back to index
Life Long Learning (6/7)
link |
那講到這邊呢,我們來講一下,怎麼衡量一個Life Long Learning的model。
link |
那這個部分呢,大家就知道一下大概念就好。
link |
Life Long Learning其實也是很新的問題,你會發現說,每篇paper都propose一個自己的evaluation的方法。
link |
那我這邊只是講一下說,大概,如果你要evaluate一個Life Long Learning的model,大概有什麼樣的面向。
link |
那通常你要evaluate一個Life Long Learning的model,你就會畫一個metric出來。
link |
這個metric的橫軸啊,代表的是在不同的task上的performance。
link |
假設我們現在有大體的task,那這個每一個column代表說現在在第一個task上的performance,
link |
第二個task上的performance,到第大體一個task上的performance。
link |
那每一個row代表什麼呢?每一個row代表是說,我們現在學完task1以後,在每一個task上面的performance。
link |
學完task2以後,在每一個task上的performance。
link |
到學完task的大體以後,在每一個task上的performance。
link |
那我這邊用這個0呢,來代表這個random。
link |
那在這個矩陣裡面,這個rij的意思就是,當我們學完第一個task的時候,在第這個task上的performance。
link |
舉例來說,這個r21的意思就是,當我們學完第二個任務,就機器把第一個任務學好了,第二個任務也學好了,機器學完第一個跟第二個任務的時候,它在第一個任務上的performance,這個是r21。
link |
或者說rt-1t的意思就是,機器已經學到了第t-1的任務,它已經學到第t-1課,那它在第t的任務,其實這個任務它還沒有學過,但未來它還沒學過那個任務上,它到底得到了多好的performance。
link |
所以rij的意思就是,先讓機器在機器學完第一個task的時候,它在第這個task上面的表現。
link |
那如果今天這個rij的i大於j,那是什麼意思?代表說,今天機器在學完第i的任務之前,它已經學過了第j個任務。
link |
所以rij想要看的事情是說,機器已經學到第i的任務了,那之前它學過的第j個任務,它到底忘記了多少?它到底還記不記得在第j個任務的時候學到的技能?
link |
那如果是i小於j的意思就是,我們想要知道說,今天機器學到第i的任務,它還沒學到第j個任務,第j個任務還沒學到。
link |
那它學到第i的任務的時候,這個第i的任務裡面學到的知識,從第一個到第i的任務裡面學到的這一串知識,到底能不能夠transfer到第j個task上面去。
link |
所以你要衡量一個Life-Long-Learning的系統的話,你就先畫一個這樣子的矩陣。接下來,你就可以在這個矩陣上定義各式各樣的標準,然後來說你的Life-Long-Learning的系統有多好。
link |
舉例來說,你可以說我想算accuracy。什麼是accuracy呢?上面accuracy就是,今天當機器把第一個任務到第t個任務統統都學完的時候,它在第一個到第t個任務上的performance的平均。
link |
你就把這個矩陣的最下面這個role的performance統統都平均起來,就是現在這個Life-Long-Learning model的accuracy。或者是你想要衡量機器今天會不會遺忘,它有多會做knowledge retention,它有多不會遺忘過去所學到的技能。
link |
你可以定義一個measure叫做backward transfer。這個backward transfer是說,我們現在把最後學完task的大T以後某一個task,假設task1的performance,減掉剛學完task1的時候的performance。
link |
或者是你把task2學到最後,學到大T的task的時候,task2的performance,減掉task2剛學完的performance,再把所有的task統統都平均起來。
link |
這個東西就表示了機器有多能夠記住過去的資訊。我講到這邊,大家有問題要問嗎?
