back to index
ML Lecture 1: Regression - Case Study
link |
主題,我們今天要講的是regression,那等一下我會舉一個例子來講regression是怎麼做的呢,順便引出一些machine learning裡面的常見的重要觀念。
link |
好,那regression可以做什麼?除了我們在作業裡面大家要做的預測,P2.5這個任務以外,還有很多其他非常有用的task。
link |
舉例來說,你可以做一個股票預測的系統,如果你要做股票預測的系統的話,你要做的事情就是找一個function。
link |
這個function的input可能是過去十年各種股票的起伏的資料,或者是某些A公司併購B公司,B公司併購C公司等等的資料。那你希望這個function在input這些資料以後,它的output是明天的道瓊工業指數的點數。
link |
如果你可以預測這個的話,你就發了。還有別的task,比如說現在很熱門的無人車、自動車,這個自動車其實也可以想成是一個regression的problem。
link |
regression的problem的input就是你的無人車所看到的各種sensor,它的紅外線感測的sensor,它的影像的視訊的鏡頭所看到的馬路上的東西等等,你的input就是這些information。
link |
output就是方向盤的角度,比如說要左轉50度還是右轉50度,右轉50度你就當作是左轉-50度,所以output也是一個scanner。
link |
所以無人車駕駛其實就是一個regression的problem,input一些information,output就是方向盤的角度,它是一個數字。
link |
或者是你可以做推薦系統,我們都知道說YouTube要推薦影片,或者是Amazon要推薦商品給你。
link |
推薦系統它要做的事情也可以想成是一個regression的問題,就是找一個function,它的input是某一個使用者A和某一個商品B,它的output就是使用者A購買商品B的可能性。
link |
如果你可以找到這樣一個function,它可以精確的預測使用者A購買商品B的可能性的話,那Amazon就會推薦使用者A最有可能購買的商品。
link |
那這個是regression的種種應用,那今天我要講的是另外一個我覺得更實用的應用,就是預測寶可夢的CP值。這個大家知道是什麼意思嗎?我來說明一下好了。
link |
CP值就是一隻寶可夢的戰鬥力。你抓到一隻寶可夢以後,比如說這個是一隻妙蛙種子,然後你給它吃一些星塵或者是糖果以後,它就會進化成妙蛙草。
link |
而進化成妙蛙草以後,它的CP值就變了。為什麼我們會希望能夠預測寶可夢的CP值呢?因為如果你可以精確的預測說一隻寶可夢在進化以後的CP值的話,你就可以評估說你是否要進化這一隻寶可夢。
link |
如果它是一隻CP值比較低的寶可夢的話,你可能就把它拿去做糖果,你就不進化它,這樣你就可以節省一些你的糖果的資源。
link |
那你可能就會問說為什麼我們要節省糖果的資源呢?因為你這樣可以在比較短時間內進化比較多強的神奇寶貝。
link |
你現在不能叫神奇寶貝,這樣暴露我的年齡。你就是進化比較強的寶可夢。你就會想說為什麼我們要有比較強的寶可夢呢?因為它可以去打道館。
link |
你就會問說為什麼我們要打道館呢?其實我也不知道。
link |
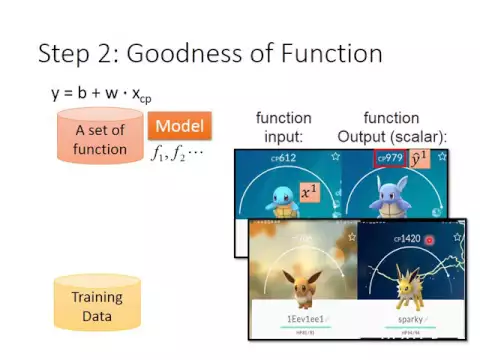
好,那我們今天要做的事情就是找一個function。這個function的input就是某一隻寶可夢,那它的output就是這一隻寶可夢,如果我們把它進化以後,它的CP值的數值是多少。
link |
這是一個regression的problem,我們的input就是某一隻寶可夢所有相關的information,比如說我們把一隻寶可夢用X值來表示,那它的CP值呢,我們就用X下標CP來表示。
link |
我們用下標來表示某一個完整的東西裡面的某一個component,某一個部分,我們用下標來表示。XCP代表某一隻寶可夢X,它在進化前的CP值。
link |
比如說這個妙蛙種子它的CP值是14,那XF代表說這一隻寶可夢X,它是屬於哪一種物種,比如說這是妙蛙種子,那XHP代表說這一隻寶可夢它的HP值是多少,它的生命值是多少。
link |
這邊這個妙蛙種子的生命值是10,XW代表它的重量,XH代表它的高度,那就看看說你抓的寶可夢是不是特別大隻或特別小隻。
link |
那output是進化後的CP,這個進化後的CP值就是一個數值,就是一個scalar,我們把它用Y來表示。好,怎麼解這個問題呢?我們知道說,我們第一堂課就講過做Machine Learning就是三個步驟。
link |
第一個步驟是找一個model,第二個步驟是定義,model就是一個function set,第二個步驟就是定義function set裡面某一個function,我們拿一個function出來可以要evaluate它的好壞,第三個步驟就是找一個最好的function。
link |
首先我們就從第一步驟開始,我們要找一個function set,這個function set就是所謂的model,在這個task裡面,我們的function set應該長什麼樣子呢?
