back to index
ML Lecture 6: Brief Introduction of Deep Learning
link |
好,那Deep Learning現在非常的熱門,所以它可以用在什麼地方,我覺得真的還不需要多講,我覺得大家搞不好知道都比我更多。
link |
我相信你隨便用Deep Learning當作關鍵字,胡亂Google一下,你就可以找到一大堆的exciting的result。
link |
所以我就直接用這個圖來簡單的summarize一下這個趨勢,而這個圖是Google的Jeff Dean,他在Sigmoid的keynote speech的一張投影片。
link |
這個圖想要表達的事情是這樣,橫軸代表時間,從2012的Q1到2016,而縱軸代表說在Google內部有用到Deep Learning的花學的數目,可以發現這個趨勢是從幾乎零到超過兩千。
link |
使用Deep Learning的花學數目是指數成長,那如果你看它的應用的話,它有各種各樣的應用涵蓋幾乎你所有可以想像的領域,
link |
像是Android、Apps、Drop Discovery、Gmail、Image Understanding、Natural Language Understanding、Speech,各種各樣的應用,通通有用到Deep Learning。這個Deep Learning可以做的應用實在是太多了,我們這邊就不要花時間來講這些東西,如果要講這些東西的話,再用兩三堂課其實也是講不完的。
link |
這個隨便Google就有的東西我們就不要再講述。我們來稍微回顧一下Deep Learning的歷史,在歷史上它是有經過好幾次的層層符符的。
link |
首先在1958年有一個技術叫做Perceptron被提出來,Perceptron這個技術它也是一個linear的model,它非常非常像我們在前一堂課講的Logistic Regression,它只是沒有Sigmoid的部分而已,但它還是linear的model。
link |
一開始有人提出Perceptron這個想法的時候,大家非常非常的興奮,這個是Fred Rosenberg在一個海軍的project裡面提出來的,一開始提出來的時候大家覺得非常非常興奮。
link |
那時候要做Perceptron的運算,如果你看那個B-Shop教科書裡面有一張機器的圖,看起來是一個房間那麼大的機器。那時候New York Times據說還寫了一個報導說,從此以後人工智慧就要產生了,電腦可以自己學習了,就像是現在這個樣子。
link |
可是後來有人就寫了一本教科書,我覺得這個教科書的名字就叫做Perceptron,在這個教科書裡面它就指出了linear的model是有極限的,就像我們在上一張投影片裡面講的,linear model有很多事都辦不到,就像是我們剛才舉的那個那麼簡單的example,它都辦不到,然後大家希望就破滅了。
link |
當時在1958年剛提出Perceptron的時候,有各種驚人的application,就像今天Deep Learning一樣。有人就說,我用了Perceptron,結果我可以分辨說,給我一張照片,那照片裡面有坦克或者是一般的卡車,那他可以正確地分辨說,哪些照片裡面是坦克,哪些照片裡面是卡車。
link |
就像那些坦克被藏在叢林裡面,有一半被樹木蓋住,也偵測得出來,其他人就覺得說,太厲害了,這是人工智慧。可是既然Perceptron有這樣的,後來大家就發現說,Perceptron其實是很有limitation的,那怎麼可能分辨得出卡車跟坦克這麼複雜的option呢?
link |
所以有人就去把那個data再拿出來看了一下,就發現說,原來卡車跟坦克的照片是在不同的日子所拍攝的,所以一天是雨天,一天是晴天,所以那個照片本身的亮度就不一樣了,所以Perceptron他唯一抓到的東西就只有亮度而已。
link |
所以大家就崩潰了,這個方法的名字就臭掉了。後來就有人想說,那既然一個Perceptron不行,我能不能夠接很多Perceptron,就像我們剛才講的,把logistic regression都接在一起,他應該就很powerful,這個就叫做multilayer的Perceptron。
link |
事實上,1980年代,multilayer的Perceptron的技術基本上在1980年代的時候就都開發得差不多了,那個時候已經開發完成的技術其實就跟今天的deep learning是沒有太significant的差別的。
link |
有一個關鍵的技術是,1986年的時候,Hinton proposed a backpropagation,其實很多人同時也有proposed a backpropagation,但大部分人把這個credit歸給Hinton的paper,那篇paper是比較著名的。
link |
但是在那個時候遇到的問題就是,通常超過三個layer的neural network,你就勸不出好的結果,通常一個還可以,再多你就勸不出好的結果。後來在1989年,有人就發現了一個理論,就是說一個hidden layer其實就可以model任何可能的function。
link |
只要一個neural network有一個hidden layer,它就可以是任何的function,它就已經夠強了,所以根本沒有必要疊很多個hidden layer,所以這個multilayer perceptron的方法又臭掉了。
link |
然後大家就都比較喜歡做SVM,那這個方法就臭掉了,據說那陣子呢,這個multilayer perceptron這個方法,也就是也有人叫它neural network這個方法,它就像是一個髒話一樣,寫在paper裡面就是保證paper一定會被reject。
link |
然後後來呢,有人就想到一個突破的點,這個突破點的關鍵的地方就是把它改個名字,因為這個方法已經臭掉了,所以只好改一個名字,就改成dictory,整個就抄起來。
link |
改名字其實是有很大的力量的,現在都沒有人念博士,我們應該把博士改換另外一個名字,大家就想念了,我下次跟系主任建議一下。
link |
好,那很多人覺得說有一個關鍵的技術是,Hinton在06年提的,用restricted Boltzmann machine做initialization,那很多人覺得說這是個突破。
link |
甚至有一陣子,大家的認知是,到底deep learning跟1980年代的multilayer perceptron有何不同呢?它的不同之處在於,如果你有用restricted Boltzmann machine做initialization,你在做威廉底線的時候不是要找一個初始的值嗎?
