back to index
Meta Learning – MAML (2/9)
link |
好,第一步,你要準備一堆learning的algorithm。在講deep learning的時候,我們說什麼叫做準備一個function set,我們說network的architecture,network的架構,當你訂出network架構的時候,你就有了一個function set。
link |
那到底什麼叫做一組learning的algorithm呢?什麼叫做一組learning的algorithm呢?我們先來看一下我們一般常用的learning的algorithm,舉例來說,gradient descent是怎麼做的?
link |
gradient descent是怎麼做的呢?你先定義一個network的架構,這個是冷定的,然後你要想個辦法初始化你的參數,你從某一個distribution裡面sample出數值來當作你的初始的參數,然後接下來你要根據這個初始的參數,還有你的訓練資料去計算出規點,我們這邊用G來表示規點。
link |
有了規點以後,你就可以拿這個規點去update你的初始的參數,那通常update的方法就是把這個規點乘上一個小小的learning rate,再把規點乘上一個小小的learning rate去減掉你現在初始的參數,你就得到了新的參數,然後根據新的參數再計算一次規點,再計算一次規點,根據訓練資料計算出規點G。
link |
但這兩個G是不一樣的啦,我這邊用台灣的符號,其實不是很精確,因為你現在是不同的參數,雖然是台灣的資料,但不同的參數算出來的G應該是不一樣的,那算出規點以後再去update你的參數,然後要反覆很多次,然後最後就輸出最終的訓練結果,我們講說最終訓練出來的參數叫做setahead。
link |
那這整個training的process,你可以把它看作是一個function,這整個training的algorithm,你可以把它看作是一個function,輸入就是訓練資料,輸出就是最終訓練後的結果。
link |
而在這個training的過程中,有很多的步驟都是我們人手去設計的,內部架構長什麼樣子,是人手去設計的。初始的參數怎麼來,這個也是你人想辦法去設計出來的,它並不是學出來的,它是設計出來的。
link |
然後怎麼update你的參數,得到這個G以後怎麼update這個setahead,這也是人design的,因為你可以調整你的learning rate,你可以調整你的learning rate設定的方式,比如說選擇add-in、rns-pop等等不同的update,不同的gradient descent的變形,你就有不同的update的方式。
link |
所以今天在我們常用的gradient descent這個learning的algorithm裡面,我們這些紅色的方塊是人設計的,而這個紅色方塊裡面當我們選擇不同的設計的時候,其實我們等於就是得到了不同的learning的algorithm。
link |
所以我們今天在meta learning裡面,我們要做的事情其實就是,在這個紅色方塊裡面有沒有一些部分我們不要人來設計,我們讓機器自己來學,比如說我們放寬initial這個參數初始化這件事情的設計。
link |
我們可以想成說,每次我們用不同的初始化的值,我們就會得到不同的學習的結果,所以不同初始化的值其實就可以想成是不同的learning的algorithm。
link |
所以我們今天能不能夠不要用一個人為定義的方法來找出初始化的值,而是讓機器自己去學出,我們今天要做我們群learning的時候,什麼樣的初始的參數對訓練nerver而言是最好的。那如果可以做到這件事,就算是達成meta learning的其中一塊。
link |
所以我們今天可以想成說,不同的initial的參數就等於是不同的learning algorithm,我們現在不預設我們的這個initial的參數要怎麼被找出來,不預設這個initial的參數應該長什麼樣子,我們其實就是有了一個learning algorithm的set。
link |
講到這邊,大家有問題要問嗎?沒有的話,我們就繼續。我們現在有了一個learning algorithm的set,裡面有一大堆的learning algorithm,那接下來第二步就是我們需要有辦法去評量一個learning的algorithm,它有多好或者是多不好,我們要有辦法去評量一個learning algorithm的好壞。
link |
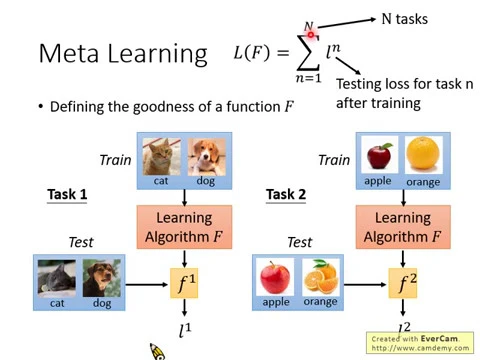
那怎麼去評量一個learning algorithm的好壞呢?在原來的machine learning裡面,我們會定一個loss function來評價一個function的好壞,那在這邊我們要評價一個learning algorithm大F的好壞,我們一樣也可以定一個loss function。
link |
怎麼定一個loss function呢?我們怎麼知道一個learning algorithm它是好還是不好呢?那你就實際拿這個learning algorithm來學一些task看看,讓它來解一些問題看看。
link |
所以我們現在就說,我現在已經找了一個task 1,這個task 1是貓跟狗的分類,要準備一些訓練資料,然後根據我們現在要評估的learning algorithm F5,把訓練資料帶進去,學學學就學出了一個參數,學出了一個訓練的結果。
link |
那我們這邊用F1來表示學習出來的結果。那這個學習的結果到底好還是不好呢?你要有testing set去評量這個學習的結果的好壞,所以你把task 1的這些testing data丟到function 1裡面看看你得到什麼樣的結果。
link |
那得到的結果,我們這邊用L1來表示。那你只是一個testing的task是不夠的,只是一個任務是不夠的,也許這個algorithm就只是特別會解任務1,不會解別的任務。
link |
所以你要準備一把任務來衡量你的learning algorithm的好壞。就像你今天在machine learning裡面,你要知道一個function好不好,你要準備一個training set,很大的training set,去評量一個function的好壞。
link |
那這邊你要評量一個learning algorithm好不好,你要準備一個learning的任務的集合,你要有一堆task的set,你要一大堆的任務去衡量你的learning algorithm的好壞。
link |
所以假設我們今天有個任務2,那任務2當然要跟任務1不太一樣,任務2可能是分類蘋果跟橘子,然後learning algorithm可以找出另外一個function F2,然後任務2也有一些測試資料,我們把測試資料帶到F2裡面,會告訴我們說,現在這個learning algorithm找出來的function在task和tube上面表現如何,表現我們用L2來表示。
link |
所以可以想成這邊L1跟L2,就是這個function在testing set1,在第一個任務的testing set上面的loss,L2就是這個function,learning algorithm產生出來的function,在task2上的testing set上得出來的loss。
link |
那我們把我們手上所有的task,就假設我們現在有大N個task,我們現在有一個learning algorithm讓它去學這個大N個task,每一個task我們都可以算出一個loss值,這個loss的值我們用小寫的L來表示,上標N代表是第幾個task,用小寫的L代表是某一個task上面的learning algorithm得到的任務。
link |
那把我們所有手上有的task,用這個learning algorithm去得到function以後,再去測試得到出來的loss,全部加起來,得到大L,用這個大L來評估一個function的好壞。
link |
所以我們怎麼知道一個learning algorithm到底好不好呢?你就把這個learning algorithm丟到這個大寫的L裡面,然後看這個大寫的L的值,這個值越小,就代表說現在這個learning algorithm越好。
link |
所以這是第二步,我們能夠有辦法去決定,定義出一個learning algorithm它是好的還是不好的。