back to index
Network Compression (2/6)
link |
我曾經想過一個問題,為什麼我們要做微波呢?既然你要的就是一個比較小的內窩,為什麼你不一開始就圈一個比較小的內窩呢?
link |
為什麼要圈一個比較大的內窩,再砍掉一些weight呢?為什麼不就直接圈那個小的內窩,為什麼要捨本逐末,捨近求遠,先圈大的,再把它變成小的呢?
link |
常見的說法是,因為小的內窩比較難圈。在實作上,我也是感覺小的內窩比較難圈,我不知道大家覺得怎麼樣就是了。
link |
為什麼小的內窩比較難圈呢?一個可能的原因是,其實大的內窩比較容易optimize。你可以看一下下面這個是我之前上課錄的YouTube連結,我講說為什麼大的內窩可能是比較容易optimize。
link |
因為我們知道,在圈內窩的時候,你會有這種local minima的問題,你會有saddle point的問題。但是如果你的內窩夠大,這種問題就會比較不嚴重。今天已經有越來越多的文獻,甚至可以證明說,只要內窩夠大,你可以用歸顛descent直接找到global optimum。
link |
我們之前常常批評deep learning的一個點就是,deep learning就是會卡在local minima,或者卡在saddle point,找不到global minima。事實上,已經有不少文獻可以證明說,只要內窩夠大,用歸顛descent可以找到global optimum的解決方案。
link |
這也許就是為什麼小的內窩比較不好,大的內窩比較好圈。我們圈一個好圈的大的內窩,然後接下來再把它變小,也許是一個好的方式。
link |
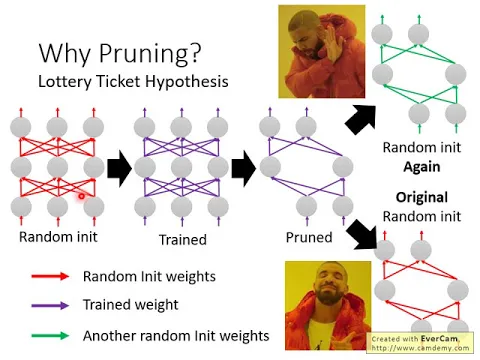
今年的Ipeer有一篇很有趣的篇文,他提出了一個Lottery Ticket Hypothesis的想法,他提出了一個大樂透假設,然後他試圖解釋為什麼我們會需要waypointing。在這個大樂透假設裡面,作者觀察到這樣的現象。
link |
他說,我們一般做waypointing的時候就是,你先圈一個大的內窩,給random initialize一個大的內窩的參數,然後接下來就給它圈下去,圈完以後,point掉一些你不要的位。
link |
我們假設紅色的參數代表的是我們random initialize那個大的內窩的時候,我們所random initialize的參數,這些紅色的位的,它是random initialize的,圈完以後變成紫色的位的。
link |
我們現在有一個小的內窩,那我剛才問的問題是,何不直接就圈這個小的內窩呢?
link |
這個作者發現說,直接圈這個小的內窩,你把這個小的內窩的架構拿出來,再重新random initialize,那重新random initialize當然它的參數不會跟紫色的位或者紅色的位一樣,重新random initialize一組綠色的位圈下去,結果發現是圈不起來的。
link |
這個符合多數人的common sense,就是小的內窩不好圈。
link |
但是這篇payment驚人的地方是,它發現說,如果我們現在一樣是拿一組random initialize的位的,但是這組random initialize的位的它不是真正的random,這個聽起來很奇怪,什麼叫做不是真正的random?
link |
它說,我們用這邊的位的來initialize這一個比較小的內窩,也就是說,這邊本來這個位是多少,就直接把它copy過來,這個位是多少,就直接把它copy過來。
link |
就這個內窩是原來大的內窩的一個subset,因為它是prune過以後的結果,所以這個小的內窩是大的內窩的一個subset。那我們現在大的內窩的時候,給這個subnetwork,給這個比較小的內窩,到底給它random initialize什麼樣的值,現在就給它一樣的值。
link |
所以我們就把紅色這邊的位的直接copy過來,圈下去,發現就圈得起來了。為什麼會這樣呢?它就提出了大樂透假設,它說,圈內窩就像是買樂透一樣,你知道在買樂透的時候,你買的那個ticket越多,你買越多張,中獎的機率就越高。
link |
圈內窩就像買樂透一樣,因為不同的random initialize的位格,有時候圈得起來,有時候圈不起來。它說,一個巨大的內窩,你可以想像裡面就是有很多的小內窩,一個巨大的內窩就是有很多的小的內窩所組成的。
link |
一個內窩越巨大,裡面的小的內窩就越多,每一個小的內窩就是一種可能的initialization的參數,這些小的內窩有的圈得起來,有的圈不起來。
link |
所以你圈完以後,大的內窩比較容易圈起來,是因為大的內窩裡面只要有某一個小的內窩圈起來,整個大的內窩就圈起來了。
link |
然後你再把大的內窩做pulling,你就把剛才圈得起來的那個小的內窩取出來,然後這個之前圈得起來的那個小的內窩代表說,之前你random initialize這個小的內窩的參數,它是好的,它是一種好的initialization。
link |
你要這種好的initialization去圈,就圈得起來了,就這樣。
link |
好,這個問題問得很好,我沒有真的做過這個實驗,
link |
所以我沒有辦法回答你這個問題,你可以仔細看看paper看看是不是這個樣子,但是就我的印象而言,作者可能沒有要求shuffle的次序必須是一樣的,也許這是一個好的research的problem就是了。
link |
這篇paper其實很長,它有三十幾頁調參數的內容,它不好調一波參數,因為它想要告訴你說,它不是特別挑了某一個結果是這個樣子,它覺得這個現象是很general的現象。
link |
好,你可以再自己仔細check一下paper。
link |
我們其實也可以停在這邊,你會覺得說,嗯,人生是很美好的,我們知道為什麼我們要prune network的位置,這個是ICLR2019的paper。
link |
