back to index
Meta Learning – Metric-based (2/3)
link |
直觀的解釋,怎麼直觀的解釋Science Mix Network做的事情呢?你可以說,Science Mix Network其實就是一個單純的Binary Translocation Problem,你不需要把它當作Meta Learning來看待,你可以說它就是一個單純的Binary Translocation Problem。
link |
這個Binary Translocation Problem,它輸入的就是兩張圖片,輸出要問的就是,這兩張圖片一樣嗎?還是不一樣?也就是說,你現在每一個Training的Task,其實就是Training的時候的一筆資料,每一筆資料裡面都有兩張圖片,都有兩張圖片。
link |
他們的標註就是,這兩張圖片是一樣的嗎?還是不一樣?一樣就算是一類,不一樣就算是另一類。所以它是二元分類的問題,直接Train一個Network,吃兩張人臉,Output就是他們是一樣還是不一樣,Apply在測試資料上就結束了。
link |
所以Science Mixed Network,我們剛才要講的這個Face Verification的問題,其實可以把它看成是一個Binary Translocation的問題,就不見得要從Meta Learning的框架來解釋它,你可以從另外一個角度來解釋它,這樣其實是比從Meta Learning來講解是更容易理解一點的。
link |
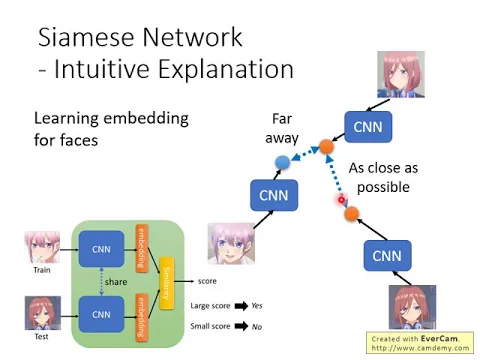
Science Mixed Network它內部的設計有什麼意義呢?它裡面要做的事情其實就是,用這個CNN把所有的人臉都投影到一個空間上,在這個空間上,同一個人的臉就會比較接近,不同人的臉就會離比較遠。
link |
因為你知道說,其實就算是同一個人的臉,他今天如果兩張臉你在計算相似度的時候,你是在他們的Pixel上面計算相似度。同一個人的臉,他朝左看、朝右看,對機器來說,Pixel上的差異非常大。
link |
所以我們希望把所有的人臉都投影到一個空間上,在這個空間上,只要是同一個人臉,不管他是朝左看、朝右看,實際上的Pixel差異有多大,但在這個CNN的Output這個空間上,看起來是非常接近的。
link |
我們在訓練的時候,我們訓練的目標就是,我們現在把每一張臉都透過這個CNN投影到一個空間中,投影到一個空間中,投影到一個空間中。如果是同一個人,我們就希望他在這個空間中距離被拉得越近越好。如果是不同人,我們就希望他被拉得越遠越好。
link |
有人可能會問說,認這種embedding的方法,把圖片做降維的方法,我們在上課錄影裡面不是也講過很多其他的方法了嗎?比如說PCA,比如說Autoencoder。
link |
如果我們直接在這邊apply Autoencoder,跟用Semis Network會有什麼樣的差別呢?但是你想想看,我們在train Autoencoder的時候,我們並不知道我們要解的任務是什麼。對Autoencoder來說,它就是要保留這張圖片裡面大多數的資訊,但它不知道什麼樣的資訊是重要的,什麼樣的資訊是不重要的。
link |
在這個例子裡面,如果你看這張一花的圖跟這張三九的圖,它們的背景都是淺的灰色,而這張圖的背景是深的灰色。
link |
如果你用Autoencoder,Autoencoder是要保留所有的資訊,所以對Autoencoder來說,這兩張圖搞不好還蠻像的,因為它們的背景是一樣的。但是在Semis Network裡面,Network就會學到說,這些CNN就會學到說,因為你要求要我把這兩張圖片拉遠、這兩張圖片拉近,所以我就要學到說,也許頭髮的顏色很重要,但是背景的顏色就不重要,就忽視它。
link |
這個CNN可能就可以學到說,我們要Encode頭髮的顏色,但是我們要忽略背景的顏色。這就是如果你用Semis Network認出來的Embedding跟一般的隨便用Autoencoder認出來的Embedding會有什麼樣的不同。
link |
怎麼計算在這個空間中,怎麼計算兩個點之間的距離呢?這個就有很多不同的方法,不同的方法之間也許會給你很不一樣的結果,那我們這邊就不細講下去,我們就列一些Reference給大家參考,有各種不同的計算,兩個Embedding的Output有多相近的方法。
link |
舉剛才的例子裡面,我們做的都是One-Shot Learning,就是給你一張Training的Data,如果你在做Few-Shot Learning的時候,就是你給他一張你要Verify目標的臉,再給他一張不是Verify目標的臉,再給他Testing Data,給他兩張訓練資料,往往Performance會更好。
link |
這個就叫做Triple Loss,本來只有兩個東西叫做Input,但是你可以Input三個東西,你的Training Data裡面可以有兩張圖片,一張是Positive Example,就是我們現在identify那個對象,另外一張是隨機一個路人,那這樣結果其實會做得更好。