link |
如果你是用RBN找的,叫deep learning,你沒有RBN找,是傳統的1980年代的multilayer perceptron。後來大家逐漸意識到說,restricted Boltzmann machine這個方法非常的複雜。
link |
假設你是machine learning的初學者的話,你看那個paper,我相信你是看不懂的。如果我們今天要講restricted Boltzmann machine,要從現在開始,假設用我們上課已經講過的那些知識,要講到你聽懂,我覺得要再另外多講三周。
link |
它是有用到一些比較深的理論,讓大家覺得說,哇,這個這麼複雜,一定就是非常的powerful。而且它不是neural network based的方法,它是graphical model。大家覺得說,這個這麼複雜,我一看都看不懂,這個一定是有用的。
link |
後來大家逐漸試來試去以後就發現說,這招其實沒什麼用。你可以發現說,如果你讀deep learning的文獻,現在已經不太有人用restricted Boltzmann machine做initialization,因為這一招帶給我們的幫助並沒有說特別大。
link |
連Hinton自己都知道這一點,他有在某一篇paper裡面提過這件事情,大家可能都沒有注意到那篇paper就是了。但是它有一個最強的地方,它最強的地方就是它讓大家重新再次對這個model有了興趣。
link |
因為它很複雜,所以大家就會開始想要研究deep learning是什麼樣的東西,就花很多力氣去研究。所以我其實聽過有一個Google的人對restricted Boltzmann machine的評論,他說這個方法就是石頭湯裡面那個石頭。
link |
石頭湯的故事大家聽過嗎?就有一個人說,我要煮一個石頭湯。有一個士兵他在一個村莊裡面借樹,他說,我要煮一碗石頭湯。然後大家就說,你要怎麼煮一碗石頭湯?我用石頭就可以了,就用石頭煮一碗湯。
link |
他就說,如果再加點鹽就更好了,就加點鹽。再加點米就更好了,就加點米。再加點菜就更好了,就再加點菜。然後就煮了一鍋湯,然後大家就覺得,哇,這好好的用石頭可以煮湯。但是那個石頭其實沒有什麼作用,所以其實RPM就類似這種東西。
link |
然後呢,我覺得有一個關鍵的圖謀是,2009年的時候,我們知道要用GPU來加速。這些事情還頗關鍵的。過去如果你做什麼deep learning train一次,一周就過去了,然後結果實驗失敗,你就不會想要再做第二次了。
link |
其實我多年前有跟一個學弟試著想要做deep learning,那個時候還不知道要疊很多層,那時候大家都疊一層。直覺想法就知道說,一定要疊很多層啊,怎麼會只有疊一層。
link |
就想說,我們來把它疊很多層吧,然後我們就來開始做,然後train一次要一周,train完以後結果沒有比較好,就沒有人想要再有戲去把它做下去。本來想要找專題生做,專題生也都不想做,就沒有人要做,那個題目就沒有人要做了。那時候如果我們把它好好做出來的話,我們現在就發了。
link |
不過那時候我們不知道要用GPU,所以train一次要一周,所以我想要做出來也是很難。我現在有GPU以後,本來要train一周的東西,你可能幾個小時就可以把它看到結果了。
link |
在2011年的時候,這個方法被引入到語音辨識裡面,開始語音辨識的人發現說,這招果然很有用,大家都開始瘋狂地用deep learning的技術。到2012年的時候,deep learning的技術贏了一個很重要的image的比賽,所以大家在image那邊的人也瘋狂地用deep learning的技術。
link |
其實deep learning的技術並沒有真的很複雜,它其實非常簡單。我們之前講說machine learning就是三個step,其實deep learning也一樣就是這三個step。
link |
講說deep learning就是這三個step,就好像是說把大象放進冰箱一樣。大象放進冰箱,大家知道嗎?把門打開,把大象趕進去,把冰箱門關起來,就把大象放進冰箱了。這三個step聽起來就像是這個樣子。