link |
就是說,你先讓機器看機器在學完第一個task的時候,它得到的performance有多少,然後再看它一直學到大T的task的時候,在task1上的performance有多少。
link |
然後你再把學完大T的task的時候得到的performance,減掉剛學完第一個task,它還記憶猶新的時候的performance,看看這兩者之間的差距。
link |
那通常你算出來是會負的,因為機器通常會忘記它過去學的東西,如果你今天可以算出正的,那就很屌了。
link |
你通常會算出是負的值,因為通常這邊的正確率是最高的,剛學完task1的時候記憶猶新,正確率最高,接下來就慢慢忘記,慢慢忘記,慢慢忘記,然後學到大T的task的時候可能就忘得差不多了。
link |
我們希望說今天這個忘記的程度越小越好,所以你希望這個RT1跟R11它們的差距越小越好,它忘記的程度越小越好。如果是正的話最好,代表說它不只沒忘記,還畜類蟠蟲,就學了未來的東西,之後學了新的課程,對過去它所學到的技能居然還有加成的效果,那這樣子是最強的。
link |
這個是forward transfer,是要量機器有多能夠做knowledge retention,多能夠記憶,多不會遺忘。另外,你也可以量forward transfer,就是機器在transfer到new task上面的能力有多強。
link |
那要算knowledge transfer怎麼算呢?我們以task的大T作為例子,你就計算說,task的大T在機器還沒有開始做任何學習之前,它們的performance有多少,我們把random initialized model用0來表示。
link |
所以R01代表說,今天是一個random initialized model在task1上的performance,random initialized model在task2上的performance,random initialized model在task大T上的performance。今天一開始,機器它的參數是random initialized,所以它在大T上顯然不會得到太好的performance。
link |
接下來讓它學學學學學,在它學大T的task之前,它還沒看到大T的task,大T的這個task,它只學了第一個到T-1的task,它還沒學大T這個task。它把之前的task都學完,它到底已經學到大T這個task學到了什麼樣的程度?
link |
那這個叫做forward transfer,就在還沒有看到要它學task之前,它看了別的task,到底已經可以學到多少東西?
link |
好,那這個就是幾個你常常拿來衡量你的lifelong learning model的方法。那我們剛才講說,如果有一個model它可以做到forward transfer算出來是正的,那就很厲害。那有些model確實可以做到forward transfer算出來是正的,就你不只不會遺忘,還可以學新的task還會觸類旁通。
link |
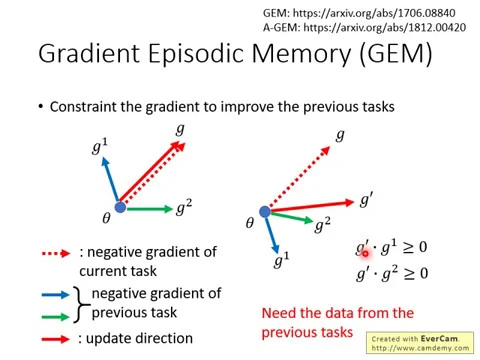
那這邊舉一個例子,叫做Gradient Episodic Memory,它所寫的是GEM。那GEM它想要做到的事情是說,我們今天在新的task上算出我們的Gradient,我們今天要optimize一個新的task,所以要Gradient descent嘛,要算Gradient,它在新的task上算出的Gradient,它稍微修改一下,改一下它的方向,希望它對過去的task也有幫助。
link |
什麼意思呢?今天假設你現在要訓練的model叫做Seda,在新的任務上,在你現在要考慮的那個任務上,你算一下它的Gradient,或者說算一下它的Gradient的負的方向,因為我們update參數的時候是走負的方向嘛,你算它的negative的Gradient,告訴你說,我們現在要把參數往這個方向update,可以讓loss下降最多。
link |
然後呢,你再回頭過去計算一下之前的task它的Gradient的方向,但是如果你要計算之前的task的Gradient的方向的話,意味著其實你是偷偷存了一些之前的task的data,所以其實GEM這個model跟其他model比起來也稍微有點不公平,因為它其實是有存過去的task的資料,
link |
只是它可能不把整個code格存下來,而是每個task都只取幾筆存下來,比如說每個task都只取十筆存下來這樣子。
link |
