back to index
Network Compression (4/6)
link |
舉例來說,你本來都是用32個bit來存一個參數,現在改成用16個bit來存一個參數,你直接整個network的size就變二分之一。
link |
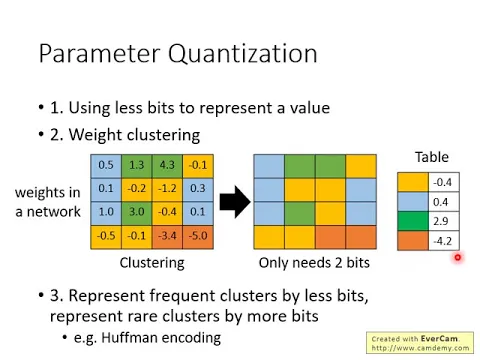
另外一個方法是做weight的classing,舉例來說,這個是我們現在network的weight,現在假設這個network有16個weight,那你把這些weight進行分群。
link |
你用一個你喜歡的分群的方法,比如說K-means的algorithm,把這些參數分群,假設我們現在就是分成四群,每一群用不同的顏色來表示。
link |
之後你在記錄存這個network的時候,你就不需要存它真正的數值,你就存它的cluster ID就好。現在我們把我們所有的參數分成四群,接下來你只要記得每一個參數屬於哪一群就好。
link |
如果我們現在是把參數分成四群,現在你在表示每一個參數、記錄每一個參數屬於哪一群的時候,你可能只需要兩個bit,因為兩個bit你就有0001、101,總共有四組可能,你就可以表示四個cluster。
link |
那每一個cluster、每一群要用哪一樣的數值呢?你就存另外一個table,這個table告訴我們說,只要看到紅色這個cluster,我們就當作它的數值是-4.2。
link |
為什麼-4.2呢?因為這個紅色cluster裡面有-3.4、有-5,那你就取它的平均值,取-4.2來代表-3.4跟-5。
link |
那你只這樣做,你會有一些不精準的地方,你把-3.4跟-5都用-4.2來取代,會有一些不精準的地方,你的performance可能會稍微掉一點,不過用這個方法,你可以讓你的network變得比原來小很多。
link |
甚至你可以再更進一步壓縮你的network,因為假設你對通訊的編碼比較熟悉的話,那你可能有學過Hopeman Coding,Hopeman Coding做的事情就是把比較常出現的那些token給它比較少的bit來表示,比較少出現的token給它比較多的bit來表示。
link |
所以你這邊你可以把比較常出現的cluster用比較少的bit來表示,比較少出現的cluster用比較長的bit來表示,這樣子你的network的大小又可以再更進一步的進行壓縮。
link |
就這種Programmable Quantization的方法的極致,是你可不可以只用-1跟-1來表示一個weight。其實在文獻上,有不少文獻試圖去develop一些方法,是可以直接train一個binary weight的network的。
link |
而那其中最早的一篇paper是這個binary connect,那我就要很快的跟大家講一下這個binary connect是怎麼做的。當然很簡單,你要自己再做一做,應該也是有可能做得起來的。
link |
binary connect是怎麼做的呢?現在這個圖上的這些灰色的點代表的是參數的space,現在這個投影片上的每一點代表某一組參數。
link |
那灰色的點代表這一組參數裡面的每一個數值都是二元化的,都是正一或者是負一。
link |
binary connect它的精神是,我們在找binary weight的同時,我們keep了一組real value的參數。比如binary weight的訓練,binary connect的訓練,其實跟一般的network很像,你就先random initialize一組參數,那這組參數可以是real value的,沒有關係,我們random initialize一組參數。
link |
一般我們在train network的時候,就是根據這一組參數去計算它的gradient。但在binary connect裡面,你不是拿這一組參數去計算它的gradient,你是去找跟這組參數最接近的一個有binary weight的network,然後根據這個binary weight的network去計算它的gradient。
link |
所以現在這個藍色的參數,它跟這一組有binary weight的參數是最接近的。在這邊計算一下gradient,紅色的箭頭指向這邊,那你就把這一組參數根據紅色箭頭這個方向來進行update,那這個參數就移動到這邊。
link |
接下來你再找一個最接近的binary weight,然後根據binary weight算出來的gradient去update藍色這組參數,再找一個最接近的,再計算一下gradient,再update一下參數,再找一個最接近的,再update gradient,再計算一下參數。
link |
直到你想要停下來的時候,你就看說現在我們所停的位置最接近的binary weight的network是哪一個,把這個binary weight的network拿出來做最後的使用。
link |
而這個binary connect根據文件上的結果,看起來其實結果還不錯的,這是在admins的Cypher10還有SDHN這三個corpus上的結果。大家會發現說,上面這個是正常的network,它在admins上的錯誤率是1.3,binary connect的錯誤率是1.29,它居然還比原來的admins還要強,它比正常的network的performance還要再好一點。
link |
那為什麼呢?因為你可以想像binary connect這件事情有點像是regularization,它給network提供一些限制,說你現在的參數的值只能夠是正1跟負1。
link |
所以相較於完全沒有做regularization的network,binary connect的結果,它把參數都二元化以後,居然結果還比正常的network performance還要好一點。
link |
你可能本來期待說,把network weight變成只有正1跟負1,應該會整個慘掉吧?不是,居然還好一點點。不過它贏不過有抓爆的結果就是了,抓爆還是更好的。