back to index
ML Lecture 2: Where does the error come from?
link |
會找最小的,最好的function。再來,呃,我們要問的問題就是,我們上一次啊,有看到說,如果你選擇不同的function set,你就選擇不同的model,你在testing上面,testing data上呢,你會得到不同的error,而且呢,越複雜的model,不見得會給你越低的error,ok,你會發現說呢,呃,一到五分之一的error,你會發現說呢,呃,一到五分之一的error,你會發現說呢,呃,一到五分之一的error,你會發現說呢,呃,一到五分之一的error,你會發現說呢,呃,一到五分之一的error,你會發現說呢,呃,一到五分之一的error,你會發現說呢,呃,一到五
link |
特別代表說,我們今天的這個做linear regression的時候,我們考慮的input是一次,一次二次,一次二次三次,一直到一次到一次,那你會發現說,最複雜的model,其實它的performance是最差的,那今天我們要討論的問題就是,這個error來自什麼地方,ok,error來自什麼地方,那其實error有兩個來源,一個是來自於bias,一個是來自於variance,一個是來自於variance,一個是來自於variance,一個是來自於variance,一個是來自於variance,一個是來自於variance,一個是來自於variance,一個是來自於variance,一個是來自於variance,
link |
那了解這個error的來源呢,其實是重要的,因為你常常就是做一下machine learning,然後做完就發現說,你得到一個error rate,比如說60%的error rate,那接下來你要怎麼improve你的model呢,如果你沒有什麼方向的話,毫無頭緒的亂做,你就沒有效率,如果你今天可以診斷你的error的來源,比如說error可以分成兩種,一種是來自bias,一種是來自variance,
link |
如果你可以診斷你的error的來源,你就可以挑選適當的方法來improve你的model。
link |
好,那我們之前在上一堂上周的時候,我們舉的例子是這樣,我們要做寶可夢進化後的cp值的估測,也就是說我們要找一個function,這個function,input一隻寶可夢output就是他進化後的cp值,那這個function理論上有一個最佳的function,
link |
這個理論上最佳的function呢,我們寫成fhat,但這個理論上最佳的function我們是不知道的,只有Ninetic知道的,Ninetic大家知道是什麼嗎,就做寶可夢的那個公司,因為他一直用一個程式寫出來的啊,所以如果你知道那個程式的話,你就可以知道說input一個寶可夢,照理說output他的進化後的cp值應該是什麼,但是問題就是這個function,fhat呢,是你不知道的。
link |
那你能夠做的事情是,你有一些training data,你實際去抓一些寶可夢,然後呢,去找一個你根據你的training data所學出來所找到的最好的function,fstar,那這個fstar並不會真的等於fhat,因為你根本不知道真的fhat是什麼樣子,那fstar可能不等於fhat,這個fstar呢,他就好像是一個fhat的估測值一樣,他的estimator一樣。
link |
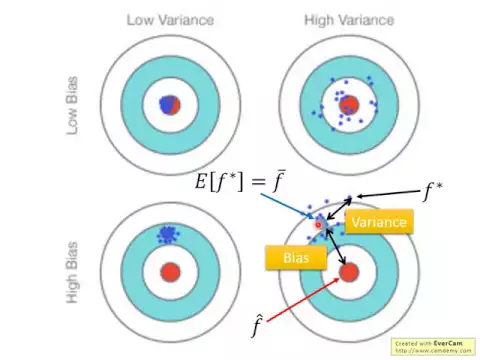
所以就想成說現在是在打靶,fhat呢,是靶的中心點,你先收集到一些data做training以後,你找到一個你覺得最好的function,fstar,這個fstar他不等於fhat,他是在靶子上的另外一個位置,這個fstar跟這個fhat他們中間有一段距離,那這個距離呢,來自於兩件事,他可能來自於bias,也有可能來自於variance。
link |
