back to index
Attack ML Models (6/8)
link |
好,那剛才講的呢,其實都是white box的attack,也就是說在剛才的攻擊裡面呢,我們需要知道network的參數。
link |
我們根據network的參數,我們才能夠計算gradient,我們才能夠找出那個最具有攻擊力的xπ。
link |
那因為在攻擊的時候,我們需要知道network的參數,這種需要知道network的參數的攻擊,我們叫做white box的attack,叫做白箱攻擊。
link |
這個圖意味不明啦,這就是有一個叫做白箱的動畫就是了。
link |
那這個是白箱攻擊,那所以有人就會想說,既然你攻擊的時候一定要知道network的參數,其實我們只要保護好network的參數,其實我們就是安全的囉。
link |
尤其是假設你今天要做一個線上的服務,做出線上的服務你並不會把你的network參數讓使用者知道,你並不會告訴使用者只要拖一個API,他能夠做語音辨識,能夠做影像辨識就算了,他也不要你network的參數。
link |
所以我們只要保護好network的參數,不要讓它流出去,那也許我們的線上的系統就是安全的。
link |
但事實上並不是這樣子,我們其實可以做黑箱的攻擊,也就是就算是不知道network參數的情況下,也是有辦法對一個系統,對一個machine learning的model進行攻擊的。
link |
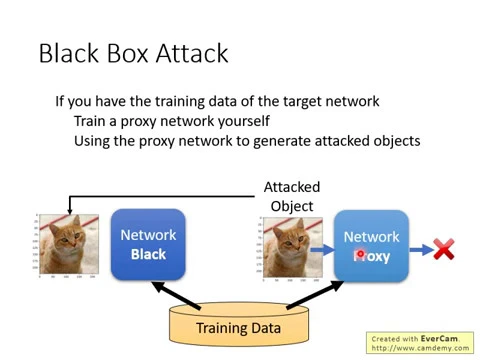
那怎麼做呢?這邊舉一個黑箱攻擊的方法例,你現在有一個network,它是一個黑箱,它是網路上的一個線上的API,你不知道它背後的參數長什麼樣子,你甚至不知道它背後的架構長什麼樣子,它就對你來說就是一個黑盒。
link |
但今天假設你知道這個network是用什麼樣的training data train出來的,舉例來說,你可能知道說這是一個影像辨識的模型,這個影像辨識的模型是用ImageNet那個corpus訓練出來的。
link |
假設你知道它是用ImageNet那個corpus訓練出來的,你就可以用訓練這個network所得到的訓練資料,自己去訓練一個network,把這個你自己訓練的network叫做positive的network。
link |
接下來,你用這個positive的network去找出attack的object,就是你用這個positive的network去計算規點,然後找出一張image可以成功的攻擊這個positive的network。
link |
接下來,你把這個可以成功攻擊positive的network的image,假設你現在做的是影像辨識的攻擊,然後你把這個可以成功攻擊positive的network的image拿去攻擊這個對你來說是黑箱的network,你往往能夠成功。
link |
這聽起來很神奇,就是你今天要攻擊的對象是positive的network,這個黑盒的network,這個black box的network,你不知道它的架構是什麼,你甚至不確定它是不是一個neural network,它搞不好是別的SVM、DCM等等。
link |
但是你用同樣的training data去訓練這個positive的network,然後找出一個可以攻擊這個positive的network的image,再去攻擊這個黑盒子,往往是可以成功的。
link |
有人會說,所以我們應該保護好我們的訓練資料,我們不可以讓別人知道說我們今天訓練的model是用什麼樣的訓練資料訓練出來。
link |
但是就算是你保護好你的訓練資料,別人仍然有可能進行攻擊,因為假設這是一個線上的服務,那別人可以丟很…
link |
假設你是一個線上的影像辨識系統,別人只要丟大量的image進去,然後從你的線上系統得到這些image的辨識結果,他把這些東西收集起來,
link |
也可以當作訓練資料,他同樣可以訓練positive的network,所以一樣可以採用黑箱攻擊的方式來攻擊一個什麼訓練你的model。
link |
其實有真實的實驗數據佐證說,黑箱攻擊是非常有可能成功的。
link |
現在假設你的黑箱有五種不同的network,有三種receiver network,VGG,還有Google net,他們的network架構都是不一樣,
link |
所以他們都是CNN,他們的network架構都是不一樣。
link |
