back to index
ML Lecture 3-1: Gradient Descent
link |
好,各位同學,大家早。那我們就開始上課吧。
link |
好,那今天第一堂課我們要講的是Gradient Descent。
link |
Gradient Descent上次我們已經大概講過怎麼做了,但是有一些小技巧你可能是不知道的。
link |
所以我們要再詳細說明一下Gradient Descent,你要怎麼把它做得更好。
link |
好,那我們上次是這樣說的,在整個Machine Learning的第三個步驟,我們要找一個最好的function。
link |
找一個最好的function這件事是要解一個Optimization的Problem。
link |
也就是說在第二步我們先定了一個Loss function大L。
link |
這個Loss function它是一個function的function。
link |
你把一個function帶到這個Loss function裡面,或者是你把操控一個function形狀的參數。
link |
我們現在在這張投影片裡面把那些參數寫成θ,L是Loss function,θ是那些參數。
link |
你把一組參數帶到一個Loss function裡面,它就會告訴你說這組參數有多不好。
link |
那你接下來要做的事情就是,我一開始就發現這張投影片有一個地方寫錯了。
link |
這裡應該是minima,因為它是Loss function,Loss function我們是希望它越小越好。
link |
當然你也可以反過來定義一個function是參數越好,它的output值越大。
link |
但這個時候我們就不會叫它Loss function,我們會叫它別的名字,比如叫它Objective function。
link |
我們要找一組參數θ,讓這個Loss function越小越好。
link |
那這件事情怎麼做呢?我們可以用Gradient Descent。
link |
假設現在θ是一個參數的set,裡面有兩個參數,就是θ1跟θ2。
link |
那首先你先隨機的選取一個起始的點,隨機選取一組起始的參數。
link |
這邊寫成θ上標0下標1,θ上標0下標2。
link |
我用上標0代表說它是初始的那一組參數,然後用下標代表說這個是這一組參數裡面的第一個component跟第二個component。
link |
接下來你計算這個θ上標0下標1跟θ上標0下標2對這個Loss function的偏微分。
link |
計算他們的偏微分,然後把這個θ上標0下標1,θ上標0下標2減掉learning rate乘上這個偏微分的值,得到一組新的參數。
link |
這個參數這邊寫作θ上標1下標1,θ上標1下標2。
link |
θ上標1代表說它是在第二個時間點由θ上標0update以後得到的參數,下標代表說它有兩個component。
link |
同樣的步驟你就反覆不斷的進行,接下來你有θ上標1下標1和θ上標1下標2以後,
link |
你就一樣去計算他們的偏微分,再乘上learning rate,再去減θ上標1下標1和θ上標1下標2,得到下一組參數。
link |
那就反覆進行這個process,這個就是gradient descent。
link |
那如果你想要寫得更簡潔一點的話,其實可以這樣寫,假設你現在有兩個參數θ1和θ2,你把這個θ1和θ2對這個loss function做偏微分。
link |
你把這兩個偏微分的值串在一起變成一個vector以後,這個vector就叫做gradient,你把l前面加一個倒三角形,這個東西就叫做gradient,它其實是一個vector。
link |
所以你可以把這個式子寫成,你把這個東西寫成一個vectorθ上標1,這個東西寫成一個vectorθ上標0,這一項就是這一項,就寫成了這個l在θ0的地方的歸點。
link |
所以你可以把update參數簡單寫成,這個θ0就減掉這個learning rate乘上歸點就等於θ1,同理這個θ1減掉learning rate乘上歸點就得到θ2。
link |
而如果把它visualize的話,它看起來像是這個樣子,假設我們現在有兩個參數θ1和θ2,那你隨機的選一個初始的位置θ上標0。
link |
然後接下來你計算在θ上標0這個點,這個參數對loss function的歸點,假設參數對loss function的歸點是這個紅色的箭頭,歸點就是一個vector,它是一個紅色的箭頭。
link |
如果你不知道歸點是什麼的話,你就想成它是等高線的髮線方向,這個箭頭指的方向就是,如果你把loss的等高線畫出來的話,這個箭頭指的方向就是等高線的髮線方向。
link |
那怎麼update參數呢?你就把這個歸點乘上learning rate eta,然後再取一個負號,歸點乘上learning rate eta,再取一個負號,就是這個藍色的箭頭,再把它加上θ0就得到θ1。
link |
那這個步驟就反覆的持續進行下去,再計算一遍歸點,你得到另外一個紅色的箭頭。紅色的箭頭指向這個地方,那你現在走的方向就變成是紅色的箭頭的相反,紅色的箭頭乘上一個負號,再乘上learning rate,就是現在這個藍色的箭頭,得到θ2。
link |
那這個步驟就反覆一直進行下去,再算一下在θ2這個地方的歸點,然後再決定要走的方向,再算一次歸點,再決定要走的方向,這個就是歸點descent。
link |
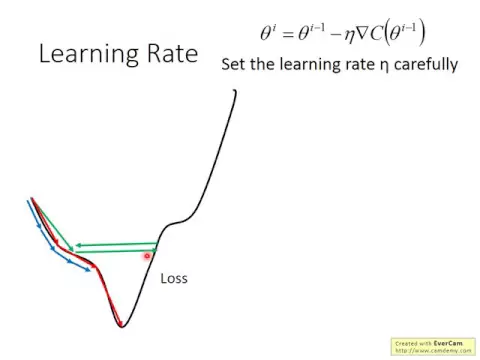
那我們上次其實都有講過了,那接下來要講一些歸點descent的tip,首先第一件事情就是你要小心的調你的learning rate,如果你已經開始做作業一的話,你會知道說有時候learning rate是可以給你造成一些問題的。
link |
舉例來說,假設這個是我們的loss function的surface,長這個樣子,如果你今天learning rate調得剛剛好的話,你從左邊這邊開始,那你可能就是順著紅色的箭頭很順利的走到了最低點。
link |
可是如果你今天learning rate調得太小的話,那他走的速度會變得非常慢,雖然只要給他夠多的時間,他終究會走到local minima的地方,但是如果他走得太慢的話,你會沒有辦法接受這件事情,你可能會來不及交作業。
link |
而如果你今天learning rate調得稍微大一點,比如說像綠色這個箭頭的話,那就變成說他的步伐太大了,他變得像一個巨人一樣,步伐太大了,他永遠沒有辦法走到特別低的地方,他都在這個山谷的口上面震盪,他永遠走不下去。
link |
那甚至如果你今天真的把learning rate調太大的話,他可能一瞬間就飛出去了,結果你update參數以後,loss反而越update越來越大。
link |
那其實只有在你的參數是一維或者二維的時候,你才能夠把這樣子的圖visualize出來。如果你今天是有很多維的參數,這個arrow的surface在一個高維的空間裡面,你是沒有辦法visualize他的,但是有另外一個東西你是可以visualize,什麼東西呢?
