back to index
Network Compression (3/6)
link |
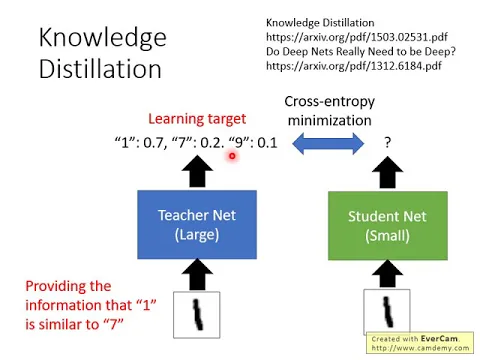
下一個要講的技術叫做知識分析。知識分析是什麼意思?知識分析是說,我們可以先訓練一個大的網絡,再訓練一個小的網絡,去學習大的網絡的行為。
link |
我們先訓練一個很大的網絡,然後把訓練的資料都丟到大的網絡裡面,那這個大的網絡會得到一些效果。
link |
但大的網絡的效果也不會完全是正確的。大的網絡的效果,他可能給他這張圖片,他覺得他有0.7的信心分數是1,0.2的信心分數是7,0.1的信心分數是9。
link |
他可能不會覺得說完全是1,因為他1跟7跟9長得有點像,所以他說他覺得很像是1,但也有一點點可能是7跟9。
link |
接下來,你用一個學生名稱,他是一個比較小的網絡,去模仿大的網絡的效果。
link |
也就是這個學生名稱,他不是跟正確的資料去學習,你並不是直接教學生名稱說這個是1,你不是這樣教他。
link |
你是告訴他說,你去看大的網絡的效果是什麼,你跟他的效果一模一樣的東西,就是學生名稱看到這張一樣的圖片,他要效果說他有70%的信心分數是1,20%的信心分數是7,10%的信心分數是9。
link |
過去人們相信說,或者在文件上也看到很多的例子是,小的網絡,學生名稱直接勸,勸不起來,他要跟著大的網絡去勸,才勸得起來。
link |
當然我們剛才有看到說,也有很多的反例,那這個都是目前仍然尚待研究的問題。
link |
不過在過去,人們相信,小的網絡勸不太起來,要勸大的網絡才可以。那你可以在文獻上找到這樣子的相關的技術跟討論。
link |
但是你在計算這個Cross Entropy的時候,你是計算兩個Distribution之間的Kailh Divergence,對不對,你要minimize兩個Distribution之間的Cross Entropy。
link |
那今天是在OneTard的Case,它只是一個Special Case。
link |
今天在這個Case,你當然也可以用Mean Square Error,但是你在這邊用Cross Entropy是完全沒有問題的,因為這邊也是一個Distribution,然後你希望你的Narrow Output的Distribution跟Teacher Output的Distribution越近越好,這樣希望有回答到你的問題。
link |
那我認為這邊應該是用Cross Entropy還是會比較好啦,用Mean Square Error,在你的Output是Sigmoid或者是Softmax的時候,是會有問題的這樣子。
link |
好,這樣大家這邊還有問題嗎?好,那這邊試圖用直觀的方法幫大家解釋一下說,為什麼Student跟著Teacher去學可能會有比較好的結果。
link |
那是因為Teacher其實提供了比Label Data更豐富的資料。舉例來說,在這個例子裡面,如果Student直接跟Label Data去學,他只會知道說這張圖片是1,但是老師在教Student的時候,他不只告訴他這張圖片是1,他還順便告訴你說1跟7長得很像,1跟9長得很像。
link |
所以今天Student跟老師學的時候,他學到的東西是更多的。
link |
那如果你看這個Knowledge Destination,Hinton寫的那篇Paper的話,他甚至可以做到神奇的事情是說,在訓練的時候,你可以把某些數字直接就Remove掉,比如說你從來沒有給Student看7這個數字,但是Student仍然可能可以正確地辨識7這個數字。
link |
為什麼?因為他在跟老師學的時候,學過說7長得跟1很像,他也學過說7長得跟9很像,所以到時候,雖然在訓練的時候,他從來沒有看過7這個數字,但是訓練的時候有7進來,他可能也可以得到正確的辨識結果。
link |
那Knowledge Destination一個有用的地方是說,我們今天在做Machine Learning的時候,你往往會做Ensemble,大家都知道說如果是打Cargo比賽的話,最終的大絕招我們都要做什麼?就是瘋狂的Ensemble。
link |
最後比的就是,誰Ensemble比較多Model就贏了,別人用8個,你用16個,你就贏了,別人用16個,你就用32個,你就贏了,所以最後就是比說誰Ensemble比較多的Model。
link |
但是這種Ensemble,雖然你可以在Cargo的比賽上進步一些,但是在實作上、在實用上是沒有效率的,因為你說你train了一千個Model,進步了1%,那又怎樣呢?你真的能夠在你的device上面放一千個Model嗎?你真的能在testing的時候跑過一千個Model嗎?
