back to index
More about Auto-encoder (4/4)
link |
接下來我們要講的是說,我們過去在train auto encoder的時候,那個embedding,我們都說它就是一個continuous vector,它是一個向量,它是一個我們都說是低微的向量,不過算低微,它可能維度也是,比如說五十微、一百微一個向量,然後它是continuous。
link |
一般給你一個這樣的向量,它到底在幹什麼?你也是搞不清楚。所以我們更進一步期待說,今天我們的encoder,它能不能夠output discrete的東西。
link |
如果今天encoder可以output discrete的東西,我們就更容易解讀這個output的東西代表什麼意思,我們甚至可以更容易的做分群,因為過去,如果你今天要把這個encoder拿來做classic,那通常怎麼做?你說encoder會把你database的每一張圖片變成一個向量,接下來你還要用k-means classic或其他classic的方法把這些向量分成好幾群。
link |
但假設今天encoder它output直接就是discrete的東西,它直接告訴你說,這一張圖片它的code就是1,而另外一張圖片它的code就是2,再一張圖片它的code就是3,你直接就知道說所有code是1的圖片它們就是一群,所有code是2的圖片是一群,所有code是3的圖片就是一群。
link |
所以我希望encoder如果它可以output discrete的embedding,那今天我們要解讀這個embedding的內容會更加的方便。舉例來說,我們能不能夠讓encoder它的輸出就是one half vector,只有一維是1,其他都是0,那我們光看是哪一個維度是1,我們就可以知道說只要同一個維度是1的object,就通通都屬於同一類。
link |
所以就不需要把這個embedding叫做k-means的percent,你就自動已經把它分好群了。
link |
那實際上有辦法做到這件事嗎?有辦法做到這件事的,怎麼做?你可以說,我們今天在訓練encoder跟decoder的時候,我們在encoder跟decoder之間再加一個東西,我們今天encoder本來的輸出是一個continuous的vector,我們看看輸出這個continuous的vector的哪一維最大。
link |
接下來我們就把那一維改成1,其他維都改成0,得到一個one half vector,把這個one half vector丟給decoder,然後讓decoder還原原來的圖片。
link |
或者是說,假設你不喜歡one half vector,你喜歡的是binary的vector,你也可以做一樣的事情,你可以說,我們訓練一個encoder,一樣output一個vector,然後這個vector裡面,如果它的值大於0.5的話,我們在這個binary的vector裡面就給它1。
link |
如果小於0.5的話,在這個binary的vector裡面就給它0,然後把這個binary的vector丟給decoder,讓它還原原來的圖片。
link |
那你說這個東西要怎麼train呢?因為顯然這個步驟跟這個步驟是沒有辦法為分的,最大的值變成1,其他都變成0,或者是大於0.5就變成1,小於0.5就變成0,這個步驟顯然是沒有辦法為分的。
link |
那怎麼把這個步驟放到autoencoder裡面去做end-to-end的training呢?那這個,我有一些trick可以幫你做到這些事啦,那我就把reference列在這邊給大家參考,一個常用的trick叫做complete softmax的reparameterization,那我們這邊就不細講。
link |
總之你就知道說,就算這邊有一些步驟看起來好像是不能為分的,今天也有一些方法去想辦法optimize這些有不能夠為分的步驟的network,這個也是有辦法做的,總之這樣的network也是有辦法train的就是了。
link |
怎麼把binary vector跟one-half vector比較,我個人會覺得也許binary vector是一個更好的選擇,為什麼會這麼說呢?因為你想想看,假設你今天你的database裡面的東西可以分成1024群,那你這邊這個one-half vector就應該要有1024位,但是如果是binary vector的話,你只要10位就夠了,對不對?