link |
你可以visualize參數的變化對這個loss的變化,你可以visualize每次參數update的時候loss的改變的情形。
link |
所以今天如果你learning rate設得太小的話,你就會發現說這個loss下降得非常非常慢。如果你今天learning rate調得太大的話,你在左邊這個圖會看到說loss先快速的下降,接下來他就卡住了。
link |
所以如果你learning rate調太大的話,你把參數的update對loss的變化做出來,你看到可能是綠色這一條線,而你的loss很快的下降,但很快就卡住了,很快就不再下降了。
link |
那如果你今天learning rate真的調太大了,你就會發現說你的loss就飛出去了,那你需要調整他,讓他調到剛剛好,那你才能夠得到一個好的結果。所以你在做gradient design的時候,你應該要把這個圖畫出來,而沒有把這個圖畫出來,會非常非常的卡。
link |
有的人就說他就把gradient的程式寫好,寫好放下去以後就開始跑上去打一場low這樣子,然後打完回來就發現說結果爛掉了,然後他也不知道爛在哪裡。
link |
所以如果你在做gradient design的時候,你應該把這個圖畫出來,然後你要先看一下他前幾次update參數的時候,他update的走法是怎麼樣,搞不好你learning rate一開始就調太大,他一下子就爆炸了,那你這個時候你就知道你要趕快調learning rate,你要確定他是穩定的下降,你才能去打low這樣子。
link |
但是要調learning rate很麻煩,有沒有辦法自動的調learning rate呢?有一些自動的方法可以幫我們調learning rate,最基本的而簡單的大原則是通常learning rate是隨著參數的update會越來越小的。
link |
為什麼會這樣呢?因為當你在剛開始的起始點的時候,他通常是離最低點的是比較遠的,所以你步伐要差大一點,走得快一點才能夠趕快走到最低點。
link |
但是經過好幾次參數的update以後,你已經比較靠近你的目標了,所以這個時候你就應該減少你的learning rate,讓他能夠收斂在最低點的地方。
link |
舉例來說,你learning rate的設法可能是這樣,你可以設成說這個learning rate是一個t-dependent的函數,他是dependent on你現在參數update的次數的。
link |
在第一次update參數的時候,你就把你的learning rate設成一個constant eta除以根號的t加1,這樣當你參數update的次數越多的時候,這個learning rate就會越來越小。
link |
那這樣是不夠的,我們需要因材施教,所以每個不同的參數,最好的狀況應該是每一個不同的參數都給他不同的learning rate。
link |
這件事情是有很多的小技巧的,其中我覺得最容易實做、最簡單的叫做adagrade。adagrade是這樣子的,他說每一個參數的learning rate都把它除上之前算出來的微分值的root mean square。
link |
什麼意思呢?我們原來的歸顛decent是這樣,假設w是某一個參數,現在這個w不是一組參數,我們現在只考慮一個參數。
link |
因為我們現在在做adagrade這樣的做法的時候,他是adaptive的learning rate,所以每一個參數都有不同的learning rate,所以我們現在要把每一個參數都分開來考慮。
link |
那w是某一個參數,那w的learning rate在一般的歸顛decent,你可能就給他一個dependent實踐值,比如說at。
link |
但是你可以把這件事情做得更好,在adagrade裡面,你把這個at除以這個sigma t,這個sigma t是什麼呢?這個sigma t是過去,這邊這個g是偏微分的值。
link |
這個sigma t是過去所有的微分值的root mean square,是過去所有微分值的root mean square。
link |
這個值對每一個參數而言,他都是不一樣,所以現在就會變成說不同的參數,他的learning rate都是不一樣。
link |
那我們來實際舉一個例子,來看看說這件事情是怎麼做。假設你現在初始的值是w0,接下來你就計算在w0那一點的微分,這邊寫做g0。
link |
然後呢,他的learning rate是多少呢?他的learning rate是eta0除掉sigma0,那eta0是一個時間dependent的參數,那eta0是什麼呢?eta0是一個參數dependent的參數。
link |
eta0他是過去所有算過的微分值的root mean square,那在這個case裡面,我們過去只算過一個微分值,就是g0。
link |
所以這個eta0呢,就是g0的平方在開根號。那接下來呢,你再update參數,你把w1呢,你把這個w0更新變成w1。
link |
在w1這個地方,你再算一次歸點,就是g1。那個g1的learning rate應該乘上多少呢?他要乘上eta1除以這個sigma1。
link |
那sigma1他是過去所有的微分值的root mean square,過去我們已經算過兩次微分值,一次是g0,一次是g1。
link |
所以sigma1呢,就變成g0跟g1的root mean square,也就是把g0平方加g1平方,再取平均值,再開根號。
link |
那w3一樣,update參數又得到w2,你有了w2以後,你可以算g2,在w2地方的微分值就是g2。
link |
他的learning rate呢,就是eta2除以sigma2。那這個sigma2呢,就是過去算出來微分值的root mean square,過去算出g0,g1,g2。
link |