link |
一個input一隻寶可夢,output進化後的CP值的function,應該長什麼樣子呢?我們這邊就先胡亂寫一個簡單的,比如說我們認為說進化後的CP值Y等於某一個常數像B,加上某一個數值W,乘上現在輸入的寶可夢的X,它在進化前的CP值。
link |
這個XCP代表進化前的CP值,這個Y是進化後的CP值。
link |
這個W和B是參數,W和B它可以是任何的數值,在這個model裡面,W和B是未知的,你可以把任何的數值填進去,填進不同的數值,你就得到不同的function。
link |
比如說你可以有一個F1,F1是B等於10,W等於9,你可以有另外一個function F2,這個F2是B等於9.8,W等於9.2。
link |
你有一個F3,這個F3它是B等於-0.8,W等於-1.2。如果今天你的W和B可以帶任何值的話,其實你這個function set裡面可以有無窮無盡的function,有無窮多的function。
link |
那你用這個式子Y等於B加W乘上XCP代表這些function所乘的集合。當然在這些function裡面,比如說F1,F2,F3裡面,你會發現說有一些function顯然是不太可能是正確的,比如說F3不太可能是正確的。
link |
因為我們知道說CP值其實是正的,乘-1.2就變負的,所以進化以後CP值變負的,這樣顯然是說不通的。這個就是我們等一下要靠training data來告訴我們說,在這個function set裡面,哪一個function才是合理的function。
link |
好,那這樣子的model,這個Y等於B加W乘XCP這樣子的model,它是一種linear的model。所謂的linear的model的意思是,簡單來說,如果我們可以把一個function,我們把現在我們要找的function寫成Y等於B加上summation over Wi乘上Xi,那它就是一個linear的function。
link |
在這邊,這個Xi指的是你input的X的各種attribute,比如說你input的寶可夢的各種不同的屬性,比如說身高、體重等等。
link |
這些東西我們叫做feature,從input的object裡面抽出來的各種數值當作function的input,這些東西叫做feature。那這個Wi跟B,這個Wi叫做weight,這個B叫做bias。
link |
接下來,我們要收集training data才能夠找這個function。這是一個supervised learning test,所以我們收集的是function的input和function的output。因為是regression test,所以function的output是一個數值。
link |
舉例來說,你就抓了一隻,這個是傑尼龜,進化以後,這個是卡咪龜。這個function的input在這邊就是這隻傑尼龜,那我們用X1來表示它。
link |
我們用上標來表示一個完整的object的編號,我們剛才有看到說我們用下標來表示一個完整object裡面的component,我們用上標來表示一個完整的object的編號。
link |
所以這是第一個X,這是一隻傑尼龜。那它進化以後的cp是973,所以我們的function的output應該看到X1,就output數值973。這個973,我們用Y1 hat來代表。
link |
這邊用Y來代表function的output,用上標來代表一個完整的個體。因為我們今天考慮的output是scalar,所以它其實裡面沒有component,它就是一個簡單的數值。
link |
但是我們未來如果在考慮structured learning的時候,我們output的object可能是有structure的,所以我們還是會需要上標下標來表示一個完整的output的object,還有它裡面的component。我們用Y hat1來表示這個數值979。
link |
只有一隻不夠,要收集很多,再抓一隻伊布。伊布就是X2,它進化以後可以變成雷精靈。雷精靈的cp值是1420,這個1420就是Y2 hat。
link |
我們用hat來代表說這個是一個正確的值,是我們實際觀察到function該有的output。你可能以為說這只是一個例子,這不只是一個例子,我是有真正的data的。
link |
今天其實我是想要發表我在神奇寶貝上面的研究成果,有兩百多人來聽我真的太高興了。我們就收集了十隻神奇寶貝。
link |
這十隻神奇寶貝呢,又說錯了,我們收集了十隻寶可夢。這十隻寶可夢就是從編號1到編號10。那每一隻寶可夢我們都讓它進化以後,我們就知道它進化後的cp值,就是Y1 hat到Y10 hat,這個是真正的data。
link |
你可能會問說,怎麼只抓十隻呢?你不覺得抓這個很麻煩嗎?其實老實說這個我也不是我自己抓的,網路上有人分享他抓出來的數據,我拿他的數據來做一下。
link |
其實他也沒有抓太多隻,因為你知道抓這個其實是很麻煩的,一抓來以後,並不抓來就好,你要把它進化以後,你才知道說function的output是多少,所以收集這個data並沒有那麼容易。
link |
所以就收集了十隻神奇寶貝,它進化後的cp值。如果我們把這十隻神奇寶貝的information畫出來的話,這個圖上每一個藍色的點代表一隻寶可夢。
link |
然後它的X軸代表的是這一隻寶可夢的cp值,這個我們一抓來的時候就知道了。然後它的Y軸代表說如果你把這一隻寶可夢進化後的cp值,這個用Y hat來表示。
link |
所以十隻寶可夢,所以這邊我們有十個點啦,確實有十個點,1、2、3、4、5、6,這邊其實有三個點,7、8、9、10。
link |
這個cp值其實就特別高,這隻其實是伊布。伊布不是很容易抓。
link |
那這邊每一個點呢,就是某第n隻寶可夢的cp值,跟它進化以後的Y hat。那我們用X上標n下標cp,來代表第n筆data它的某一個component,也就是它的cp值。
link |
好,那接下來呢,我們就要有了這些training data以後,我們就可以定義一個function的好壞,我們就可以知道說一個function是多好或是多不好,我們知道說這裡面每一個function它是多好還是多不好。
link |
怎麼做呢?我們要定義另外一個function,叫做loss function,這邊寫成大寫的L。我們在這邊已經有一大堆的function,我們這邊定了一個function set,這裡面有一大堆的function,那這邊我們要再定另外一個function。
link |
這個另外一個function呢,叫做loss function,我們寫成大寫的L。這個loss function的input,它是一個很特別的function。這個loss function呢,它是function的function。大家了解我的意思嗎?它的input就是一個function。
link |
它的output就是一個數值告訴我們說,現在input的這個function,它有多不好。我們這邊是用多不好來表示。所以這個loss function,它是一個function的function,它就是吃一個function當作input,它的output就是這個function有多不好。
link |
所以你可以寫成這樣,這個L它的input就是某一個function f,你知道一個function呢,它又是由這個function裡面的兩個參數b跟w來決定的,這個f是由b跟w來決定的,所以input f就等於是input這個f裡面的b跟w。
link |
所以你可以說,這個loss function,它是在衡量一組參數的好壞,衡量一組b跟w的好壞。那怎麼定這個loss function呢?其實這個loss function,你其實可以隨自己的喜好定一個你覺得合理的function。
link |
不過這邊我們就用比較常見的做法,怎麼定呢?你就把這個input的w跟b呢,你就把這個input的w跟b呢,實際的代入這個y等於b加wxcp這個function裡面。
link |
你把w乘上第n隻寶可夢的cp值,再加上這個constant b,然後你就得到說,如果我們使用這一組w,這一個w跟b,來當作我們的function,來預測寶可夢它進化以後的cp值的話,這個預測的值y的數值是多少。
link |
所以這個裡面的括號,裡面的括號,比較小的括號,它輸出的數值是我們用現在這個function來預測的話,我們得到的輸出是什麼?
link |
那y hat是真正的數值,我們把真正的數值減掉預測的數值再取平方,真正的數值減掉預測的數值再取平方,這個就是估測的誤差。
link |
再把我們手上的十隻寶可夢的估測誤差都合起來,就得到這個loss function。這個定義我相信你是不太會有問題的,因為它非常的直覺。如果我使用某一個function,它給我們的估測誤差越大,那當然這個function就越不好。
link |
所以我們就用估測誤差來定義一個loss function,當然你可以選擇其他的可能性。再來我們有了這個loss function以後,我們這邊如果你還是有一些困惑的話,我們可以把這個loss function的形狀畫出來。
link |
這個loss function L of WB,它input就是兩個參數WB,所以我們可以把這個L of WB對W跟B把它做圖,把它畫出來。
link |
在這個圖上的每一個點就代表了一個組WB,也就是代表了某一個function,比如說紅色這個點,紅色這個點就代表了這個B等於-180,W等於-2的時候所得到的function,就y等於-180-2乘以xcp這個function。
link |
在這個圖上每一個點都代表了一個function,而這個顏色代表了現在如果我們使用這個function,根據我們定義的loss function,它有多糟糕,它有多不好。
link |
這個顏色越偏紅色代表數值越大,所以在這一群的function,它的loss非常大,也就是它們是一群不好的function。最好的function落在哪裡呢?越偏藍色代表那個function越好。
link |
所以最好的function其實落在這個位置,如果你選這個function的話,它是可以讓你loss最低的一個function。
link |
接下來我們已經定好了我們的loss function,可以衡量我們的model裡面每一個function的好壞,接下來我們要做的事情就是從這個function set裡面挑選一個最好的function。
link |
所謂挑選最好的function這一件事情,如果你想要把它寫成formulation的話,如果你想要把它寫成equation的話,寫起來是什麼樣子呢?