link |
所以deep learning是很簡單的,你其實可以非常快地了解,你可以瞄懂它。其實在deep learning裡面,我們說在machine learning裡面,第一個step就是要define一個function。
link |
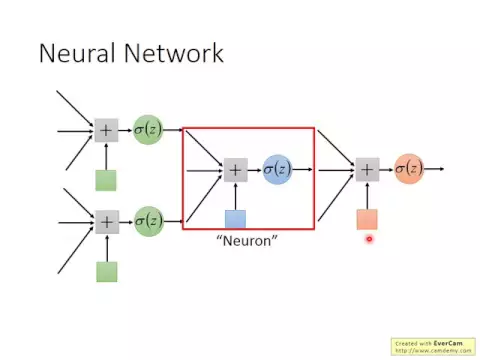
這個function其實就是一個neural network。這個neural network是什麼呢?我們剛才已經講說,我們把這個logistic regression前後concatenate在一起,然後把一個logistic regression整個稱作neural network,我們其實就得到了一個neural network了。
link |
我們可以用不同的方法來連接這些neural network,我們用不同的方法來連接這些neural network,我們就得到了不同的structure。在這個neural network裡面,我們有一大堆的logistic regression,每個logistic regression它都有自己的weight跟自己的bias。
link |
這些weight跟bias集合起來,就是這個network的parameter,我們這邊用theta來描述它。這些logistic regression或這些neural,我們應該怎麼把它接起來呢?
link |
有各種不同的方式,怎麼連接其實是你手動去設計的,手動去連接的。最常見的連接方式叫做fully connected feedforward network。在fully connected feedforward network裡面,你就把你的neural排成一排一排。
link |
這邊有六個neural,就兩個兩個兩個一排。每一個neural它都有一組weight,都有一組bias。這個weight和bias是根據training data去找出來的。
link |
假設上面這個藍色的neural它的weight是1-2,它的bias是1,下面它的weight是-1,它的bias是0。假設我們現在的輸入是1跟-1,那這兩個藍色的neural它的output是什麼呢?
link |
你做一下小學生會做的運算,你就可以得到答案。1乘1加-1乘-2再加上bias1,通過sigmoid function以後,你得到的結果就是0.98。
link |
那下面呢,你把1乘-1,-1乘1加0,再通過sigmoid function以後,你就得到0.12。接下來,假設這個structure裡面的每一個neural,它的weight,我們都是weight跟bias,我們都是知道的。
link |
那我們就可以反覆進行剛才的運算,1跟1通過這兩個neural變成0.98跟0.12,再通過這兩個neural變成0.86跟0.11,再通過這兩個neural得到0.62跟0.83。
link |
所以輸入1跟-1,經過一串很複雜的轉換以後,就得到0.62跟0.83。那如果你輸入是0跟0的話,你得到的output就是,經過一番一模一樣的運算,你得到的是0.51、0.85。
link |
所以一個neural network,你就可以把它看作是一個function。如果一個neural network裡面的參數,weight和bias我們都知道的話,它就是一個function,它的input是一個vector,它的output是另外一個vector。
link |
舉例來說,我們剛才看到說,input是1-1,output是0.62、0.83,input是0跟0,output是0.51跟0.85。所以一個neural,如果我們把參數已經設上去的話,它就是一個function。
link |
如果我們今天還不知道參數,我只是定出了這個network的structure,我只是決定好說,這些neural之間,我們要怎麼連接在一起。這樣子的一個network structure,它其實就是define了一個function set,對不對?
