back to index
Life Long Learning (3/7)
link |
這邊再給大家舉一個例子,更具體的講一下EWC的概念。假設我們現在有兩個任務,我們現在有任務一跟任務二。
link |
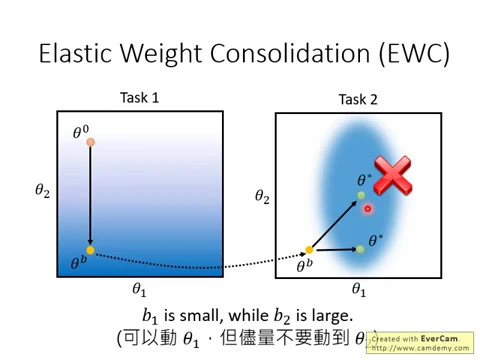
我們現在的network是一個非常簡單的network,它只有兩個參數,θ1跟θ2。我們現在在這個投影片上看到的這兩張圖,它們是任務一跟任務二的arrow surface,就是任務一跟任務二隨著參數不同的時候loss的變化,顏色越深代表loss越小。
link |
也就是說,假設今天θ1的值在這邊,θ2的值在這邊,那loss會很大。對Tasker來說,θ1是這個值,θ2是這個值,是不好的。
link |
然後對Tasker來說,如果θ1的值在這邊,θ2的值在這邊,那是好的,它的loss是小的。
link |
所以你今天在訓練的時候,我們知道我們在訓練的時候,你先讓機器先去學θ1,那假設在θ1之前沒有其他的任務了,那你就先隨便初始一下它的參數,random initialize你的θ0在這個地方。
link |
然後你就用Gradient Descent去調一下θ0,那θ0根據Gradient Descent的方向走,那可能就走到這個地方,那最後你就得到了,就是你讓機器學完θ1以後,它就得到了θB,那θB它在這個地方。
link |
接下來你要讓機器繼續去學任務2,所以你就把θB貼過來,同樣的參數,繼續用Gradient Descent去學任務2。
link |
那任務1跟任務2因為它們是不同的任務,所以它們的error surface當然是不一樣的,你同樣的參數在任務1和任務2上,你得到的loss是不一樣的。
link |
θB這組參數在任務1上會得到很低的loss,但在任務2上並不會得到非常低的loss,所以你要繼續去訓練,用Gradient Descent調整θB,讓你在任務2的loss上面變小,所以就調整一下θB,按照Gradient Descent的方向,可能就會跑到這個位置。
link |
我們把新的參數叫做θstart和θstop。如果你看任務2的loss,你會發現說從這個地方到這個地方,你的loss確實變小了。
link |
但是如果你回頭去看任務1的loss的話,你就會發現說現在任務1的loss變大了,換句話說,機器忘記了它過去在任務1上面所學到的東西。
link |
這個可以按作是一個簡單的例子告訴你說,為什麼災難性的遺忘會發生的原因。
link |
如果我們今天用了EWC的話,代表什麼意思呢?我們用了EWC,我們會為每一個參數設定一個保鏢,設定一個守衛BI。
link |
這個BI是怎麼來的呢?不同文章有不同的做法。一個簡單的做法是,算這個參數的二次微分。
link |
你可以想像說,現在我們的θB是在一個山谷的谷底,那我們算二次微分的時候,可以知道這個山谷的每一個方向,它到底是很寬敞的還是非常狹窄的。
link |
如果我們看θ1這個方向,發現說它的二次微分算出來是比較小的,意思就是說,從θ1的方向來看,θB是落在一個平坦的盆地裡面。
link |
那你改變θ1的參數,結果對Loss的影響並不會太大,所以這個時候你就可以給B1比較小的值。
link |
也就是說,今天在訓練的過程中,如果θ1這個參數被動到了也沒有關係,因為它對Task1的Loss影響不大。
link |
但如果我們從θ2來看,這個θB是落在一個峽谷之中。也就是說,如果我們從θ2來看,因為θ2的二次微分的值比較大,所以從θ2的方向來看,這個θB是落在一個峽谷之中。
link |
所以這個時候我們就要給B2比較大的值,因為從θ2的方向來看,θB是落在一個峽谷之中,所以如果我們改變θ2的參數,對Task1的Loss影響就會很大。
link |
所以我們就要把θ2這個參數保護起來,給它一個比較大的B,在之後的訓練過程中,盡量不要動到θ2,因為動到會出事,我們盡量不要動到θ2,這樣Task1的Loss才不會有太大的變化。
link |
那這個不是唯一的做法,文件上有各式各樣的做法,我今天只是舉一個例子而已。這樣大家有問題,我們還請說,二次微分是不是也可以作為一種Attack的方法?
