back to index
Life Long Learning (7/7)
link |
最後我們要講model的expansion,我們剛才在討論裡面,我們都假設說今天你的network的capacity是夠大,也就是說你的network的參數夠多,他其實是有能力把所有你要他學的任務都學會,他有能力做到這件事,只是他不想做而已,所以我們想個辦法讓他可以做到這件事。
link |
但是還是有一個可能性,也許今天你的任務實在是太多了,network就已經到他的極限,他真的是學不了新的任務了,就算你用multi-task learning把所有的data統統倒起來,讓network一起訓練,他也許也已經學不起來。
link |
那我們能不能夠讓network做到今天他可以自動擴張他的model的大小,他發現說今天他的能力已經不夠了,他就自動生一些新的神經元出來,讓他可以解更多的任務。
link |
但是我們不希望機器今天在擴張他的model的時候是任意的擴張的,我們希望他今天在擴張他的model的時候是有效率的擴張的,因為如果今天你設定的strategy是今天每次沒有一個新的任務,機器都要擴張一下他的model,你擴張model的速度跟任務進來的速度是成正比的,這樣隨著任務越來越多,你的model參數會越來越多,最終你終究會沒有辦法把你的model存下來。
link |
所以我們今天會希望說,你的model的擴張速度最好不要跟你新的任務進來的速度是成正比的,應該要比你新的任務進來的速度要慢,不然你今天最終你的model成長的速度會太快,你沒有辦法把你的model存下來。
link |
其實在model expansion這個部分,這個也是一個上代研究的問題,就沒有太多的文獻可以跟大家講,我今天就很流水上的分享幾個例子,而且這些方法通常在model的parameter efficiency上都還不是做得太好。
link |
一個最經典的例子就是progressive neural network,progressive neural network它的方法是說,我們現在先讓機器去解任務一,就跟訓練一般的neural一樣,我們訓練了第一個neural。
link |
接下來要讓機器解任務二的時候怎麼辦?我們再開另外一個neural出來,讓機器去解任務二,但是如果我們直接開一個新的neural出來讓機器去解任務二,就沒有做到noise transfer這件事,那怎麼把noise transfer這件事考慮進來呢?
link |
我們說,今天這個第二個neural,它的input會吃第一個neural的output,也就是說,今天同一筆資料進來,它不只會通過test2所訓練出來的neural,它也會通過test1所訓練出來的neural。
link |
那test1的這個neural參數就固定住,就不動它,因為如果你再去動這邊的參數的話,那可能機器就會把test1的任務忘掉。所以今天test1已經學好了,它相關的參數都不動它,但是在解test2的時候,這個test2的neural會去把test1的neural的output當作它的輸入,以便它可以做到noise transfer這件事,把在test1學到的一些noise transfer到test2上面去。
link |
那你說如果有第三個test怎麼辦呢?再開第三個neural,第三個neural它會把test1跟test2的hidden neural的輸出都當作它的輸入再接進來。
link |
你會發現說,當你的test越來越多的時候,如果你今天有test4,它就要接test1、2、3的參數,如果有test5,它就要接test1、2、3、4的參數。test1、2、3、4是neural的output,你的參數量會越來越多,終究是會沒有辦法負荷的。
link |
所以在實作上,這個方法終究是沒有辦法學太多的任務,不過這個是比較早期的,你看2016年就是比較早期的一個paper,叫做Progressive Neural Network。
link |
還有其他的想法,有一個想法叫做Expert Gate,他的想法是說,我們現在一樣還是每一個test就去訓練一個neural。
link |
那如果每一個test就去訓練一個neural,就做不到neural transfer這件事怎麼辦?他說他認了另外一個test的detector,這個test的detector他是說,有一個新的任務進來,他會去看說這個新的任務跟哪一個舊的任務最像。
link |
如果假設今天進來第三個任務發現說他跟第一個任務最像,他就把第一個任務訓練好的model拿來當作第三個任務的initialization,那希望這樣子可以做到一些knowledge transfer的效果。
link |
不過他也是每多一個任務就會多一個model,所以他的model的參數量的成長速度跟任務增加的速度是一樣快的。
link |
還有一個方法叫做net-to-net,他也是要讓network長寬的方法。
link |
那怎麼讓network長寬呢?如果你今天只是說,我今天要讓一個network多十個neural,你就直接把十個neural加進去,那你可能會破壞了原來的test。
link |
因為你加了新的十個neural,那你現在整個network function就變了,那你的network做的事情就不一樣了,他可能就會忘記過去他學到的技能。
link |
所以怎麼加入新的neural而不忘掉過去的技能呢?那這個就是net-to-net那篇paper想要解決的問題。
link |
那這邊就是直接從那篇paper裡面尻了一個例子出來,他說我們原來的network只有兩個neural,我們要怎麼把它變成三個neural,
link |
但是完全不會傷害到原來的function,完全不會改變這個network原來可以做的事情呢?其實概念非常簡單。
link |