那一個estimator的bias,variance指的是什麼呢?我們先舉一個你在機率裡面看過的例子,這個地方在機率,我想應該是機率與統計你應該是學過的,所以你可以很快的看過去。
link |
假設我們現在有一個variable x,我想要估測他的mean,怎麼做呢?假設這個variable x,他的mean是μ,他的variance是σ平方,那我要估測mean的話,我怎麼做呢?我就先sample n個點,我用對這個variable sample n個點,x1,x2到x2,我們再把這n個點算平均值得到n。
link |
這個n個點算出來的平均值,會跟μ一樣嗎?其實不會,對不對?除非你sample無窮多個點,不然如果你只sample有15個點,10個點,n等於5跟10,這個μ跟n,他們不見得是一樣。
link |
OK,所以假設這個是μ的value,現在你做一次sample,你sample n個點,算出來的n可能不會跟μ一樣,做第一次實驗做出n1,可能跟μ不一樣,再做一次實驗,n2也跟μ不一樣,n3也跟μ不一樣,n4跟μ不一樣,n5不一樣,n6也不一樣,你可能沒有辦法找到一個n正好exactly跟μ。
link |
但是如果你今天把你的n的期望值算出來的話,假如你算e of n,n就是這個式子,把它代進來,然後用國小數學把e放進去,然後你就得到xn的期望值,summation over n去n分之1,反正得到的值就是μ。
link |
所以今天每一個n雖然都不一定跟μexactly一樣,但是如果你找很多n,他們的期望值會正好等於μ。
link |
所以用n來estimate,μ這個estimator,n這個estimator,它是unbiased的,因為它的期望值會正好等於μ,就好像是說,如果你在打靶的時候,它的準心是瞄準μ的,但是因為種種比如說機械故障,或者是受到其他各種風速的干擾等等,你會散落在你本來瞄準的位置的周圍。
link |
這個散佈在周圍會散得多開呢?取決於n的variance。
link |
這個variance就是σ平方除以n,你就不要問怎麼來,這個機率課本都有寫。這個variance的值,它depend on你今天取了多少的sample。如果你今天的n,我發現一個錯誤,你有發現嗎?
link |
我今天把larger跟smaller放反了,不好意思,這個larger跟smaller,他們應該是反過來的。如果你有比較多的n的話,它的散佈就會比較集中。如果你值取比較少的n的話,你那個n就會分散得比較開。
link |
如果你要估測variance怎麼辦呢?你就先用剛才的方法估測n。估測n以後,你再計算xn-n的平方,再取它們的平均值。你得到另外一個值是s平方,這個s平方可以拿來估測σ平方。
link |
這個s平方它估測得怎麼樣呢?當然每一次你算一個s出來,它們跟σ,我這邊應該要把它取平方才對,因為s平方才是σ平方的估測值,假設我這邊有取平方。
link |
我們每一次取出來的這個s,它不會跟σ正好一樣,它散佈在σ的周圍,但是這個estimator它是bias,也就是說如果你取s平方的期望值的話,它算出來並不是正好等於σ平方,它是n分之n-1。
link |
所以你會發現說,普遍而言,s平方是比σ平方還要小的,小的次數比較多,當然因為有variance,所以也有可能比較大,但是平均而言小的次數是比較多的。
link |
如果你increase n的話,如果n比較大的話,那這個σ平方的這個跟這個s平方的估測之間的差距就會變小。
link |
好,那說了這些,我們回到regression這個問題,也就是說我們現在要估測的是靶的中心,也就是f-hat,這個是我們的目標。
link |
你collect一些data,做一次實驗,你找出來的x-dot可能是在這個位置。這個位置跟這個紅心之間,它們其實有發生了兩件事,它們這個arrow取決於兩件事。
link |
第一件事情是你瞄準的位置在哪裡,就你這個estimator是不是bias的。怎麼知道一個estimator是不是bias的呢?
