back to index
Meta Learning - Gradient Descent as LSTM (3/3)
link |
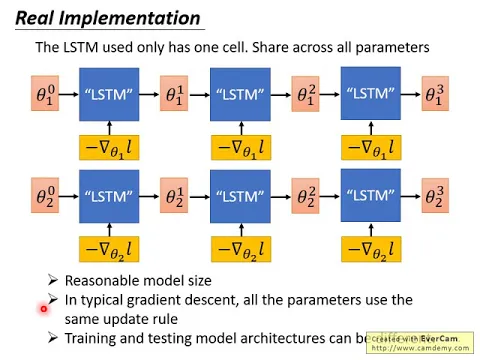
在實作上,講到這邊,有人可能會有一個問題,我們說LSTM裡面的memory cell的值就是你的network的參數,network的參數動輒十萬百萬,你難道要開一個LSTM裡面有十萬百萬的cell嗎?
link |
你一般做LSTM的時候,你有什麼開個1024的cell,你就覺得好像勸很久了,有十萬百萬的cell,難道真的勸得起來嗎?勸不起來。
link |
所以在實作上,也不是這麼做的,在實作上做了一個非常大的簡化。這個非常大的簡化是什麼呢?
link |
這個非常大的簡化是,實際上在實作的時候,我們所認的LSTM其實都只有一個cell而已,它只處理一個參數,然後所有的參數都共用同一個LSTM。
link |
就算你有一百萬個參數,也都用同一個LSTM來處理。也就是說,現在你認好一個LSTM以後,它是直接被用在所有的參數上,雖然這個LSTM它一次只會處理一個參數,但是同樣的LSTM被用在所有的參數上。
link |
那我這邊用下標來代表整個model裡面的某一個參數,所以set R1用的參數,它的處理方式跟set R2用的參數,它的處理方式是一樣的。
link |
那你可能會說,那set R1跟set R2用的處理方式一樣,會不會就算出一樣的值呢?不會,為什麼?
link |
因為例如它們的初始的參數是不一樣的,然後它們的這個gradient算出來也是不一樣的。在初始參數跟gradient不同的情況下,就算你LSTM的參數是一樣的,也就是你update參數的規則是一樣的,你LSTM的參數是一樣的,最終算出來也不會是一樣的。
link |
所以這就是實作上怎麼真的使用這個LSTM gradient descent真正的implementation的方法。那這麼做有什麼好處呢?
link |
第一個就像我剛才說的,你要train一個LSTM裡面有十萬個cell是怎麼可能?當然是train一個cell是比較有可能的方法。
link |
然後再來就是,這樣子的方法其實也不會說非常的不合理,因為你仔細想想,一般我們人設計的gradient descent的種種變形,比如說rnsprop,比如說addend,你想想看那些方法,那些方法其實也都是對不同的參數apply同樣的rule,對不對?
link |
我們並沒有不同的參數用不同的update rule,雖然說今天你在用rnsprop或者是addend的時候,不同的參數在不同的時間點它的learning rate不一樣,但是怎麼決定那個learning rate的規則是一樣的,你並不會不同的參數就給它不同的規則。
link |
所以你今天自己learning的東西,你也是同樣的參數給它同樣的規則,其實也是很合理的,跟原來一般人類的設計是一樣的。
link |
然後再來就是,這樣子設計還有一個好處就是,我們之前講memo的時候,我們說memo其實還是有限制,就是你的training的task跟testing的task它的model的architecture必須要是一樣的。
link |
你不是說我train是CNN,我test的是RNN,這樣是行不通的memo,做不了這種事。但是如果是這樣子的implementation,所有的參數都用同一個LSTM來update,其實你training跟testing的model就可以是不一樣的。
link |
這邊就是文件上的一個實驗結果,這是做在fuelshark learning的task上,上週就有講過,通常meha learning往往都搭配fuelshark learning一起使用。
link |
橫軸是什麼?橫軸就是update的次數,每次training的時候會update十次。左邊是forget gate值的變化,這個是從第一層一直到第五層,這個LSTM的forget gate值的變化。
link |
你會發現說不同的紅色的線就是不同的task裡面forget gate值的變化,你會發現說現在forget gate的值幾乎都是固定的,幾乎都保持在接近1的位置。
link |
所以我們自動有知道說,一般的LSTM,不是一般的LSTM,一般的quotient descent,就是set rt-1直接乘上1,就不做任何的decay,只做一點點小小的decay就得到set rt。所以LSTM有自動認到這件事,它知道說,set rt-1沒事,你就不要隨便給它decay,那就是很重要的資訊,不應該隨便把它忘掉。
link |
好,那這個是input gate,input gate的變化長成像是這個樣子,那你會發現說,這有點複雜,我們其實不太知道說為什麼LSTM的input gate的變化是這個樣子。
link |
那我們至少可以知道說,它有學到一些特別的東西,它不是單純說每一個time state的input gate的值都是一樣,它不是一個固定的learning rate,它的learning rate是dynamic的變化的。
link |