link |
我們可以給這個network設不同的參數,它就變成不同的function,把這些可能的function統統集合起來,我們就得到了一個function set。所以一個neural network,你還沒有認參數,你只是把它架構架起來,你決定這些neural要怎麼連接,你把這個連接的圖畫出來的時候,你其實就決定了一個function set。
link |
這跟我們之前做的東西都是一樣的,我們之前也是做logistic regression,做linear regression的話,我們都是也決定了一個function set。那這邊呢,我們也只是換一個方式來決定function set,只是如果我們用neural network決定function set的時候,你的function set是比較大的,它包含了很多原來你做logistic regression,做linear regression所沒有辦法包含的function。
link |
那剛才講的是一個比較簡單的例子,在這個例子裡面呢,我們把neural分成一排一排的,然後所有每一排的neural都兩兩互相連接,藍色neural的output就都接給紅色,藍色就都接給紅色,紅色就都接給綠色,紅色就都接給綠色,綠色後面沒有別人可以接了,所以它就整個network輸出,藍色前面沒有其他人了,所以它就是整個network的輸入。
link |
那in general而言呢,我們可以把neural畫成這樣,你有好多好多排的neural,你有第一排第二排到第大L排,每一排neural它裡面的這個neural的數目呢,可能很多,比如說一千格啊兩千格啊這個scale,那這邊每一個球呢代表一個neural。
link |
在layer和layer之間的neural呢,是兩兩互相連接的,layer1的output就是layer1的neural它的output會接給每一個layer2的neural,每一個layer2的neural。
link |
那layer2的neural的input就是所有layer1的output,就是所有layer1的output。
link |
因為layer和layer之間所有的neural兩兩間都有連接,所以它叫fully connected的network,那因為現在傳遞的方向是從1到2,從2到3,由後往前傳,所以它叫做feedforward的network。
link |
那整個network呢需要一組,需要一個input,這個input呢就是一個vector,那對每一個layer1的每一個neural來說,每一個neural它的input就是input layer的每一個dimension,就是input layer的每一個dimension。
link |
那最後第大L個layer的那些neural,它後面沒有接其他東西了,所以它的output呢就是整個network的output,假設大L排呢有大N個neural的話,它的output就是y1,y2到y大L。
link |
這邊每一個layer呢,它是有一些名字的,input的地方呢我們叫做input layer,那嚴格說起來,input其實不是一個layer,它跟其他layer不一樣,它不是由neural所組成的,但是我們把它當作一個layer來看,所以叫它input layer。
link |
output的地方呢我們叫它output layer,其餘的部分就叫做hidden layer,那所謂的deep是什麼意思呢?所謂的deep就是有很多hidden layer就叫做deep,那有人就會問一個問題說要幾個hidden layer才叫做deep呢?
link |
這個就很難說了,有人會告訴你說要三成以上才叫做deep,有人會告訴你說要八成以上才叫做deep,這個就看每個人的定義就不一樣。
link |
本來沒有deep learning這個詞的時候,大家都說我在做neural network,通常都只有一層,自從有deep learning這個詞以後,有一層的人都說它這個是deep learning。
link |
所以現在基本上只要是neural network的base的方法,大家都會說是deep learning的方法。
link |
那到底可以有幾層呢?在2012年的時候,參加ImageNet那個比賽得到冠軍的NXNet,它有八成,它的錯誤率是46.4%,那大家可能都知道說它比第二名好的非常多,第二名的error rate是30%,
link |
到2014年的時候,VGG有19層,它的error rate降到7%,GoogleNet有22層,它的error rate降到6.7%,但是這個都還不算什麼,Receiver Network有152層。
link |
因為它跟GoogleNet跟VGG跟NXNet比起來,大概是長這個樣子,它的error rate是3.57%,如果你看這個benchmark compass的話,其實它這個performance是比人在同一個test上做得還要好。
link |
你可能會很懷疑說,人怎麼可能會在影像辨識上輸給機器呢?因為那個test其實還蠻難的,它給你一張圖,一張狗的圖,你光回答狗並不是正確答案,你要回答說這個是哈士奇。
link |
那個test其實還蠻難的,但其實為了要公平的比較,當時在讓人跟機器比較的時候,那些人是有事先看過training data,也就是說,你有先讓他訓練辨識不同狗的種類,不同花種,不同植物的種類,只是經過訓練以後,其實他還是沒有機器那麼強就是了。
link |
那這個是跟101做一下比較,101在這邊。其實這個我們之後再講。
link |
CTO Network不是一般的Fully Connected Feed Forward Network,如果你用一般Fully Connected Feed Forward Network搞在這個地方,其實結果是會有問題的,它並不是overfeeding,而是你train都train不起來,所以你其實要特別的structure才能搞定這麼深的network,這個我們之後再講。
link |
Network的運作,我們常常會把它用matrix的operation來表示,怎麼說呢?我們舉剛才的例子,假設第一個layer的兩個neural,它們的weight分別是1-2-1-1,那你可以把這個1-2-1把它排成一個matrix。
link |
當我們input 1-1要做運算的時候,我們就是把1乘上1,-1乘上-2,1乘上-1,-1乘上1,所以我們就可以把1跟-1當成一個vector,把它排在這邊。
link |
當我們把這個matrix跟這個vector做運算的時候,我們算1乘1加-2乘-1,就等於是做1乘以1,-1乘-2,當我們做1乘以-1,-1乘-1的時候,就等於是做1乘以-1,-1乘-1。
link |
接下來有bias 1跟0,所以我們要在後面把bias排成一個vector,再把這個vector再加上去。這個結果算出來就是4-2,就是通過activation function之前的值4跟-2。
link |
然後通過這個sigmoid function,在這個neural network的文線裡面,我們把這個function稱之為activation function,事實上它不見得要是sigmoid function,現在大家都已經把它換成別的function。
link |
而如果你是從logistic regression那邊想過來的話,你會覺得它是一個sigmoid function,現在已經比較少用sigmoid function。
link |
假設我們這邊仍然用的是sigmoid function的話,我們就是把4跟-2丟到sigmoid function裡面,接下來算出來就是0.98跟0.12。
link |
所以一個neural network,一個feedforward network,它的一個layer的運算,你從1,-1到0.98,0.12,你做的運算就是把input 1跟-1,1跟-1,乘個metric,乘個metric,加上一個bias所成的vector,再通過一個sigmoid function得到最後的結果。
link |
所以in general來說,一個neural network,假設我們說第一個layer的weight,我們全部集合起來,當作一個metric w1,這個w1是一個metric,把它的bias全部集合起來,當作一個vector b1。
link |
把第二個layer的metric,把weight集合起來,當作w2,把它的每一個neural的bias集合起來,當作b2,到第L個layer,所有的weight集合起來,變成wL,bias集合起來,變成bL。
link |
那你今天得到,你今天給它一個input x的時候,output的這個y,要怎麼算出來呢?我們假設我們把x1,x2到x2,接起來,變成一個x,那這個output的y,應該要怎麼把它算出來呢?