link |
你把這個estimatorf-star,假設你可以做很多次實驗,你把這個f-star的期望值算出來,我們這間寫成f-bar,bar就是平均的意思,我們把f-star的期望值算出來就是f-bar。
link |
你會發現說假設我們用這個例子來看,右下角這個例子來看,你做了很多次實驗,找了很多不同的f-star,你會發現它們散佈是這些藍色的點,這個時候你的f-bar可能是在這個地方。
link |
也就是說你的estimator跟你的靶心中間是有一個bias的,也就是說你瞄的時候就沒有瞄準,你以為正中心在這邊,瞄這個點,實際上靶心是在這個地方,瞄的時候就沒有瞄準。
link |
但是還有另外一個error,這個error來自於你瞄準了這個位置,但是你把子彈射出去以後還是會有偏移的,你瞄準這個位置,但是射出去還是會有偏移的,所以每次找出來的f-star是不一樣。
link |
而這個f-star跟你瞄準的位置,也就是f-star的期望值,f-bar中間的距離,就是variance。所以你的錯誤來自於兩件事,一件事情是你的bias有多大,另外一件事情是你的variance有多大。
link |
所以最理想的狀況是,我們期待的是你同時沒有bias,variance有小,這樣你每次做實驗,你找出來的每一個f-star都是好的。
link |
那如果說今天你有可能遇到一個狀況是你的bias很大,但variance很小,那這樣你每一次找到f-star都很像,但是都集中在這個錯的位置,那你總是有錯。
link |
也就是你今天找出來的f-bar,它是沒有bias的,也就是你瞄的位置是對的,但是你那個槍性能很差,所以它每次射出去以後是散布在靶心的周圍的,那你也會得到一些error。
link |
所以error來自於兩個地方,一個是你瞄準的位置在哪裡,另外一個是你今天的variance有多大。
link |
有人可能會問一個問題,你不就只能做一次實驗嗎?如果你上週有來的話,你不就collect了十筆data,然後就找一個f-star,不就結束了嗎?
link |
你怎麼找很多個f-star呢?你怎麼知道它的variance還有bias有多大呢?你怎麼找很多個f-star呢?
link |
所以這個怎麼想呢?你就假設說這個世界上是有很多的平行的宇宙,我們知道有很多的平行的宇宙,在很多的平行宇宙,雖然每個宇宙都不一樣,但是我們都在抓寶可夢。
link |
在每一個平行宇宙裡面,我們都想要estimate進化後的CP值,所以在每個平行宇宙裡面,我都去抓了十個寶可夢,然後來算f-star。
link |
但是因為在不同的宇宙裡面,我們抓到的寶可夢是不一樣的。在不同的宇宙裡面抓到十隻寶可夢是不一樣的。
link |
這個是第一個宇宙中的我,然後抓到的是這十隻。這個是第二個宇宙中的我,其實衣服換一個顏色而已,抓到的是這十隻。
link |
這個是第三個宇宙中的我,這性別換了,然後抓到的是這十隻。抓到的寶可夢是不一樣的。如果你拿不同的寶可夢來找你的最好的function,就算你用同一個model,
link |
假設我們現在都用y等於b加w乘上xct值這個model,我們用同一個model,但是你給他data不一樣,那你找出來最好的function f-star就是不一樣。
link |
所以在宇宙編號123號,我們抓到這十隻寶可夢,用這個model,我們找到的f-star是這樣。
link |
在宇宙編號345號裡面,我們找到另外十隻寶可夢,我們找到的model是這個樣子,這兩個model是不一樣的。
link |
在不同宇宙裡面,我們找到的f-star是不一樣的。
link |
現在我們的問題就是,每個宇宙找出來的f-star就像對著靶子開一槍一樣。
link |
我們現在就是要知道它的散布是什麼樣子,所以我們就把一百個不同宇宙裡面的f-star都找出來。
link |
世界上並沒有真的平行宇宙,所以做這件事情其實就是做一百次實驗,然後每次都抓十隻不同的寶可夢就是了。
link |
在一百個平行的宇宙裡面,我們都抓了十隻不同的寶可夢,然後都去找一個f-star。
link |
今天如果我的model是y等於b加w乘以xcp,那這一百個f-star它們分布長什麼樣子呢?如果我們把這一百個f-star,這一百個y等於b加wxcp畫出來,就有一百個不同的w,一百個不同的b。
link |
你把這一百條直線都畫出來,它們長得是這個樣子,這邊有一百條直線。
link |
那如果我今天換另外一個model,你換一個model,這個model是考慮了xcp,xcp平方,xcp三方。
link |
你做了一百次實驗,在一百個宇宙裡面找出了不同的b,w1,w2,w3,那你的這一百條線長這個樣子,你會發現說有點像是散開了,像花一樣散開了。
link |
那如果今天是換另外一個最複雜的model,考慮了五次的model,那你就會發現說,做了一百次實驗以後,你把那一百條曲線都畫出來,就發現是這樣子,就崩潰了。
link |
每一件事情,在不同的宇宙裡面,每一件事情都是有可能會發生的。
link |
所以呢,如果我們看這個model之間的variance的話,如果你看你做一百次的設計以後,你的結果散佈的話,你會發現說,簡單的model,就是只有考慮一次的model,它是比較集中的。
link |
如果你考慮五次的話,它散佈就非常的廣,所以如果你用一個比較簡單的model的時候,它的variance是比較小,就好像說你在射擊的時候,每次射擊的位置都是差不多的。
link |
你每次來找出來的直線,找出來的最好的function,F-star,都是差不多的。但是,如果你今天換一個比較複雜的model,它的散佈就很開。
link |
比方這邊藍色的點一樣,它的variance很大,它的散佈就很開。
link |
這邊每一條直線都長得很不像,各種怪怪的線,都長得不一樣,所以它的散佈就非常開。
link |
那你可能會問一個問題,為什麼比較複雜的model,它的散佈就比較開呢?為什麼比較簡單的model,它散佈就比較緊呢?
