back to index
Meta Learning – MAML (6/9)
link |
那這邊有一個Toy example,就展現一下NANL跟Transfer learning之間的差異,那這個Toy example呢,就是在原始的NANL那篇paper裡面,它也有做這個Toy example,不過我這個圖呢,是從這個部落格上載下來的,我覺得這個圖是比原來的NANL的paper講得更加清楚一點。
link |
好,我們現在Toy example是這樣,我們每一個訓練跟測試的任務啊,這個任務是什麼呢?這個任務是說,我們先假設我們有一個side function,Y等於AsinX加B,然後這個A呢,就是Ampitude,這個B呢,就是Phase。
link |
我們從這個side function裡面呢,去隨機sample出K的點,當作我們的訓練資料,當作我們的某一個任務裡面的訓練資料,然後我們再用這些訓練資料去想辦法估測出一個function,我們希望根據那些訓練資料,根據這個K的訓練資料估測出來的function,跟原來sample的那個function,拿來做sample的function Y呢,越接近越好。
link |
那我們現在的每一個任務,不管是訓練的任務還是測試的任務,我們要做的都是一樣的事情。
link |
然後接下來,你要怎麼製造各式各樣不同的任務呢?你只要有sample不同的A跟B,你就可以製造出不同的任務。
link |
所以你用一組A跟B,你就可以製造出一堆的訓練的task,你用另外一組A跟B製造出一些測試的task,那接下來你就可以跑meta的領域。
link |
好,那接下來我們就來看一下這個NNL在這個tool.example上面的結果。
link |
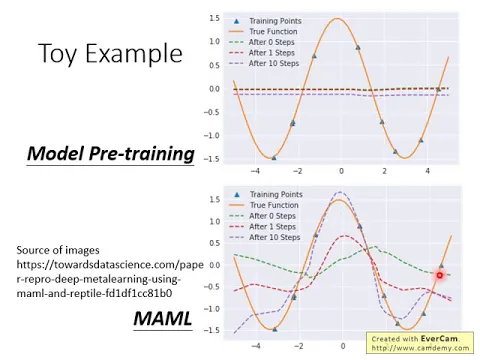
我們現在看model pre-training的結果,在這個圖上,橙色這條線是我們的測試的task,我們就假設說我們只有一個測試的task。
link |
它會從這個測試的task裡面sample出幾筆資料,這邊應該好像是sample出十筆吧,不過有一些資料是還蠻重疊在一起的,就sample出一些資料,然後拿這些資料想辦法去訓練出一個function。
link |
那希望用這些資料訓練出來的function跟這個橙色的function越接近越好。
link |
那如果你是用model pre-training的方法,model pre-training的方法訓練出來的initialization的參數,那個find它做出來的function是一條水平的線,近乎水平的線。
link |
這邊綠色的是還沒有做training的時候,也就是你的初始的參數find它的結果長什麼樣子,然後它跟紅色的線有點重疊,它也是一條水平線。
link |
那為什麼它會是一個水平線呢?你想想看哦,你今天在做model pre-training的時候,你是希望找出一個初始的參數,它在所有的training task上表現都好。
link |
那所有的training task就是一大堆的sign函數,一大堆的sign函數,那它們的amplitude跟phase都不一樣。
link |
你想想看,你把一大堆不同的sign函數疊起來,它不就只是一個水平線嗎?因為在同一個位置,有的地方是波峰,有的地方是波谷,你sample一大堆的sign函數疊起來,變成一條水平線。
link |
所以你的training learning能夠認到的就是一條水平線。
link |
那這條水平線可能是一個很不好的初始的參數,因為你發現說拿這條水平線再去做fine-tune,訓練一個step,得到的仍然是一條水平線。
link |
訓練十個step,你只是把這條水平線平移而已,結果能量很差。
link |
如果你做NAML的話,結果就不太一樣。現在NAML在還沒有做任何training的時候,它是綠色的這一條線,它當然跟你的目標,也就是橙色這一條線,是有一段差距的。
link |
但現在如果你讓它只訓練一個step,你讓它update一次參數,就是你從這個橙色的線上sample出幾個點,然後用綠色的這一條線作為初始值,去update一次參數,你得到的就是紅色這一條線。
link |
那你會發現說紅色這一條線跟橙色這一條線其實是有些接近的,至少它知道說波峰應該在這邊,然後這邊有點像是波谷的位置。
link |
我剛才有講說NAML雖然你在訓練這個model的時候,你說在那些training task上,期待你只update一次參數就可以做好,
link |
但實際上在testing的task上,在測試的任務上,你還是可以update很多次參數,所以在測試的任務上,我們可以update多一點參數,比如說update十次。
link |
那這個時候,你得到的這條紫色的線可能又跟橙色的線更接近一點,就用這個example來顯示說model-to-training跟NAML它們是有差別的。
link |
有問題要問嗎?沒有的話,我們就繼續。
link |
也在NAML的原始的paper裡面,也把這個技術用在Omega跟Mini ImageNet上面。
link |
Omega這個codes我們剛才介紹過了,我們說你要決定說你現在fusion類的task有幾個位,也就幾個類別,所以你可以說我要做五個類別的fusion classification,也可以做二十個類別的fusion classification。
link |
那每一個類別有幾個example呢?你可以做one shot,也可以做五個shot,也可以做one shot,也可以做三個shot。
link |
那這邊就把NAML跟其他meta類的方法比一下,那當然NAML performance看起來是最好的,在這個paper裡面。
link |
那Mini ImageNet其實跟Omega的setup還蠻像的,它就說我們從ImageNet的codes裡面挑一些class出來當作training的class,
link |
再挑一些class出來當作validation的class,再挑一些class出來當作testing的class,然後其他的setup就跟Omega一樣,就每一個classsample出一些image。
link |
所以這邊要做的就是five way的classification,也就是說我們現在fusion類的task有五個class,每一個class它有一張圖片或者是五張圖片,但是這些圖片是來自ImageNet的那個codes,所以這個task叫做Mini ImageNet。
link |
那NAML它的表現也是最好的,那這NAML有兩個變形,一個是first-order approximation,另外一個是沒有approximation,那這兩個方法你會發現說它們的表現其實都是差不多的。
link |
那這個first-order approximation是什麼意思呢?我們來看一下。