link |
它寫起來就是,我們定的loss function長這樣,你要找一個f,它可以讓L of f最小,這個可以讓L of最小的function,我們就寫成f star。
link |
可是我們知道f是由兩個參數w和b來表示,今天要做的事情就是窮取所有的w和b,看哪一個w和b代入L of wb,可以讓這個loss的值最小。
link |
這個w和b就是最好的w和b,寫成w star和b star,或者是我們把L這個function列出來,L這個function我們知道它長的就是這個樣子,那我們就是把w和b用各種不同的數值帶到這個function裡面,看哪一組w和b可以給我們最好的結果。
link |
如果你修過線性代數的話,其實這個對你來說應該完全不是問題,這個是有closed form solution的,雖然我相信你可能不記得它長什麼樣子了。
link |
所謂的closed form solution的意思是說,你只要把十隻寶可夢的cd值跟他們進化後的y hat,你只要把這些數值帶到某一個function裡面,它output就可以告訴你說最好的w和b是什麼。
link |
如果你修過線代的話,其實你理論上應該是知道要怎麼做的。
link |
我假設你已經忘記了,我們要教你另外一個做法,這個做法叫做gradient descent。
link |
這邊要強調的就是,gradient descent不是只適用於解這個function,解這個function是比較容易的,你有修過線代你其實就會了。
link |
但是gradient descent它厲害的地方是,只要你這個LOR是可為分的,不管它是什麼function,gradient descent都可以拿來處理這個function,都可以拿來幫你找可能是比較好的function或者是參數。
link |
我們來看一下gradient descent是怎麼做的。我們先假設一個比較簡單的test,在這個比較簡單的test裡面,我們的loss function L of w,它只有一個參數w。
link |
這個L of w必然是不需要是我們之前定出來的那個loss function,它可以是任何function,只要是可為分的就行了。
link |
我們現在解的問題是,找一個w讓這個L of w最小。這件事情怎麼做呢?暴力的方法就是窮舉所有w可能的數值,把所有w可能的數值從負無限大到無限大,一個一個值都帶到loss function裡面去,試一下這個loss function的value,你就會知道說哪一個w的值可以讓loss最小。
link |
如果你做這件事的話,你就會發現說,比如說這裡,這個w的值可以讓loss最小,但是這樣做是沒有效率的。怎麼做比較有效率呢?這個就是gradient descent要告訴我們的。
link |
這個做法是這樣子的。我們首先呢,先隨機選取一個初始的點。我們先隨機選取一個初始的點,我們這邊隨機選取的是w0。那其實你也不一定要隨機選取,其實有可能有一些其他的方法可以讓你找的值是比較好的。
link |
這個字後代替,那現在就想成是隨機選取一個初始的點,w0。接下來呢,在這個初始的w0這個位置呢,我們去計算一下w這個參數對l的這個,跳出來了,又跳回去了。
link |
好,我們要計算這個在w等於w0這個位置,參數w對loss function的微分。如果你對微分不熟的話,反正我們這邊找的就是切線斜率。
link |
好,如果今天這個切線斜率是負的的話,那顯然就是,從這個圖上就很明顯看到,如果切線斜率是負的的話,顯然左邊loss是比較高的,右邊loss是比較低的。
link |
那我們要找loss比較低的function,所以你應該增加你的w值,你應該增加w0的值。反之呢,如果今天是正的,算出來斜率是正的,代表跟這條曲線反向,也就是右邊高左邊低的話,那我們顯然就應該減少w的值,把我們的參數往左邊移動,把我們的參數減小。
link |
或者是,假如你對微分也不熟,切線也不熟的話,那你就想成是有一個人站在w0這個點,那他往前後各窺視一下,看一下他往左邊走一步loss會增加,還是往右邊走一步loss會減少,還是往右邊走一步loss會減少。
link |
如果往右邊走一步loss會減少的話,那他就會往右邊走一步。總之在這個例子裡面呢,我們的參數是會增加的,會往右邊移動。那怎麼增加呢?應該要增加多少呢?
link |
這邊的增加量,我們寫成,有關Gradient Descent的這個theory,我們留到下次再講,我們今天就講一下它的操作是什麼樣子。而如果我們往右邊踏一步的話,應該要踏多少呢?這個踏一步的step size取決於兩件事。
link |
第一件事情是,現在的微分值有多大?現在的底w分之底l有多大?如果微分值越大,代表現在在一個越陡峭的地方,那它移動的距離就越大,反之就越小。
link |
那還取決於另外一件事情,這個另外一件事情呢,是一個常數項。這個常數項這個eta呢,我們把它叫做learning rate。這個learning rate決定說,我們今天踏一步不只是取決於我們現在微分值算出來有多大,還取決於我們一個事先就定好的數值。
link |
這個learning rate是一個事先定好的數值,如果這個事先定好的數值你給它定大一點的話,那今天踏出一步的時候,參數更新的幅度就比較大,反之參數更新的幅度就比較小。
link |
那如果參數更新的幅度比較大的話,learning rate是大一點的話,那學習的效率、學習的速度就比較快。所以這個參數eta呢,我們就稱之為learning rate。所以現在我們已經算出,在w0這個地方,我們應該要把參數更新eta乘上底w分之底l。
link |
所以你就把原來的參數w0減掉呢,eta乘以底w分之底l。這邊會有一項減的,因為如果我們這個微分算出來是負的的話,要增加這個w的值。
link |
如果算出來是正的的話,要減少w的值。所以這一項微分值跟我們要增加減少是反向的,所以我們前面要乘一個負號。好,那我們把w0更新以後變成w1。
link |
接下來呢,就是重複剛才看到的步驟,重新去計算一次,在w等於w1這個地方,所算出來的微分值。假設呢,這個微分值算出來是這樣子,那這個微分值仍然建議我們呢,應該往右移動我們的參數。
link |
只是現在移動的幅度呢,可能是比較小的,因為這個微分值呢,相較於前面這一項呢,是比較小的。好,那你就把w1呢,減掉eta乘上這個微分值,然後變成呢,w2。
link |
那這個步驟就反覆不斷的執行下去,經過這個非常非常多的iteration以後,經過非常多次的參數更新以後呢,就到了,假設經過t次的更新,這個t是一個非常大的數字,最後你會到一個local minima的地方。
link |
所謂local minima的地方就是,這個地方的微分是零,所以呢,你接下來算出來的微分都是零的,所以你的參數就會卡在這邊,就沒有辦法再更新了。
link |
那這件事情你可能會覺得,嗯,不太高興,因為這邊其實有一個local minima,因為你找出來的這個solution,你找出來的參數,它其實不是最佳解。
link |
你只能找到local minima,你沒有辦法找到local minima。但幸運的是,這件事情在regression上面呢,不是一個問題。
link |
因為在regression上面呢,在linear regression上面呢,它是沒有local minima,等一下這個事情呢,我們會再看到。
link |
好,那今天我們剛才討論的是只有一個參數的情形,那如果是有兩個參數呢,我們今天真正要處理的問題是有兩個參數的問題,也就是w跟b。
link |