link |
因為,你可以這樣想,簡單的model,它比較不會受你的data的影響。
link |
在每個宇宙裡面,我們sample出來的,我們抓到的寶可夢都不一樣,所以找出來的model都不一樣。
link |
但比較簡單的model,它受到不同的data的影響呢,是比較小的。
link |
這個極端的例子是,我們的整個model set裡面呢,就我們整個function set裡面呢,我們整個function set就model裡面,就一個function,f of x,output就是c。
link |
你不管抓到什麼樣的training data,這個function的output就是給你c,給你一個concept。
link |
這時候你就會發現說,你在不同的宇宙裡面,你找出來的model都是一模一樣,因為你根本就沒找。
link |
也不同的宇宙裡面,你找出來的model通通是一模一樣,它variance是0。
link |
所以如果給你一個最簡單的model,它的variance是0。
link |
當你給model的這個複雜度越來越高的時候呢,它的variance就會越來越大。
link |
bias的意思是說,我們有很多很多的f-star。
link |
假設我們把所有的f-star平均起來,找它的期望值,也就是f-bar的話,這個f-bar跟我們的靶心f-hat,它有多接近呢?
link |
如果是一個大的bias的話,意思是說,你今天把所有的f-star平均起來,你得到f-bar,它跟靶心是有一段距離的。
link |
如果是小的bias的話,意思是說,你的f-star可能分散得很開,它分散得多開我們不管,你就找它的平均值。
link |
它的平均值呢,跟靶心是接近的,不管它散得有多開,平均值跟靶心是接近的,這樣叫small bias。
link |
說到這邊的時候,我就卡住了,我為什麼卡住了呢?
link |
我想要量不同的function之間的bias有多大,仔細想想,我根本沒有辦法量這件事情,因為我根本不知道f-hat長什麼樣子,所以我就卡住了。
link |
所以我只好胡亂自己假設一個f-hat,我就假設說f-hat就是長這一條直線。
link |
好,那我就假設說f-hat就是長這一條直線,所以我們的寶可夢data呢,寶可夢就是從這一條曲線sample出來,每次我們就sample十個點出來,那你就可以找一個f-star。
link |
好,那這個是實驗結果,黑色的線代表的是我們剛才在前一頁課裡面看到的真正的f-hat,就是你的靶心的位置,是這一條黑色的直線。
link |
紅色的呢,代表了我們做五千次實驗,五千次實驗每一次找出來的f-star都是不一樣。
link |
所以假設是一次的model,最簡單的那個model,有五千條直線在這邊,畫出來就是紅紅的一大塊。
link |
如果是藍色的呢,藍色代表說這個是f-bar,就是我們把五千個f-star平均起來變成f-bar,就是藍色的這一條線。
link |
如果我們只考慮一次的話,你會發現說那五千條直線都差不多都在這個地方,那它們平均就是這一條藍色的線,那它跟黑色這個f-hat跟靶心是有一段差距。
link |
如果你用三次式,三次式的話,你會發現說你畫出來,五千條直線畫出來的話是這樣,它的頭跟尾是很散。
link |
雖然它頭跟尾都很散,但是如果你說平均找f-bar,也就是藍色這一條線的話,你會發現說,雖然每一次的這個f-star都差很多,
link |
但平均起來這個藍色的線跟黑色這個f-hat,其實相對於這邊,它是比較接近的。
link |
如果我們找五千條,如果我們用五次式,你會發現說五千條線畫出來這樣,你要不要乾脆把整個圖都塗紅色算了。
link |
你會發現說,哇,一切都有可能,但雖然這個地方你完全看不出來說,哇,到底有什麼直線,通通塗成紅色的。
link |
但是如果你把它平均起來,你把這五千條五次的曲線平均起來,你會發現說,它得到的是這一條藍色的f-bar,它的這個f-bar是這一條藍色的。
link |
它跟我們真正的f-hat,它跟真正的f-hat是接近的。
link |
雖然它每一次都差很多,但平均起來以後是接近的。
link |
所以我們看到說,如果是一個比較簡單的model,它有比較大的bias。
link |
如果是一個比較複雜的model,每一次找出來f-bar都不一樣,但它有比較小的bias。
link |
所以今天左邊這個簡單的model,它的case就像是這個樣子。
link |
每一次f-bar都差不多,但是它的分布比較小,但它跟靶心是有一個差距的。
link |
那這個case就像是這邊這樣子,每一次找出來的f-bar都不太一樣,但平均而言是在靶心附近。
link |
為什麼會這樣子呢?我試著直觀的解釋給大家聽。
link |
我們說我們的model就是一個function set,對不對?