好,那只有剛才的架構還不夠,我們可以更進一步想說,你想想看,我們現在人們所設計的常用的那些quotient descent的方法,我們在決定我們的learning rate的時候,不是只看現在這個time state的quotient,我們還會考慮過去的time state的quotient。
link |
舉例來說,這個都是之前的錄影有的投影片啦,我只是把之前的投影片截下來給大家複習一下,我就不細講這個投影片的內容,就給你乘快複習一下。
link |
那initialized part,我們會需要把過去的gradient乘上取平方以後加總,然後momentum,我們會需要記得過去的gradient才能夠算出現在的momentum。
link |
但在剛才的架構裡面,我們好像沒有讓machine去記過去的gradient,所以我們可以再做更進一步的延伸,剛才我們只是直接把gradient丟到LSTM裡面,然後讓machine決定它要怎麼算learning rate,怎麼做wake decay。
link |
我們現在再加上另外一個LSTM,我們先把gradient丟到這個LSTM裡面,再讓這個LSTM吐出一個什麼東西去update我們的參數。
link |
那中間這個下面這個綠色的LSTM要做的事情是什麼呢?也許它做的事情就是把過去的gradient累加起來,它就可以做到有點像是momentum可以做到的事情。
link |
你可以想像說,這個LSTM也許它會把過去input的gradient統統都累加起來,它就可以做類似這個momentum可以做到的事情。
link |
這個圖上的方法有點是我的幻想,就是說,在learning by gradient descent by gradient descent那篇,它是有下面這個LSTM,但它上面這邊不是用learning,它上面那邊就是直接用一般的gradient descent,它沒有上面這個LSTM。
link |
它這邊就是用一個簡單的規則,直接把這個output的東西跟SELA0加起來而已。然後另外一篇,它是有上面,但是沒有下面這樣。
link |
但是我相信說,兩個合起來做應該也是還蠻合理的,所以我相信這個完全體應該是長這個樣子就是了。
link |
這個是learning by gradient descent by gradient descent那篇的實驗結果,首先它的第一個實驗是做在一個toy example上面,在這個toy example上面當然它可以製造一大堆訓練的任務,然後測試在測試的任務上。
link |
然後它發現說LSTM,我們用LSTM來當作gradient,那很強,很強,比現在人設計的其他什麼add-on、add-on、add-on,都還要強,它的下降速度都還要更快,也都可以收斂到更低的高度。
link |
然後接下來它就把這個技術用在at least上面,不過用在at least上面有點cheating,因為它training跟testing都是at least的。
link |
我們說你做meta learning的時候,你training的test應該跟testing的test都應該是不同的任務,所以如果它在這上面的這個實驗,它說它的training跟testing都是at least的,然後它的方法,也就是陳設這一條線,結果特別好,其實也沒有特別讓人意外。
link |
當然Pamela作者也注意到這件事,所以她說這個實驗只是cheating,接下來我們來做真正的meta learning,真正的meta learning,training跟testing必須要是不一樣的,所以她說training跟testing一樣data set是at least的,但它training跟testing的時候,它的network的架構是不一樣的。
link |
它training的時候,我記得它training的network其實也沒有很大,它network好像是一層然後只有二十個neuron,現在train的時候一層二十個neuron,testing的時候一層四十個neuron,看看會怎樣,沒問題,還是做得起來。
link |
我們剛才有講說這種用LCM當歸顛design的方法,有辦法跨model,training跟testing的model它也是不一樣的,所以它test的時候,它apply在四十個neuron的network上面,結果比其他人手設計出來的這個歸顛design的方法都還要好。
link |
現在它試一下,train的時候是一層,test的時候是兩層,也行,也做得起來,但接下來它試說training的時候是sigmoid,testing的時候是relu,就做不起來,整個壞掉。
link |
所以training跟testing的equivalent function不一樣的時候,現在這個LCM的方法沒有辦法跨model做apply。
link |
就是這樣,就算是同一個task,你每次input的data的順序也是會不太一樣的,所以其實它在paper裡面也有講說,就算是它都用at least來train,在上面這個實驗裡面,每次的training跟testing還是有不同的,不同在哪裡,input data的順序不一樣,sample到fetch是不一樣的,所以還是有些不一樣的。