back to index
Explainable ML (8/8)
link |
好,那我們剛才講的是我們用一個linear的model來分析我們的黑盒子。
link |
那這個黑盒子不一定要是neural network,它也可以是其他的東西。
link |
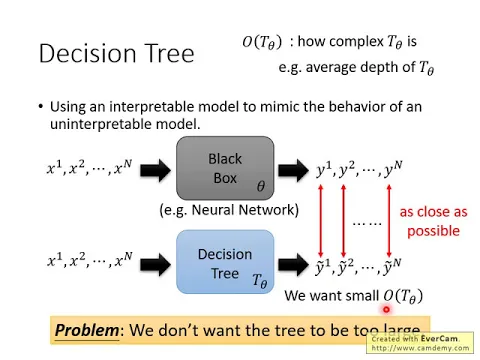
好,那這個可解釋性的model除了linear的model以外,還有其他的選擇,舉例來說,decision tree。
link |
好,那如果我們用decision tree來模擬一個黑盒子的話,會遇到什麼樣的問題呢?
link |
我們知道decision tree它有很強的能力,所以它確實很有可能可以完全模仿黑盒子的行為。
link |
你只要把decision tree它的深度無限的變深,它最終一定可以跟黑盒子的行為完全一模一樣。
link |
但是如果我們今天為了要讓decision tree完全模仿黑盒子的行為而訓練出一個非常非常深的decision tree的話,
link |
那我們就是搬了石頭砸自己的腳,就是為了搶快樂倒了不快樂,就跟梁靜茹唱的那首歌一樣。
link |
那怎麼辦呢?我們並不希望訓練出一個太過巨大的decision tree,
link |
我們希望我們今天訓練出來的decision tree它的深度是有限制的。
link |
那怎麼辦呢?我們用一些符號來formulate一下我們這個問題。
link |
我們假設我們這個黑盒子的參數是theta,而如果這個黑盒子是neural level的話,那theta就是neural level的參數。
link |
那根據這個黑盒子,我們訓練出一個decision tree,它可以模擬這個黑盒子的行為。
link |
那這個decision tree我們寫作大T下標theta,代表說這個decision tree它想要模仿的是這個theta的這個黑盒子,
link |
用theta作為參數的這個黑盒子它的行為。
link |
然後我們接下來第一個function,這個function它是一個decision tree作為input,它輸出是一個數值。
link |
那這個big O的theta這個function代表的是這顆decision treetheta它有多複雜。
link |
那至於怎麼定義一個decision tree它的複雜的程度,那這個就看你自己了。
link |
你可以說這個decision tree的平均的深度就代表了它的複雜的深度。
link |
那如果你用平均深度來代表decision tree的複雜程度的話,那這個big O這個function它計算的就是theta的平均的深度。
link |
那我們現在的目標是希望說這個big O的theta它的輸出不要太大。
link |
我們根據這個theta找出一個decision treetheta,我們把這個theta代到這個function O,我們希望它輸出的數值不要太大。
link |
那怎麼做到這件事情呢?我就看到了一個非常有趣的想法。
link |
這個有趣的想法是說,我們來訓練一個特別的network,假設你現在要分析的對象是一個network的話,
link |
我們訓練一個特別的network,這個network在被訓練的時候,它就已經想到它要被decision tree分析了。
link |
這樣你了解嗎?它已經考慮到接下來很多步了,它並不是只想說我要把我現在手上的,比如說影像分類的任務做好。
link |
它已經考慮到說,它被訓練完以後,它接下來會被decision tree分析。
link |
所以我們今天在訓練network的時候,我們希望這個network訓練出來的參數是容易被decision tree分析的。
link |
也就是說,我們今天訓練出來的這個network,把它轉那個decision tree的時候,那個decision tree是一個簡單的decision tree。
link |
那怎麼做呢?一般我們在訓練network的時候,我們就是定一個loss function,然後我們就用歸顛decision說,我要找一個setup,這個setup可以minimize我的loss function,就結束了。
link |
這個loss function可能跟影像辨識有關,它可能跟影像辨識的正確率有關,loss function越低代表影像辨識的正確率越高。
link |
但是我們現在並不只滿足於minimize這個loss function,我們再加了另外一項regularization的term。
link |
這一項代表了如果我們把這個setup用decision tree去模仿以後,這個decision tree的複雜的程度。
link |
我們希望找到,用歸顛decision找到一個參數setup,這個參數轉成decision tree,在計算它的複雜程度以後也要越小越好。
link |
我們希望這個network它不只是可以做好我們現在要做的任務,也就是它不只是minimize左邊這個loss function,同時它轉成decision tree,這個decision tree的複雜的程度也要越小越好,也不可以太高。
link |
所以這個東西就有點像是regularization的term,我們一般在做regularization的時候,我們用L1或者是L2的regularization說,我們的參數,它的none不能夠距離原點太遠。
link |
這邊是希望我們的參數轉成decision tree以後不可以太複雜,所以這個東西叫做tree的regularization。
link |
講到這邊你可能就覺得有點匪夷所思,因為我們今天要找setup,我們是用歸顛decision,但是右邊這個第二項可以做微分嗎?
link |
我們做歸顛decision的時候,我們必須要能夠做微分才能做歸顛decision,但是我們右邊這個第二項,它確實是沒有辦法做微分的。
link |
怎麼用歸顛decision去minimize這個function呢?怎麼用歸顛decision去解這個optimization problem呢?
link |
這篇paper是神奇的地方,它提出了一個非常神奇的想法,我其實覺得有點匪夷所思,它說它訓練了另外一個神奇的network,這個神奇的network給它一個network的參數,
link |
它可以預測這個network的參數轉成decision tree以後,這個decision tree的平均的深度有多少這樣子。
link |
這個network就是太強大了,這個network它是吃另外一個network的參數,然後它輸出一個數值,這個數值代表我們把這個network轉成decision tree以後,
link |
這個decision tree的平均的深度有多少,然後我們就把這個o跟state,跟o跟這個大t,換成那一個network,
link |
這個network雖然我看到paper,那個network沒有很複雜,它只是一個非常簡單的default network而已,但是根據它paper的結果,
link |
它還可以蠻準確的預測network轉成decision tree以後的深度,那你說那個network怎麼來?
link |
你就自己隨便random sample一些neural network,然後再把這些你隨便找來的neural network都轉成decision tree,然後再把那decision tree的平均深度算出來,
link |
你就有network的input跟output對不對,這種data收集個幾百幾千筆,硬訓練一個network告訴我們怎麼計算一個tree的dex,
link |
然後就把那個network套在這邊,然後那個network適可為分的,然後你就可以回結decision,然後就結束了。
link |
好,那細節你可以自己check一下這篇paper,所以結果我還覺得還蠻可以說是的。
link |
好,那這個部分我們就大概講到這邊,那接下來今天要講作業三跟作業四,所以我們就有比較多時間要講一下作業三跟作業四。