那其實有兩個參數,從一個參數推廣到兩個參數,其實是沒有任何不同的。
link |
首先呢,你就隨機選取兩個初始值,w0跟b0。接下來呢,你就計算在w等於w0,b等於b0的時候,w對loss的偏微分。
link |
你在計算w等於w0,b等於b0的時候,b對l的偏微分。好,接下來呢,你計算出這兩個偏微分以後,你就分別去更新w0和b0這兩個參數。
link |
你就把w0減掉eta,乘上w對l的偏微分,得到w1。你就把b0減掉eta,乘上b對l的偏微分,你就得到b1。
link |
好,那這個步驟呢,你就反覆的持續下去,你就接下來呢,你算出b1和w1以後,你就再計算一次w對l的偏微分。只是現在是計算w等於w1,b等於b1的時候的偏微分,所以這項偏微分跟這項偏微分的值不是一樣,是在不同位置算出來的。
link |
接下來,你有了w1跟b1以後,你就計算w1和b1,在w等於w1,b等於b1的時候,w對l的偏微分,還有w等於w1,b等於b1的時候,b對l的偏微分。
link |
接下來你就更新參數,你就把w1減掉eta,乘上算出來的微分值,你就得到w2。你把b1減掉eta,乘上微分值,你就得到b2。你就反覆進行這個步驟,最後你就可以找到一個loss,相對比較小的w值跟b的值。
link |
這邊要補充說明的是,所謂的Gradient Descent的Gradient指的是什麼呢?其實Gradient就是這個倒三角l。我知道大家已經很久沒有學微積分了,所以我猜你八成不記得倒三角l是什麼。
link |
這個倒三角l就是你把w對l的偏微分和b對l的偏微分排成一個vector,這一項就是Gradient。因為我們在這個整個process裡面,我們要計算w對l的偏微分和b對l的偏微分,這個就是Gradient。
link |
所以這門課裡面,如果沒必要的話,我們就盡量不要把這個大家不熟悉的符號弄出來,只是想要讓大家知道一下說,Gradient指的就是這個東西。
link |
我們來visualize一下剛才做的事情。剛才做的事情像是這樣,有兩個參數w和b,這兩個參數決定了一個function長什麼樣。在這個圖上的顏色代表loss function的數值,越偏藍色代表loss越小。
link |
那我們隨機選取一個初始值,比如說隨機選取的初始值是在左下角紅色的點這個地方。
link |
接下來你就去計算在紅色這個點b對loss的偏微分,還有w對loss的偏微分。然後你就把參數更新eta乘上b對loss的偏微分,還有eta乘上w對loss的偏微分。
link |
如果你對偏微分比較不熟的話,其實這個方向,這個方向,這個Gradient的方向,這個方向其實就是等高線的髮線方向。
link |
那我們就可以更新這個參數從這個地方到這個地方。接下來你就再計算一次偏微分,這個偏微分告訴你說現在應該往這個方向更新你的參數。
link |
就把你的參數從這個地方移到這個地方。接下來它再告訴你說應該這樣走,然後你就把參數從這個地方再更新到這個地方。那Gradient Descent有一個讓人擔心的地方。
link |
就是如果今天你的loss function長得是這個樣子,如果今天w和b對這個loss l看起來是這個樣子,那你就麻煩了。
link |
這個時候如果你的隨機取始的值是在這個地方,那按照Gradient建議你的方向,按照今天這個偏微分建議你的方向,你走走走走走,你就找到這個方向。如果你隨機取始的地方是在這個地方,那根據Gradient的方向你走走走走,就走到這個地方。
link |
就變成說這個方法你得到的結果是看人品的。這個讓人非常非常擔心。但是在linear regression裡面,你不用太擔心。
link |
為什麼呢?因為在linear regression裡面,你的loss function l,它是convex的。如果你定義你的loss的方式跟我在前幾個投影片講的是一樣的話,那那個loss是convex的。
link |
所謂的,如果你不知道convex是什麼的話,換句話說就是,它是沒有local的optimal的位置的。或者是,如果我們把圖畫出來的話,它長得就是這樣子。
link |
它的等高線呢,就是一圈一圈橢圓形的。所以它是沒有local optimal的地方。所以你從隨便選一個起始點,根據Gradient descent所幫你找出來的最佳的參數,你最後找出來的呢,都會是同一組參數。
link |
好,那在下課休息一下之前呢,我們來看一下它的formulation。其實這個式子是非常簡單的。假如你要實際算一下w對l的偏微分和b對l的偏微分,這個式子長的是什麼樣子呢?
link |
這個式子長什麼樣子呢?這個l呢,我們剛才已經看到了,它是長這個樣子。它是估測誤差的平方和。那如果我們把它對w做偏微分,我們得到什麼樣的式子呢?
link |
這個其實非常簡單,我相信有秀過微積分的人都可以秒算。你就把這個2移到左邊,對不對?你要對那個w做偏微分嘛,你就先把括號裡面這一項先做偏微分,把2移到左邊,你得到這樣子的結果。
link |
接下來考慮括號裡面的部分。括號裡面的部分,只有負的w乘上xc上標n下標cp這一下,是跟w有關的。
link |
所以如果你把括號裡面這個equation對w做偏微分的話,你得到的值就是負的x上標n下標cp。所以,partial w, partial l,w對l的偏微分,它的式子就長這個樣子,是非常簡單的。
link |
如果你要算b對l的偏微分的話,也非常簡單。你就把2移到前面,把2移到前面,變成這個樣子。然後你再把括號裡面的值對b做偏微分,括號裡面只有負b這一下,跟我們要偏微分的這個b有關。
link |
所以負b,對b做偏微分得到的值是負1,然後就結束了。所以有了Gradient Descent,你又知道說怎麼算偏微分,那你就可以找一個最佳的function。
link |
好,其實這樣,我本來想要做一個demo,但是我現在連不到那個系中的ipython,所以就算了。
link |
就是說,其實這個問題的Gradient Descent並沒有你想像的那麼好解。你可能覺得說Gradient Descent是一個很trivial的問題,尤其是現在的function又是convex的,應該就秒做吧。
link |
你可以在作業的時候自己體驗看看。事實上,剛才那個10個example problem是出了一些狠招才把它解消的。
link |
那結果怎麼樣呢?其實就是這樣啦。我們的model漲價,然後費盡一番功夫以後,你找出來的最好的b跟w,根據training data分別是b等於-188.4,w等於2.7。
link |
如果你把這個function y等於b加w的xcp,把它的b跟w值畫在圖上的話,它長得是這個樣子,就是這條紅色的線。
link |
那你可以計算一下,你會發現說這條紅色的線沒有辦法完全正確的predict所有的寶可夢的進化後的cp值。
link |
如果你想要知道它做得有多不好的話,或者是多好的話,你可以計算一下你的error。
link |
你的error就是你計算一下每一個藍色的點跟這個紅色點之間的距離。
link |
第一個藍色的點跟紅色的線之間的距離是1萬,第二個藍色的點跟紅色的線之間的距離是1-2,以此類推,所以有1萬到1-10。
link |
那平均的training data的error就是summation 1萬到1-10,這邊算出來是31.9。
link |
但是這個並不是我們真正關心的,因為你真正關心的是generalization的case,也就是說,假設你今天抓到一隻新的寶可夢頭,
link |
如果使用你現在的model去預測的話,那做出來你的估測的誤差到底有多少?