link |
你就這樣算,x乘上w1,再加b1,再通過activation function,然後你就算出第二排的這些neural的output,我們稱之為a1,你把x乘上w1再加b1,就得到a1,x乘上w1再加b1,再通過activation function以後,就得到a1。
link |
接下來,你做一樣的運算,把a1乘上w2加b2,把a1乘上w2加b2,再通過activation function以後,就得到a2。
link |
然後就這樣一層一層一層的做下去,到最後一層,你把aL-1乘上wL加bL,通過activation function以後,得到整個neural最終的output y。
link |
所以整個neural network的運算其實就是一連串的matrix的operation,就是這個function,它的input output x跟y的關係,他們是什麼樣的關係呢?
link |
你把x乘上w1加b1,通過activation function,再把這個output乘上w2加b2,再通過activation function,再通過sigmoid function,最後到乘上wL再加bL,再通過sigmoid function,就得到最後的y。
link |
所以一個neural network實際上做的事情,就是一連串的vector乘上matrix再加上vector,就是一連串我們在炫星代數就有學過的矩陣運算。
link |
那把這件事情寫成矩陣運算的好處就是,你可以用GPU加速,那實際上現在一般在用GPU做加速的時候,這個GPU的加速並不是真的有對neural network去做什麼特化,而是說,那現在有一些特別的技術有做特化,但是你覺得如果你是買那種玩遊戲的顯卡的話,那它是沒有對這個neural network做什麼特化。
link |
那你實際上拿來加速的方式是,當你需要算矩陣運算的時候,你就call一下GPU,叫它幫你算矩陣運算,這會比你用CPU來算還要快。
link |
所以我們在寫這個neural network式子的時候,我們習慣把它寫成matrix operation的樣子,那裡面如果有需要用到矩陣運算的時候,就call GPU來做它。
link |
好,那這整個network我們怎麼看待呢?我們可以把它到offer layer之前的部分,看作是一個featured extractor,這個featured extractor就replace我們之前要手動做feature engineering,做feature transformation這件事情。
link |
所以你把一個Xinput,通過很多很多hidden layer,在最後一個hidden layer的output,每一個neural的output,X1,X2到X大K,你就可以把它想成是一組新的feature。
link |
那offer layer做的事情呢,offer layer就是一個multiclass的classifier,這個multiclass的classifier,它是拿前一個layer的output當作feature,這個multilayer的classifier,它用的feature不是直接從X收出來的,它是經過很多個hidden layer,做了很複雜的轉換以後,抽出一組特別好的feature。
link |
這組好的feature可能是能夠被separable,經過這一連串的轉換以後,它們可以被用一個簡單的一個layer的multilayer的multiclass的classifier,就把它分類的好。
link |
那我們剛才其實有講過說,multiclass的classifier,它要通過一個softmax function,因為我們把output layer也看作是一個multiclass的classifier,所以我們最後一個layer也會加上softmax。
link |
一般你在做neural network的時候呢,是會這樣做的。
link |
那舉一個不是寶可夢的例子,我們之後會示範一下實作這個例子。
link |
就是input一張image,它是一個手寫的數字,然後output說這個input的image它對應的數字是什麼。那在這個問題裡面,你的input是一張image,但對機器來說呢,一張image它就是一個vector。
link |
假設這是一個解析度16x16的image,那它有256個pixel,對機器來說呢,它就是一個256維的vector。那在這個image裡面呢,每一個pixel就對應到其中一個dimension。
link |
所以右上角這個pixel就對應到xy,第二個pixel就對應到x2,右下角的就對應到x256。那如果你可以說有塗黑的地方就是1,沒有塗黑的地方它對應的數字呢,就是0。
link |
那output呢,neural network的output,如果你用softmax的話,那它的output代表了一個probability的distribution,對不對?所以今天假如output是10維的話,你就可以把這個output看成是對應到每一個,你可以把output看成是對應到每一個數字的機率。
link |
就y1代表了input這張image,根據這個neural network判斷呢,它是屬於1的機率,代表它是屬於2的機率,代表它是屬於0的機率。
link |
那你就實際上讓neural network幫你算一下說,input一張image屬於每個數字的機率是多少,假設屬於數字2的機率最大是0.7,那你的machine就會output說,這一張image它是屬於數字2。
link |
