在我們有這樣的definite set,我們在這個definite set上如何計算一個我們的異常偵測系統它的performance的好壞呢?
link |
那有人就會想到說,我們剛才說的異常偵測,其實它是一個二元分類的問題,它是一個binary classification的問題。
link |
我們已經講過binary classification,在等一下助教公報作業二裡面就是要做binary classification。
link |
那在binary classification裡面,我們都是用正確率來衡量一個系統的好壞,比如說給系統給它一張圖片,如果它的答案是對的就得1分,如果是錯的就得0分,這樣子來做。
link |
那但是在異常偵測這個問題裡面,正確率並不是一個好的來評估系統的方式,你會發現說,很有可能一個系統它有很高的正確率,但它其實是一個很爛的系統,它什麼事都沒有做。
link |
為什麼會這樣呢?因為在異常偵測這個問題裡面,往往異常的data和正常的data,它的比例的分佈是非常的懸殊的。在這個例子裡面,我們說異常的資料只有五張,然後正常的image有一百張。
link |
在其他的問題裡面,它們的分佈可能是更懸殊的。舉例來說,在所有的交易裡面,假設你今天要做的是詐欺偵測,可能一百筆、一千筆、一萬筆交易裡面都不見得有一筆是有詐欺的行為。
link |
所以今天的異常的資料跟正常的資料,它們的比例分佈是非常懸殊的,所以會造成說,如果你光拿正確率來衡量一個系統的好壞,是會得到非常奇怪的結果的。
link |
舉例來說,在這個例子裡面,我們可以說我們有一個異常偵測的系統,它的浪打我們把它設在0.3以下,浪打以上我們說它是正常的,浪打以下我們說它是異常的。
link |
這個時候這個系統的正確率有多少呢?這個時候你會發現這個系統,它如果算正確率的話,在全部給它的100加5,105筆data裡面,它犯了五個錯誤。它的五個錯誤都是把五張異常的資料判斷成正常的資料。
link |
但這個時候如果你計算它的正確率,把100除以105的話,你會發現它的正確率是超過95%以上的。雖然這不是一個你要的異常偵測系統,因為這個系統會把所有的東西統統判斷成是正常的,但是因為異常的資料很少,所以它其實算出來的正確率仍然是很高的。
link |
所以今天在做異常偵測的問題的時候,你不會拿正確率來直接當作你的evaluation measure。那你會怎麼做呢?首先我們要知道說,在異常偵測的問題裡面有兩種錯誤。
link |
一種錯誤是異常的資料被判斷成正常的資料,另外一種是正常的資料被判斷成異常的資料。所以如果你實際分析一下的話,假設我們現在把Lambda切在比如說0.5這個地方,0.5以上說它是正常的,0.5以下說它是異常的,
link |
這個時候你就可以計算看看,其實在這兩種錯誤上各分別犯了多少錯誤。你就可以計算說,現在對所有五筆異常的資料而言,有一筆被偵測出來,剩下四筆統統沒有被偵測成異常。
link |
而在所有正常的一百筆資料裡面,只有一筆的這個老爺爺它被判斷成異常的,剩下九十九筆統統都是正常的。
link |
這個時候我們會說,這個機器在false alarm這個地方,false alarm就是正常的東西把它判斷成異常的,這是一個偽警報,我們叫false alarm。
link |
false alarm的話,它有犯了一個false alarm的錯誤。那如果今天是異常,但沒有偵測出來這個叫missing,它有四個missing的錯誤。
link |
那如果我們今天把這個threshold切在其他的地方,舉例來說,我們把這個threshold切在比0.8還要稍微再高一點點,這時候你會發現說在五張異常的圖片裡面,
link |
有兩張,第一個小鷹跟這個像安娜貝爾的雛鷹,它們都是被偵測成異常的,但剩下三張會被歸類為正常的。
link |
在所有正常的圖片裡面,在一百張正常的圖片裡面,這邊總共有六張圖片被歸類為異常的,九十四張仍然被判斷為正常的。
link |
那哪一個系統比較好呢?事實上,你其實很難回答這個問題。有人可能會很直覺地說,這邊是一個false alarm,四個missing,這邊是六個false alarm,三個missing,
link |
這邊加起來有五個錯誤,這邊加起來有九個錯誤,所以顯然左邊的系統好,右邊的系統差。
link |
但是其實一個系統到底是好還是壞,取決於你覺得false alarm比較嚴重還是missing比較嚴重。所以你在做異常偵測的時候,
link |
你可能會有一個這樣子的cost table告訴我們說,每一種錯誤有多大的cost。
link |
舉例來說,今天把錯的東西沒偵測到missing就扣一分,但是如果今天是false alarm把正常的東西偵測誤判成異常的,那就要扣一百分。
link |
如果你是用這樣子的cost來計算來衡量你的系統的話,那左邊的系統會被扣多少分呢?它被扣了一百零四分,而右邊的系統被扣了六百零三分。
link |
所以這個時候按照左邊這個table,你會說左邊這個系統是比較好。
link |
但是如果你的cost table是像右邊這個樣子,你說如果我們有一個missing,異常的東西有一個沒有被偵測出來就扣一百分,
link |
而如果我們把正常的東西不小心判斷成異常的就只扣一分的話,那你計算出來的結果就會很不一樣。
link |
那在不同的情境下、不同的任務,其實你會有不同的cost table。舉例來說,因為今天這個辛普森家庭的任務是一個比較奇怪的任務,
link |
我不知道說誰會需要一個系統來偵測說看那個圖片是不是辛普森家族的人物。
link |
但是假設是舉別的例子,舉例來說你今天想要做的是癌症檢測,那你可能就會比較傾向於想要用右邊的cost table。
link |
為什麼?因為假設今天一個人他其實沒有癌症,但是你不小心判斷說他有癌症,那他可能去別家醫院再檢查還是又檢查出來了,
link |
所以他頂多就是幾個禮拜心情不好而已,雖然很不好,但是其實也還可以接受。
link |
但如果其實他有癌症,但是他是異常的狀況,他身體有問題,但是你卻沒有檢查出來的話,那這個很嚴重,這個時候就應該要有比較高的cost。
link |
所以今天cost不同的錯誤,cost要給多少,其實就要問你自己,問你說現在這是什麼樣的任務,那根據不同的任務,你會有不同的cost table。
link |
所以如果根據右邊這個cost table,你就會說左邊的系統的cost是401分,右邊的系統的cost是306分,所以這個時候右邊的系統就會比較好。
link |
所以今天anomaly detection的系統要怎麼衡量,取決於你今天要拿這個系統來做些什麼事。
link |
那在文件上其實還有很多很多衡量這種異常偵測系統的measure,那我們今天就不細講這些measure。
link |
舉例來說,一個常用的measure叫做AUC,就是area under ROC curve。
link |
那如果你用這種衡量的方式,你就不需要決定threshold,就有一些衡量一個系統好壞的方式是不需要決定threshold的,
link |
它是看你把testing data裡面所有的結果根據分數做一個排序,由高分排到低分,由最可能是異常的排到最不可能是異常的排一個排序,
link |
它直接根據這個排序來決定說這個結果到底是好還是不好。
link |
那總之有很多種evaluation的方式,那這邊就放一個AUC給大家自己survey,如果你想要研究這個問題的話。
link |
那總之就是要告訴大家說,異常偵測沒有辦法用一般的方法來評估一個系統的好壞。