link |
所以真正關心的是那些你沒有看過的新的data,這邊我們叫做testing data,它的誤差是多少?
link |
所以這邊又抓了另外10隻寶可夢當作testing data,這10隻寶可夢跟之前拿來做訓練的10隻不是同樣的10隻。
link |
那其實這新抓的10隻跟剛才看到的10隻的分佈其實是還蠻像的啦,他們就是這個圖上的10個點。
link |
那你會發現說我們剛才在訓練資料上找出來的這條紅色的線,其實也可以大致上預測在我們沒有看過的寶可夢上,它的進化後的CP值。
link |
那如果你想要知道它,你要量化它的錯誤的話,就計算一下它的錯誤,它錯誤算出來是多少呢?算出來是35.0。
link |
那這個值呢,是比我們剛才呢,在這個training data上面看到的error呢,還要稍微大一點。
link |
因為你可以想像我們最好的function是在training data上面找到的啊,所以在training data上面算出來的error本來就應該比testing data上面算出來的error呢,還要稍微大一點。
link |
好,那有沒有辦法做得更好呢?那如果你想要做得更好的話,接下來你要做的事情就是重新去設計你的model。
link |
如果你觀察一下data,你會發現說呢,在原進化前的CP值特別大的地方,還有進化前的CP值特別小的地方,預測是比較不準的。
link |
在這個地方跟這個地方,預測是比較不準的。那你可以想想看說,這個任天堂在做這個遊戲的時候呢,它背後一定是有某一隻程式去根據某一些hidden的factor,比如說根據原來的CP值還有其他一些數值,generate進化以後的數值。
link |
所以呢,我們到底它的function長什麼樣子?從這個結果看來,那個function可能不是這樣一條直線,它可能不是這樣一條直線,它可能是稍微更複雜一點。
link |
那所以呢,我們需要有一個更複雜的model。舉例來說,我們這邊可能需要引入二次式,我們今天可能需要引入xcp平方這一項。我們重新設計了一個model,這個model呢,它寫成y等於b加w1乘以xcp,加w2乘以xcp的平方,我們加了後面這一項。
link |
如果我們有了這個新的function,你可以用我們剛才講的一模一樣的方式去define一個function的好壞,然後用gradient descent找出一個在你的function set裡面最好的function。
link |
那根據training data找出來最好的function是b等於-10,w1等於10,w2等於2.7乘以10的-3次方。如果我們把這個最好的function畫在這個圖上的話,它長得是這個樣子。
link |
所以你就會發現說呢,現在我們有了這一條新的曲線,我們有了這個新的model,它的預測呢,在training data上面看起來是更準一點。在training data上,你得到的average error現在是15.4。
link |
但我們真正關心的是testing data,那我們就把同樣的model,在apply到testing data上,我們在testing data上apply同樣這條紅色的線,然後去計算一下它的average error,那我們現在得到的是18.4。
link |
剛才呢,如果我們沒有考慮XDP的平方的時候,算出來的average error是30左右,現在呢,有考慮平方下來以後,得到的是18.4。那有沒有可能做得更好呢?
link |
比如說我們可以考慮一個更複雜的model,我們引入不只是XDP的平方,我們引入XDP的三次方。所以我們現在的model長得是這個樣子。
link |
那你就用一模一樣的方法,你就可以根據你的training data,找到在這個function set裡面,在這個model裡面最好的一個function。那找出來是這樣,b等於6.4,w1等於0.66,w2是4.3乘以12-3四方,w3是12-6四方。
link |
所以發現w3其實是它的值比較小,它可能是沒有太大的影響。做出來的這個線呢,其實跟剛才看到的二次的那個線呢,是沒有太大的差別的。
link |
把它做出來看起來像是這個樣子。好,那這個時候,average error算出來是15.3。那如果你看testing data的話,testing data算出來的average error呢,是18.1。跟剛才二次的,有考慮CP二次的那個結果比起來是稍微好一點點啦。
link |
剛才前一頁是18.3,有考慮三次項,變成18.1,是稍微好一點點。那有沒有可能是更複雜的model呢?或許在寶可夢的那個程式背後,它產生這個進化後的CP值,用的是一個更複雜的function。
link |
或許它不只考慮了三次,或許它不只考慮了XCP的三次方,或許它考慮的是四次方,也說不定。
link |
好,那你就用同樣的方法呢,再把這些參數,b,w1,w2,w3,w4都找出來,那你得到的function呢,長這個樣子。你會發現說它在training data上,它顯然可以做得更好。在input的這個CP值比較小的這些寶可夢,這些顯然是一些綠毛蟲之類的東西。
link |
這顯然是一些綠毛蟲。那它在這邊呢,是predict更準的。所以現在的average error是14.9,剛才三次的時候是15點多,剛才三次的時候在training data上是15點多,現在在training data上,四次的時候在training data上是14.9。
link |
但是我們真正關心的是testing,我們真正關心的是如果沒有看過的寶可夢,我們能夠多精確地預測它進化後的CP值。所以我們發現說呢,如果我們看沒有看過的寶可夢的話,我們得到的average error是多少呢?我們得到的average error其實是28.8。
link |
那我們前一頁做出來已經是18.3了,我們用三次的時候,在testing data上做出來是18.3。但是我們換了一個更複雜的model以後,做出來呢,是28.8。結果又變得更糟了,我們換了一個更複雜的model,在training data上給我們比較好的結果,但在testing data上看起來結果是更糟。
link |
那如果換再更複雜的model會怎樣呢?有沒有可能是五次式?有沒有可能它背後的程式是如此的複雜?它考慮了原來的CP值一次,兩次,三次,四次到五次。
link |
那這個時候呢,我們把這個最好的function找出來,那你會發現說它的這個最好的function在training set上長得像是這樣子。這個是一個合理的結果嗎?你會發現說,在原來的CP值是500左右,500左右可能就是一步之類的東西。
link |
在原來的CP值是500左右的寶可夢,根據你現在的model預測出來,它的CP值居然是負的。但是在training data上面,我們可以算出來的error是12.8,比我們剛才用四次式得到的結果又再更好一些。
link |
那在testing結果上是怎樣呢?如果我們把這個我們找出來的functionapply到新的寶可夢上面,你會發現說結果整個爛掉了,至少這一支大概是一步吧,這一支一步,它的預測出來的進化後的CP值是非常的不準。照理說應該有1000多,但是你的model卻給它一個負的預測值。
link |
所以算出來的average error非常大,有200多。當我們換了一個更複雜的model,考慮到五次的時候,結果又更加糟糕了。
link |
所以我們到目前為止,我們試了五個不同的model。那這五個model,如果你把它們分別在training data上面的average error都畫出來的話,你會得到這樣子的一張圖,從高到低。
link |
也就是說,如果你考慮一個最簡單的model,這個時候error是比較高的。model稍微複雜一點,error稍微下降。然後model越複雜,error在training data上的error就越來越小。
link |
為什麼會這樣呢?這件事情倒是非常的直覺,非常容易解釋。假設黃色的這個圈圈,我們故意用一樣的顏色。黃色這個圈圈代表這個式子有考慮三次的式子所形成的function space。
link |
那四次的式子所形成的function space就是這個綠色的圈圈。它是包含黃色的圈圈的。這個事情很合理,因為你只要把w4設為0,四次的這個式子就可以變成三次的式子。
