back to index
Meta Learning - Gradient Descent as LSTM (2/3)
link |
這邊是LSDM的式子,我們把Gradient Descent的式子列出來。
link |
Gradient Descent,我們知道在Gradient Descent裡面每一個time step,你做的事情,
link |
就是把你的原來的參數θt加t減一,減掉你的這個Gradient,乘上一個learning rate,然後得到新的參數θt。
link |
那如果你比較這個式子跟這個式子的話,你會發現說,他們有一些相似的地方,什麼樣相似的地方呢?
link |
你看,這個式子的右邊有ct-1,左邊有ct,它的右邊有θt-1,左邊有θt,那我們何不就把ct-1當作θ來看呢?
link |
所以我們現在把LSDM裡面存在memory cell裡面的值,那些ct-1ct,我們就把它當作是一個network的參數來看待。
link |
假設一個network參數裡面有一萬個,那你就是有一萬個cell,它們裡面存了一萬個value,你有一個有一萬個cell的LSDM,裡面存了一萬個value。
link |
我們現在把LSDM的cell ct-1,ct跟ct-1換成θt跟θt-1,然後接下來呢,怎麼讓下面這個式子變得跟上面這個式子一樣呢?
link |
你可以說,那我現在的input,本來input有一個st跟ht-1,ht-1是來自於三個timestamp,st是外界的input,比如說在我們的作業裡面就是一個詞彙。
link |
那我們現在把st跟ht-1換成gradient,換成gradient成三個符號,然後接下來我們說這個,假設從input到Z的transformation,它就是identity的metric,所以Z我們就說它是negative的gradient。
link |
接下來呢,我們說這個Zf它就永遠都是1,然後Zi它通通都是σ,Zf這個vector裡面每一個dimension都是1,Ziinput gate,本來每一個input gate都不一樣,它是一個vector,每一個vector值都不一樣。
link |
那我現在說,這個vector裡面每一個值都是learning rate,那你會發現說,下面這個式子跟上面這個式子其實就是一模一樣的。
link |
所以你可以說gradient descent這件事,其實就是LSTM的一個簡化版,在這個gradient descent裡面,我們其實也有input gate,也有forget gate,只是input gate跟forget gate的值跟一般的LSTM不一樣,一般的LSTMinput gate、forget gate的值並不是人設的,它是機器自己學出來的。
link |
那在gradient descent裡面,你的input gate跟forget gate的值是人設的,那人的設法就是說,forget gate永遠都不可以忘記,那input gate要input的東西永遠都乘上ε就結束了。
link |
那以前的gradient descent,它的ZF跟ZI是人設的,那現在能不能夠就讓它用learning,讓它用學的定式把它學出來,能不能夠做到這件事呢?
link |
那input的部分,我們剛才說input就假設只有gradient descent,假設就只有這個gradient的值,那在實作上,你其實可以做更多其他的事情,你可以拿更多其他的資訊當作input。
link |
比如說常聽的做法,會把現在這個timestamp,θt-1算出來的loss,也當作θt-1算出來的loss也是一個值,也是一個value,它也會把它當作輸入,來control這個LSTM的input gate跟forget gate的值。
link |
好,那如果我們可以自動的讓機器去學input gate,那意味著什麼?意味著機器可以dynamic的決定learning rate,每一個dimension,在每一個timestamp,它的learning rate都會不一樣,而不是一個固定的數字。
link |
可以自動認ZF有什麼用呢?這個ZF,它做的事情是會把原來的參數縮小,對不對?它會把前一個timestamp算出來的參數進行縮小。
link |
那其實你仔細想想看,在做regularization的時候,我們在上次的錄影也有講過這件事,L2的regularization又叫做weight decay,為什麼它又叫weight decay?