把g0,g1,g2都平方,再平均,然後再開根號,得到sigma2,把他放在這邊,那update參數得到w3。
link |
這個步驟呢,就反覆地一直繼續下去,到第七次update參數的時候,你有一個微分值g2,那這個g2的learning rate呢,就是eta2除以sigma2。
link |
這個sigma2就是過去所有微分值的root mean square,過去已經算出g0,g1,g2,一直到gt。
link |
你就把g0,g1,g2,一直到gt,都取平方,再加起來,再平均,再開根號,得到sigma,就把他放在這邊。
link |
好,所以呢,現在如果我們用gradient descent,我們用algebra的時候呢,他update參數的式子呢,寫成這個樣子,而這個sigma t呢,我們就寫成這個樣子。
link |
這個root mean square,我們在前一頁的投影片已經看到了。
link |
好,那這個tie-dependent learning rate呢,你可以寫成eta除以根號t加1。那你會發現說,當你把這一項除以這一項的時候,因為他們都有根號t加1,所以根號t加1呢,是可以刪掉。
link |
所以整個algebra的式子呢,你就可以寫成,他的learning rate呢,你就可以寫成一個constant eta除掉根號過去所有gradient的平方和,但不用算平均。
link |
因為這個平均這件事情呢,會跟上面呢,tie-dependent的這個learning rate呢,抵消掉。好,所以呢,你在寫algebra的式子的時候,你可以簡化成,不需要把tie-dependent的這件事情explicit的寫出來,你就直接把你的learning rate寫成eta除以根號過去的算出來的gradient的平方,再開根號,就好。
link |
這個方法,你可以接受嗎?假如這邊大家有問題嗎?請說。
link |
我會說algebra的時候,他在後面下降的速度慢到令人髮指。就是他可能過了1000種資料的範圍,然後降到0.8。這其實是正常的。就是說,algebra呢,他的參數update其實是整體而言會是越來越慢的,因為他有加上tie-dependent。
link |
所以,如果你不喜歡這個結果的話,有很多比這個更強的方法。這個adaptive learning rate其實是一系列的方法。我今天講的adaptive learning rate其實是裡面最簡單的。還有很多其他的,他們都是用ada開頭,adaptive learning rate,adam啊,什麼之類的。
link |
如果你用別的方法,比如說adam的話,他就比較不會有這個情形。其實如果你沒有什麼特別偏好的話,你現在其實是可以用adam,他應該是現在我覺得最穩定的。
link |
但是他implement比較複雜就是了,但其實也沒有本事啦。好,講到這邊,大家有什麼問題嗎?好,那我其實有一個問題啦,我其實有一個問題。
link |
我們在做一般的gradient descent的時候,我們這個參數的update取決於兩件事情,一件事情是learning rate,另外一件事情是gradient。我們意思就是說,gradient越大,你參數update就越快。
link |
斜率算法越大,參數update就越快。我相信你可以接受這件事情。但是在adaptive learning裡面,你不覺得相當矛盾嗎?你不覺得有些怪怪的地方?這一項告訴我們,微分的值越大,你參數update越快。
link |
但這一項,它是相反的。這一項跟這一項,它們卻是不一樣的。你有沒有覺得說,這邊有一些奇怪的地方?
link |
也就是說,今天當你的gradient越大的時候,當你的gradient越大的時候,你底下算出來的這一項就越大。你底下算出來的這一項越大,你的參數update的步伐就越小。
link |
這不就跟我們原來要做的事情是有所衝突的嗎?在分母的地方告訴我們說,gradient越大,就怕的步伐越大,參數update越大。但是分母的地方卻說,如果gradient越大,參數update就越小。
link |
怎麼解釋這件事情呢?有一些paper是這樣解釋的。Anna Graham想要考慮的是,今天這個gradient有多surprise,也就是所謂的反差。
link |
反差,大家知道嗎?比如說反差萌的意思就是說,如果本來一個很兇惡的角色突然對你很溫柔,你就覺得他特別溫柔。所以對gradient來說也是一樣的道理。
link |
假設有某一個參數,他在第一次update參數的時候算出來的gradient是0.001,再要算0.001、0.003等等。到某一次,他gradient算出來是0.1,你就覺得特別大,因為他比之前的gradient算出來都大了100倍,特別大。
link |
但是如果是有另外一個參數,他一開始算出來是10.8,再上20.9,再上31.7,他的gradient平常都很大,但是他在某一次算出來的gradient是0.1,這時候你就會覺得他特別小。
link |
所以為了強調這種反差的效果,在Adagram裡面我們就把它除以這一項。這一項就是把過去這些gradient的平方把它算出來,我們就想要知道過去gradient有多大,然後再把它們相除,看看這個反差有多大。
link |
這個是直觀的解釋。更正式的解釋,我有這樣的解釋。我們來考慮一個二次函數。這個二次函數我們就寫成這樣子,他的一個參數就是x。
link |
如果我們把這個二次函數對x做為分的話,把這個y對x做為分,國中生就知道這是2ax加b,如果他絕對值算出來的話,長這個樣子。
link |
這個二次函數的最低點在哪裡呢?是-2ab,所以我國中就背過這個式子。如果你今天在這個二次函數上,你隨機的選一個點開始,你要做gradient descent,那你的步伐踏出去多大是最好的呢?
