back to index
More about Auto-encoder (3/4)
link |
那麼進入下一個主題,我們怎麼讓encoder的output更容易被解釋。第一個我們要講的概念呢,叫做feature的disentangle。
link |
disentangle是什麼意思呢?disentangle這個字眼翻譯成中文就是解開的意思,你本來有一大堆東西糾纏在一起,你想把它解開,這個叫做disentangle。
link |
那我一般在訓練這個autoencoder的時候,我們知道說,我們要去做encoder那些object,它可能是影像,它可能是聲音,它可能是一段文字。
link |
這些我們要被encoder的object裡面,它包含了各式各樣複雜的資訊,比如說一段聲音裡面,它不是只有文字的資訊,不是只有那個語音內容的資訊,
link |
它還包含了什麼資訊?它還包含了舉例來說說話人的聲音的特質,還有比如說環境裡面有什麼樣的噪音等等。
link |
所以一段聲音訊號裡面,它是包含了各種不同面向的資訊的。那一段文字也是一樣,一段文字裡面,它有語意的資訊,它有文法的資訊。
link |
徽章圖片裡面,它有這張圖片的風格的資訊,它裡面有什麼樣的物件的資訊。所以一個encoder的輸入,它包含了各式的資訊,但是我們就是拿一個vector來表示我們輸入的那個object。
link |
所以在這個vector裡面,顯然某一些維度,假設以語音為例的話,那input的聲音訊號通過encoder要用decoder解回來,那這個向量裡面,它可能包含了這個聲音它的內容的資訊,它裡面講了什麼話,還有它的語者的資訊,說話的人是男生是女生,是小孩還是老人等等。
link |
但是我們不知道說這個向量裡面,哪些維度是說話的人的資訊,是語者的資訊,哪些維度是聲音訊號內容的資訊。
link |
那我們現在要做的事情,就是我們希望encoder可以自動告訴我們說,哪些維度就是語者的資訊,哪些維度就是內容的資訊。
link |
所以怎麼做呢?我們期待做到的事情是,encoder輸出一個vector以後,這個vector假設本來是兩百維,那舉例來說,可能前一百維代表的就是內容的資訊,代表就是這句話裡面說了什麼東西的資訊,然後第一百零一到兩百維代表的就是語者的資訊。
link |
這樣我們就可以輕易地知道說,這個向量裡面哪些部分是語者的資訊,哪些部分是內容的資訊。或者是說這個想法也可以有一個變形,但他們意思是差不多的,就是我們有兩個encoder,一個encoder專門抽出內容的資訊,另外一個encoder專門抽出語者的資訊。
link |
把內容的資訊跟語者的資訊拼在一起丟給encoder,他才能還原原來的訊號。不過這邊是簡化了這個問題,聲音訊號裡面可能除了內容的資訊、除了語者的資訊以外還有其他的資訊,比如說雜訊的資訊、背景噪音的資訊、麥克風的資訊等等。
link |
我們這邊就是簡化這個問題,假設只有語者跟內容這兩個資訊。那你可能會問說,這樣子的東西有什麼用呢?當然它的技術不是只能用在語音上,雖然我們今天是拿語音做例子,但是你完全可以用在影像上、用在文字上。
link |
那這個在語音上有什麼樣的應用呢?舉例來說,假設你今天訓練一個encoder,它可以把聲音內容的資訊跟語者的資訊切開。所以你今天把某一個女生說How are you丟到這個encoder裡面,
link |
它就會告訴你說,How are you就放在綠色的這個項量裡面,然後這個女生的資訊就放在黃色的項量裡面。你那個男生說Hello,Hello的資訊就放在綠色的項量裡面,男生的資訊就放在黃色的項量裡面。
link |
你可以把How are you的項量跟男生的項量結合起來,丟到encoder裡面,這樣你就可以用這個男生的聲音說How are you。
link |
那你做到的事情是什麼呢?你就可以做一個領結變聲器。那有可能會問說,我又不是柯南,為什麼會需要一個領結變聲器呢?