那在這個application裡面,假設你要解這個手寫數字辨識的問題,那你唯一需要的呢,就是一個function。這個function,input是一個256維的vector,output呢,是一個10維的vector。
link |
而這個function呢,就是neural network。所以呢,你只要丟一個neural network,你可以用簡單的v4 network就好了,丟一個neural network,它的input呢,有256維是一張image,它的output呢,你特別設成10維。
link |
這10維裡面,每一個dimension都對應到一個數字。如果你做這樣的設計,讓input是256維,output固定是10維的話,那這一個network,它其實就代表了一個可以拿來做手寫數字的function。
link |
而這個function set裡面呢,這個network的structure就define了一個function set。所以function set裡面,每一個function你都可以拿來做手寫數字辨識,只是有些做出來的結果比較好,而有些做出來的結果比較差。
link |
那接下來你要做的事情就是,用quadrant descent去找一組參數,去挑一個最適合拿來做手寫數字辨識的function。
link |
那在這個process裡面呢,我們需要做一些design。在之前在做logistic regression,或者是linear regression的時候,我們對model的structure是沒有什麼好設計的。
link |
但是對neural network來說,我們現在唯一的constraint只有input要是256維,output要是10維。但是中間要有幾個hidden layer,每一個hidden layer要有多少個neural,是沒有限制的。你必須要自己去設計它,你必須要自己去決定說我要幾個layer,每個layer要有多少個neural。
link |
那決定layer的數目和每個layer的neural數這件事情,就等於是決定了你的function set長什麼樣子。你可以想像說,如果我今天決定了一個差的function set,那裡面沒有包含任何好的function,那你之後在找最好的function的時候,就好像是大海撈針,結果針不在海裡這樣子。
link |
怎麼找都找不到一個好的function,所以決定一個好的function set其實是很關鍵的,也就是決定這個network的structure是很關鍵的。講到這邊,總是會有人問我一個問題。
link |
假設我們今天讓machine來聽我的talk,然後叫它predict之後會有什麼樣的問題的話,它一定可以預測接下來的問題,那我們到底應該要怎麼決定layer的數目還有每個layer的neural的數目呢?這個答案就是我不知道這樣子。這個問題很難,就好像問說怎麼成為毛可夢大師一樣。
link |
這只能夠憑著經驗和直覺,這個network structure要長什麼樣子,就是憑著直覺還有多方的嘗試,然後去想辦法找一個最好的network structure。
link |
其實找network structure這件事情並沒有那麼容易,它有時候是蠻困難的,有時候甚至是需要一些domain knowledge,所以我覺得從非deep learning的方法到deep learning的方法,我並不認為machine learning真的變得比較簡單,而是我們把一個問題轉化成另外一個問題。
link |
本來不是deep的model,我們要得到好的結果,你往往需要做feature engineering,也就是做feature transform,你要找一組好的feature。
link |
但是如果今天是做deep learning的時候,你往往不需要找一組好的feature,比如說做影像辨識的時候,你可以直接把pixel就丟進去。過去做影像辨識的時候,你需要對影像抽一些feature,抽一些人定的feature。
link |
這件事情就是feature transform,但是有了deep learning以後,你可以直接丟pixel,硬做。但是今天deep learning製造了一個新的問題,它所製造的新的問題是你需要去design這個network structure,你的問題變成本來如何抽feature,轉化成怎麼design network structure。
link |
那我覺得deep learning是不是真的好用就depend on你覺得哪一個問題比較容易。我個人是覺得如果是語音辨識或者是影像辨識的話,design network structure可能比feature engineering容易。
link |
因為雖然說我們人都會看、會聽,我們自己都做得下下焦,但是這件事情它太過淺意識了,它離我們意識的層次太遠,我們其實不知道,我們無法意識到我們到底是怎麼做語音辨識這件事情的。
link |
所以對人來說,你要抽一組好的feature,讓機器可以很方便地用linear的方法去做語音辨識,這件事對人來說很難,因為根本不知道好的feature長什麼樣。所以還不如design一個network structure,或是嘗試各種network structure,讓我們自己去找出好的feature。
link |
這件事情反而變得比較容易,我覺得對影像來說也是一樣。那對其他case來說,我覺得就是case by case。比如說,你有沒有聽過一個說法是deep learning在NLP上面,覺得performance沒有那麼好。
