back to index
ML Lecture 1: Regression - Demo
link |
那我們在前一堂課呢,看了regression,那我們知道怎麼用Gradient Descent來找出regression model的參數。
link |
那這個聽起來呢,還蠻容易的。那接下來呢,呃,我就舉個例子,讓大家知道說,實際在做regression的時候,你會碰到什麼樣的困難。
link |
好,那這邊呢,我們假設X data有十筆,Y data也有十筆。那X和Y之間的關係呢,是Y data等於B加W乘上X data。
link |
那B和W呢,都是參數,我們要用Gradient Descent呢,把B和W找出來。那我當然知道說,其實今天這個問題有closed form solution。
link |
這個B和W呢,有更簡單的方法把它找出來,但我們假裝不知道這件事,我們要練習呢,用Gradient Descent把B和W找出來。
link |
好,那怎麼做呢?那Gradient Descent其實非常的簡單,所以這邊我們不需要說太多,這個程式碼呢,還沒有超過20行。
link |
好,那這個呃,我們先給B呢,一個初始值,這邊B的初始值是-120,我們給W一個初始值,這邊W的初始值是-4。
link |
那我們需要一個learning rate,那learning rate我們就給它一個很小的數字,那iteration呢,就是十萬個iteration。
link |
那在每一個iteration裡面,我們要做的事情是,計算出B和W對loss的偏為分。
link |
那呃,這個計算的式子呢,在之前的課程裡面已經講過了,那你就呃,把之前課程裡面呢,導過的式子呢,把它呃,寫出來就可以了。
link |
好,算出這個B和W對loss的偏為分以後呢,你就把呃,這個B的偏為分乘上learning rate去update B,把W的偏為分乘上learning rate去update W。
link |
那反覆呢,這個iteration多次,就最後就可以找出呢,呃,B跟W了。
link |
好,那我們就實際來執行一下程式,看看我們會得到什麼樣的結果。
link |
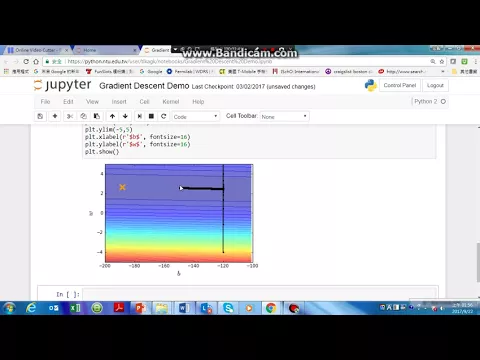
那這個圖上面的顏色啊,代表了這個不同的參數下,我們會得到的loss。縱軸呢,代表了W的變化,橫軸呢,代表了B的變化。
link |
不同的W和不同的B,我們得到不同的顏色,也就是不同的loss。
link |
那loss最低的點呢,是在這個地方,也就是B呢,介於-180到-200之間,W大概介於2到4之間的時候,這個時候呢,loss最低。
link |
那我們的初始的這個B和W呢,在這個地方。
link |
那在做gradient descent的時候,就從這個地方開始update參數,啊,所以參數就一路從這個地方開始變化,一直變化,一直開始變化,走到這邊,然後呢,向左轉。
link |
但是過了十萬次參數update以後,我們發現說,呃,我們現在的參數離這個最佳解仍然非常的遙遠。
link |
怎麼辦?這顯示learning rate不夠大,把learning rate調大一點,調大一點。
link |
好,這是learning rate呢,調,調大十倍後的結果,那也發現說呢,最後,經過十萬次參數update以後呢,我們的參數在這個地方,離最佳解呢,稍微近了一點,不過呢,這邊有一個劇烈的震盪的現象發生。
link |
好,那我們再把learning rate稍微設大一點,我們設再大十倍。
link |
啊,你們發現,啊,糟糕了,啊,learning rate再大十倍以後就太大了,呃,這個,從這個地方開始update參數,結果呢,這個參數一update,它就飛到這個圖外面去了,就飛得很遠很遠很遠了。
link |
所以,哇,現在learning rate太大,那,呃,如果再把它變小,又變成跟剛才一樣還是離,呃,我們的最佳解很遠呢,怎麼辦?
link |
哇,這個,呃,這個問題明明就很簡單,只有兩個參數,結果跟gradient descent搞半天呢,都搞不定,連兩個參數都搞不定,之後,如果再做這個neural network有數百萬個參數的時候,要怎麼辦呢?這個就是一事之不致,何以天下國家為的概念。
link |
那怎麼辦?啊,只好,呃,放個大絕來解這個問題,就,我本來不想用這一招的,就跟死神一樣,啊,我本來不想用這一招的,但是,不得不,呃,這個只有兩個參數的問題我們不解決是不行的,而且還是要解決它,怎麼辦呢?
link |
我們要給b跟w客製化的learning rate,啊,他們兩個learning rate要是不一樣,那怎麼做呢?好,這個,這個做,實做起來蠻容易的啦,所以現場寫一下,好,我們要給b跟w呢,客製化的learning rate。
link |
好,那原來b和w的這個偏為分都是直接乘上learning rate,固定的learning rate,那我們現在呢,把它除掉,不同的值,哦,所以他們。
link |
它們呢 會有不同的landing rate
link |
不過沒有關係呢 這個罩叫做Atagram
link |
那這個landing rate就隨便設設個1就好
link |
好 你會發現說有了新的landing rate以後呢