本來這個neural,它的input的weight是c跟d,它output的weight是f。
link |
現在我們要多加一個neural,那我們怎麼做呢?我們把原來這個neural進行分裂,原來的input是c跟d,新的input也是c跟d。
link |
原來的output是f,現在新的output就變成2分之f。
link |
那你就會發現說,左邊這個network跟右邊這個network,他們做的事情會是一模一樣的。
link |
但是右邊是一個比較寬的network,你就可以把你的network變寬,但是它不會忘記它過去已經學到的技能。
link |
但是如果你光只是這樣做,可能會有問題,你會發現說這兩個neural是一模一樣的。
link |
所以到時候Chain起來會發現說,這兩個neural相關的weight,它們得到的規定算出來永遠都是一樣的。
link |
那這兩個neural,它們在update參數的時候,它們的參數永遠都是一樣的,所以這兩個neural等於沒有任何的作用,它們做的事情就是一模一樣的。
link |
所以怎麼辦?你會加上一個小小的noise,你會在這些neural相關的參數上面加一個小小的noise,讓它們兩個看起來還是有一些些不同,但是不影響整個network它本來已經學到的技能,然後再拿去做訓練,這個就是net-to-net的概念。
link |
你可以找到一篇去年的News的workshop,它裡面就有用到net-to-net這個概念,然後它也不是每進來一個新的task就做net-to-net這件事,而是說今天如果進來一個新的task,
link |
然後它在這個task上面去learn,發現說它的loss降不下去,或者是在training data上的accuracy升得不夠高,然後才去做net-to-net這件事,才去把它的network變寬。
link |
也就不是進來每一個新的任務都應該把network變大,而是進來這個新的任務發現說,在training data上解不了,training data的accuracy太低了,training data上的loss太低太高了,然後再把network變寬。
link |
好,那其實這個主要就是今天想要跟大家分享的內容,就是如果我們要解life long learning的話,我們至少要解三個問題,knowledge retention, knowledge transfer和model expansion。
link |
那在未來,假設life long learning已經變成了一個非常常見的技術的話,我們其實會有新的問題,這個新的問題是這些任務的順序應該怎麼排比較對?
link |
我們剛才在舉例的時候,我們先讓機器學任務一,再讓它學任務二,發現說它會忘掉過去在任務一學的東西。
link |
但是我發現說,如果我們調換一下學習的順序,先學任務二,再學任務一的話,會發生什麼事呢?
link |
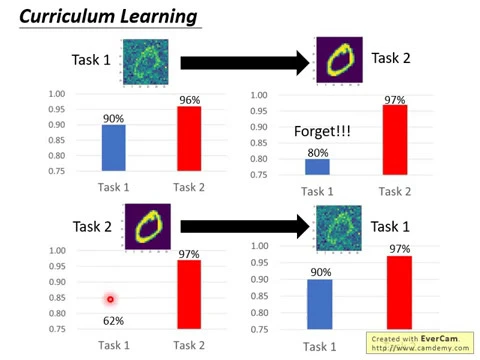
機器先學任務二,今天它學了任務二,它可以做得很好,任務二做得很好,97%的正確率,但是它在任務二上學到的知識無法transfer到任務一上。
link |
它在任務二上,它看任務二的data,它在任務一上只有62%的正確率。不像在這邊,看任務一的data是可以transfer到任務二上去的,它只看了任務一的data,在任務二上都有96%的正確率。
link |
在這邊,給它任務二的data,在任務一的結果上是會殘掉的。但是接下來讓它學一下任務一,發現說它居然就沒有忘記了。
link |
本來任務二可以做97%,看了任務一的data,學會任務一的技能,它還是97%,它並沒有發生忘記這件事情。
link |
所以這告訴我們說,會不會發生遺忘這件事情,knowledge能不能夠做transfer這件事情,跟你任務的排序的順序是有非常大的關係的。
link |
所以假設未來的live long learning變成一個非常熱門的主題,大家都知道怎麼做了,那接下來要問的問題就是,你要讓機器先學什麼任務,再學什麼任務?
link |
這個問題叫做curriculum的learning,你要讓機器的教材排一下順序,告訴它先學什麼教材,後學什麼教材。
link |
確實已經有一些這樣的研究,舉例來說,在CVPR的2018的best paper就是一個相關的研究。
link |
在那篇paper裡面,他提出了一個東西叫做Testanonymy,Testanonymy是Test加Testanonymy這兩個字的合體,Testanonymy就是分類學的意思。
link |
他就想要對種種跟影像有關的任務進行分類,跟影像有關的任務有很多,有object detection,有depth estimation,有segmentation,有各式各樣的任務。
link |
這些任務間他想要知道說,到底有什麼樣的關係,到底應該先學什麼任務,後學什麼任務?
link |
他就做了一個study,可以在下面這個連結看看他是怎麼做的,找出這些任務間先後的次序。
link |
舉例來說,他發現說,你應該要先學怎麼做edge detection,跟先學怎麼做normal estimation,就是找一個平面的法向量。
link |
先學這兩個技能,可以幫助你去把reshading,reshading就是換光源的方向,跟point matching,就是知道說這兩個房間的中心點是不是一樣的,
link |
就一個同一個房間,兩個不同視角,你怎麼知道它是同一個房間,可以把這兩個任務做得更好。
link |
但反過來,你先學這兩個,再學這兩個就沒什麼用了,你要先學這兩個任務,才能夠學這兩個任務。
link |
所以這些任務之間是有某種順序關係的,那未來一個需要探討的問題就是,那怎麼為這些任務排出一個最好的順序,讓機器最有效率地學習。
link |
好,那今天有關Live long learning的部分呢,就講到這邊。