但是在ICLR2019還有另外一篇paper,它叫做rethinking the value of network pruning,它想要講的事情就是,其實小的network就是圈得起來了,就是這樣。
link |
它說,我們做在不同的data set上,我們有不同的大的model,我們現在想要把它prune小一點,如果你直接fine-tune,這是你得到的結果。
link |
它說要train from scratch,就是直接從random initialize開始train,其實是比fine-tune還要好的。
link |
然後它這邊的scratch,在它這邊的random initialize,是真正的random initialize,並不是跟那個大樂透假說一樣,是拿之前的random initialize再copy過來,它是真正的random initialize。
link |
這邊scratch1跟scratch1的差別只是說,scratch1就是train比較多APOC而已。
link |
所以就是又回到了原點,這篇paper告訴我們說,不需要什麼大樂透假說,直接train其實就是train得起來的。
link |
那你可能會說,那這篇paper的結論不就跟前面那篇paper的結論矛盾了嗎?對,就是矛盾了,你可以去看一下ICLR的paper是open review的,所以reviewer他們還有作者的回應都可以直接在網絡上找到,都是公開的。
link |
所以在這兩篇paper的review comment裡面,都有reviewer提到說,你跟另外一篇paper得到的結論是矛盾的,你要不要解釋一下?
link |
那其實這兩篇paper的作者都有做一些回應,你可以再自己去看看。
link |
那這個network pruning有一些實作上的問題是你需要注意的,我們剛才在講pruning的時候,我們說你可以衡量weight的重要性去把weight prune掉,你可以去衡量neuron的重要性去把neuron prune掉,但是pruneweight跟pruneneuron哪一個比較好呢?
link |
我們來想想看pruneweight會有什麼樣的問題。如果我們今天是pruneweight的話,本來這是你prune之前的network,這是你prune之後的network,你可能會遇到一個問題是,prune完以後,你的network變成是不規則的。
link |
所謂不規則的意思是說,在同一層裡面,有些neuron是吃兩個input,有些neuron是吃四個input,那這樣子你在實作上就有問題了,或我們講得更具體一點,像這樣的network你用keras implement得出來嗎?
link |
你不知道怎麼implement對不對?所以這個實作上根本就有點難,然後你可能想說,好,也許我用某些方法真的implement出來了,GPU也不好加速這種network,GPU能夠加速是因為它是做矩陣運算,那你現在如果是這種不規則的形狀,你不做矩陣運算的話,你就不好用GPU加速了。
link |
所以實作上,假設你要寫paper,然後你做weight pruning的話,比較常見的實作方法就是,其實它並沒有把這些weight prune掉,它只是把要prune的weight的值設成零,懂嗎?
link |
把要prune的weight的值設成零,這樣你的network架構仍然是規則的,這樣子你在做實作的時候,你仍然就是比較方便,仍然可以用GPU加速。
link |
那這樣的問題是什麼?這樣的問題就是,你並沒有實際上,就是你當然可以在腦中想像說,我設成零的那些weight就是從network裡面prune掉了,它們是不存在的,然後我也可以得到數據,但是實際上你並沒有把那些weight prune掉,這樣大家知道我的意思嗎?
link |
或者是我們講得更具體一點,到時候作業怎麼評估你的network的大小呢?我們是直接算你圈出來的network那個file的大小,如果你今天是補零,並不是真的把它移除的話,那你就只是在自嗨而已,到時候算出來的network大小仍然是一樣的,這樣大家了解嗎?
link |
所以在實作上,prune weight比較麻煩。這個是文獻上真正的結果,就是有人試了一下說,如果我們今天是做weight pruning,會遇到什麼樣的問題?
link |
如果我們今天是做weight pruning的話,這個紫色這條曲線是我們prune掉的量,然後這邊是prune那個NX net,那有五成,那這個prune的量它prune很大,它都prune到大概95%左右,就丟掉了95%的weight,多數的weight都被丟掉了。
link |
但是其實network的performance沒有掉很多,所以weight pruning這招很強,你可以把networkprune到剩下原來的十分之一,有時候那個accuracy都只是在一兩趴的差別而已。
link |
好,那如果我沒記錯的話,這個實驗應該是這個NX netprune了95%的參數以後,accuracy只掉兩趴而已。反正他發現說,實際上用了各種不同的GPU在做加速的時候,你並沒有真的加速太多,而且在很多case,你的加速居然是小於一的。
link |
加速小於一是什麼意思?就比較慢這樣子。為什麼?因為你現在你的network不是regular了,那你變成說你在實作的時候,你根本就不好實作,GPU加速的時候根本就沒有效率,結果你以為prune了weight以後會比較快,結果沒比較快,結果反而是更慢。
link |
所以prune neuron也許是比較好的方法,因為舉例來說,我們知道說這個neuron不重要,我想要把它prune掉,那你就把這個neuron前面連接的weight跟後面連接的weight整個拿掉,那你只是變成說本來你這個hidden layer有四個neuron,變成有三個neuron,那這樣子是比較容易實作,也比較容易加速的。
link |
好,那這個是network pruning。