link |
因為你把它的微分的式子拿出來看,你把它update參數的式子拿出來看,會發現說,每一個timestamp,它都會把原來的參數稍微變小,乘上一個decay的位。
link |
那其實今天這個ZF就扮演了像是weight decay一樣的角色,但是我們今天不是直接設定告訴機器說要做多少的weight decay,而是讓機器自動的學出來,它今天要做多少的weight decay。
link |
好,那講到這邊,大家有沒有問題要問呢?好,那如果大家沒有問題要問的話,我們就繼續。
link |
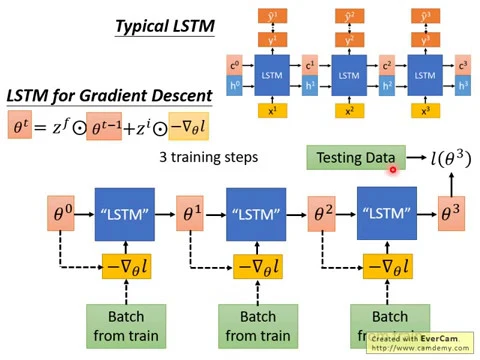
好,那上面這個是一般的LSTM,一般LSTM大家都很熟悉,input x, output c 跟 h,每一個timestamp會output一個y,那你要看y跟你的標準答案有多像,你可能會算一個cross entropy,然後希望每一個timestamp的output都跟標準答案y hat越接近越好,這是一般的LSTM。
link |
那gradient descent的LSTM長什麼樣子呢?它長這樣,你一開始的時候你要一個初始化的參數Z0,有初始化的參數Z0以後,接下來你sample一個batch的data,然後根據那個batch的data,你會算出gradient,你會算出negative的gradient。
link |
把這個negative的gradient丟到一個LSTM裡面去進行運算,那這個LSTM的參數過去是人設好的,現在我們讓它在meta learning的架構下,自動的被應學出來。
link |
那它的update的參數、update的式子就長成這個樣子,這個for gate gate跟input gate的值以前是人設死的,現在的這個LSTM可以自動把它認出來,然後你就output了新的參數Z1,然後Z1在做一樣的事情,你再去sample一個batch的data,現在又有一個新的input。
link |
不過這個input要注意一下,這個input跟這個input它們是不一樣的,對不對?每一個time state,每一次你update參數前你都會算一個gradient,但每一次因為你sample到的data不一樣,你現在的參數的數值已經不一樣,所以你算出來的gradient都會不一樣,所以我就沒有同樣的符號來表示,但每一個time state,input的gradient都是不一樣的。
link |
然後再放到LSTM裡面,再根據for gate gate跟input gateupdate一次參數得到Z2,然後這個process就反覆繼續下去得到下一個time state的參數,假設你今天預設好說我們只做三次參數的update,但實際上你在change a model的時候往往是更多次,現在假設說我們只做三次參數的update。
link |
那接下來你就把最後你得到的參數Z3拿去你的testing data上算一下loss,那你這個loss,最終算出來的loss就是我們要minimize的目標,然後你就會去調這個LSTM參數,用gradient descent去調這個LSTM參數,去minimize最終的輸出loss of Z3,就這樣。
link |
那這邊有幾個要注意的地方,你會發現說這個gradient descent的LSTM跟一般的LSTM還是有一個很大的差別,怎麼樣很大的差別呢?
link |
在一般的LSTM裡面,X跟C是independent的,是完全沒有關係的,對不對?C是外界的輸入,那個不是你的LSTM可以control的,所以你的這個C裡面,你的memory cell裡面存了什麼值,不會影響你在下一個時間點看到的輸入。
link |
但是今天這個gradient descent的LSTM不太一樣,因為你的θ的值會影響你接下來算出的gradient的值,對不對?
link |
gradient值的計算是跟你現在的參數是有關係的,所以我這邊特別畫了一個箭頭,你現在的參數會影響你未來看到的gradient,所以它跟一般的LSTM不一樣。
link |
理論上,你的這個error signal除了走這一條路回來以外,它還會走這一條路,它還可以走這一條路,它還可以通過這個gradient這個block,從這邊update參數。
link |
但是這樣做會很麻煩,跟一般的LSTM就不太一樣了,對不對?一般的LSTM,這個X跟C是沒有關係的,不過這邊的input跟你存在memory的值是有關係的。
link |
不能讓它跟一般的LSTM更像,那你根本就希望你少改一點code的,所以就把這個連結假設它不存在,就這樣。
link |
在文獻上到目前為止都是,就是假設這個θ跟input的關係是不存在的,然後就直接把它當作一般的LSTMtrain下去,硬train下去,就結束了。
link |
那另外在input的地方,我們知道說LSTM的memory裡面的初始值是可以透過訓練直接被認出來的,所以在這個LSTM的架構下,它也可以做到跟memo一樣的事情,它可以把初始的參數,把它可以把θ0也當作是參數,跟著LSTM一起去把它學出來。