link |
那我們就用一個範圍來表示這個function set。
link |
當你定一個model的時候,你就已經設定好說你最好的function就只能從那個function set裡面挑出來。
link |
如果是一個簡單的model,它的space是比較小的。
link |
所以這個比較小的space,它可能根本就沒有包含你的target。
link |
如果在沒有包含target的情況下,你從這裡面不管怎麼sample,你平均起來都不會是這個target。
link |
因為你的這個function set裡面根本就沒有包含那個target。
link |
但是如果你今天你的model是比較複雜的,你的model所代表的function space,
link |
我們上次有講過說,你從一次,二次,三次,一直到五次,你的function是越來越複雜的。
link |
比較簡單的function是包含在那個比較複雜的function裡面。
link |
所以如果你用五次的時候,這個時候你的function的space是比較大。
link |
它可能有包含那個target,只是它沒有辦法找出那個target在哪裡。
link |
因為你給的training data不夠,你給的training data每一次都不一樣,
link |
所以它每次找出來的fbar都不一樣。
link |
但如果它們是散佈在這個target附近的,那平均起來你就可以得到fbar。
link |
所以我們回到我們上次看到的那個model對這個testing data error所畫出來的線。
link |
那比較簡單的model,我們剛才有講說,比較簡單的model它就是bias比較大,但是variance比較小。
link |
比較複雜的model就是bias比較小,但variance比較大。
link |
所以今天這個圖,由左到右,一方面model的bias是逐漸的下降,
link |
就是bias所造成的error是逐漸下降,也就是你描的越來越準。
link |
但是同時呢,這個variance是越來越大。
link |
你現在每次,雖然你描的越來越準,但你每次射出去以後,你的誤差是越來越大。
link |
所以當這兩項同時被考慮的時候,你得到的就是藍色這一條線。
link |
藍色這一條線,也就是說,在某個地方,你可以找到一個平衡的點,
link |
讓你同時考慮bias跟variance的時候,你得到的error值越小。
link |
但是當你的model越來越複雜的時候,variance增長的比較快,所以你的model的error就變得很大。
link |
所以今天如果是一個variance大的情形,如果你的error來自於variance很大,
link |
這個狀況就是overfitting。
link |
如果你今天你的error來自於bias很大,這個狀況叫做underfitting。
link |
所以今天假設你遇到一個error的時候,你自己做一些implement,
link |
比如說你碩士論文用到machine learning的技術,你做完得到一個結果,
link |
然後你後面寫了一些future work,然後我都會問一個問題,
link |
如果你找我來考碩士口試的話,我都問這個問題,
link |
就是說你覺得你現在的問題是bias大還是variance大?
link |
你應該先知道這件事情,你才知道說你future work,你要improve你的model的時候,
link |
那怎麼知道你現在是bias大還是variance大呢?
link |
如果什麼時候bias大?如果今天你的model沒有辦法fit你的training example,
link |
就是如果我們只sample這幾個藍色的點,而你的model even沒有辦法fit這少數幾個藍色的點,
link |
代表說你的model跟正確的model是有一段差距的。
link |
所以這個時候是underfitting,這個時候是bias大的狀況。
link |
如果今天是你在training data上,你可以fit你的training data,
link |
在training data上得到小的error,但是在testing data上你卻得到一個大的error,
link |
這意味著你的model可能是variance比較大,這個時候代表的是overfitting。
link |
那遇到bias大跟variance大的時候,你其實是要用不同的方式來處理它。
link |
比如說如果今天是bias大,那你要做的事情是什麼呢?