假設你可以有一些過去的task的資料,所以你也可以計算說,假設我今天要minimize過去的task的loss,那我歸點是要怎麼走?假設我今天過去有兩個task,task1跟task2,現在要取的是task3,那你可以計算出,假設我要minimize task1的loss,那我歸點是這個方向,那我要minimize task2的loss,我歸點是這個方向。
link |
那這兩個方向跟G這個方向,因為它們的data都是正的,它們的內積都是正的,那我們就往G這個歸點的方向來走,那今天假如你算出來G是這個方向,但是你要讓過去的task它loss下降的方向分別是G1跟G2,
link |
這個時候如果你把你的歸點往G這個方向移動,你把你的參數往G這個方向移動,那因為跟G1的這個方向,它的inner data是負的,所以你現在update你的參數的時候,你可能就會傷害到過去第一個task的performance。
link |
那為了不要傷害到第一個task的performance,你就稍微轉一下這個G的方向,你就稍微轉一下,把G轉到Gπ的方向,這個轉方向的條件是希望轉完這個方向以後,這個新的方向Gπ跟G1的inner data跟G2的inner data至少都要大於等於零,
link |
可以確保說我們往Gπ這個方向做update你的參數的時候,不會傷害到G1跟G2,搞不好還可以讓你過去的task的loss變得更小,或至少不要傷害到過去的task,至少不要讓過去的task的loss變大,搞不好還可以讓過去的task的loss變小。
link |
但同時因為我們也不能讓現在的這個task變差,所以我們希望說Gπ跟G的距離應該要越近越好。然後在這些constraint之下,你就解一個optimization problem,找出一個最好的Gπ,它跟G的距離是最近的,同時跟G1跟G2做inner data以後是正的,
link |
然後你今天update參數的時候,不是順著native gradient的方向去update,而是順著這個新算出來的這個新的參數update的方向去update。講到這邊,大家有問題要問嗎?
link |
對,這邊就是你每次update參數的時候,你都要算一下G1跟G2這樣,其實這樣G1跟G2是現場算出來的,對不對,因為你在算task1跟task2的時候,你並不知道你之後的model的參數是在哪個地方。
link |
就今天這個model是會一直變化的嘛,那你今天要算gradient是跟這個model其實也是有關係的,所以變成G1跟G2是每次你要update參數的時候,你都要回頭去把G1跟G2都算出來。
link |
所以這就是為什麼你必須要存一些過去的data,你才能夠算G1跟G2,所以這個方法是需要存一些過去的data,所以跟其他方法比也是有一點不公平的。
link |
我今天講的這些papers其實都是很新的東西,所以有很多東西都是還沒有人嘗試過,像你剛才講的其實就是一個很好的想法,今天居然要產生data,要存一些data不太公平,那能不能夠自己升級data。
link |
這邊我放的一些reference都是很新的,比如說2017年、2018年的papers。
link |
對,就GEM,這個是比較舊啦,是2017年的papers,後來有一個新改進的版本叫AGEM,它應該是在今年的,它會發表在今年的IKEA,你要知道今年的IKEA,一般都還沒有開就是了。
link |
好,如果沒有的話,我們來看一下GEM的performance,它就很屌啊,它backward transfer居然是正的。
link |
我們來看一下它在anis的permutation這樣的test,就是說我們把anis的hocus的image拿出來做種種的擾動,一種擾動就叫做是一種test,然後就做了一大堆的test。
link |
我們就看左邊這個圖就好,那我們剛才說我們在做evaluate的時候,三種evaluation的measure,一個是所有的任務通通學完的時候,對每一個任務的正確率最高。
link |
它這邊比較是有把GEM跟EWC比,那這個single的意思就是說同一個model,然後把所有的task通通都學完,第一個學完第一個,再學第二個,然後沒有做任何其他的事情。
link |
然後independent是每一個task都獨立的去學一個model,然後multimodel這個有點難解釋,我們今天就不要解釋了,總之就是GEM它的正確率最高。
link |
然後如果你看backward transfer,就是它會不會遺忘過去的東西,它不只不遺忘過去的東西,居然全部的test做完以後,過去的任務做出來,正確率還稍微高了一點點,其他的方法,backward transfer都是負的,都會遺忘一些東西。