link |
假設這個起始的點是x0,最低點是-2ab,那踏出去一步,最好的步伐其實就是這兩個點之間的距離。
link |
因為你只要踏出去的步伐如果是這兩個點之間的距離的話,你就一步到位了。這兩個點之間的距離是什麼呢?你整理一下,它是2ax0加b除以2a。2ax0加b,這一項就是這一項。
link |
2ax0加b就是x0這一點的微分,就是x0這一點的一次微分。所以gradient descent就聽起來很有道理,就是說如果我今天算出來的微分越大,我就離原點越遠。
link |
如果踏出去的我最好的步伐是跟微分的大小成正比,所以如果踏出去的步伐跟微分的大小成正比,那它可能是最好的步伐。
link |
但是呢,這件事情是只有在只考慮一個參數的時候才成立。而如果我們今天同時有好幾個參數,我們要同時考慮好幾個參數的時候,這個時候剛才的論述就不見得成立了。
link |
也就是說,gradient的值越大,就跟最低點的距離越遠,這件事情在有好多個參數的時候是不一定成立的。比如說你想看看,我們現在考慮w1和w2這樣的參數。
link |
這個圖上面的顏色是它的loss。如果我們考慮w1的變化,我們就在藍色這條線這邊切一刀,我們把藍色這條線這邊切一刀,我們看到的這個arrow的surface長得是這個樣子。
link |
如果你比較這個圖上的兩個點,a點跟b點,那確實a點的微分值比較大,那它就距離最低點的是比較遠。
link |
但是如果我們同時考慮幾個參數,我們同時考慮w2這個參數,我們在綠色的這條線上切一刀。
link |
如果我們在綠色這條線上切一刀的話,我們得到的值是這樣子,我們得到的這個arrow surface是這樣子,它是比較尖的,而這個谷是比較深的。
link |
因為你會發現說,w2在這個方向的變化是比較猛烈的。
link |
如果我們只比較在w這條線上的兩個點,c跟d的話,確實c的微分比較大,所以它距離最低點的是比較遠。
link |
但是如果我們今天的比較是跨參數的話,如果我們比較a這個點對w1的微分,c這個點對w2的微分,這個結論就不成立了。
link |
雖然說c這個點的微分值對w2的微分值是比較大的,這個微分值是比較小的,但c是離最低點是比較近的,而a是比較遠。
link |
所以當我們update參數選擇跟微分值成正比,這樣的論述是在沒有考慮跨參數的條件下,這件事情才成立的。
link |
當我們要同時考慮好幾個參數的時候,我們這樣想就不足夠了。
link |
所以如果我們今天要同時考慮好幾個參數的話,我們應該要怎麼想呢?
link |
如果你看看我們說的最好的step的話,它其實還有分母這一項,它這個分母這一項是2a。這個2a哪來的呢?這個2a是什麼呢?這個2a它是如果我們今天把這個y做二次微分,我們做一次微分得到這個式子。
link |
那如果我們做二次微分的話,就得到2a,那它是一個constant,那這個2a就出現在最好的step分母的地方。
link |
所以今天最好的step它不只是要正比於一次微分,它同時要和二次微分的大小成反比的。
link |
如果你二次微分比較大,這個時候你參數的update量應該要小,如果二次微分小的話,你參數的update量應該要比較大。
link |
所以最好的step應該是要把二次微分考慮進來。
link |
所以如果我們今天把二次微分考慮進來的話,你會發現說在w1這個方向上,你的二次微分是比較小的,因為這個是一個比較平滑的谷,所以這個二次微分是比較小的。
link |
在w2的方向上,這個是一個比較尖的谷,比較深的谷,所以它是一個比較尖的谷,所以它的二次微分是比較大的。
link |
所以你光比較a跟c的微分值是不夠的,你要比較a的微分值除掉它的二次,跟c的微分值除掉它的二次,再去比。
link |
如果你做這件事,你才能夠真正顯示這些點跟最低點的距離。
link |
雖然a這個點它的微分是比較小,但它的二次也同時是比較小,c比較大,二次是比較大的。
link |
所以如果你把二次微分的值考慮進去做平減的話,做調整的話,你這個時候才能夠真正反映你現在所在的位置跟最低點的距離。
link |
好,那這件事情跟阿達館的關係是什麼呢?如果你把阿達館的式子列出來的話,它參數的update量是這個樣子的。
link |
這個GTR它就是一次微分,對不對?下面這個過去所有微分值的平方和開根號,神奇的就是它想要代表的是二次微分。
link |
你可能會問說,怎麼不直接算二次微分呢?你可以直接算二次微分,確實可以這麼做,也有這樣的方法,而且你確實可以這麼做。
link |
但是有時候你會遇到的狀況是,當然在這個作業一裡面是比較簡單的case,我相信你都秒算,電腦都秒給你結果。
link |
但是在有時候你參數量大,你data多的時候,你可能算一次微分就花一天,然後你再算二次微分,你要再多花一天。
link |
有時候這樣子的結果是你不能承受的,而且你多花一天performance還不見得會比較好,但有時候這個結果是你不能承受的。
link |
所以阿達館它提供的做法就是,我們在沒有增加任何額外運算的前提之下,想辦法能不能夠做一件事情去估一下二次的微分應該是多少。
link |
在阿達館裡面,你只需要一次微分的值,這個東西我們本來就要算它了,所以並沒有多做任何多餘的運算。
link |
怎麼做呢?如果我們考慮一個二次微分比較小的峽谷跟一個二次微分比較大的峽谷,然後我們把它的一次微分的值考慮進來的話,這個是長這樣。
link |
如果你只是在這個區間和這個區間裡面隨機sample一個點算它的一次微分的話,你看不出來它的二次微分的值是多少。
link |
但是如果你sample夠多點,你在某一個range之內sample夠多點的話,那你就會發現說,在這個比較平滑的峽谷裡面,它的一次微分通常就是比較小。
link |
在比較尖的峽谷裡面,它的一次微分通常就是比較大。而阿達館這邊這件事情,summation over過去所有的微分的平方這件事情,你就可以想成是在這個地方做sampling。
link |
就在這個地方做sampling,然後你再把它的平方和再排根號算出來,那這個東西就反映了二次微分的大小。這個阿達館怎麼做,我們其實上次已經有示範過了,所以我們就不再示範。
link |