link |
所以如果今天你要讓network做到同樣的事情,其實用binary vector來表示你需要的參數量是比較少的。
link |
而且binary vector還有一個好處就是,它有機會產生訓練資料裡面從來沒有看過的類別,對不對?不知道大家能不能夠體會這個意思。
link |
就是你有可能今天在訓練資料裡面,你看到的是1001跟0110,但是它有可能在測試的資料裡面看到其他的組合,所以它可能可以處理它在訓練的時候它從來沒有看過的東西,所以我會覺得說,相較於one-half vector,binary vector也許是更好用的。
link |
好,那這類的做法在文獻上有一個非常知名的做法叫做VQ-VAE,Vector Quantized Variational Autoencoder,我們這邊就講一下VQ-VAE的概念。
link |
那這個VQ-VAE怎麼做呢?這個VQ-VAE是這樣子的,我們有一個encoder,有一個decoder,但除了encoder、decoder之外,我們還有一個codebook,這個codebook裡面就是一排向量,那這個codebook它不是人設的,它也是學出來的。
link |
你要想成codebook這裡面這一排向量,這五個向量,它們也是network的參數,假設這些向量都是十維,這邊有五個向量,就總共有五十個參數,它們是被學出來的。
link |
好,那今天有一張圖片進來的時候,encoder會output一個向量,這個向量是continue的,接下來你拿這個向量去跟codebook裡面的每一個向量,跟codebook裡面這五個向量,去算它的相似度,看誰的相似度最高。
link |
假設今天跟這個紅色的vector,跟這個黃色的vector,它們的相似度最高,我們就把黃色的vector拿出來,當作decoder的input,然後try的時候還是minimize reconstruction error。
link |
因為今天這個codebook裡面只有五種向量,所以今天你丟給encoder的輸入,不是丟給encoder的輸入,說錯了,所以今天這個codebook裡面只有五個向量,所以丟給decoder的輸入就只有五種選擇而已。
link |
所以你等於就是把你的latent representation,你的embedded做一站化,讓它變成discrete的,然後你今天只有五種不同的token而已,那就看你的codebook的size有多大,你可以選擇的token就有多少。
link |
有人會問說,這個可以微分嗎?什麼算相似度,然後再看誰最像被拿出來,好像也不能微分。
link |
對,它也不能微分,這整個network,encoder decoder加codebook合起來是沒辦法微分的。
link |
那怎麼勸它呢?你就自己去讀一下文獻,還是有一些trick可以讓你勸這種沒有辦法微分的network。
link |
那像這種discrete的representation,它實際上有什麼用途呢?
link |
舉例來說,你如果今天用這種BQBAE或者是其他的方法,其他的discrete representation來encode語音訊號的話,就你強迫你的latent representation,你的embedded必須是discrete的話,那你今天認出來的那個discrete的embedded,它裡面包含的就會是聲音的內容的訊號。
link |
就是聲音裡面有關文字的部分才會被放到embedded裡面,有關語者的、有關環境雜訊的那些部分,它們就會被濾掉。
link |
為什麼?因為你想想看,這些embedded,假設它是discrete的,它就比較容易存這種discrete的資訊,而聲音裡面有關文字的部分,它是discrete的。
link |
文字本身就是一個一個符號組成,它是discrete的,所以這種discrete的資訊就會被放到embedded裡面,而不是discrete的資訊,舉例來說,語者的資訊、噪音的資訊可能就會被濾掉。
link |
那這樣子的話,假設你今天的目標是我要做語音辨識,那你先把聲音訊號通過這個encoder,你就比較容易保留你要去被辨識的那些語音的內容資訊,把其他的雜訊把它濾掉。那這個是VQBAE一個可能的應用,那我就把reference留在這邊給大家參考。
link |
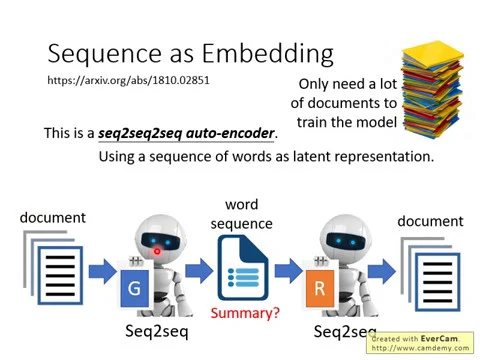
好,想要跟大家有問題要問嗎?好,那接下來,我們剛才說,我們讓data的representation變成discrete的,然後它比較容易被解讀,那我們其實甚至可以讓我們的embedded data的representation,它不再是一個向量,舉例來說,我們讓它是一個句子,假設我們現在encode的對象是一大堆的文章。
link |
那我們可以認一個sequence-to-sequence-to-sequence的autoencoder,然後這個sequence-to-sequence-to-sequence的autoencoder,它就是你的encoder吃一篇文章進來,它的output不是一個向量,而是一個sequence。
link |
這個sequence是什麼?是一串文字,也就是說你的encoder的output直接是一串文字,然後這個decoder把這串文字吃進去,試圖還原原來的文章。那你可能會期待說,這中間的文字到底會是什麼樣的內容呢?