link |
其實變聲這個東西是非常有用的,因為我們知道同一個句子,不同人說出來,效果就不太一樣。
link |
舉例來說,我們說這門課就是要猝不及防地說服大家念博班這樣子,但是你的教授跟你說,你要不要念個博班的時候,通常你根本就不想理你的老師,等於你要不要簽下去的時候,通常你都是不願意的。
link |
但是如果我今天把我的聲音轉成新人結衣的聲音,新人結衣叫你要不要簽下去啊,那你可能就簽下去了。所以這個word conversion是非常有用的,把人的聲音變聲是非常有用的。
link |
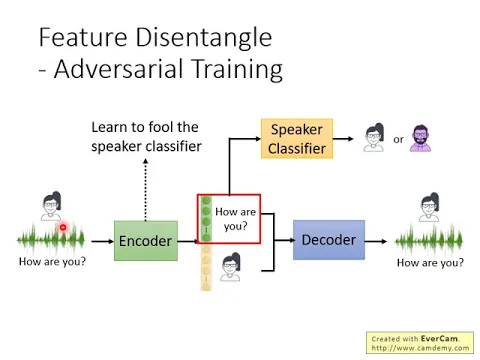
那要怎麼做呢?那這邊就是提供幾個可能的做法。第一個可能的做法是用game的概念,用adversarial training的概念。怎麼做呢?我們今天到底要怎麼訓練一個encoder,讓這個encoder他的前一百維就是語者的資訊,他的前一百維就是聲音內容的資訊,後一百維就是語者的資訊呢?
link |
那我們訓練一個語者的classifier,我們訓練一個classifier,這個classifier它會把encoder output的這個向量吃進去,接下來它做的事情就是根據這個向量判斷說,現在這個向量它來源的那個語者到底是哪一個呢?
link |
你訓練一個語者的classifier,根據這個向量判斷原來的聲音訊號是來自於哪個語者。然後呢,你的encoder做的事情是去想辦法騙過這個語者的classifier,它想辦法讓這個語者的classifier的正確率越低越好,最好是它通通都猜錯,它猜出來的結果就跟隨機的一樣。
link |
如果今天這個encoder成功騙過了這個speaker classifier,然後你今天給這個speaker classifier看的embedding是encoder output的前一百維,那encoder就會學到說,現在有關speaker的任何資訊,有關語者的任何資訊,我們都不可以放在前一百維裡面,我們通常會把它藏在後一百維。
link |
因為如果你把speaker的資訊放在前一百維,那這個speaker classifier就會可以從這個embedding判斷說它是哪一個speaker。
link |
那encoder為了要騙過這個speaker classifier,它就會把所有語者的資訊放在後一百維,那前一百維可能就只剩下content,只剩下內容的資訊。
link |
實際上在做訓練的時候,你通常會用這個game的scenario來訓練這個speaker classifier,也就是這個speaker classifier就是一個discriminator,然後你的encoder就是generator,
link |
然後你的speaker classifier跟encoder它們是iterative trend的,就是你先trend speaker classifier,然後再trendencoder,然後再trendspeaker classifier,再trendencoder,它們是交替trend。
link |
代表不同資訊embedding是用不同的encoder輸出出來的,我們其實也可以用更簡潔的方式,就是直接去改encoder的架構,就抹掉我們不希望它出現的資訊。
link |
這個部分我們就不深入細講,但是你可以自己想想看說,我們有沒有辦法設計network的架構,去設計出來以後,它就把我們不要的資訊濾掉,只包含我們要的資訊。
link |
舉例來說,有一種layer叫做instance normalization layer,因為我們這堂課還沒有講過normalization,比如說bench norm,layer norm之類的,所以我們就不跟大家解釋instance normalization是什麼。
link |
那就想成說,我們在network裡面,我們為network的架構做一些特別的設計,裡面設計了一種特別的layer,這種layer它可以抹掉global的資訊,可以抹掉整個object的每一個小部分都有的資訊。