link |
你有沒有聽過這個說法的同學舉手一下?沒關係,我手放下。好,好像沒有太多人聽過這個說法。這件事情是這樣,如果你看語音辨識跟影像辨識的文獻,語音辨識跟影像辨識這兩個community的人是最早開始用deep learning的。
link |
你用下去,進步量就非常驚人,比如說辨識的錯誤率相對下降了20%以上。那如果是NLP的話,你就會覺得說它的進步量似乎沒有那麼驚人。
link |
甚至很多NLP的人現在仍然認為說deep learning不見得network。我覺得我自己的猜想是,這個原因就是人在做對NLP這一件事情,對文字處理來說,人是比較強的。
link |
比如說叫你設計一個rule,detect說一篇document它是正面的情緒還是負面的情緒,你可以說我就列表,列一些正面情緒的詞彙、負面情緒的詞彙,然後看這個document裡面正面情緒的詞彙出現百分之多少,你可能就可以得到一個不錯的結果。
link |
所以NLP這個task對人來說,你比較容易設計rule。所以你設計了那些A-hard的rule,往往可以給你一個還不錯的結果。這就是為什麼deep learning相較於NLP傳統的方法,覺得進步沒有那麼顯著。
link |
它其實還是有一些進步的,只是覺得沒有其他的領域,也沒有語音和影像處理看起來那麼顯著,但還是有進步的。我覺得就長久而言,因為文字處理其實也是很困難的問題,裡面有很多幽微的資訊可能是人自己也不知道的。
link |
所以就長久而言,deep learning讓我們自己去學這件事情,還是可以占到一些優勢,只是一下子,眼下看起來進步沒有那麼顯著,它跟傳統方法比起來的差異就沒有那麼驚人,但是還是有進步的,這是我一些想法。
link |
再來就是有人會問說,能不能夠自動學network structure?其實可以的,你就去問余天利老師。在晶圓算法那邊,有很多的technique是可以讓machine自動地去找出network structure。
link |
不過這些方法目前還沒有非常的普及,你看到的那些非常驚人的應用,比如說AlphaGo什麼的,都不是用這些方法所做出來的。還有一個常見的問題就是,那我們能不能自己去設計network structure?
link |
我可不可以不要fully connected?我可不可以說,第一個連到第三個,第二個連到第四個,我可不可以自己亂接?可以,一個特殊的接法就是convolutional neural network,這個我們下一堂課再講。
link |
接下來第二步,第二步跟第三步真的很快,我們等一下就秒講。第二步是什麼呢?要定義一個function的好壞。在neural network裡面,怎麼決定一組參數的好壞呢?
link |
假設給定義一組參數,我要做手寫數字辨識,所以我有一張image跟它的label。這個label告訴我們說,因為現在是一個multiclass classification的問題,所以今天這個label1告訴我們說,
link |
你現在的target是一個vector,你的target是一個十維的vector,只有在第一維對應到數字1的地方,它的值是1,其他都是0。
link |
你就input這張image的pixel,然後通過這個neural network以後,你會得到一個output,這個output我們稱之為y,然後把我們的target稱之為y hat。接下來你要做的事情就是計算這個y跟y hat他們之間的cross entropy。
link |
就跟我們在做multiclass classification的時候是一模一樣,我們就計算y跟y hat的cross entropy,然後接下來我們就是要調整network的參數,去讓這個cross entropy越小越好。
link |
當然整個training data裡面不會只有一筆data,你有一大堆的data,你有第一筆data,那它所有算出來的cross entropy是C1,第二筆data算出來是C2,到第三筆data算出來是Cn,那你會把所有data的cross entropy偷偷上起來,得到一個total loss style。
link |
然後呢,你接下來要做的事情就是在function set裡面找一個function,它可以minimize這個total loss,或者是找一組network的parameter,現在寫成theta star,它可以minimize這個total loss。
link |
解了這個問題,怎麼找一個theta star,minimize這個total loss呢?你用的方法就是gradient descent,gradient descent大家已經太熟了,沒有什麼好講的,實際上在deep learning裡面用gradient descent,跟linear regression那邊沒有什麼差別,就一模一樣。
link |
所以你要做的事情,只是function變複雜了,其他東西都是一樣的。也就是說,你的theta裡面是一大堆的參數,一大堆的weight,一大堆的byte,你先找一個random,找一個初始值,random給每個數字一個初始值。
link |
接下來呢,計算一下它的gradient,計算每一個參數對你total loss的偏微分,把這些偏微分全部集合起來呢,叫做gradient。
link |
有了這些偏微分以後呢,你就可以更新你的參數,你就把所有的參數都減掉一個learning rate,這邊寫成mu,乘上偏微分的值,你就得到一組新的參數。
link |
這個process就反覆繼續下去,你有了新的參數,再計算一下它的gradient,然後呢,再根據你的gradient,再更新你的參數,你就得到一組新的參數。
