back to index
More about Auto-encoder (2/4)
link |
其實如果你今天你的data它是sequential的,它是有順序性的,在做training open encoder的時候,你要training open encoder的時候,你是自己當作輸入,然後要預測自己。
link |
那如果你今天你的資料它是一個有序列性的資料,舉例來說你的資料是一篇文章,文章裡面有一堆句子,這個句子是按照某種順序做排列的,這個時候你就可以做更多更多不同的變化。
link |
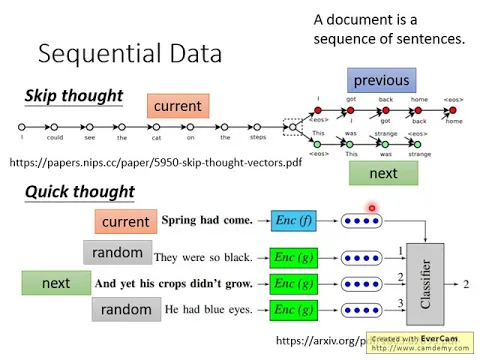
舉例來說除了train一個open encoder輸入自己,預測自己以外,你可以train一個model,它是輸入一個句子,但是它預測的是前一個句子跟下一個句子,這個概念叫做skip zone。
link |
這個概念其實跟train word embedding是非常像的,我們上課錄音裡面有講過train word embedding這件事情。train word embedding的時候我們說,如果某一個詞彙它的上下文都很像,那這個詞彙,比如兩個不同的詞彙,它們的上下文都很像,那這兩個不同的詞彙,它們的語意應該是接近的。
link |
那在skip zone它的概念是一樣的,只是它擴展到句子的層級,也就是說兩個不同的句子,如果它們的上下文都很像,那這兩個不同的句子,它們應該有同樣的意思。
link |
舉例來說,有人問說這個東西要多少錢,然後另外一個人回答說要十塊,有一個人問說這個東西有多貴,那另外一個人也回答要十塊,那有多貴跟要多少錢,今天如果你要skip zone這個model,skip zone就可以自動知道說有多貴跟多少錢,它們後面接的答案都是一樣的,那這兩個問題,它們的語意,它們的意思應該是一樣的。
link |
那這個就是skip zone的概念,然後來skip zone又有另外一個延伸的想法叫做quick zone,那quick zone從它的名字就知道說它就是訓練比較快,所以叫做quick zone。
link |
那skip zone它的訓練往往是比較花時間的,因為你不只要訓練encoder,你還要訓練decoder,然後你要叫機器去predict未來的句子,你要叫機器去產生前一句跟後一句,那這個effort是很大的。
link |
那在quick zone裡面,我們就只認encoder,就不認decoder了,那quick zone的想法是說,我們現在把每一個句子都丟到encoder裡面,每一個句子都丟到encoder裡面,然後會跑出一個embedding的vector。
link |
那我們接下來就不訓練decoder了,我們說,那不訓練decoder要怎麼訓練這個encoder呢?今天的訓練的概念就是說,每一個句子要跟它的下一個句子,它們output的這個embedding的vector越接近越好。
link |
那如果今天是隨機的句子,隨便不知道從哪裡找來的句子,它們現在這個句子output的這個embedding,距離就要越遠越好。
link |
實際上在那篇quick zone那篇文章裡面,它是講得更general,它說,今天什麼叫做一個好的embedding?好的embedding就是,我現在認一個classifier,然後這個classifier是它吃某一個句子的embedding當作輸入,然後它再吃一個正確的句子,不是正確的句子,它再吃現在我們考慮的這個句子的下一個句子的embedding當作輸入。
link |
它再隨機sample幾個句子,得到它們的embedding當作輸入。你把現在我們考慮的句子跟它下一個句子跟隨機sample的句子的embedding當作輸入,然後這個classifier可以正確的判斷說哪一個句子是下一個句子。
link |
然後這個classifier跟這個encoder,它們是共同訓練的。然後這樣子訓練下去,訓練出來的encoder就是好的encoder。不過後來在實作的時候,它的classifier其實做的事情是非常簡單的。
link |
它的classifier做的事情就是把現在的句子,它的encoder的output跟其他句子的encoder的output算inner product,inner product越大就代表classifier覺得它是下一個句子的機率越高。
link |
所以實際上做的事情就是計算current vector跟current sentence它的embedding vector跟next sentence的embedding vector,希望它們越接近越好。然後今天現在這個句子的embedding vector跟你隨機sample一個句子的embedding vector,它們的距離要越遠越好。
link |
那這個就是quicksort的概念,它拿掉了decoder,所以訓練起來又更快一點。那這個quicksort類似的概念性,這個quicksort的時候,你一定要隨機sample一些句子。
link |
因為假設你沒有隨機sample一些句子,你只說現在我們這個句子的embedding要跟下一個句子的embedding越接近越好,那實際上model訓練出來的結果就是所有句子都給它一模一樣的embedding,那就跟下一個句子的embedding越像越好啦,就很像啦。
link |
那為了要避免這個問題,所以你要設另外一個條件是說,不只跟下一個句子的embedding越像越好,你還要跟隨機不知道從哪裡找來的句子的embedding越不像越好。
link |
在其他地方也出現過,比如說有另外一個技術叫做contrastive predictive coding,它叫CPC,這邊我們就不用細講,光看這個圖,你大概就可以猜到說它要做的事情是什麼。
link |
而這個CPC它就是要train一個encoder,這個encoder在這個例子裡面它的輸入是一段聲音訊號,我相信在別的application上面應該也可以做很類似的事情。
link |
你輸入一段聲音訊號,這個聲音訊號的每一小段,你都要用這個encoder得到它的embedding,這邊用Z來表示。
link |
那訓練的時候怎麼得到這個embedding呢?你訓練的目標就是希望你的encoder,output出來的這個embedding可以拿去預測接下來同一個encoder會output的embedding,就跟那個Quixel的概念是很像的。