link |
所以Knowledge Destination一個有用的地方是,它可以把你Ensemble的Model統統併起來,變成一個Model。也就是你現在,你在做Ensemble這件事,你有一大堆的Network,你會把這些Network的output做平均,得到一個答案。
link |
接下來,你讓你的Student去學這個Ensemble的Network的output,你希望你的Student的Network的output跟Ensemble的結果一樣,那你就可以把Ensemble這個東西讓Student學起來,到時候你只需要一個Model,它就可以達到類似Ensemble的效果,它就可以達到Ensemble的Performance。
link |
好,那這是Knowledge Destination的一個妙用。然後在實作上呢,在實作Knowledge Destination的時候,有一個常用的Trick就是,一般我們在做Classify的時候,你最後會有一個Softmax的Layer嘛,那Softmax的Layer是怎麼實作的呢?
link |
就是你會把你的Network Output的值,假設Network現在在最後一層Output的值叫做X,你會把X取Exponential,再做Normalize,得到最終的輸出Y。那這個呢,我們之前課堂已經講過很多遍了,我們就不要再重複,你會做這個是Softmax。
link |
那在做Knowledge Destination的時候,你在取Exponential之前,你可以把你這些值都除一個大T,這個大T叫做Temperature,它通常是一個大於1的值。
link |
那除這個Temperature有什麼用呢?我們就舉一個例子,假設你現在的X有三個分別是110跟1,你做完Softmax以後,你得到的結果,Y1是1,Y2跟Y3都是十個負十幾次方,就跟0是一樣的。
link |
那我們說這種Knowledge Destination的方法會有用,是因為你的Teacher告訴Student更多的訊息,他告訴你說1跟7很像,但是你不希望說你的Student,你的Teacher的Output跟One-half是一樣的,跟Label Data是一樣的。
link |
如果你的Teacher只會Output說某一個Label是1,其他都是0,那其實就跟Label Data學,直接跟正確答案學是一樣的。所以我們為了讓Teacher Output Distribution可以更輕易地讓Student學到,
link |
所以你會讓不同的Label間的分數拉近一點。那怎麼讓不同的Label間的分數拉近一點呢?你就是除上這個Temperature,那這邊假設我們Temperature是100,
link |
所以本來X1、X2、X3分別是110,那除掉100以後就變成1、0.1、0.01。那再做Softmax,再過Softmax以後得到的值就是0.56、0.23、0.21,Y1它的值仍然是最大的。
link |
那這個時候Student就會知道說,那Y2跟Y3也有一些值,讓Student跟Teacher去學的時候就會跟真正的Data學不一樣。
link |
那這個T就是一個參數,這個參數是你需要去調一下的。
link |
那在實作上,還有在我們的作業上,助教自己實作的結果發現Noise Desolation沒有特別有用,就這樣子。