back to index
Network Compression (6/6)
link |
那這邊再更直觀的幫大家解釋一下說,原來的convolution跟現在這個describe separable的convolution有什麼樣的關係。
link |
在原來的convolution裡面,你input這樣子的東西,output這樣子的東西,那左上角的這個值是怎麼被算出來的呢?左上角這個值是說,我們有一個3乘以3乘以2的filter,我們把這個3乘以3乘以2的filter放在這個input的feature map的左上角跟input feature map的左上角的這3乘以3乘以2的值做搭發搭,
link |
然後你就得到左上角這個值,你把你的filter放在這邊,做搭發搭以後就得到這個值,所以你可以想像說你的filter就是吃18個輸入,然後得到一個輸出,把它放在左上角。
link |
同理,比如說,黃色的這個matrix,它左下角的值是怎麼來的呢?你是把另外一個filter放在左下角,這個filter也是吃18個值當作input,得到一個輸出,就是一般的convolution。
link |
好,那我們剛才講的那個dashwise separable的convolution,跟一般的convolution有什麼不同呢?dashwise的convolution,左上角的值是怎麼來的呢?這個左上角的值是來自於一個中間產物。
link |
所以其實這個dashwise的這個separable的convolution,它的概念跟我們最開始講的那個,我們剛才講說如果你要讓fully connected v-forward的值,the network的值變出來,是中間就插一個linear的hidden layer,就可以讓它的參數量變少。
link |
那其實這邊的概念是很像,我們是在中間再插一個東西,我們在中間再插一個feature map,那這個feature map它的channel跟input的feature map的channel是一樣的。
link |
那這個紅色的左上角的值是怎麼來的呢?它是從這個中間產物的左上角,根據1x1的feature來的。
link |
那這個中間產物的左上角的值又是怎麼來的呢?這個中間產物是根據我們剛才講的這個沒有深度的feature得到的,每一個feature只處理自己的channel,它完全不管其他的channel。
link |
所以今天你可以想成是,我們在第一個步驟的時候,我們input如果是有兩個channel的話,那我們就有兩個feature,這兩個feature它們各自只處理9個input。
link |
接下來它們的output會有另外一個紅色的neural,把它們兩個的output吃進去,再得到最終的輸出。
link |
在desk-wide separable convolution裡面,每一個feature其實可以看作是拆成兩層,它中間還有一個different layer,我們把原來的feature吃18個input得到一個output,拆解成這18個input拆成9個input跟9個input,分別用兩個neural來處理,最終再把這兩個neural的輸出丟給紅色這個neural,再得到最終的輸出。
link |
如果我們看黃色的這個matrix的左下角,黃色這個matrix的左下角是怎麼來的呢?黃色這個matrix的左下角是從中間產物的左下角來的,中間產物的左下角是從本來feature map的左下角來的。
link |
我們現在在處理這個feature map的時候,我們用的都是這兩個藍色的neural,所以你把同樣這兩個藍色不同input的neural的輸出,再丟給黃色的neural,再得到輸出。
link |
所以你會發現說在dense white separable的convolution裡面,不同的feature它們前面的參數,它們有部分的參數是共用的。就在dense white separable convolution裡面,我們把原來的feature拆解成兩層,而它們的第一層參數是共用的,在第二層採用不同的參數。
link |
那這就是為什麼dense white convolution它可以用比較少的參數,但是可以做到類似的事情。所以不同feature間,我們讓它共用同樣的參數。
link |
好,那我們接下來在理論上算一下,有用dense white separable convolution跟一般的convolution,它們的參數量大概有什麼樣的差距。
link |
我們現在假設i是input channel的數目,o是output channel的數目。在剛才的例子裡面,我們設i等於2,o等於4,k是feature的size,那我們這邊的例子是設3乘以3。
link |
那在一般的convolution裡面,每一個feature的參數量都是k乘以k乘以i,每一個feature都是立體的,你的是curl size是k乘以k,但它是有深度的,它的深度是input channel的數目,也就是i。
link |
那你有幾個output channel,那你就應該要有幾個feature,你有o個output channel,你就應該有o個feature,所以最終一般的convolution,它需要的參數量是k乘以k乘以i,這是每一個feature的參數量,再乘上我們總共需要的o個feature。
link |
那接下來呢,我們再看described separable的convolution,這個新的convolution,這個簡化後的convolution,它需要多少的參數。在第一個步驟,我們說在第一個步驟,我們的feature是沒有深度的,每一個feature只自己管自己的事。
link |
沒有深度的feature,它的參數是k乘以k,如果input有i個channel,那我們需要i個feature,因為有i個channel,所以我們需要i個feature,每一個人去管一個channel,所以是k乘以k乘以i的參數。
link |
接下來在第二步,我們用的是1乘以1的feature,那每一個1乘以1的feature有多少參數呢?如果你input的channel是i的話,那每一個feature就有i個參數,output的channel有多少,我們就需要多少1乘以1的feature,所以這些1乘以1的feature的參數的總量是i乘以o。
link |
