back to index
Network Compression (5/6)
link |
調整network的架構設計,讓它變得只需要比較少的參數,那這個也許是今天我覺得在實作上最有效的做法。
link |
那怎麼調整network的架構設計,去減少你需要的參數量呢?我們先來看,如果是fully connected的network,你可以怎麼做?
link |
我們現在有一個fully connected的network,前一層有n的neuron,下一層有n的neuron,那在這個前一層到下一層中間,W代表我們的weight matrix,W代表我們的network的weight。
link |
那現在呢,我們在這前一層跟下一層,在這n的neuron跟這n的neuron之間,再插一個hidden layer,這個hidden layer有k的neuron。
link |
那這hidden layer的k跟neuron,它們沒有acclimation function,它們是linear,所以我們再多插一層,那把原來只有W這一層變成有v這一層加u這一層。
link |
那你聽到這邊可能會想說,這個多加一層不是參數變多了嗎?你仔細想想看,多加一層,其實參數是變少的。
link |
怎麼說呢?今天這個W的weight,它裡面有多少參數呢?前一層有n的neuron,下一層有n的neuron,那這一層的weight就是n乘以n。
link |
那在這邊呢,你的v這一層呢,有n乘以k的neuron,u這一層呢,有k乘以n的neuron,那你把這個v乘上u,希望它可以做到原來W可以做的事。
link |
那如果你今天在設計你的network架構的時候,你特別調整一下,讓k的這個值不要太大。舉例來說,你可能本來n是1000,n是2000,那你這個k估計給它一個比較小的值,比如說100。
link |
k估計給它一個比較小的值,你做出來就會發現說,u跟v的參數的和其實是比W還要小,W是n乘以n,那如果n跟n的值都很大的話,那這個值就會非常大。
link |
但是u跟v的參數的和,是k乘上n加n,對不對,是k乘上n加上k乘上n,也就是k乘上n加n。
link |
如果你今天特別做一下設計,讓k的值不要太大,那你就可以減少你的network的參數量。
link |
所以今天如果你有一個fully connected的network,它的healer layer非常大的話,那一個可以讓你的參數量減少的trick,就是插一個linear的layer,然後這個linear layer的neuron不要太多,你就可以減少你的參數的量,那做到的事情可能仍然跟原來是非常類似的。
link |
當然如果你插一個這樣的layer,你就給network一個比較大的限制,因為今天這個W其實可以做到u跟v本來相乘以後做不到的事情。
link |
你想想看,如果你熟悉線性代數的話,你把u這個matrix跟v這個matrix相乘,它們的rank一定會小於等於k。所以u跟v相乘以後,它得到的結果,它得到那個matrix的rank一定會小於等於k,但W沒有任何限制。
link |
所以你右邊的這個network,你插了一個linear layer以後,你其實會限制你的network capacity,你會限制你的network可以train出來的參數,你會限制你的network原來可以做到的事情。
link |
我們先來很快地幫大家複習一下,原來standard的convolutional neural network是怎麼做的。現在假設我們的input feature map長這個樣子,那我們這個input feature map有兩個channel,每個channel表示成6乘以6的matrix。
link |
那今天假設我們的input feature map有兩個channel,那我們的filter就會變成是立體的。
link |
這樣大家可以了解嗎?假設我們input有兩個channel,我們input這個feature map它的高是2的話,那你的filter它的高也必須要是2。
link |
filter的kernel,filter的size是你可以自己訂的,比如說我們這邊filter的size,我們訂3乘以3。但是如果我們input的feature map它的高是2的話,它有兩個channel的話,那我們的filter它的channel也必須要是2,我們filter會變成是立體的,它的高也是2。
link |
好,那我們就把這一個filter跟這個feature map做一下convolution的運算,那這個我們在之前的影片都有提過了,這邊就不再細講,你會得到一個4乘以4的matrix。
link |
好,那我們filter通常不只一個,在這個例子裡面,我們有四個filter,我們就得到四個4乘以4的matrix,我們把這些matrix放在一起,就得到新的feature map,留給下一個convolutional的layer去做使用。
link |
好,那今天在這個例子裡面,我們總共使用了多少的參數呢?今天在這個例子裡面,我們前一層input的feature map是兩個6乘以6的matrix,那我們的output是四個4乘以4的matrix,要做到這件事情我們需要多少參數呢?