link |
你應該去redesign你的model。
link |
Bias大代表說你現在的model裡面可能根本沒有包含你的target,
link |
那個f hat,它根本就不在你的model set裡面。
link |
那你要怎麼辦呢?你要做的事情是redesign你的model。
link |
比如說你可能重寫你model的式子,把更多的feature加進去,
link |
比如說只考慮cp值可能不夠,你可能還要考慮hp值或者是其他什麼東西。
link |
或者是你讓你的model更複雜,本來只考慮一次不夠,你要考慮二次三次等等。
link |
在這個狀況下,因為是你的model不好,沒有包含f hat,
link |
所以如果你今天error差是來自bias,你不要說什麼我去collect更多data,
link |
collect更多data是沒有用的,今天在這個狀況下collect更多data你也不會有幫助,
link |
因為你的model本來就是,你的model,你的function set本來就不好,
link |
再找更多的data下來也不會有幫助。
link |
今天如果是另外一個case,如果是variance大的話,那你應該怎麼辦呢?
link |
一個方法就是增加你的data,那我們看剛才的例子,
link |
如果是五次式找100個f hat,每次如果我們只抓10隻寶可夢的話,
link |
那我們找出來的式子是這個樣子,找出來的這100個f star的散佈是這個樣子,
link |
但如果我們每次抓100隻寶可夢的話,那100個f star的散佈會發現說他們非常的集中,
link |
他們幾乎都集中在這個地方,他們幾乎都集中在這個地方。
link |
所以其實增加data是一個很有效控制variance的方法,假設你覺得你variance太大的話,
link |
這個時候你要做的事情,collect data幾乎是一個像是萬靈丹這樣的東西,
link |
但是他沒有什麼太多的,比如說他不會傷害你的variance,
link |
但他有可能造成你的問題就是在實際上你沒有辦法collect更多data,對不對?
link |
在practical,collect data很麻煩啊,你不見得能夠collect更多data,
link |
不只在學校實驗室沒有辦法,你可能以為在業界就可以說你要collect多少data,
link |
其實你也不見得可以,比如說有人想要在業界做些AI的東西,
link |
然後他就跟老闆說我要collect一萬筆level data,然後就被reject,
link |
因為老闆說這個機器會自己學習,所以你不需要level data,
link |
機器會自己學習嗎?為什麼要level data?就把他否決了這樣子。
link |
所以在業界你也不是想要collect data都可以了,會有各種review,
link |
尤其是你的高層又不知道machine learning是什麼的時候,你就會很卡。
link |
所以有時候你根本就沒有辦法collect data,所以你不見得能夠這麼做。
link |
那如果你不能這麼做,其實有一招啦,這一招就是generate假的training data,
link |
就根據你對這個問題的理解,自己去製造更多data。
link |
那是有這一招的,比如說在做手寫數字辨識的時候,
link |
手寫辨識的時候有人會說,因為每個人手寫的這個角度不一樣,
link |
就把所有的training data裡面的數字都左轉15度,右轉15度,這樣是可以。
link |
或是說影像辨識,你只有一個從左邊開過來的火車,沒有從右邊開過來的火車,怎麼辦?
link |
圖片翻轉你就有右邊開過來的火車啦,對不對?