你還可以在文件上找到有人試過說,假設你用neural network所找出來的attack的object去攻擊,比如說SVN,其實也是會成功的,非常神奇。
link |
這邊都是neural network,假設你的黑箱都是neural network。
link |
現在你訓練你的proxy network,假如是152層的residual network,你用你的proxy network找出來的image,可以攻擊你的proxy network的image,去攻擊同樣的黑盒子,當然是成功率非常高。
link |
這個代表系統的辨識錯誤率,辨識的正確率,它正確率變成只有4%,代表說你多數的時候,你的攻擊都是成功的。
link |
你將辨識變得非常弱,它只有4%的辨識率是正確的,多數的時候它會辨識錯誤。
link |
你用這個可以成功攻擊residual net 152的image,去攻擊residual net 101、residual net 50、VGG跟Google net,你會發現說它也可以讓這些network它的正確率變得非常的低。
link |
所以今天黑箱的攻擊也是有可能會成功的。
link |
這個攻擊甚至可以是universal的。我們剛才講說我們攻擊的時候,必須要為每一張不同的image找不同的attack的signal。
link |
因為不同的image,你到時候你做那個gradient descent,你用你的attack的alpha,算出來的那個signal,算出來要加上去給那個image的signal,通常是不一樣的。
link |
所以你為每一張不同的image,你都需要加上不同的signal來攻擊它。
link |
但是有人甚至嘗試說universal的attack,也是有可能成功的。
link |
你可以找到一個非常神奇的attack的signal,這個attack signal加到你的database裡面的所有image,多數時候都可以讓你database裡面的image辨識錯誤。
link |
你可以想像說,如果這種universal attack是有可能成功的話,有人如果在監視攝影機的鏡頭前面貼一張這樣子的雜訊,就可以讓那個監視攝影機總是辨識的結果通通都是錯的。
link |
所以他不需要為每一張不同的image都找不同的雜訊,你可以找出一個神奇的雜訊,它會讓所有image的辨識結果幾乎都是錯的。
link |
我把文獻貼在這邊給大家參考。而這個universal attack甚至也可以做黑箱攻擊,就是你找出來這個神奇的雜訊,你用A-network找出來神奇的雜訊,攻擊B-network還是有很高的機率是可以成功的。
link |
有人又做了adversarial reprogramming,他就說本來有一個network,他當時train的時候是想要做A任務,但是我們給他看一些神奇的雜訊,那個network就發狂,然後他解了變成是B任務。
link |
而在這個paper裡面,他想要做一個很新的paper,這是2019,甚至還沒有開的一個conference的paper。而他想要做的事情是這樣,你有一個很強的影像辨識的模型,然後他希望可以做到說這個影像辨識的模型可以去數我們輸入的圖片裡面有幾個方塊。
link |
如果今天我們輸入的圖片裡面有一個方塊,他就說這是一個patch,patch是什麼呢?我其實也不知道,我google了一下它的中文,我發現是種魚,但我還是不知道它是什麼就是了。
link |
如果裡面有兩個方塊,你就說它是一個goldfish,如果它有三個方塊,你就說它是一個white shark,如果有四個方塊,你就說它是一個titan shark,以此類推。
link |
本來這個network它的工作是來辨識各種不同的東西,比如說辨識不同的動物,但是我們把這個network做一番改造,我們希望它可以辨識方塊。
link |
那麼改造方法並不是對這個network的參數本身做任何的改變,可以想像說那個network其實是一個線上的API,你也不能夠動它。
link |
但是今天我們只要把這個我們要數方塊的這個小的圖片旁邊加上這些雜訊,你把這張圖片,要數方塊這個小的圖片,貼在這個雜訊上面,丟到這個imager classifier裡面,它今天就會幫你做數方塊這件事情。
link |
所以這個也是非常神奇,然後我把這個reference列在下面給大家參考,你可以改變一個network它原來想做的事,它本來是要做影像辨識,但是你給它看了一些雜訊的話,它就發狂來去做別的事情了。