back to index
Explainable ML (7/8)
link |
好,那LINE這個技術,我們就舉例一下說,剛才只是general的,說它的概念是怎麼樣。
link |
那我接下來說,如果實際上把這個技術用來解釋一個image的classification的classifier的話,那是怎麼用?
link |
好,那首先,你要先有一張你想要被解釋的圖片。那LINE呢,它通常都只能用在local的explanation上,
link |
因為如果你今天用的是linear model,也沒有辦法去fit一整個memo,你只能夠做local的explanation。
link |
你給一張圖片,你需要解釋說,這張圖片為什麼classifier會覺得它是一隻樹蛙。
link |
好,那第二步呢,我們說我們要做一下sample,那要怎麼做sample呢?你可以說,我把這張圖片加上一些雜訊,也許就是一些sample。
link |
或把這張圖片裡面的一些pixel拿掉,也許就是一些sample。
link |
那我剛才都講過說,你用不同的方法做sample,你得到的結果會非常的不一樣。
link |
如果你說,我現在的sample是,我把圖片裡面的一些pixel隨機的拿掉,每次隨機拿掉一個pixel,就叫做一張新的圖片,
link |
就叫做是在現在要解釋的圖片的附近拿到的sample,你可能不會得到太好的結果。
link |
那我剛才說過,拿掉一個pixel對你的classifier的輸出可能是沒有什麼影響的。
link |
那所以通常在使用line這個技術的時候,比較常見的做法是,你會先把你的影像做一下sample,把你的影像切成一小個一小個區塊。
link |
我們用這些小區塊來作為單位,來做接下來的分析。
link |
那通常我們的sample的方法就是,你會隨機的丟掉一些sample,你會隨機的把一些圖片上的區塊丟掉,然後產生不同的image。
link |
那舉例來說,在這個image裡面,有很大的區塊通通都被丟掉,所以丟掉的部分我們就塗灰色,在這個圖片裡面只有兩個區塊被丟掉,在這個圖片裡面有很多的區塊都被丟掉。
link |
你把這些有丟掉區塊的圖片,就當作是sample的結果。
link |
等於把這些sample丟到你的黑盒子裡面去,然後你就可以計算說,這些nearby的sample,這些sample把它丟到黑盒子裡面的時候,黑盒子輸出來的分數有多少。
link |
好,那你得到這樣子的結果以後,接下來你就要去找一個可以解釋的,你可以找一個linear的或者是可以解釋的model,去beat這個輸入和輸出的關係。
link |
你要找一個可以解釋的model,他丟進去這些圖片,他也會得到這樣的分數,然後你在分析那個可解釋的model,希望你就可以知道說,現在黑盒子在做什麼樣的事情。
link |
好,但是如果我們直接把這些圖片丟到linear的model,讓他輸出分數,你可能很難直接用linear的model吃這個圖片就得到這個分數。
link |
或者是說,今天如果你是讓一個linear的model直接吃一張圖片就算出分數,他這個linear的model輸入的參數的量,輸入的參數的量就會變得太多了。
link |
太多就是所有的pixel,你到時候分析其實也不太容易。
link |
所以一般而言,這個linear的model,到底要把什麼model用來beat這個data,你是可以自己做一些設計的。
link |
舉例來說,如果你把line用在影像處理上,比較常見的例子是,你會先做一個feature的extraction,你會先把這些pixel表示成一些比較低微的像量,
link |
然後再把這些比較低微的像量丟到linear的model裡面,希望他可以beat原來的定model,原來的黑盒子輸出的結果。
link |
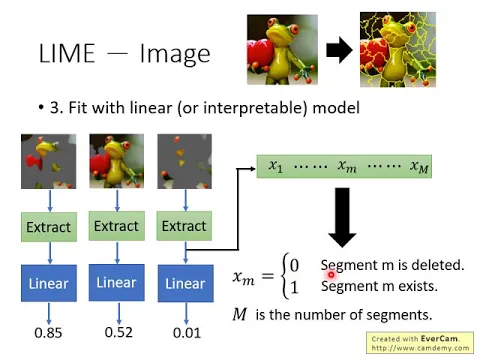
好,那這個沖降量的過程是長什麼樣子的呢?你怎麼把一張圖片變成一個像量呢?