接下來我們要講的另外一件事情是stochastic的gradient descent,那它可以讓你的training更快一點。這個怎麼說呢?我們之前講說我們的loss function,它的樣子是,如果我們今天做的是regression的話,這個是regression的式子,
link |
這個是regression得到的estimation的結果。而regression得到estimation的結果,減掉white hat,再取平方,再summation over所有的training data,這個是我們的loss function。
link |
所以這個式子非常合理,我們的loss本來就應該考慮所有的sample,所以它本來就應該summation over所有的sample,那有這些以後,你就可以去算gradient,然後你就可以做gradient descent。
link |
但是stochastic gradient descent它的想法不一樣,stochastic gradient descent它做的事情是,每次就拿一個xn出來,這邊你可以隨機取,也可以按照順序取。
link |
那其實隨機取的時候,如果你今天是在做deep learning的case,也就是你的error surface不是convex,是非常崎嶇的,隨機取是有幫助的。總之,你就取一個example出來,假設取算example是xn。
link |
這個時候,你要計算你的loss,你的loss只考慮一個example,你只考慮你現在的參數,對這個example的y的估測值,再減掉它的正確答案,再做平方。
link |
然後就不summation over所有的example,因為你現在只取一個example出來,你只算某一個example的loss。那接下來呢,你在update參數的時候,你只考慮那一個example。
link |
我們只考慮一個example的loss function,我們就寫成l上標n,代表它是考慮第n個example的loss function。那你在算gradient的時候呢,你不是算對total所有的data它的gradient的和,你只算對某一個example它的loss的gradient,然後你就很急躁的update參數了。
link |
所以在原來的gradient descent裡面,你計算所有data的loss,然後才update參數。但在soprastic gradient descent裡面,你看一個example,就update一個參數。
link |
而且想說,這有啥好呢?聽起來好像沒有什麼好的。那我們實際來操作一下好了。我覺得,我怎麼看不到自己的頁面?剛才看到的圖呢,它可能是這個樣子。
link |
原來的gradient descent呢,你看完所有的example以後,你就update一次參數。那它其實是比較穩定,發現說它走的方向就是按照gradient建議我們的方向來走。
link |
但是如果你是用soprastic gradient descent的話,你每看到一個example,你就update一次參數。如果你有20個example的時候,那你就update20次參數。
link |
那這邊它是看完20個example才update一次參數,這邊是每一個example都update一次參數。所以在它看20個example的時候,你這邊也已經看了20個example前update20次參數了。
link |
所以update20次參數的結果看起來就像是這樣,從一樣的起始點開始,但它已經update了20次參數。如果只看一個example的話,它的步伐是小的,而且可能是散亂。
link |
因為你每次只考慮example,你只考慮一個example,所以它參數update的方向跟gradient descent跟total loss的error surface建議我們走的方向不見得是一致的。
link |
但是因為我們可以看很多個example,所以天下武功唯快不破,在它走一步的時候已經出20圈了,所以它走的反而是比較快。
link |
然後接下來我們要講的是第三個tip,就是你可以做feature scaling。所謂feature scaling的意思是這樣子。
link |
假設我們現在要做regression,那我們的regression function裡面input的feature有兩個x1跟x2,比如說如果是要predict寶可夢進化後的CP值的話,可能x1是進化前的CP值,x2是它的生命值等等。
link |
你有兩個input的feature,x1跟x2。那如果你看,如果你今天的x1跟x2它們的分佈的range是很不一樣的話,那就建議你把它們做scaling,把它們的range的分佈變成是一樣的。
link |
舉例來說這邊x2它的分佈是遠比x1大,那就建議你把x2這個值做一下rescaling,把它的值縮小,讓x2的分佈跟x1的分佈是比較像。
link |
你希望不同的feature,它們的scale是一樣的。為什麼要這麼做呢?我們舉一個例子。假設這個是我們的regression function,然後寫成這樣,這個意思跟這邊是一樣的。
link |
y等於b加w1x1加w2x2,y等於b加w1x1加w2x2。假設x1它的平常的值都是比較小的,比如說1,2之類的。
link |
假設x2它平常的值都很大,它的input值都很大,都是100,200之類的。那這個時候如果你把loss的surface畫出來,會遇到什麼樣的狀況呢?你會發現說呢,如果你更動w1跟w2的值,
link |
假設你把w1跟w2的值都做一樣的更動,都加個delta w,你會發現說w1的變化對y的變化而言是比較小,w2的變化對y的變化而言是比較大。
link |
這件事情是很合理的,因為你要把w2乘上它input的這些值,你要把w1乘上它input的這些值。如果w2乘的input值是比較大的,那你只要把w2做小小的變化,那y就會有很大的變化。
link |
那同樣的變化,w1如果你給它同樣的變化,因為它input值是比較小,所以它對y的影響就變得是比較小。所以如果你把他們的error surface畫出來的話,你看到的可能像是這個樣子。
link |
