back to index
Anomaly Detection (7/7)
link |
整個機器人做的,所以你要選多少feature都可以,你就可以把你想到的,覺得可能跟判斷一個玩家是正常的還是異常的有關的各種feature,通通把它加進去,通通把它加進去。
link |
舉例來說,你可以說,一個玩家他按star這個鍵的比例,可能代表了他是正常的玩家還是異常的玩家。因為傳說有一批troll,有一批小白,他們做的事情就是不斷地按star鍵,然後你就會不斷地打開道具欄,讓你什麼事都沒辦法做這樣子。
link |
舉例來說,你可以說,統計某一個玩家在過去某一段時間,比如說過去三十秒之內,他的選擇的行為如果跟其他人都一樣,跟多數人都一樣,代表他是跟大家想法比較一致的玩家。
link |
這個才有多少百分比,他的行為、他的決策跟其他人一樣,這顯然也是一個好的指標,判斷說他是不是一個正常的玩家。
link |
或是假設某一個玩家,他選的行為都跟別人最不一樣,這個也是一個指標,判斷他是不是一個正常的玩家,他有多喜歡跟別人唱反調。
link |
有了這些資料以後,你就可以去訓練出一個自己的new star跟新的star,然後你就可以創造一個新的玩家,然後帶進去這個function,就可以看說這個玩家算出來的分數有多高。
link |
我這邊會取一個log,因為一般來說你算出來的分數都非常非常小,所以我們會取一個log。
link |
假設輸入的這個玩家,他有10%說垃圾話、90%在無政府狀態發言、10%暗殺戒,然後他總是跟大家一樣,從來不跟大家唱反調的話,這個時候算出來的likelihood是-16。
link |
假設有一個人,他其他部分都跟第一個玩家一樣,但是他從來不跟大家一樣,然後有30%的時候在跟大家唱反調的話,那顯然是一個比較奇怪的人,因為唱反調是比較奇怪的行為,通常大家的行為都差不多,所以今天你按的button跟別人都很不一樣的話顯然是比較奇怪的,那這個時候他算出來的分數就再更低一點,是-22。
link |
不過這邊一個有趣的事情是,假設我創造一個玩家,這第三個玩家跟第一個玩家,他們在前三圍是一樣的,不一樣的只有第四圍,第五圍是一樣的,不一樣的只有第四圍,他只有70%的機率跟大家一樣。
link |
第一個玩家有100%都跟所有人一樣,他只有70%跟大家一樣,但是算出來他的分數其實是更高的,是高達-2。不過自己仔細想想看,這樣也是正常的,因為你總不可能永遠都跟別人一樣。
link |
所以在訓練資料裡面,在我們看過玩家的資料裡面,很少很少有人他總是跟別人的決定完全一模一樣。
link |
所以假設有一個玩家,他的決策永遠都跟別人一模一樣,他反而是一個奇妙的異常玩家。如果你今天有時候跟別人不一樣,反而看起來比較真實,你根據這個模型算出來的分數,反而是比較高的,反而比較容易被判斷成一個正常的玩家。
link |
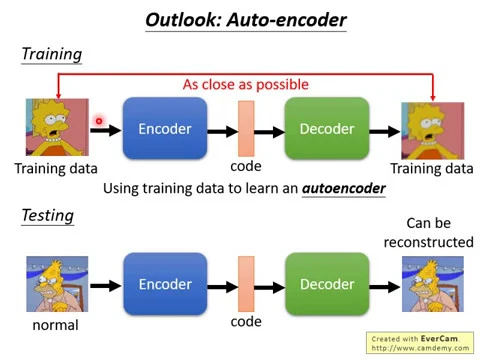
那這邊是用一個generative model,用一個Gaussian distribution來做異常偵測這件事情。那其實有其他的方法,舉例來說,你可以有deep learning base的方法,你可以訓練一個auto encoder來做這件事。
link |
那我們其實在這堂課裡面,我們還沒有講過auto encoder,所以這邊我們就當作是範圍外的東西很快地看過去。所謂auto encoder的意思是什麼呢?在之後的影片裡面,我們會再看到auto encoder這個東西。auto encoder做的事情就是,我們今天把所有的訓練資料都拿來,然後我們訓練一個encoder,encoder做的事情是把你輸進去的圖片,就假設我們現在回到辛普森那個例子,我們現在收集一大堆辛普森的圖片,
link |
那encoder做的事情就是把一張圖片變成一個code,變成一個向量,然後decoder做的事情就是把這個向量解回原來的圖片。在訓練的時候,encoder跟decoder他們是同時一起訓練的,他們訓練的目標就是希望輸入跟輸出越向越好,越接近越好,你是這樣訓練你的auto encoder的。
link |
然後在這個測試的時候,你就把一張圖片丟進去你的encoder,丟進你的encoder,這樣decoder還原原來的圖片。如果這張圖片它是一個正常的圖片,那你就會發現說它被還原的比例,它很容易被還原回來,你還原回來的圖片會跟原來非常的接近。
link |
因為今天這個auto encoder在訓練的時候,他看過的都是辛普森的圖片,他特別擅長還原辛普森的圖片。那如果今天你給他看到的是一個異常的東西,他通過encoder變成code,再通過decoder解回來以後,你會發現decoder無法解回來的圖片,解回來的結果跟輸入的圖片差非常的多,這個時候你就可以說它是一個異常的圖片。
link |
我們可以根據這個還原的還原度,還原度越低就代表說越有可能是異常的圖片,那我這邊就很快地帶過。
link |
那其實其他machine learning的技術也有做anonymity detection的方法,剛才舉的是deep learning的例子,那在SVM這樣的系列技術裡面有一招叫做one-pass SVM,它只需要正常的data就可以訓練一個SVM,讓你分類正常的data跟異常的data。
link |
或者是說在random forest,大家很常用random forest,在這種forest的base,在decision tree的base的方法裡面,有一招叫做isolated forest,它跟one-pass SVM做的事很像,給他正常的資料,訓練出一個模型告訴你說異常的資料長什麼樣子。
link |
那這個就是今天大概要跟大家分享的內容,時間拖有點久,我們就趕快請助教來講一下作業二。