back to index
Meta Learning – Metric-based (3/3)
link |
那剛才舉的例子裡面呢,我們的訓練資料都只有一張,我們要做的事情就是verification,接下來要回答的就是yes or no。
link |
那如果現在你要做的是identification,也就是說它是一個分類的問題,它不是一個單純回答yes or no的問題,那怎麼辦呢?
link |
舉例來說,假設我們現在要把同樣的概念用在five-way one-shot的內容上,five-way one-shot的task上要怎麼做呢?
link |
那麼上週已經講過five-way one-shot是什麼意思,我們上週有講說five-way one-shot的意思就是,我們有五個class,但是每一個class我們只有一個example,這叫five-way one-shot。
link |
好,那現在呢,如果要做five-way one-shot的話,那你要有五個class,假設五個class,就是那個五等分的五姐妹,每個人都是一個class,她們分別是一花二奶三酒四夜都約這樣子。
link |
這些人物是出自那個五等分的花架,我不知道大家有沒有看過這個,需要我解釋一下這個是什麼嗎?我簡短的解釋一下這個故事,這個故事是這樣子的,就是中野家有五姐妹,她們是五胞胎,然後她們都喜歡她們的家教老師,就是風太郎這樣子。
link |
然後呢,風太郎小時候呢,曾經他的初戀情人是五姐妹的其中一個,但是他不知道是哪一個,因為我講過說五姐妹長得是一模一樣的,所以他只知道說他的初戀情人是五姐妹的其中一個人,但是那是小時候的事了,他長大以後已經不知道是哪一個了。
link |
所以這個故事就是找出那個……而且小時候他沒有真名,他用他的名字叫做林奈,兩個人就是要找出林奈的故事,跟未戀的劇情有點像啦,活著裡面有五個人,所以就特別容易有黨爭,就大家會各擁其主。
link |
就好像說有很多人研究紅樓夢就是紅學,很多人現在在研究五等分的花架就是武學,就是要預測說誰會是最後的真命天女。就網路上有很多武學家,寫數十萬字的論文來論證說,他們覺得最後獲勝的會是誰這樣子。
link |
但是我其實想到一個方法可以解決最後的問題,因為其實不管最後風太郎跟誰在一起,最後都會有人生氣嘛,所以最後一個大圓滿的結局就是,並不是我全都要中搭檔,我不是這個意思,我的意思是說,我相信林奈其實是有輪迴演的,就跟六道配合一樣,他其實操縱了五具屍體。
link |
最後風太郎就是要發現說,這個本體不在其中啦,然後最後就找到林奈,就結束了,可喜可賀,就這樣,好,就是這樣。
link |
好,我講完了,反正這個就是五等分的花架,裡面的五個角色,每個角色就是一個class,現在每個角色就只有一張圖片,那Network就把這五張圖片都給它吃下去,測試的時候給它一張圖片,希望它就可以自動判斷說,這張圖片是剛才給的五個類別,每個類別只給一張圖片的哪一個。
link |
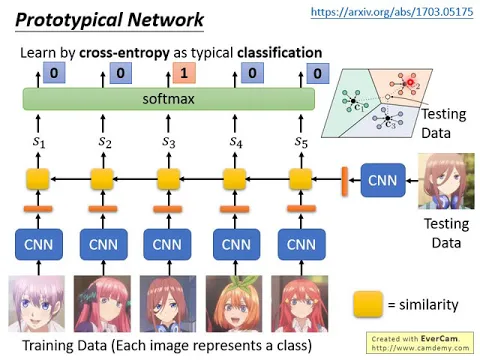
實際上Network的架構要怎麼設計呢?在文獻上就有很多的做法,舉例來說,一個經典的做法叫做Prototypical的Network。
link |
Prototypical的Network做的事情就是,我們現在有一個CNN,跟SanDisk Network其實非常非常像,只是現在從input一張training data,extend到input好多張training data。
link |
我們用這個CNN把training的image,每一個image都變成一個embedding的vector,然後testing的image也變成embedding的vector。
link |
接下來我們計算testing的image的這個vector,跟訓練的圖片的每個vector的相似度,我們計算相似度,我們用黃色的bug來代表計算相似度這件事。
link |
這個圖畫得有點難畫啦,所以這個不是一個RNN的意思,這個是說,我們拿這個vector跟一花算個相似度,拿這個vector跟二奶算個相似度,跟三酒算個相似度,跟四葉算個相似度,跟五月算個相似度等等。
link |
所以我們就得到五個相似度的值,S1到S2。接下來你可以比如說取個softmax,然後你在train的時候,你的loss function就跟一般的分類的問題一樣。
link |
你想想看,一般你在做分類的問題的時候,假設是五個class,你就通過softmax要output五個value,接下來做cross entropy,minimize cross entropy。
link |
那這邊做的事情是一模一樣的,你現在也有五個value了,通過softmax,你一樣做cross entropy。
link |
它的reference,它的target就是,假設這張圖片它是三酒,所以它是屬於第三個class,那就是第三個class的目標是1,其他都是0。
link |
你就計算你softmax layer的output跟你的reference的這個target之間的cross entropy,然後在train的時候,你要去minimize它,這個就是prototypical的network。
link |
在我們這個舉的例子裡面,我們都假設說它是one-shot的,那如果是few-shot,就是你的每一個class不只一張圖片,那也沒什麼問題。
link |
在prototypical network裡面,它做的事情就是,假設你有三個class,每個class有五張圖片,那你就把五張圖片embedding平均起來就結束了。
link |
今天進來一個testing的資料,你就看說它跟哪一個圖片的代表、哪一個圖片的平均、哪一個class的embedding平均最像,那就算是哪一個class。
link |
這個方法也非常直覺,它的道理就跟ScienceMix Network差不多,你就是希望說,今天如果這個testing的data它算是class 2,那它就跟class 2的那些image的平均越接近越好,
link |
然後跟其他class的平均、跟其他class的代表遠離,那就可以了,所以它是很直覺的,這個叫做prototypical network。
link |
還有另外一個很類似的做法,叫做matching network,那matching network跟prototypical network最不一樣的地方是,之前我們是training data裡面的每一張圖片都分開處理。
link |
他說,也許training data裡面的每一張圖片互相之間也是有關係的,所以我們就直接用一個bi-directional LSTM來處理。
link |
我們把training data這些圖片通過bi-directional LSTM,每張圖片仍然會得到一個embedding,接下來其他的做法就跟prototypical network是一樣的。
link |
事實上,在歷史的演進上是,先有matching network,才有prototypical network,是先propose matching network,後來才有人propose了prototypical network。
link |
那prototypical network,你可能想說,哎,prototypical network比較簡單啊,它怎麼是後提出來的?