這個圖是什麼意思呢?因為w1的變化對loss的w1對y的影響比較小,所以w1就對loss的影響比較小。
link |
所以w1對loss是有比較小的微分的,所以w1這個方向上它是比較平滑的。w2對y的影響比較大,所以它對loss的影響比較大。所以改變w2的時候對loss的影響比較大,所以它在這個方向上是比較sharp的,所以這邊是這個方向上有一個比較尖的峽谷。
link |
那如果今天x1跟x2它們的值scale是接近的,那如果你把loss畫出來的話,它就會比較接近原型,w1跟w2對你的loss是有差不多的影響力。
link |
這個對做gradient descent會有什麼樣的影響呢?是會有影響的,比如說如果你從這個地方開始,其實我們上次已經有看到了,這樣子這種長橢圓的error surface,如果你不出些anagram什麼的,你是很難搞定它的。
link |
因為不同的,就在這個方向上和這個方向上,你會需要非常不同的learning rate,你同一組learning rate會搞不定它,你一定要有adaptive learning rate才能夠搞定它。
link |
那這樣子的狀況,沒有scaling的時候,它的update參數是比較難的,但是如果你有scale的話,它就會變成一個正原型,如果是在正原型的時候,update參數就會變得比較容易。而且你知道說gradient descent它並不是向著最低點走,比如說在這個藍色的圈圈裡面最低點是在這邊,綠色的圈圈裡面最低點是在這邊。
link |
但是你今天在update參數的時候走的方向是順著等高線的方向,是順著gradient進入的方向,所以雖然最低點在這邊,你從這邊開始走,你還是會走這個方向,再走進去,你不會指向最低點去走。
link |
但如果是綠色的,綠色就不一樣,因為它如果真的是一個正原的話,你不管在這個區域的哪一個點,不管在這個區域的哪一個點,它都會向著原型走。所以如果你有做feature scaling的時候,你在做參數的update的時候,它是會比較有效率。
link |
那你可能會問說怎麼做scaling,這個方法有千百種,你就選一個你喜歡的就是了。常見的做法是這樣,假設我有R比example,X1,X2到XR,每一比example裡面都有一組feature,
link |
所以X1它有它的第一個component就是X1-1,X2它的第二個component就是X2-1,X1它的第二個component就是X1-2,X2的第二個component就是X2-2。
link |
那怎麼做feature scaling,你就對每一個dimension i都去算它的mean,這邊寫成mi,都去算它的standard deviation,這邊寫成sigma i,然後對第二個example的第二個component,
link |
你就把它減掉所有data的第二個component的mean,也就是ni,把它減掉所有data的第二個component的mean,再除掉所有data的第二個component的standard deviation。
link |
然後你就會得到說,你做完這件事以後,你所有dimension的mean就會是0,那你的variance就會是1,這是其中一個常見的做normalization的方法。
link |
最後在下課前呢,我們來看一點,我們來講一下為什麼gradient descent它會work,gradient descent背後的理論基礎是什麼,那在真正深入數學的部分之前呢,我們來問大家一個問題。
link |
大家都已經知道gradient descent是怎麼做,假設我問你這樣一個示範題,每一次我們在update參數的時候,我們都得到一個新的setup,這個新的setup總是會讓我們的loss比較小,這個乘數是對的嗎?
link |
好,也就是說,意思就是說,setup0你把它帶到l裡面,它會大於setup1帶到l裡面,它會大於setup2帶到l裡面,我們每次update參數的時候,這個loss的值它都是越來越小的,這個乘數是正確的嗎?
link |
你覺得它是正確的同學舉手,沒有啊,你覺得這個乘數是不對的同學舉手,好,手放下,好,大家的觀念都很正確,沒錯,就是update參數以後,loss不見得會下降的。
link |
如果你今天自己implement gradient descent做出來後,update參數的loss沒有下降,那不見得是你的乘數有差,因為本來就有可能發生這種事情,我們剛才看過說,如果你learning rate調太大的話,會發生這種事情,或許我們可以在下課前做一個demo。
link |
好,那在解釋gradient descent的theory之前,這邊有個warning of math,意思就是說,這個部分就算是你沒聽懂,也沒有關係,太陽明天就會升起。
link |
好,那我們先不要管gradient descent,我們先來想想看,假如你要解一個optimization problem,你要在這個figure上面找它的最低點,你到底應該要怎麼做?
link |
那有一個這樣的做法,如果今天給我一個起始的點,也就是θ0,我們有方法在這個起始點的附近畫一個圓圈,畫一個範圍,畫一個紅色圈圈,然後在這個紅色圈圈裡面找出它的最低點。
link |
比如說假設紅色圈圈裡面的最低點就是在這個邊上。這個意思就是說,如果你給我一整個arrow function,我沒有辦法馬上一秒鐘就告訴你說,我沒有辦法馬上告訴你說它的最低點在哪裡。
link |
但是如果你給我一個arrow function加上一個初始的點,我可以告訴你說,在這個初始點的附近畫一個範圍之內,哦,有問題,是嗎?
link |
謝謝,謝謝,沒問題。我們可以在那個附近找出一個最小的值。
link |
假設找到最小的值以後,我們就更新我們的中心的位置,把中心的位置挪到θ1,接下來再畫一個圓圈,我們可以在這個圓圈範圍之內再找一個最小的點,假設它是落在這個地方。
link |
然後你就再更新中心點的參數到θ2這個地方,然後你就可以再找小小範圍之內的最小的值,然後再更新你的參數,就一直這樣子下去。
link |
好,那現在的問題就是,怎麼很快地在紅色的圈圈裡面找一個可以讓Loss最小的參數呢?