link |
所以三次的式子都包含在這個四次的式子裡面,黃色的圈圈都包含在綠色的圈圈裡面。那如果我們今天考慮更複雜的五次的式子的話,它又可以包含所有四次的式子。
link |
那所以呢,如果今天你有一個越複雜的model,它包含了越多的function的話,那理論上呢,你就可以找出一個function,它可以讓你的error rate越來越低。
link |
你的function如果越複雜,你的candidate越多,你當然可以找到一個function,讓你的error rate越來越低。當然這邊的前提就是,你的那個gradient descent要能夠真正幫你找出best function的前提之下,你的function越複雜呢,可以讓你的error rate在training data上越低。
link |
但是在testing data上面呢,看起來的結果是不一樣的。在training data上,你會發現說model越來越複雜,你的error越來越低。但是在testing data上,在到第三個式子為止,你的model呢,error是有下降的。
link |
但是呢,到第四個和第五個function的時候,error就暴增了,然後把它的圖呢,試著畫在左邊這邊。藍色的是training data上對不同function的error,橙色的是testing data上對不同function的error。
link |
你會發現說,今天在五次的時候呢,在testing上是爆炸的,它就突破天際,我沒辦法畫在這個圖上面。好,那所以我們今天呢,得到一個觀察。雖然說越複雜的model可以在training data上面給我們越好的結果,但這件事情也沒有什麼,因為越複雜的model並不一定能夠在testing data上給我們越好的結果。
link |
這件事情呢,就叫做overfitting。就複雜的model,在training data上有好的結果,在testing data上不一定有好的結果,這件事情呢,叫做overfitting。
link |
比如說,當我們用第四個和第五個式子的時候,我們就發生overfitting的情形。那為什麼會有overfitting這個情形呢?為什麼更複雜的model,它在training上面得到比較好的結果,在testing上面不一定會得到比較好的結果呢?這個我們日後再解釋。
link |
但是你其實可以想到很多很直觀的,在training data上得到比較好的結果,在訓練的時候得到比較好的結果,但在測試的時候不一定有比較好的結果的例子。比如說,你有沒有考過駕照?考駕照不是都要去駕訓班嗎?駕訓班不是都是在場內練習嗎?
link |
在場內練習的時候不是都很順,練習了非常非常多次以後,你就會學到很奇怪的技能,你就會學到說,比如說當我後照鏡裡面看到路邊小丸子的貼紙對到正中間的時候,就把方向盤左轉半圈這樣子,你就學到這種技能。
link |
所以你在測試訓練的時候,在駕訓班裡面可以做得很好,但在路上的時候你就做不好,這樣我就不太會開車,雖然我有駕照,所以我都在等無人駕駛車出來。
link |
所以overfitting是很有可能會發生的,所以model不是越複雜越好,我們必須要選一個剛剛好,沒有太複雜,也沒有非常不複雜,也沒有很複雜的model,你要選一個最適合的model。
link |
比如說在這個case裡面,當我們選一個三次式的時候,在這個case裡面當我們選一個三次式的時候,可以給我們最低的error。
link |
所以如果今天可以選的話,我們就應該選那個三次的式子來作為我們的model,來作為我們的function set。
link |
你以為這樣就結束了嗎?其實還沒有,剛才只收集了十隻寶可夢,其實太少了。當我們收集到六十隻寶可夢的時候,你會發現說,剛才都是白忙一場。
link |
你仔細想,當我們收集六十隻寶可夢,你把它的原來的CP值跟進化後的CP值畫在這個圖上,你會發現說,它們中間有一個非常奇妙的關係,它顯然不是一次二次三次一百次四,顯然都是。
link |
中間有另外一個力量,這個力量不是CP值,它在影響著進化後的數值。到底是什麼呢?其實非常直覺,就是寶可夢的物種。
link |
這邊我們把不同的物種用不同的顏色來表示,藍色是波波進化是比比鳥,比比鳥進化是大比鳥。
link |
大比鳥,沒錯,我沒有收錯,如果我有收錯就請指正我。黃色的,我故意跟寶可夢用一樣的顏色,黃色的點是獨角蟲,獨角蟲進化是鐵殼昆,鐵殼昆進化是大針鋒。
link |
綠色的是綠毛蟲,綠毛蟲進化是鐵甲蛹,鐵甲蛹進化是八大蟲。紅色的是伊布,伊布可以進化成雷精靈、火精靈或水精靈等等。
link |
你可能會說怎麼都只有這種路面就可以見到的,因為抓乘龍拜里是很麻煩的,所以就只有這些而已。所以剛才只考慮CP值這件事,只考慮進化前的CP值顯然是不對的。
link |
進化後的CP值受到物種的影響其實是很大的,它是有非常關鍵性的影響。所以我們在設計model的時候,剛才那個model設計的是不好,
link |
剛才那個model就好像是你想要海底撈針,從function set裡面撈一個最好的model,其實裡面的model通通都不好,針根本就不在海裡,所以你要重新設計一下你的function set。
link |
所以這邊就重新設計一下function set,我們function set inputX跟outputY,這個input寶可夢跟output進化後的CP值有什麼關係呢?它的關係是這樣,如果今天輸入的寶可夢X的物種是屬於波波的話,
link |
這個Xs代表說這個inputX的物種,那它的這個輸出Y就等於B1加上W1乘以Xcp,那如果它是獨角蟲的話,Y就等於B2加W2乘以Cp,如果它是羽毛蟲的話,就是B3加W3乘以Cp,
link |
如果它是伊布的話,就用另外一個式子,也就是不同的物種,我們就看它是哪一個物種,我們就帶不同的linear function,然後得到不同的Y作為最終的輸出。
link |
你可能會問一個問題說,你把if放到整個function裡面,這樣你不就不是一個linear model嗎?這個function裡面有if你搞得定嗎?你可以用微分來做嗎?你可以用剛才那個gradient descent來算參數對loss的方向微分嗎?
link |
其實是可以的,這個式子你可以把它改寫成一個linear function,寫起來就是這樣。這個有一點複雜,但沒有關係,我們先來看一下delta這個function,如果你有學過信號的處理,我想應該知道delta這個function是什麼。
link |
delta這個function的意思是說delta of Xs等於BB鳥的意思就是說,假如我們今天輸入的這隻寶可夢是BB鳥的話,這個delta function的output就是1。
link |
反之如果是其他種類的寶可夢的話,它delta function的output就是0。所以我們可以把剛才那個有if的式子寫成像這邊這個樣子。
link |
從進化後的cp值等於B1乘上deltaBB鳥,加上W1乘上deltaBB鳥乘上這隻寶可夢的cp值,加上B2乘上delta獨角蟲,加上W2乘上delta獨角蟲,再乘上它的cp值。
link |
接下來考慮綠毛蟲,接下來考慮伊布。你可能會想說這個跟剛才那個式子哪裡一樣呢?你想想看,假如我們今天輸入的那一隻神奇寶貝,
link |
假如我們輸入的那隻寶可夢是BB鳥的話,假如xs等於BB鳥的話,意味著這兩個delta function會是1。這兩個delta function如果input是BB鳥的話就是1。
link |
其他delta function就是0。那乘上0的象就當作沒看到,就變成y等於B1加W1乘上cp。所以對其他物種,其他種類的寶可夢來說也是一樣。
link |
所以當我們設計這個function的時候,我們就可以做到我們剛才在前頁design的那一個有if的function。這個function它就是一個linear function。
link |
也就是說前面這個B1W1到B4W4就是我們的參數,而後面這一項delta或者是deltaxcp,不同的delta跟不同的deltaxcp就是後面這個xi這一項feature。
link |
藍色框框裡面的這些其實就是feature,所以這個東西它也是linear model。那有了這些以後,我們做出來的結果怎麼樣呢?