link |
那在語音訊號裡面,一整個句子裡面,global的資訊,一整個句子裡面每一個片段都有的資訊,可能就是說這句話的人他的資訊。所以你今天把一整個句子通過一個encoder以後,它就會抹掉了語者的資訊,可能只保留了跟內容有關的資訊。
link |
所以從這個encoder1假設我們加了一個instance normalization的話,那它的輸出就只剩下內容的資訊而不包含語者的資訊,所以這是一個可能的作法。
link |
但是光這麼做可能是不夠的,因為也許雖然說我們encoder1它的輸出沒有包含任何語者的資訊,但是並不代表encoder2它就不會包含內容的資訊。
link |
舉例來說,一個可能的設計是在decoder上加一個特別的layer,這個特別的layer叫做adaptive instance normalization。
link |
我們原來是說把兩個encoder的輸出就直接接在一起丟給decoder,然後讓decoder去還原聲音訊號。
link |
但是我們現在這個decoder在吃encoder1跟encoder2的輸出的時候,他們是用不同的方法來對待它的,encoder1的資訊就直接吃進去。
link |
但是encoder2的資訊,這個decoder說我們把它加在adaptive instance normalization這個layer裡面,那adaptive instance normalization它會調整輸出的global information。
link |
如果adaptive instance layer那個layer一變的話,它是整個句子每一個片段都會做改變,而不是只有改一點小地方,它是整個句子都會做改變。
link |
所以現在encoder2的輸出,它會改變它的句子,它輸出的這個向量會改變這整個句子,所以它就不能夠在這個輸出的向量裡面放語音內容的資訊。
link |
因為你會變成說語音內容的資訊會改變一整個句子,這樣就不對了,它也會放的是語者的資訊,因為語者的資訊是決定了整個句子每一個部分的內容,它是一個global的資訊。
link |
所以你會把encoder2的輸出接到adaptive instance normalization裡面,然後discoder它把encoder1當作一般的輸入,encoder2的輸出做特別的處理,然後還原聲音訊號。
link |
你也可以用這種設計內部的方法把不同的資訊分開,總之這邊就是提供給大家兩個不同的想法,而沒有講細節。
link |
這個都是上代研究的結果,還有很多東西是你可以嘗試的,你永遠可以去想像說,在你今天想要做disentangle的問題裡面,你怎麼做network架構的設計,去抹掉或保留你想要抹掉或保留的資訊。
link |
這個是用adversarial training做的結果,這個是周如潔同學做的,就是可以把一個人的聲音轉成另外一個人的聲音,現在要被轉的那個對象就是我的聲音。
link |
我要強調一下,機器在訓練的時候,它其實從來沒有聽過我的聲音,而且它甚至從來沒有聽過中文,訓練的時候只給它英文的資料而已,那我們要轉換的最硬的目標,是隨便一個外國女性的聲音,它從來沒有說過中文。
link |
它從來沒有說過中文,現在機器要想像,如果這個外國女性勉強它說一句中文的話,聽起來像是什麼樣子?聽起來像是這樣。
link |
主持人說,它是有口音的,人家講說它是外國人的,它說中文它本來就應該是要有口音的。然後我試著唱一首歌,聽起來像是這樣子。
link |
主持人說,它是有口音的,人家講說它是外國人的,它說中文它本來就應該是要有口音的。然後我試著唱一首歌,聽起來像是這樣子。
link |
主持人說,它是有口音的,人家講說它是外國人的,它說中文它本來就應該是要有口音的。然後我試著唱一首歌,聽起來像是這樣子。
link |
好,所以歌詞是對的。所以這個就是Voice Conversion,它也可以用VTC,Tango這個技術來做到變聲器。