link |
怎麼做這件事呢?這個地方就要從Taylor Series說起,假設你是知道Taylor Series,因為這個微積分有教過。
link |
Taylor Series告訴我們什麼呢?它告訴我們說,任何一個function h of x,如果它在x等於x0這一點呢,是infinitely differentiable,
link |
那你可以把這個h of x寫成以下這個樣子,你可以把h of x寫成summation over k等於0到無窮大,這個k代表那個微分的次數,
link |
k階分之h為k次of x0,h在x0這個地方微分k次以後的值,然後x減x0的k次吧。不把它展開的話,你可以把h of x寫成h of x0加上h prime of x0乘以x減x0,
link |
加上二階分之h double prime of x0,x減x0的平方。當x很接近x0的時候,那x減x0就會遠大於x減x0的平方,
link |
就遠大於後面的三次四次到無窮多次,所以這個時候你可以把後面的高次項就把它刪掉,所以當x很接近x0的時候,在x很接近x0的時候才成立,
link |
h of x就可以寫成h of x0加上h prime of x0乘上x減x0。這個是只有考慮input一個variable的case,這邊有個例子,假設h of x是sin x,
link |
那在這個x0約等於四分之pi的地方,sin x就可以寫成什麼樣子呢?你用計算機算一下,算出來是這樣子。所以這個sin x可以寫成這麼多這麼多這麼多項的項加。
link |
好,那如果我們把這些項把它畫出來的話,你得到這樣子一個結果。如果是1除以根號2只有考慮0次的話,是這條水平線。
link |
考慮1除以根號2加x減四分之pi除以根號2考慮一次的話,是這條斜線。如果你有再把二次考慮進去考慮0次一次二次的話,我猜你得到的可能是這一條線。
link |
如果你再把三次考慮進去的話,你得到這一條線。如果你再把四次考慮進去的話,你可能得到是橙色這一條線。但是,雖然說比如說你看,橙色這一條線應該是sin,
link |
好,那你發現說如果你只有考慮一次的時候,它其實跟sin橙色這一條線差很多,更不像。但是它在四分之pi的附近,在這個地方附近,它是像。
link |
因為如果x很接近四分之pi的話,那後面這些像,有平方向三次方向這些都很小,所以就可以忽略它們只考慮一次的部分。
link |
那這個tether series也可以是有好幾個參數的,如果今天有好幾個參數的話,那你就可以這樣做,這個h of xy,假設這個function有兩個參數,它在x0和y0附近,你可以把它寫成,
link |
這個h of xy,你可以用這個tether series把它展開成這樣,就有0次的,有考慮x減x0的,有考慮y減y0的,還有考慮x減x0平方跟y減y0平方。
link |
如果今天xy很接近x0y0的話,那平方向就可以被消掉,就只剩這個部分。所以今天xy如果很接近x0y0的話,那h of xy就可以寫成約等於h of x0y0,
link |
加上x減x0乘上在x0y0這個位置對x做偏微分,y減y0乘上在x0y0這個位置對y做偏微分。這個偏微分的值你不要看它這麼複雜,它其實就是,微分的值就是一個constant而已,就是一個常數項而已。
link |
這個是一個常數項,這個是一個常數項。如果我們今天考慮我們剛才講的問題,如果今天給我一個中心點,就是A跟B,那我畫了一個很小很小的圓圈,紅色的圓圈,假設它是很小的。
link |
在這個紅色圓圈的範圍之內,我其實可以把loss function用Taylor series做簡化,我可以把loss function L of theta寫成L of AB,加上theta1對loss function的偏微分,在AB這個位置的偏微分,乘上theta1減A,加上theta2對loss function在AB這個位置的偏微分,再乘上theta2減1,減減B。
link |
所以在紅色的圈圈內,loss function可以寫成這樣子。
link |
那我們把L of AB用一個,它就是一個constant,你把L用AB代進去,它就是一個constant,所以我們用AS來表示。那theta1對L的偏微分在AB這個位置,這個也就是一個constant,所以我們用U來表示。這個也是一個constant,用B來表示。
link |
這樣這個式子看起來就非常簡單了。所以在這個範圍之內,L對theta跟theta1,所以在紅色圈圈範圍內,這個式子是非常簡單的,就寫成左下角這個樣子。
link |
再來,如果告訴你說,紅色圈圈內的式子就長這個樣子,你能不能秒算哪一個theta1跟theta2可以讓它的loss最小呢?我相信你可以秒算這個結果,不過我們還是很快稍微看一下。
link |
L寫成這樣,SUV都是常數,我們就把它放在藍色的框框裡面,不用管它值是多少。我們現在的問題就是,在紅色的圈圈內找theta1跟theta2,讓loss最小。
link |
那所謂的在紅色圈圈內的意思就是說,紅色圈圈的中心就是A跟B,所以你這個theta1-A的平方加上theta2-B的平方應該小於等於D,他們要在紅色圈圈的範圍內。
link |
這件事情其實就是秒算,對不對?太簡單了,一眼就可以看出來。如果你今天把theta1-A都用delta theta1來表示,theta2-B都用delta theta2來表示,S你可以不用理它,因為S跟theta沒關係,所以你要找不同的theta讓它值最小,你就不用管S。
link |
如果我們看一下L,你會發現說它是U乘上delta theta1,B乘上delta theta2,也就是說它的值就是有一個vector叫做delta theta1,delta theta2,有另外一個vector叫做U跟B。
link |
你把這個vector跟這個vector做inner product,也就是把delta theta1乘上U加delta theta2乘上B,你就得到這個值,如果我們忽略S的話,你就得到這個值。
link |
接下來的問題就是,如果我們要讓L of theta最小,我們應該選擇什麼樣的delta theta1跟delta theta2呢?我們要選擇什麼樣的delta theta1跟delta theta2,我們才能夠讓L of theta最小呢?