link |
這個是在training data上面的結果。在training data上面,我們知道說現在不同種類的寶可夢,它用的參數就不一樣。所以不同種類的寶可夢,它的線是不一樣的。
link |
它的model的那一條line是不一樣的。藍色這一條線是BB鳥的線,綠色這一條線是綠毛蟲的線,黃色那個獨角蟲的線跟綠毛蟲的線其實是重疊的。
link |
紅色這一條線是伊布的線。所以可以發現說,當我們分不同種類的寶可夢來考慮的時候,我們的model在training data上面可以得到更低的error。
link |
是把training datafit得更好,是把training data解釋得更好。如果我們這麼做,有考慮到寶可夢種類的時候,我們得到的error是3.8,在training data上。
link |
然後預測新看到的寶可夢,就是testing data上面的結果。在testing data上面,它的結果是這個樣子。一樣是這三條線,可以發現說,它也把在testing data上面的那些寶可夢fit得很好。
link |
它的average error是14.3,比我們剛才可以做好的18點多還要更好。但是如果你在觀察這個圖的話,感覺應該是還有一些東西是沒有做好的,對不對?
link |
仔細想想看,我覺得伊布這邊應該就沒救了,因為我認為伊布會有很不一樣的cp值,是因為進化成不同種類的精靈。如果你沒有考慮這個factor的話,應該就沒救了。
link |
我覺得這邊有一些還沒有fit得很好的地方,有一些值還是略高或略低於這一條直線,所以這個地方搞不好還是有辦法解釋的。當然有一個可能是,這些略高略低於我們現在找出來的這個藍色綠色線的model的變化,這個difference其實是來自於random的數值。
link |
每次寶可夢那個程式產生進化後的cp值的時候,它其實有加一個random的參數,但也有可能其實不是random的參數,它還有其他的東西在影響著寶可夢進化後的cp值。
link |
有什麼其他可能的參數呢?比如說,進化後的cp值是跟weight有關係的?進化後的cp值是跟它的高度有關係的?進化後的cp值是跟它的hp有關係的?
link |
其實我們不知道,我又不是大目博士,我怎麼會知道這些事情。如果你有domain knowledge的話,你就可能可以知道說你應該把什麼樣的東西加到你的model裡面去。
link |
但是我又沒有domain knowledge,那怎麼辦呢?沒關係,有一招就是把你所有想到的東西統統拆進去,我們來弄個最複雜的function,然後看會怎樣。
link |
這個function我寫成這樣,如果它是BB鳥的話,它的cp值,我們就先計算一個y'。
link |
這個y'不是最後這個y,這個y'還要做別的處理以後才變成y。
link |
如果這個是BB鳥的話,這應該是波波,因為BB鳥是進化後的。y'等於b1加w1乘以xcp加w5乘以xcp的平方。
link |
我們覺得不只是要考慮cp值,也要考慮cp值的平方。
link |
如果是綠毛蟲用另外一個式子,如果是獨角蟲用另外一個式子,如果是伊布用另外一個式子,最後我們再把y'再做其他的處理。
link |
我們把y'再加上hp值,它的生命值乘上w9,再加上生命值的平方乘上w9,再加上高度乘上w11,再加上高度的平方乘上w12,再加上它的weight乘上w13,再加上weight的平方乘上w14。
link |
這些東西合起來,才是最後output的y。所以這整個式子裡面,其實也沒有很多個參數就是14加4是18,跟你們作業比起來,幾百個參數比起來,其實也不是個太複雜的碼子。
link |
我們現在有一個這麼複雜的function,在training data上我們得到的error,期望應該就是非常的低。我們果然得到一個非常低的error。這個function你可以把它寫成線性的式子,就跟剛才一樣。
link |
這麼一個複雜的function,理論上我們可以得到非常低的training error,training error算出來是1.9。那你可以期待在testing data上也算出很低的training error嗎?
link |
倒是不見得,這麼複雜的model,很有可能會overfitting的。你很有可能會在testing data上得到很糟的數字。我們今天得到的數字很糟,是102.3。結果壞掉了。怎麼辦呢?怎麼辦?
link |
如果你是大目博士的話,你就可以刪掉一些你覺得沒有用的input,然後就可以得到一個比較簡單的model,就可以避免overfitting的情形。但是我不是大目博士,所以我用別的方法來處理這個問題。
link |
這招叫做regularization。那regularization要做的事情是,我們重新定義了step 2的時候,我們對一個function是好還是壞的定義。我們重新redesign我們的loss function。
link |
然後我們重新redesign我們的loss function,把一些knowledge放進去,讓我們可以找到比較好的function。什麼意思呢?假設我們的modelin general寫成這樣,y等於b加上mention over wi乘xi。
link |
我們原來的loss function,它只考慮了error這一件事。原來的loss function只考慮了prediction的結果,減掉正確答案的比方,只考慮了prediction的error。那regularization呢,它就是加上一項額外的turn。
link |
這一項額外的turn呢,是lambda乘上summation over wi的平方。lambda是一個常數,這個是等一下我們要手調一下,看要設多少。那summation over wi的平方就是把這個model裡面所有的wi都算一下平方以後,加起來。
link |
這個合起來,才是我們的loss function。那前面這一項我們剛才解釋過,所以我相信你是可以理解的。error越小,就代表當然就是越好的function。
link |
但是為什麼我們期待一個參數的值越小,參數的值越接近零的function呢?這件事情你可能就比較難想像。為什麼我們期待一個參數值接近零的function呢?當我們加上這一項的時候,我們就是預期說我們要找到的function,它的那個參數越小越好。
link |
那當我們加上這一項的時候,你知道參數值比較接近零的function,它是比較平滑的。所謂的比較平滑的意思是,當今天的輸入有變化的時候,output對這個輸入的變化是比較不敏感。
link |
為什麼參數小就可以達到這個效果呢?你可以想想看,假設這個是我們的model,現在input有一個變化,比如說加上delta wi,我們對某一個xi加上delta xi,這時候對輸出會有什麼變化呢?
link |
這時候輸出的變化就是delta xi乘上wi,輸入變化delta xi,輸出就是delta xi變成wi乘以delta xi。
link |
那你會發現說,如果今天你的wi越小越接近零的話,它的變化就越小,對不對?如果wi越接近零的話,輸出對輸入就越不sensitive。
link |
所以,如果今天wi越接近零,我們的function就是一個越平滑的function。而現在的問題就是,為什麼我們喜歡比較平滑的function?