link |
按照這個process呢,繼續下去,這個都是我們講過的東西,你就可以找到一組好的參數,你就做完neural network的training了。
link |
所以其實就這樣子啦,deep learning的training就這樣子,就算是最潮的alpha code,也是用gradient descent train的啦,所以大家可能會想像說,如果是deep learning的話,machine learning應該是這個樣子。
link |
其實上我們知道說,gradient descent就是玩世紀帝國,所以其實是這個樣子,希望你不要覺得太失望。
link |
然後你可能會問說,那這個gradient descent的function是長什麼樣子,之前我們都手把手的把那個算式算出來給大家看。
link |
但是在neural network裡面,因為function比較複雜,所以我們如果要手把手的算出來給大家看是比較難,要花一些時間。
link |
其實在現在這個時代,我還記得幾年前,在做deep learning很痛苦,因為你要自己implement backpropagation,那現在呢,應該已經沒有人在自己implement backpropagation了,因為有太多太多太多的toolkit可以幫你算backpropagation。
link |
那在作業商我們要做deep learning,那我也容許你用這些toolkit,所以你就算不會算這個微分,backpropagation就是算這個微分的一個比較有效的方式。
link |
因為參數非常多嘛,你有million的參數,你沒有辦法為每一個million的參數都算微分,這太花時間了,那backpropagation是一個比較有效率的算這個微分的方式。
link |
那如果你想要更知道詳細的話,我之前的deep learning課內容是有錄影的,你可以聽一下這個上課的內容。
link |
那如果你不想知道的話呢,其實也沒有什麼關係,我聽過一個傳聞是說,有某個公司他在應徵deep learning的人,我就問他說,你們要應徵deep learning的人,那你會問他什麼問題?
link |
我問他如何算微分,他說75%的號稱是deep learning專家的人,其實不會算微分的,所以大家已經太習慣用toolkit,已經不太會算微分了。
link |
這個toolkit很多啊,這邊就列一些出來給大家參考。
link |
好,那最後最後,在請助教講作業2之前,我們有一個最後的問題。
link |
為什麼我們要deep learning?一個很直覺的,你會說這個答案很簡單啊,因為越deep,performance就越好。
link |
這個是一個很早年的實驗,這個是2011年的inter-speech裡面的某篇paper,他做的是word error rate,所以word error rate是越小越好。
link |
你會發現一個hidden layer,每個hidden layer,2k個neuron,word error rate是24.2,那越來越deep了以後,它的performance,error rate就越來越低。
link |
但是如果你稍微有點machine learning的常識的話,這個結果並沒有讓你太surprise啊,因為本來有model有越多parameter,它cover的function set就越大,它的bias就越小,對不對?
link |
那你今天如果有越多的training data,你有夠多的training data去控制它的variance,一個比較複雜的model,一個參數比較多的model,它performance比較好是很正常的啊,那變deep有什麼特別了不起的地方?
link |
甚至有一個理論是這樣告訴我們,這個理論是這樣說的,任何連續的function,假設你要任何連續的function,它input是一個n-way的vector,它input是一個n-way的vector,它都可以用一個hidden layer的neural network來表示。
link |
只要你這個hidden layer的neural夠多,它可以表示成任何的function。既然一個hidden layer的neural network,它可以表示成任何function,而我們在做machine learning的時候,我們需要的東西就只是一個function而已,一個hidden layer就可以表示任何function,那做deep的意義何在呢?
link |
沒有什麼特別的意義啊,所以有人說deep learning就只是一個噱頭而已,因為做deep的感覺比較吵,如果你直接把它變寬,就變成fat neural network,那感覺太虛弱了,所以它沒有辦法引起大家的注意,所以我們要做deep learning。
link |
這個我們在往後的lecture再來告訴大家。最後就是列一些reference,如果你對deep learning很有興趣的話,你可以先看一下,還有我上學期講deep learning的錄影,在這邊也找得到,另外我有一個六小時的tutorial的slide,在這個連結上也可以找到。
link |
那個tutorial我十一月還會在新竹再講一次,這或許是我人生中最後一次講這個tutorial,千萬不要來聽,為什麼呢?因為在tutorial講的東西,在未來的課程裡面都會涵蓋,它就只是一個source而已。
link |
接下來我們先休息五分鐘,然後趕快叫助教來換場一下。