link |
所以現在我們就不是在講Live learning,而是說在講Adversal attack。就是說,如果我們今天在Train network的時候,我瞭解你的問題,你是說,我們今天在做Attack的時候,我有一個現成已經pre-trained好的network,
link |
那現成pre-trained好的network,它的一次微分可能很小,可能是接近於0的,那我是不是應該要做二次微分?但是這邊有一件事要跟大家講的就是,你知道我們今天在做Attack的時候,我們改的是inputX,我們今天訓練完network,微分等於0是說,我們的參數θ,對我們的Loss的微分是0,但是X對Loss的微分不見得是0。
link |
你瞭解我的意思?所以你不見得會遇到這個X對你的Loss的微分很小這件事情。
link |
然後其實啊,有一件事情之前在講Adversal attack的時候是沒有講到的,你講確實有很多方法,他們為了避免Attack,他們的招數就是把一次微分設為0,就想辦法讓你在Train的時候多加一個Loss,是這樣一次微分設變成0,然後這樣你在做Adversal attack的時候不就Attack不到嗎?
link |
那其實要對付那種方法,你也不需要算二次微分,你其實用那個positive network就可以攻破那種方法,就是positive network,大家記得之前講Adversal attack的時候說,你可以用另外一個network去mimic原來的network,那你用另外一個network,他只要一次微分不是0,他就可以攻破原來那個network,所以這種把gradient藏起來這種方法是不見得非常有用的。
link |
所以之前就有一個人,他就propose一個Attack的方法,專門去針對這種gradient是0的方法,就把gradient藏起來的方法變成0,0的那種方法進行攻擊,然後他就說Iclear好像assign了九篇有可以防禦的方法,然後說那些方法都是垃圾,他就說他的方法可以攻破八片這樣子,然後其他人就很神奇。
link |
總之,B其實你有別的方法來做,反正你就是自己想,你可以完全propose一個自己的方法,看你覺得說要怎麼樣衡量一個參數,他到底對某一個任務是不是重要的,二次微分只是眾多其中一個可能而已。
link |
所以我們現在知道,如果你B1設得很小,B2設得很大,就是告訴network說,我們現在在訓練task2的時候,你可以動SETA1,你可以在這個方向上移動,但是你儘量不要在這個方向上移動,雖然在這個方向上移動可能可以讓你的loss變得更小,但是在這個方向上移動是不好的,你儘量不要在這個方向上移動。
link |
那你重新做訓練以後,那可能你就不會從SETA1跑到SETA2這邊,你可能會跑到這個地方,因為你只能夠動SETA1,SETA2儘量不要動,而跑到這邊,其實這個地方的loss可能這個地方的loss也差不了多少了,所以你可能最後收斂的結果就訓練,就是你的network最後就收斂在這個地方。
link |
然後回到task1,那你就會發現說loss沒有掉太多,代表說network其實並沒有遺忘它過去已經學會的技能。
link |
好,那這個就是EWC的概念,這個是最原始的EWC的那篇paper上面的實驗結果,它就說現在我們分別訓練task A、task B跟task C,這邊那三個task都是MNIST的,都是手寫數字編制,跟我剛才舉的那個例子是有點像的。
link |
它對這三種不同的task其實就是把MNIST的那個數字做不同的permutation,做不同的破壞,把那個pixel做一下random的shuffle,做不同的shuffle,就當作不同的task。
link |
好,那我們讓機器先學task A,然後接下來學task B的時候,這個第一個row的結果是task A的正確率的變化,那你就會發現說當機器開始學task B的時候,如果你是用一般的歸間descent,task A的正確率就開始下降,那學到task C的時候正確率又下降更多。
link |
如果你是用L2的regularization,那正確率其實不會下降太多,但是還是有點掉,那如果用EWC的話,你的正確率就幾乎不會掉。
link |
那如果在task B跟task C,你看一下這個L2的結果,你會發現說L2發生intransigence的現象,也就是說現在你的network在有apply L2的regularization的情況下,先讓它學task A,接下來再讓它學task B,然後看一下它在task B上的結果,你會發現說它撐不起來了。
link |
因為L2的regularization限制太大了,它學不會新的技能了,為了避免忘掉舊的技能,它反而學不會新的技能了。
link |
那在task C上也有同樣的狀況,先讓network已經學完了task A、task B,然後看看它在task C上的結果,你會發現說當你apply L2的regularization的時候,它學不起來了,它的正確率沒有辦法像其他的方法一樣高。
link |
代表說它為了記錄舊的事情,它變得很保守,它學不會新的技能了。
link |
那EWC有很多不同的變形,這邊就是列三個例子給大家的參考,所謂不同的變形就是剛才那個B,你用不同的方法來估測出那個B,就是不同的變形。
link |
除了EWC以外,我找到目前最新的是NAS,它有比較SI跟EWC,所以它比SI跟EWC都還要好。
link |
那NAS它的一個特色就是,我們在剛才算EWC的時候,我們是算我們的參數對loss的二次微分,那如果你要計算對loss的微分,不管是一次還是二次,你要知道loss的值,你需要有label的data,你需要有XY的pair,你才能夠計算loss。
link |
但是NAS這個方法,它特別的地方就是,它不需要label,它只需要X,它不需要Y,它就可以估測B出來。
link |
好的,這邊就列一下reference給大家參考。