link |
這個可以有不同的解釋,你可以這樣想,如果我們今天有一個比較平滑的function的話,因為平滑的function對輸入是比較不敏感,所以如果我們今天的輸入被一些雜訊所干擾的話,如果一些雜訊干擾了我們的輸入在我們測試的時候,
link |
那一個比較平滑的function,它會受到比較少的影響而給我們一個比較好的結果。
link |
那接下來我們就要來看看說,如果我們加入了這個regularization的項,那對我們的最終的結果會有什麼樣的影響?
link |
這個是實驗的結果,我們就把浪打從0,1,10一直調到10萬。
link |
所以浪打值越大,代表說,我們現在loss裡面有兩項,一項是考慮error,一項是考慮有多smooth。
link |
當浪打值越大,代表考慮smooth的那個regularization那一項,它的影響力越大。所以當浪打值越大的時候,我們找到的function就越平滑。
link |
如果我們看看在training data上的error的話,我們會發現說,如果function越平滑,我們在training data上得到的error其實是越大。
link |
但是這件事情是非常合理的,因為當浪打越大的時候,我們就越傾向於考慮w本來的值,我們就傾向於考慮w的數值而減少考慮我們的error。
link |
所以今天如果浪打越大的時候,我們考慮error就越少,所以本來我們在training data上得到的error就越大。
link |
但是有趣的是,雖然在training data上得到的error越大,但是在testing data上面得到的error可能是會比較小的。
link |
比如說我們看這邊的例子,原來浪打等於0,就沒有regularization的時候error是102,浪打等於1就變到68,到10就變25,到100就變成11.1。
link |
但是浪打太大的時候,到1000的時候,error又變大,變成12.8,一直到26.8。這個結果是合理的。
link |
我們喜歡比較平滑的function,比較平滑的function對noise比較不sensitive,所以當我們增加浪打的時候,performance是越來越好。
link |
但是我們又不喜歡太平滑的function,最平滑的function是什麼?最平滑的function就是一條水平線,對不對?一條水平線是最平滑的function。
link |
如果你的function是一條水平線,那它啥事都辦不成,所以如果今天function太平滑的話,你反而會在testing set上又得到糟糕的結果。
link |
所以現在的問題就是,我們希望我們的model多smooth呢?我們希望我們今天找出來的function有多平滑呢?
link |
這件事情就變成你需要調浪打來解決這件事情,你必須要調整浪打來決定你的function的平滑程度。
link |
有時候你可能調整一下參數以後發現說,今天的training都隨著浪打增加而增加,testing隨著浪打先減少後增加。
link |
在這個地方有一個轉折點,是可以讓我們的testing的error最小,那你就選浪打等於100來得到你的model。
link |
那這邊還有一個有趣的事實,很多同學可能都知道regularization,你有沒有發現說,這邊我沒有把p加進去。
link |
我剛才突然想到一件事情,就是我其實在前面那個gradient design投影片裡面,有一個地方寫錯了,然後剛才鄭凱文同學有提醒我,
link |
以後如果你有發現我投影片有寫錯的話,你就告訴我就把你的名字寫在投影片上面,這樣就可以一直流傳下去。
link |
好,這邊,你發現我沒有加上b,為什麼呢?你覺得是我寫錯了,我忘了加上去的同學舉手一下。
link |
你覺得是本來就不需要加上b的同學舉手一下。
link |
好,謝謝謝謝,沒錯,這邊我覺得我沒有寫錯。
link |
事實上很多人可能不知道這件事,在做regularization的時候,其實是不需要考慮bias這項的。
link |
首先,如果你自己做實驗的話,你會發現不考慮bias performance比較好。
link |
再來,為什麼不考慮bias呢?因為我們今天預期的是,我們要找一個比較平滑的function。
link |
你調整bias的b的大小跟一個function的平滑程度是沒有關係的,對不對?調整bias的值的大小的時候,你只是把function上下移動而已。
link |
對function的平滑程度是沒有關係的,所以有趣的是,這很多人都不知道,在做regularization的時候,你是不用考慮bias的。
link |
好,那總之,搞了半天以後,我最後可以做到我們的testing error是11.1。
link |
在我們進行助教公告作業之前,我們就說一下今天的conclusion。
link |
首先感謝大家參加我對寶可夢研究的發表會。
link |
那我今天得到的結論就是,寶可夢進化後的cp值跟進化前的cp值,還有它是哪一個物種,是非常有關係的。
link |
知道這兩件事情幾乎可以決定進化後的cp值。
link |
但是我認為呢,可能應該還有其他的factor。
link |
我們剛剛看到說,我們加上其他什麼高度啊,體重啊,HP以後,是有比較好的,如果我們加上regularization的話。
link |
不過我data有點少,所以我沒有那麼confidence就是了。
link |
然後再來呢,就是我們今天講了gradient descent的做法,就告訴大家怎麼做的。
link |
那我們以後會講它的原理還有它的技巧。
link |
等一下如果我能夠連得上我的ipython的話,就可以實際看一下。
link |
好,那我們今天講了overfitting和regularization,介紹一下表象上的現象,未來會講更多它背後的理論。
link |
首先我覺得我這個結果應該還蠻正確的,因為你知道網路上有很多的cp的預測器對不對?
link |
那些cp的預測器你在輸入的時候,你只要輸入你的寶可夢的物種和它現在的cp值,它就可以告訴你進化以後的cp值。
link |
所以我認為,你要預測進化以後的cp值,應該是知道原來的cp值跟它的物種就可以知道大部分。
link |
不過他們預測,我看那些預測器預測出來的誤差,都是給你一個rate,它都沒有辦法給你更準確的預測。
link |
如果考慮更多的factor,更多的input,比如說hp什麼的,或許可以預測得更準就是了。
link |
但最後的問題就是,我們在testing data上面,在我們testing的十隻寶可夢上,我們得到的average error最後是11.1。
link |
如果我把它做成一個系統,放到網路上給大家使用的話,你覺得如果我們看過沒有看到的data,那我們得到的error會預期高過11.1還是低於11.1,還是理論上期望值應該是一樣的?
link |
我們先不考慮說,你知道我的training data裡面只有那四種,裡面都沒有乘龍卡比之類的,我們就假設使用者只能輸入那四種,他不會輸入乘龍卡比。
link |
在這個情況下,你覺得如果我今天把這個系統放到線上給大家使用的話,我們最後得到的cp值會比我今天在testing線上看到的高還是低還是一樣?
link |
你覺得一樣的同學舉手一下。你覺得會比現在看到的低舉手一下。你覺得會比比較,如果我真的把系統放到線上,會比我們今天看到的這個11.1還要高的同學舉手一下。
link |
謝謝,大家都對我這麼沒有信心。我們之後會解釋,我們今天其實用了testing set來選model,所以我們今天得到的結果其實是,如果我真的把系統放到線上的話,預期應該會得到比我今天看到的11.1更高的error rate。
link |
所以我們需要用validation的觀念來解決這個問題,這個我們就下一堂課再講。我們就請助教來公告一下作業1。