back to index
Anomaly Detection (4/7)
link |
好的,如果我們直接用一個分類器來偵測是不是輸入的東西是不是異常的,那我剛才說其實它並不是一個很弱的方法,那有時候它沒有辦法真的給你perfect結果。
link |
為什麼呢?我們用這個圖來說明一下,用classifier來做異常偵測的時候,你有可能會遇到的問題。
link |
假設你現在做了一個貓跟狗的分類器,這個系統顯然可以知道貓跟狗之間的差異,它可以判斷一個東西有貓的特徵就放到一邊,狗的特徵就放到另外一邊。
link |
顯然,如果一個東西它既沒有貓的特徵,也沒有狗的特徵,比如說一個草泥馬或者是一個馬萊摩,沒有貓的特徵也沒有狗的特徵,機器不知道該把它放到哪一邊,可能就會把它放在一個boundary上,得到的信心分數就比較低,你就知道說這些圖片不是貓跟狗,它是異常。
link |
但是你有可能會遇到這樣的狀況,有些東西是比貓還要更像貓,有些東西是比狗還要更像狗,因為你今天機器它在判斷貓跟狗的時候,它是抓一些貓的特徵跟狗的特徵,也許老虎在貓的特徵上又更強烈,狼在狗的特徵上又更強烈。
link |
對機器來說,有一些東西,雖然它在訓練的時候沒有看過,它是異常的,它在訓練的時候沒有看過,它不算是正常的資料,但是它有異常的、非常強的那些特徵,會給你的分類器很大的信心,說它覺得它看到某一種類別,所以確實會有這樣的問題。
link |
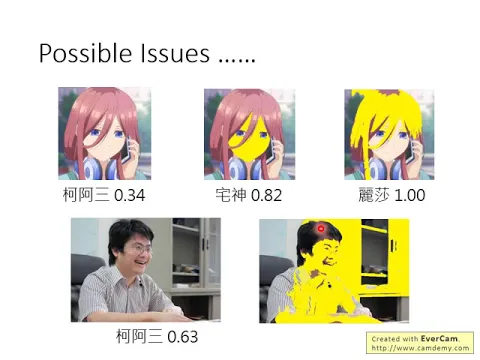
那怎麼解決這樣子的問題呢?在解決那個問題之前,我就想說,辛普森家庭的人物臉都是黃的,所以他用辛普森家族的classifier來偵測辛普森家族人物的時候,會不會其實他只要看到黃臉的人,信心分數就突然暴增了,所以就把三九的臉塗黃這樣子?
link |
然後他果然就覺得說他是宅神,變成82%,然後把他頭髮塗黃就變成麗莎,而且是100%,或者是我把自己的臉塗黃,搞不好臉塗黃以後就顯得特別猥瑣這樣子,然後他馬上覺得是麗莎88%。
link |
所以顯然這個系統對他來說,臉是不是黃色,是判斷辛普森家族的人物非常重要的一個特徵,所以今天你只要臉黃黃的,他就覺得你很有可能是辛普森家族的某個人物。
link |
當然有一些方法可以解這個問題,我們這邊一樣是列一些文獻給大家參考,因為發現這都不是很舊的文獻,都是去年的文獻而已。
link |
那一個解決的方法是說,假設我們可以收集到一些異常的資料,那我們可以教機器說,你今天看到正常的資料的時候,你不要只學做分類這件事,你要學會說,一邊做分類,一邊學說,看到正常的資料,我的confidence就高了,看到異常的資料,我們就要給他低的confidence,根據你怎麼計算confidence。
link |
比如說如果你用entropy來計算confidence的話,你就教機器說,看到異常的資料,你就要給他高的entropy,這似乎是一個解法。
link |
但是你這邊會遇到的問題就是,我剛才在一開頭就講過說,很多時候你不容易收集到anonymity的data,不容易收集到異常的data,所以怎麼辦呢?
link |
有人又想出了一個神奇的解決方法,就是既然收集不到異常的data,我們讓一個generated model來生成異常的data。比如說很多這種generated model,我們還沒有講過,比如說game它可以拿來生成data。
link |
但是你會遇到問題,因為現在生成的data你可能會生成太像真正的data,那就不是我們要的,因為異常的資料就跟正常的資料不一樣。所以今天要做一些特別的content,讓你生成出來的資料有點像真的,但是又要跟真的又沒有很像,
link |
然後你就可以有一些號稱是生成出來的異常的資料,有可能套用上面的方法來訓練你的classifier,偵測說看到異常的東西的時候要給它d的content。