link |
在prototypical network裡面有提到matching network那篇paper,首先prototypical network performance比matching network還要好,那prototypical network那篇paper裡面也有提到說,他覺得在這邊用bi-directional LSTM好像不是很有道理。
link |
那如果你這邊是用bi-directional LSTM,那是不是現在如果input的訓練資料,我們把這個12奶跟39的順序對調,那你network output難道就不一樣了嗎?這樣不會很奇怪嗎?
link |
這個matching network還有一個不一樣的地方是,它在計算出這些分數以後,其實有通過一個multiple hub的process,然後才得到最終的output。
link |
那這個multiple hub的process其實在memory network裡面有用到,那這個matching network裡面的process跟memory network裡面用的process其實還蠻類似的。
link |
不過因為這門課我們沒有講memory network,所以這個部分講起來大家應該是很難懂的,所以我們就略過,你有興趣的話再自己去看論文就好了。
link |
還有別的,比如說relation network,relation network跟剛才的network的道理也都是一樣的,就是input訓練資料、input測試資料,然後接下來就當作一個分類的問題來做,看這一張測試資料是跟哪一個訓練的資料是同一類,是屬於哪一個類別,比如說這是一隻狗,所以它應該是屬於第四類。
link |
只是relation network跟剛才的matching network等等,它們又有一個不一樣的地方,它不一樣在哪裡呢?relation network是這樣做的,它說我們先把訓練資料裡面的每一張圖片跟測試資料通通抽出它的embedding,訓練資料的每一張圖片,五張圖片有五個embedding,測試資料這個圖片,把它的embedding放在訓練資料圖片的embedding的後面。
link |
本來我們是直接算這個vector跟這個vector的相似度,matching network跟prototypical network裡面都是直接算相似度,relation network說我們的相似度不是人定的,我們的相似度是用另外一個network算出來的,有另外一個network,它把這個vector吃進去,它用它自己的方法來算相似度,說這兩個vector有多像,這個就是relation network。
link |
不算相似度,怎麼抽embedding,是一起被學出來的。
link |
我們知道說在future learning裡面常常遇到的問題就是訓練資料很少,所以怎麼辦呢?我們也可以讓機器自己去幻想出一些訓練資料。你知道我們人就是有想像的能力,所以雖然只給你看一張三角的臉,它是面無表情的,但是也許你可以想像它害羞的樣子,或者是它生氣的樣子,或者是它賣萌的樣子等等。
link |
所以你看到一個人的人臉,你可以想像出他的其他的面向,那我們能不能讓機器也做一樣的事情呢?在文獻上確實有這樣的做法。
link |
原來我們one shot learning的時候,就是每一個class就是一張圖片,現在我們去learn一個generator這樣子,我們雖然還沒有講過怎麼做generation這件事情,但是你想像說就是有一些技術,就是可以learn一個generator去生東西,去產生出東西來。
link |
所以我們現在learn一個generator,它就是吃一張圖片進來,它就產生一大堆它覺得相關的圖片。但是這個generator怎麼learn出來呢?這個generator就像是人的想像力一樣。
link |
那這個generator怎麼learn出來呢?它是跟後面這個network一起learn的,也就是說generator,我們可以先設定好說,這個generator就是你給它一張圖片,它要另外生三張。就你給它一個人的臉,它可能就會想像出那個人生氣的樣子、害羞的樣子跟賣萌的樣子,它就會想像出那個人的三種不同的樣子,然後把想像出來的臉丟到network裡面,再做接下來的訓練。
link |
那真正在做訓練的時候,這個network跟這個generator是jointly一起訓練的,這個就是future learning for imaginary data的意思。
link |
好,那我們今天就講到這邊,因為等一下十點四十我們還有很多其他的活動,今天要講一下那個final的project,所以我們就在這邊休息大概五分鐘,我們四十分的時候再回來。