link |
那這邊我們常用的做法是說,我們就看一個像量它的維度是M,這個大M的意思就是,你今天有幾個segment,這個像量就有多長。
link |
如果你今天有100個segment,這個像量的長度就是一個100微的像量。
link |
然後這個像量裡面的每一個dimension,它的值要嘛是1,要嘛就是0。
link |
0的意思就是說,如果今天這個segment,第M的segment被丟掉的話,那一微就換0。
link |
如果第M的segment沒有被丟掉,它還存在的話,它一微,那一微就換1。
link |
所以你會把一張圖片,它本來很複雜,你沒有一大堆的pixel,你把它用一個大M微的vector來表示它。
link |
那至於M的微度有多少,取決於你今天把你的image切成多少的小塊。
link |
而如果你今天把你的image切得很碎,有1000個segment,那你這個大M呢,你這個綠色的像量呢,它就是1000微。
link |
那這樣你可能會有很多小碎塊,你可能就不好分析。
link |
但是要切多少碎塊,才切多少segment,會讓你覺得比較好分析。
link |
這個是需要調的一個參數啦,你就調一下這個參數,看看你可不可以得到比較好的結果,讓你覺得比較滿意的分析的結果就是了。
link |
好,那接下來呢,有了這個Visual Extraction跟Linear Model,我們就可以訓練下去,我們就把這個Linear Model訓練出來。
link |
那Linear Model它可能長得像是這個樣子,Linear Model它的輸出是Y,它的輸入就是X1到X大M。
link |
那Linear Model會把X1到X大M前面通通乘上一個位子,這邊就是W1到W大M,然後再加上一個bias,你就得到了Y。
link |
那至於這個XM是什麼,我剛才講過說,這個大M就是你的segment的數目,XM等於0代表這個segment不見了,XM等於1代表這個segment,bM的segment仍然是存在的。
link |
好,那你從這個Linear Model的Weight,你就可以知道每個segment的重要性,舉例來說,假設某一個segment它配到的就是segment XM,
link |
bM的segment它配到的Weight的WM是趨近於0的話,那就意味著說這個segment對於判斷這張圖片是不是青蛙而言是不太重要。
link |
那假設某一個segment,bM的segment它配到的這個Weight的WM是正的話,那就意味著說這個segment對判斷這張圖片是不是青蛙是有正向的影響的。
link |
這個segment它是某一種hint告訴我們說這張圖片是青蛙,或者說假設WM做出來是一個複值,那就是告訴我們說看到這個segment反而會告訴我們這張圖片不是一隻青蛙。
link |
好,那我就實際的跑了一下Line這個東西啦,對,我就實際跑一下,那個其實很簡單的,大家作業就是要做類似的事情。
link |
我就把一張我自己的照片丟到一個Dimitry Pressify裡面,那他不知道為什麼沒有得到正確的結果,他看到說他看到和服,也看到實驗袍,和服的信心分數是25%,實驗袍的信心分數是5%,
link |
然後就想知道說到底和服跟實驗袍在哪裡呢?我們就用Line來分析一下,我們先分析一下這個實驗袍的位置,對機器來說呢,它覺得我身上穿的這個白色的衣服就是實驗袍,
link |
這個聽起來其實也還蠻合理的,所以就知道說這個model他雖然得到的答案不是很正確,但至少他想法沒有很奇怪,他的想法是正常的。
link |
那到底和服在哪裡呢?我發現我在窗戶上的倒影就是和服,所以他覺得說我在窗戶上的這個倒影,這件衣服其實就是他看到的和服。
link |
所以我們用Line這個技術可以知道說對一個image classifier而言,哪些segment是重要的,哪些segment是對結果沒有影響的。