link |
你可以把你的每一張圖片都左右顛倒,你就多一倍的data出來。
link |
或者是在語音辨識的時候,你只有男生說你好,沒有女生說大家好,
link |
那你就把男生的聲音用變聲器轉一下,就變女生的聲音,女生的聲音用變聲器轉一下,
link |
變男生的聲音,你的data就多出來了,而且是真的有人這麼做的。
link |
或者是說,你說我只有clean speech,在錄音室錄的聲音,可是我是要做真正的application,它是要讓你在公車上用的,
link |
那怎麼辦?你就去公車上錄一些雜訊,然後加到你在錄音室錄的聲音裡面,
link |
你馬上就有公車上的雜訊了,所以有各種各種方法可以用啦。
link |
然後還有人說,我今天要做language understanding的task,那我今天要做support各種不同國家的language understanding的task,
link |
所以我要做10種國家,10種語言都要,那老闆說只給你英文的data,因為他自己會學這樣子,
link |
只給你英文的data,他中文自己就會學的會,那怎麼辦呢?你就可以做translation,
link |
把英文的動作硬翻成中文,結果你還是跟一圈這樣子,有各種不同的做法。
link |
好,那如果你沒有辦法collect更多data的話,還有另外一招叫regularization,
link |
我們上次也有看到,就是我們在原來的loss function裡面,後面再加一個term,
link |
這個term會希望你的參數越小越好,也就是說希望你今天早餐的曲線越平滑越好,
link |
然後那個新加的term前面可以有一個wait,代表你希望你的曲線有多平滑。
link |
左邊這個第一個圖是沒有加regularization的case,所以這個圖跟這個圖是一樣的。
link |
如果你今天加了regularization以後,因為你的所有曲線都會變平滑,
link |
本來這種很不平滑的怪怪的曲線就不會出現了,所有曲線都集中在比較平滑的區域,
link |
如果你再更增加他的wait的話,再考慮要讓你的曲線更平滑的話,你得到的結果就是這樣。
link |
所以如果你加了regularization以後,因為你強迫所有的曲線都要比較平滑,
link |
這個時候也會讓你的variance變小,但這個時候你會得到的一個可能的傷害就是,
link |
你其實有可能會傷害你的bias,對不對?
link |
你調整了你的function space變成他只包含那些比較平滑的曲線,
link |
那你可能就沒辦法包含你的f hat,你可能就沒辦法包含你的目標的target function,
link |
所以當你做regularization的時候,你要調整一下regularization的wait,
link |
在variance和bias之間取得平衡。
link |
好,所以我們現在會遇到的問題往往是這樣,我們有很多的model可以選擇,
link |
還有很多的參數可以調,比如說regularization的wait。
link |
通常我們是在bias和variance之間做一些tradeoff,做一些平衡。
link |
我們很希望找一個model,他variance夠小,bias也夠小,
link |
這兩個合起來給我們最小的testing data的error。
link |
我們通常需要選擇一個最好的model。
link |
但是以下這件事情是你不該做的,或是你最好的原因,你不要這麼做。
link |
這個事情是怎樣呢?就是你手上有training set,有testing set,
link |
然後接下來你想要知道說model1,2,3裡面你應該選哪一個model。
link |
你就分別用model1,2,3分別去找一個best function,我們train出一個model,train出一個function。
link |
接下來你把它apply到testing set上。
link |
model1給你error0.9,model2給你error0.7,model3給你error0.5。
link |
但是你現在可能的問題是,這個testing set是你自己手上的testing set,
link |
而且你拿來衡量你model好不好的testing set,
link |
真正的testing set是你沒有的。
link |
所謂真正的testing set是說,假設我們今天把我做的寶可夢cp的預測放到網路上,
link |
想要看看有沒有人要用,那新進來的data我是從來沒有看過。
link |
因為你在挑model的時候,你考慮了你自己手上的這一筆testing set,
link |
而你自己手上的這筆testing set,它有一個bias,
link |
這個testing set它有一個自己的bias,
link |
這邊講這個bias跟之前講的bias是有點難解釋,
link |
這個testing set有自己的bias,
link |
所以你今天拿這個testing set來選最好的model的時候,
link |
它在真正的testing set上不見得是最好的model,
link |
通常都是比較差的,所以你可能會得到的error是大於你在自己的testing set上估測的0.5。
link |
這樣講一些什麼自己的真正的testing set可能讓你有點困惑,
link |
你可能已經做了作業,我們就是希望大家做了作業以後再來講這個東西。
link |
這個是這樣,你手上有training set,那你有testing set,
link |
那testing set其實有兩組,一組是public set,一組是private set,
link |
你今天上傳你的結果到cargo leaderboard的時候,
link |
你只能看到public set的分數,你沒有辦法看到private set的分數,
link |
private set的分數要等作業的deadline,你沒有辦法在上傳以後,
link |
你才會在一瞬間看到你的private set的分數,
link |
本來ranking上面show的是public的分數,
link |
它一瞬間翻過來變成private的分數。
link |
如果你今天做的是下面這個狀況,我用我的training data,
link |