link |
太容易了,就是選正對面的。如果我們今天把delta theta1跟delta theta2轉成跟UV正朝反方向,然後再把delta theta1跟delta theta2的長度增長,
link |
長到呢,我們把它轉到反方向,再把它增長,長到極限,也就是長到這個紅色圈圈的邊緣。
link |
那這一個delta theta1跟delta theta2跟UV,它們做inner product的時候,它的值是最大的。
link |
所以這告訴我們說,什麼樣的delta theta1跟delta theta2可以讓Loss的值最小呢?就是它是UV乘上負號,再乘上一個scale,再乘上一個constant,
link |
也就是你要把delta theta1跟delta theta2調整它的長度,長到正好抵到這個紅色圈圈的邊邊,這個時候它算出來的Loss是最小的。
link |
所以這個theta應該是跟這個長度是成正比的。
link |
好,所以我們再整理一下式子,delta theta1就是theta1-a,delta theta2就是theta2-b。
link |
所以如果我們今天要在紅色圈圈裡面找一個theta1跟theta2讓Loss最小的話,那怎麼做呢?
link |
那個最小的值就是中心點AB減掉的某一個constant乘上U跟V。
link |
好,所以我們就知道了這件事,那你接下來要做的事情就是把U跟V,U跟V把它帶進去,把它帶進去就得到這樣子的式子。
link |
那這個式子,你會發現它其實呢,exactly就是Gradient Descent,對不對?
link |
我們做Gradient Descent的時候就是找一個初始值,算每一個參數在初始值的地方的偏微分,把它排成一個vector,就是Gradient,
link |
再乘上某一個東西叫做Linearly,再把它減掉。
link |
所以這個式子,exactly就是Gradient Descent的式子。
link |
但你要想想看我們今天可以做這件事情,我們可以用這個方法找一個最小值,它的前提是什麼?
link |
它的前提是你的這個上面這個式子要成立,你Teleseries給你的這個approximation是夠精確。
link |
怎麼樣Teleseries給我們的approximation才會夠精確呢?
link |
當你今天所畫出來的那個紅色圈圈夠小的時候,Teleseries給我們的approximation才會夠精確。
link |
這告訴我們說,你那個紅色圈圈的半徑是小,那這個eta這個learning rate呢,它跟紅色圈圈的半徑是成正比的。
link |
所以這個learning rate不能太大,你learning rate要很小,你這個learning rate要無窮小的時候呢,這個式子才會成立。
link |
所以Gradient Descent如果你要讓你每次update參數的時候,你的loss都越來越小的話,其實理論上你的learning rate要無窮小你才有辦法保證這件事情。
link |
所以你會發現說,如果你learning rate沒有設好,是有可能說你每次update參數的時候,這個式子是不成立的。
link |
所以導致你做Gradient Descent的時候,你沒有辦法讓loss越來越小。
link |
那你會發現說,這個L呢,它只考慮了calculus series裡面的一次式,可不可以考慮二次式呢?
link |
calculus series裡面不是有二次嗎?還有三次嗎?還有很多嗎?
link |
如果你把二次式考慮進來,如果你把二次式考慮進來,理論上你的learning rate就可以設得大一點,對不對?
link |
如果我們把二次式考慮進來,可不可以呢?是可以的。有一些方法,我們今天沒有要講是有考慮到二次式的,比如說牛頓法。
link |
那在實作上,尤其是假設你在做deep learning的時候,這樣的方法並不見得太普及,不見得那麼practical。
link |
為什麼呢?因為你現在要算二次微分,甚至它還會包含一個Hessian的matrix,還有Hessian matrix的inverse,總之你會多很多運算。
link |
而這些運算在做deep learning的時候呢,你是無法承受的,你用這個運算來換你update的時候比較有效率,你是會覺得是不划算。
link |
所以如果今天在做deep learning的時候,通常還是Gradient descent是比較普及主流的做法。
link |
上面如果你沒有聽懂的話也沒有關係,那最後一頁我們要講的是Gradient descent的限制。
link |
Gradient descent有什麼樣的限制呢?有一個大家都知道的就是它會卡在local minima的地方。
link |
所以如果這是你的error surface,那你從這個地方當作你的初始值,去更新你的參數,最後走到一個微分值是0,也就是local minima的地方,你參數的更新就停止了。
link |
但是一般人就只知道這個問題而已,但其實還有別的問題。
link |
事實上這個微分值是0的地方並不是只有local minima,對不對?Zero point也是微分值是0。
link |
所以你今天在參數update的時候,你也是有可能卡在一個不是local minima,但是微分值是0的地方,這件事情也是有可能發生的。
link |
但是其實卡在local minima或卡在微分值是0的地方,這都只是幻想,其實真正的問題是這樣。
link |
你想想看,你今天implement作業儀了,你幾時是真的算出來微分值exactly等於0的時候就把它停下來的?
link |
你是不是最多就做微分值小於10的-60,小於一個很小的值就把它停下來了,對不對?
link |
但是你怎麼知道微分值算出來很小的時候,它就很接近local minima,它不見得很接近local minima?
link |
有可能微分值算出來很小,但是它其實是在一個高原的地方,而那個高原的地方微分值算出來很小,你就覺得說,那這個一定就是很接近local minima,在local minima附近,所以你就停下來。
link |
因為你很少有機會真的算出來微分值exactly是0嘛,對不對?你可能覺得說微分值算出來很小,就很接近local minima,你就把它停下來。
link |
那其實搞不好它是一個高原的地方,它離local minima還很遠啊,這也是有可能的。
link |
然後講到這邊,有人都會問我一個問題,因為目前我很難回答,他說,你怎麼會不知道你是不是接近local minima的呢?
link |
我一眼就知道說local minima在這邊啊,你怎麼會不知道呢?
link |
所以我覺得這些圖都沒有辦法表示歸根底線的解釋,我們來看一下。