back to index
Meta Learning – MAML (8/9)
link |
算了,那來告訴你,NAN流實際上是怎麼implement的,就很簡單,實際上是怎麼implement呢?它implement方法就是這樣,你的PHY還是有一個初始值的,你的初始參數PHY有一個初始值的初始值,叫做PHY0,那這個PHY在做train,那接下來你要train這個PHY0嘛,那現在每一個任務就是一筆訓練資料,
link |
我們說我們一般在做訓練的時候,你還是會選mini-batch嘛,對不對?那所以你在做NAN流的時候,你也可以sample一個batch的訓練task出來,當你有一個task-batch,然後來update你的參數。
link |
不過我們這邊就假設你做的是stochastic gradient descent,所以你一次只sample一個training task出來做考慮,你sample一個task出來,我們現在sample出來的是task N,好,那用這個task N去做訓練,那在NAN流裡面,我們只update一次參數,那現在初始參數是PHY0,update一次以後變成setahead N。
link |
好,那現在我們再計算一下setahead N對它的loss function的片尾分,也就是說我們雖然只要update一次參數就可以得到最終最好的model,但我們現在故意update兩次參數,那update出來的第二次參數拿來做什麼呢?
link |
這個第二次參數拿來更新PHY0,所以PHY0怎麼變成PHY1,它的移動的方向就跟第二步的這個gradient算出來的方向是一樣的,那可能大小不一樣,因為你learning rate不太一樣嘛,但是它們的方向是一樣的。
link |
來,再sample出task N,然後task N呢,update一次參數以後會得到setahead N,那這邊呢,我們要update第二次參數,然後把第二次參數算出來的這個叫你update參數的方向,拿去update PHY1,然後變成PHY2。
link |
實際上NNML你可以這樣implement就好。那從這邊呢,我們還可以再比較一下它跟model pre-training有什麼樣不一樣的地方,那剛才我們就精神上講一下NNML跟model pre-training不一樣的地方,接下來這邊講一下實作上有什麼不同。
link |
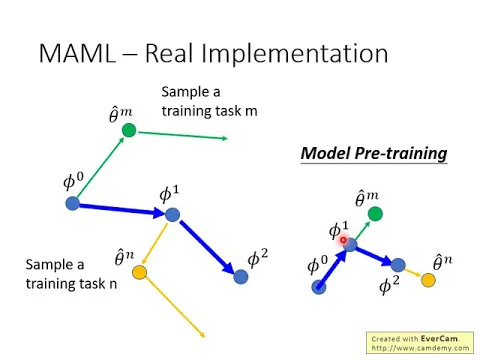
那實作上的不同就是,如果你是用model pre-training的方法來update你的初始的參數,那你是這樣,你有一個PHY0,然後呢,你計算一下,把task N拿出來,計算一下PHY0對task N的偏微分,看起來是走這個方向,你就往這個方向走一下,然後呢,接下來再sample另外一個task,然後呢,你就循著這個PHY1對另外一個task的這個gradient的值呢,再走一下,就是這個樣子。
link |
所以你會發現說,NNML跟model pre-training有不一樣的地方,model pre-training是看看我現在算出來的gradient是怎樣,我現在在每一個task上算出來的gradient是怎樣,就往那個方向移動,而NNML它是先走兩步gradient,它拿第二步的gradient來update你的初始化的參數。
link |
講到這邊,大家有問題要問嗎?沒有的話,我們就繼續。剛才在講這個NNML的時候呢,都把它用在一些好像沒有很實際的task上面,那NNML能不能用在實際的task上面呢?我在文獻上也是有找到一些例子的,雖然說沒有很多,那這邊有一個例子就是把NNML用在machine translation上面,用在機器自動翻譯上面。
link |
它的訓練資料有18個訓練的任務,這18個訓練的任務就是18種不同的語言對英文的翻譯,比如說中文對英文的翻譯是一個任務,德文對英文的翻譯是一個任務,法文對英文的翻譯是一個任務,收集了18種不同的語言對英文的翻譯,這有18個不同的任務。
link |
它也準備了兩個validation的任務,就有兩個不同的語言翻譯成英文,當作兩個不同的validation任務,當然也要準備一些測試的任務。
link |
以下就是一些實驗的結果,其實Romanian是在validation task裡面,所以Romanian轉英文的這個翻譯的任務算是validation任務,finish是在testing set裡面,沒有在訓練,沒有在validation資料裡面,所以說finish是測試任務上面的結果。
link |
在這個圖上,橫軸代表說現在每一個task用的訓練資料量,當然很直覺的,每一個任務的訓練資料量越多,結果當然會是越好的。
link |
上面這個紫色的線,上面這條線,上面這條線,這個meta nnt就是用NAML跑出來的結果,那multi nnt,下面這條線,下面這條線,multi nnt就是做model pre-training的結果。
link |
那你會發現說在所有的task上面,這個NAML的performance都是比model pre-training的performance還要好的,你會發現說尤其當資料少的時候,這個時候meta nnt特別能夠顯示出它比pre-training還要更好。