所以that's why separable convolution它的參數是k乘以k乘以i再加上i乘以o,那我們可以把這兩者相除,你就可以感受一下這兩種convolution它的參數的差距。
link |
所以我們把that's why separable convolution的參數放在分子的地方,把一般的convolutional的layer的參數放在分母的地方相除,那通常o很大,o是optional的數目,我們通常設個512、128,那只是蠻大的,所以我們不用無視它,我們只考慮1除以k乘以k的這項。
link |
那k你通常設,比如說設3,通常你feature設3乘以3是蠻常見的setup,那如果你設k設3的話,那你network的size就變成原來的1九分之一,你network的參數量就變成原來的1九分之一。
link |
那像這樣的設計,廣泛地被用在今天各種號稱比較小的network裡面,舉例來說squeeze net、mobile net、shuffle net還有exception,那其中我想最知名的就是mobile net,你從它的名字就知道mobile net它就是為了把network放在手機上而設計的,所以叫做mobile net。
link |
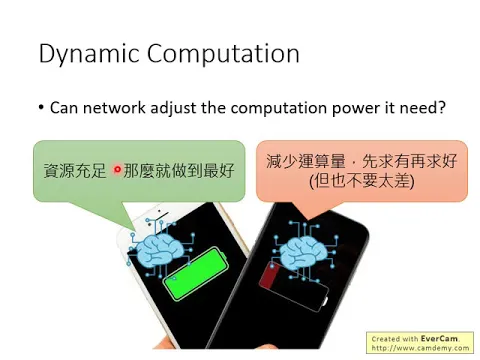
那最後我們要跟大家講的主題,這邊非常的簡短,叫做dynamic computation,那dynamic computation舉例來說,今天你的手機如果電量很不夠的時候,那你的network它可以自動知道我要減少運算量,先求有再求好,雖然說先求有再求好,但是也希望在現有的運算資源上可以盡量做到最好。
link |
另外一方面,如果運算資源很充足,那麼network就使盡全力把它的結果、把它的力量發揮出來。這件事情要怎麼做呢?一個最trivial、最簡單的solution就是,你就train一把network,合成一把network,從最深的到最淺的,從參數最高的到參數最小的,然後接下來再根據你現在device的情境,根據你device現在computing power,選擇一個適當的network。
link |
那這樣做的壞處就是,你需要存一大堆的network,這顯然會非常佔你的儲存空間,尤其是在device上你的儲存空間不太夠,你可能沒有辦法存一打的network,來根據不同的狀況選擇不同的network。
link |
另外一個方法是,我們能不能夠train一個network,但是這個network它可以,如果你給它不同的限制,它都可以做不同的應對。舉例來說,我們可以在一個network的每一個中間的hidden layer都拉出來,就做classify。
link |
所以這個network架構可能長得是這樣子,就是你一般的network有很多層,一直要到最後一層你才會知道結果,但我們能不能夠訓練一些classify,這些classify是把network的中間層拿出來,根據network的中間層就決定結果。
link |
那今天在實作的時候,你只要根據,今天在測試在使用這些network的時候,你就可以根據你的運算資源調整說,你現在到底是要跑完第一層就得到結果,還是要跑完一二層才得到結果,你就可以自由地調整你network需要的運算量。
link |
但是光直接這麼做是不太好的,為什麼?因為你可以想像說,一個network前面幾個layer,它的builder抽的東西都只是很簡單的pattern,一直要到後面的layer,你的CNN抽出來的東西才是比較有用的feature。
link |
前面幾個layer抽出來的只是很簡單的pattern,那你前面幾個layer接出來的那些classify,它的performance可能不是太好。
link |
那在實作上,確實是如此。那這邊我們先忽視NSDnet,也就是黑色這一條線。
link |
這個NSDnet是proposed專門處理這種dynamic computing的network,所以我們就忽視它。我們只看紅色的DenseNet跟藍色的ResNet。
link |
縱軸是正確率,橫軸是每一個階段,從最淺的地方一直到最深的地方,當我們把classify拉出來的時候,那些classify可以得到的正確率。
link |
你發現說,如果你在很淺的地方就把classify拉出來,你的classify吃的是很接近input的hidden layer的output,那些classify的結果都是不太好的,因為在input的時候,那些builder,因為在input的時候,你的CNN抽出來的pattern是很簡單的,所以那些classify沒有辦法做出太厲害的事情。
link |
還有另外一個問題是,你今天在中間加了一些classify,這些classify他們是跟這個networkjointly trained的,這些classify會傷害到原來network的performance,為什麼這些classify會傷害到原來network的performance呢?
link |
我們在講CNN的時候,我們有講過說,CNN比較底層的builder就是抽簡單的pattern,簡單的pattern組合起來才能夠偵測複雜的pattern,但是如果你在第一層就加了一個classify,那這個classify也會想要得到好的正確率。
link |
所以就是強迫說,前面的builder必須要抽一些這個classify可以用來得到正確答案的pattern,那就是破壞整個原來的CNN的佈局,就本來前面只需要抽簡單的東西,再把簡單的東西組成複雜的東西。
link |
但是現在有一個classify,它需要一些複雜的pattern,就會強迫第一個layer本來不該作為抽複雜的pattern,它也強迫它抽一些複雜的pattern,會破壞掉整個CNN的佈局。
link |
所以你會發現說,如果你今天加了一些classify,performance是會掉的。我們看藍色這一條線,藍色這一條線是resnet的結果,縱軸是相對的正確率,橫軸是我們今天在不同的layer加上classify。
link |
如果你在很接近input的地方加一個classify,整個performance就會暴跌,在比較接近output的地方加classify,影響是比較小的。
link |
有沒有方法可以解決這個問題呢?有的,就這些圖其實都是來自於NSDnet這篇paper,那如果你想要知道說dynamic computing怎麼做的話,那NSDnet也許是一個你可以參考的方向,因為今天時間有限,我們就講到這邊就好。