link |
我們每一個filter總共有3乘以3乘以2的參數,我們每一個filter有3乘以3乘以2的參數,總共有四個filter,所以我們總共有3乘以3乘以2乘以4的參數,總共是72個參數。
link |
大家記得72個值,因為我們等一下要把convolution的這個layer做簡化,那可以看看說我們可以從72個值減少到多少值。
link |
好,那這邊要跟大家介紹的是一個叫做separable convolution的東西,那它總共分成兩個步驟,我們把本來convolution這件事拆成兩個步驟,雖然說拆成兩個步驟,但你只需要比較少的參數就可以跟原來得到差不多的效果,就可以跟原來的convolution做到差不多的效果。
link |
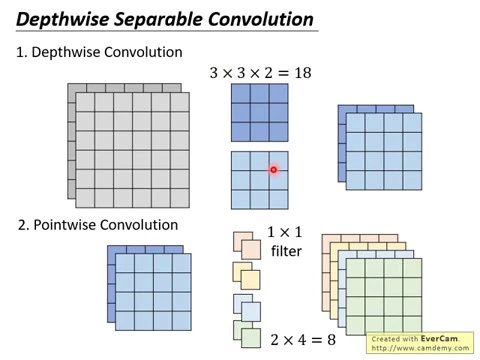
好,那我們剛才講說一般的convolution,你如果input的feature map有n個channel,那你的filter就是立體的,它也應該要有n個channel,但是在densewise的separable convolution裡面,你的第一步叫densewise的convolution,densewise的convolution它的filter不是立體的,你的filter仍然是一個矩陣,仍然是2D的,不是3D的。
link |
那在第一步這個densewise的convolution裡面的限制是,你的input有幾個channel,那你就設幾個filter,在這個例子裡面input是兩個channel,那你就設兩個filter,每一個filter只負責一個channel而已,淺藍色的filter就對付淺灰色的input,深藍色的filter就對付深灰色的input。
link |
好,那我們現在的filter它不是立體的,它的kernel size都是kxk,filter size都是kxk,但是它不是立體的,那接下來你就拿每一個filter各自去處理它們負責的channel,比如說淺藍色的filter就處理淺灰色的input,
link |
那你就把淺藍色的filter掃過這個淺灰色的input,掃過這個淺灰色的input,掃過這個淺灰色的input,那你就會得到一個feature map,像右邊這樣子,它是一個4x4的metric。
link |
那對深藍色的filter來說也一樣,它就負責處理的channel,每一個filter只負責一個channel,跟一般的CNN不一樣,一般的CNN,一個filter要處理所有的channel,所以你的filter是立體的,在這個dashwise的separable convolution裡面,你的filter不是立體的,每一個filter在第一個步驟裡面,每一個filter只管一個channel就好。
link |
那在第一步裡面呢,不同的channel之間就沒有交集,就是灰色的這個input根據藍色的convolution就得到這個藍色的4x4的metric,深灰色的input根據深藍色的filter就得到這個深藍色的metric。
link |
那不同的channel間,它們是沒有互相影響的,就各做各的,現在不同的channel是各做各的。因為第一步是各做各的,所以第二步就要把它們之間的關係考慮進來。
link |
第二步叫做pointwise convolution,pointwise convolution怎麼處理channel和channel之間的關係呢?它用一個1x1的filter來處理不同channel間的關係。
link |
舉例來說,現在我們有一個1x1的filter,它的參數就只有兩個,因為input現在有兩個metric,所以這邊的參數就兩個。你把這個1x1的filter掃過這個input的feature map,就在前一個步驟我們會得到一個feature map。
link |
但是前一個步驟這邊input如果是兩個channel,那output也一定會是兩個channel。
link |
接下來在下一步,在第二步,其實跟一般的convolution就是一樣的,但不同的地方是,一般的convolution,你的filter是有大小的,但是在第二步,它雖然跟一般的convolution是一樣的,但是你的filter的大小固定是1x1,把它縮限在1x1。
link |
那你就把這個1x1的filter去掃過input的feature map,掃過去,就得到一個4x4的metric,那你現在有幾個1x1的filter,你就得到幾個4x4的metric。
link |
我們現在有四個1x1的filter,你就得到四個4x4的metric。我們剛才在講standard的convolution例子的時候,我們說input兩個6x6的metric,output四個4x4的metric。
link |
現在我們做dashwise的separable的convolution的時候,我們做的事情跟我們做的input跟output,跟剛才我們舉例的時候用的一般的convolution的input跟output是一樣的。那我們現在來算算,它們的input跟output是一樣的,但是dashwise separable的convolution,它用的參數有多少呢?
link |
在第一步裡面,我們要用多少參數呢?我們有兩個3x3的metric,所以我們需要3x3x2總共18個參數。
link |
在第二步,我們有四個1x1的filter,每個1x1的filter有兩個參數,我們有四個filter,所以總共八個參數,合起來我們只用了26個參數。
link |
所以原來我們要把這個東西變成這個東西,需要72個參數,但現在我們把它拆解成兩步,那我們就只用了18加8個參數而已。