train了三個model,我想知道哪一個結果是最好,
link |
所以我把三個model的結果通通傳到cargo的上面,
link |
在leaderboard上,它告訴我說model3給我的error是最好,
link |
一個人就覺得我做完了,我beat了baseline,
link |
但是private set你是看不到的,
link |
而private set的error通常是大於public set的error,
link |
所以你可能其實是沒有beat了baseline,
link |
所以下週六你可能就,下週五那個受驗deadline的時候,
link |
你可能就這樣子,這個是有可能發生的,
link |
先跟大家講一下,你不要太沮喪這樣子,
link |
比如說可能第三名的,我現在排第一排,
link |
因為你知道我是看得到private set的,
link |
比如前五名的,搞不好現在一排也是說不定的,
link |
比如說現在第一名的,他其實可能在四十幾名,
link |
所以這個private set的結果是不可靠的,
link |
就是你要把你的training set分成兩組,
link |
training set你要把它分成兩組,
link |
這兩組一組是真正拿來train model,
link |
我們把它也叫做training set,
link |
另外一組你不拿它來train model,
link |
你在這個training set上找出最好的方向,
link |
然後採用validation set來選擇你的model,
link |
你想要決定說我到底應該用model 1,
link |
然後你把這三個model用你的training set去train好以後,
link |
接下來看一下他們在validation set上面的performance,
link |
假設現在model 3的performance是最好的,
link |
那你可以直接把model 3的結果拿來apply在testing data上,
link |
如果你擔心說現在我把training set分成training跟validation,
link |
感覺training data變少的話,
link |
那你可以這麼做,已經決定model 3是最好的model,
link |
但是用全部的data在model 3上面再train一次,
link |
這樣你就可以使用全部的training data,
link |
這個時候如果你把這個modelapply到public set上面,
link |
你可能會得到一個大於0.5的error,
link |
雖然這麼做你得到的error表面上看起來是比較大,
link |
但是這個時候你在public set上面的error,
link |
才能夠真正反映你在private set上的error,
link |
當然我可以了解說有一種狀況是幾乎沒有辦法,
link |
就是在你的心情上基本上沒有辦法避免這麼做,
link |
因為通常你看到你的public set上結果太差,
link |
因為如果你回頭再去搞點什麼東西的話,
link |
你就變成又把這個public testing set的bias考慮進去了,
link |
這樣又變成說你在這個public testing set上所看到的performance,
link |
沒有辦法反映你在private set上面看到的performance,
link |
但我知道說在心情上你幾乎沒有辦法把持著不這麼做,
link |
你可能看到小毛ranking在你前面,
link |
但是你可以等到private set真正出來的時候,
link |
所以public set並不是最終的結果。
link |
你要test在benchmark corpus上面,
link |
當你在test在benchmark corpus上面的時候,
link |
如果你在testing set上得到一個差的結果,
link |
你也幾乎沒有辦法把持自己不回頭去挑一下你的model,
link |
你不會說我在testing set上得到一個差的結果,
link |
只是寫一個paper告訴他說這個方法不work,
link |
然後硬是在testing set上面把結果做起來,
link |
如果在benchmark corpus上面所看到的testing performance,
link |
它的error rate你可以說是假的,
link |
或者是它大於在real application上應該有的,
link |
在image net的corpus上面,
link |
它已經有這麼多人玩過這個corpus,
link |
你已經用testing set挑過參數了,
link |
所以如果你把那些model真的apply到現實生活中,
link |
它的error rate應該會是大於3%。
link |
比如說如果這個validation set其實也有怪怪的bias怎麼辦呢?
link |
這件事情是unfold cross-validation,
link |
也就是說如果你不相信某一次分train跟test的結果的話,
link |
比如說如果你做3-fold cross-validation,
link |
意思就是你把你的training set分成三份,
link |
你每一次拿其中一份當作validation set,
link |
你拿某一份當validation set,
link |
你拿某一份當validation set,
link |
如果你要知道model 1,2,3哪一個比較好的話,
link |
你就把這三個model通通在這一個情境下,
link |
這個做validation的情境下,
link |
你在這個情境下算一下它的error,
link |
你在這個情境下算一下它的error,
link |
然後你算一下它的average error,
link |
再train在你完整的training set上面,
link |
再去test在你的testing set上面。
link |
你在private set上面的分數,
link |
就是少去根據它調整你的model的話,
link |
你往往會在private set上面,
link |
得到的差距和testing set是比較小的。