link |
今天你的encoder可以把一篇長的文章變成一段文字,然後decoder讀了這段文字以後可以還原原來的文章,那這段文字可能就是原來那篇文章的摘要,原來那篇文章所精簡的結果。
link |
但是如果你只有這樣訓練一個直接訓練一個sequence-to-sequence-to-sequence的autoencoder的話,其實是訓練不出好的結果的,為什麼?因為encoder跟decoder它們都是機器,所以它們會發明自己的暗號。
link |
就是你說臺灣大學,它並不會縮寫成臺大,它可能會縮寫成灣學,反正只要decoder可以把灣學解回臺灣大學就結束了。
link |
所以這個encoder跟decoder它們會發明自己的暗號,所以encoder輸出的這串文字,雖然它確實是一串文字,但它就只是由人類的這些詞彙拼湊起來的句子,但是人是看不懂的。
link |
那怎麼讓encoder輸出的這個sequence是人看得懂的呢?你就需要用到gain的概念,雖然我們這堂課還沒有講過gain這件事情,不過這個也不難理解,我們訓練一個discriminator,我們就訓練一個binary classifier。
link |
那這個binary classifier它的工作就是開一個句子,它要判斷說這個句子是人寫的還是不是人寫的,你就給它很多人寫的句子,然後看到這個人寫的句子,它就要說對,看到機器寫的句子,它就要說錯。
link |
然後今天你的encoder就要去學習去騙過這個discriminator,你的encoder就要學習說輸出一串文字,這串文字是discriminator覺得看得懂的,像是人寫的句子。
link |
但同時,今天這個encoder輸出的句子,decoder又要可以還原回原來的文章,那encoder輸出的句子,它可能就保留了文章裡面最重要的資訊。
link |
那這個是我們實驗室王耀賢同學做的結果,那這邊其實是有一些真正的例子。
link |
那有同學會問說,那這個也不能夠微分啊,你中間這個latent representation是一個句子,也是discrete的東西,那這整個network合起來能夠微分嗎?確實不能微分。
link |
所以實際上做的時候是用reinforcement learning去train encoder跟decoder,那如果你不熟悉reinforcement learning的話也沒有關係,你就接著記了一個口訣,就是如果今天有一個loss function,你發現它不能微分,就用reinforcement learning硬做這樣子,然後就結束了。
link |
你就把你的loss function當作reward,然後把你的network當作agent,然後就硬train,然後就結束了。
link |
好,現在是一些真正的例子。舉例來說,給機器看一篇文章,這個是人寫的摘要,那這個就是encoder output的那個句子,你會發現說這個句子是看得懂的,是人看得懂的,拿來做澳大利亞加強體育競賽之外的藥品檢查。
link |
不過我發現機器其實它很喜歡直接從文章裡面抄一個片段出來,因為它可能後來就學到說,從文章裡面抄片段出來,就很容易騙過discriminator就是了。
link |
這是一個比較強的例子,這篇文章是講說,中華民國奧林匹克委員會今天接到冬季奧運會邀請函,那那個encoder的output就寫說,奧委會接獲冬季奧運會邀請函,它自己把奧林匹克委員會縮寫成奧委會。
link |
可能是因為discriminator知道說,很多人寫的句子裡面都有什麼A委會、B委會、C委會,所以就可以把奧林匹克委員會縮寫成奧委會,看起來就像是人寫的句子。
link |
有時候機器也會犯錯,舉例來說這篇文章是,印度尼西亞蘇門達蠟島連降暴雨,那encoder的output是印尼門洪水氾濫,印尼門是什麼呢?印尼門就是印度尼西亞蘇門的縮寫,機器看過很多通俄門、羅生門之類的,所以它覺得印度尼西亞蘇門應該可以縮寫成印尼門。
link |
有時候encoder也會output一些你看不懂的結果,舉例來說這篇文章,encoder的output是,合肥領導幹部夏季臣作稿迎來送往,規定一律檢閱,不知道在說些什麼都適合你,所以用這個技術,你就可以讓機器自動學會怎麼對一篇文章做摘要。
link |
其實在文獻上現在還有更多的例子,你的這個latent representation剛才講說可以是個word sequence,所以我就把文獻留在這邊給大家參考,現在還可以說直接output一個syntactic的parsing tree,或者是semantic的parsing tree,看你敢不敢這樣,就敢不敢encoder output,就是一個parsing tree,然後再把它解回原來的句子,那這個都是一些很新的研究的成果。
link |
好,那這個就是今天大概跟大家講的內容,第一部分就講說除了reconstruction error以外有沒有別的做法,第二步就講說有沒有什麼技術可以讓今天machine的output更能夠容易的被解讀,那我們這部分就講到這邊,那接下來就趕快請助教來講作業C。