back to index
ML Lecture 7: Backpropagation
link |
好,各位同學大家好,那我們今天來,我們開始上課吧,那我們今天要講的是backpropagation,也就是實際上,如果你要用gradient descent的方法來train一個neural network的時候呢,你應該要怎麼做?
link |
好,那我們上次其實已經講過了neural network的基本架構,然後我就發現說在作業二裡面,好多人都已經implement了這個neural network based approach這樣,那或許你已經對這個方法非常的清楚了,那我不知道說你,但是我不知道說你是不是清楚說,到底實際上在train neural network的時候,backpropagation這個algorithm是怎麼運作的?
link |
好,我們就來講一下這個backpropagation這個algorithm是怎麼讓neural network的training變得比較有效率的,好,那在gradient descent裡面,我們知道說gradient descent的方法就是假設呢,你的network有一大堆的參數,一堆w一堆b,那你先選一個初始的參數,然後計算呢,你先選一個初始的參數θ0,然後計算這個θ0呢,對你的loss function的gradient,
link |
也就是計算每一個network裡面的參數,w1,w2,b1,b2等等,對你的lossθ的偏微分,而計算出這個東西以後,這個gradient呢,其實是一個vector,而計算出這個vector以後呢,你就可以去更新你的參數,你就把θ0減掉learning rate乘上這個gradient,然後得到θ1,那這個process呢,就持續繼續下去,
link |
你再算一遍,再θ1的gradient,然後呢,再把θ1減掉gradient,update成θ2,而這個process就一直持續下去,所以在neural network裡面呢,當你用gradient descent的方法的時候,跟我們在做logistic regression,還有linear regression等等,是沒有什麼太多的差別的,但是最大的差別就是,最大的問題是,在neural network裡面,我們有非常非常多的參數,那現在如果你要做語音辨識系統的話呢,
link |
你的neural network通常會有,比如說七八成,那每成呢,有一千個neural,那它有上百萬個參數,那所以這個vector呢,它是非常非常長的,這是一個上百萬維的vector,所以現在最大的困難就是,你要如何有效的呢,去把這個有百萬維的vector,有效的把它計算出來,那這個就是backpropagation在做的事情,
link |
所以backpropagation並不是一個和gradient descent不同的training的方法,它就是gradient descent,它只是一個比較有效率的演算法,讓你在計算這個gradient這個vector的時候,是可以比較有效率的把這個vector計算出來的,
link |
那其實backpropagation呢,它裡面沒有特別高深的數學,你唯一需要記得的就只有channel,那我們用一張投影片,迅速的幫大家複習一下什麼是channel,那假設你現在有兩個function,h跟g,然後g input x就得到y,這個h input y就得到z,
link |
所以如果你今天給x一個小小的變化的話,它會影響到它的output y,所以y會跟著有變化,然後y有變化以後又會影響到z,所以z會跟著有變化,
link |
那如果我們今天要計算這個底x分之底z的話,我們要計算x對z的微分的話,那怎麼算呢,你可以把它拆成兩項,x對z的微分,它就等於這個y對z的微分乘上x對y的微分,
link |
那這個怎麼來的,你就問一下微積分老師,你可以把這個y就消掉,所以左邊給你右邊,但是不要讓微積分老師知道這件事情。
link |
好,那第二個case,假設現在有三個function,g,h跟k,那g input x就得到x,h input x就得到y,k input x跟y就得到z,
link |
所以今天假如你改變了s,你會透過g和h這兩個function改變了x跟y,改變了s就改變了x跟y,那改變了x跟y以後,
link |
透過k這個function,k這個function input是x跟y,output是z,改變了x跟y以後,你就改變了z,所以你今天如果要計算s對z的微分的話,
link |
那這個s是透過兩條路徑去影響z,它可以透過x去影響z,也可以透過y去影響z,所以s對z的微分就可以寫成,就拆成兩項,根據這兩條path拆成兩項,
link |
這個s對z的微分就可以寫成x對z的微分乘上s對x的微分,上面這條路徑,加上y對z的微分乘上s對y的微分,也就是下面這條路徑。
link |
所以如果大一微積分有好好學的話,這個就是我們都學過的chain rule,那我們等一下會需要用到這個東西。
link |
好,那再來回到這個neural network的training,那我們知道說我們會定一個loss function,那這個loss function是什麼呢?
link |
這個loss function是summation over所有training data的某一個loss值c上標n,我們說假設給定我們一組neural network的參數set,
link |
我們把一個training data xn帶到這個neural network裡面,它會output一個yn,那同時我們會有一個我們希望這個neural network output的target yn hat,
link |
就是它希望如果它output yn hat的話,就是最正確的,那我們會定義一個這個yn和yn hat之間的距離的function,這邊寫做cn,
link |
cn代表yn和yn hat的距離,而如果cn大的話,代表yn和yn hat的距離很遠,所以這個neural network的parameter loss是比較大的,它是比較不好的。
link |
而如果他們這個cn很小的話,代表這組parameter是好的,那我們summation over所有training data的cn,
link |
而summation over所有training data根據這個參數set它的output跟它的目標,它的output yn跟它的目標yn hat之間的距離,就是得到我們的total loss L。
link |
那你把這個式子左右兩邊都對某一個參數w做偏為分的話,你就得到右邊這個式子,你就得到partial w分之partial L,
link |
等於summation over所有training datan等於1到N partial w分之partial cn,這個應該是沒有什麼問題。
link |
而之所以寫這個式子只是要講說,接下來我們就不用想說我們要計算partial w分之partial L,
link |
我們就只考慮我們如何去計算對某一筆data的partial w分之partial cn,
link |
你只要能夠把一筆data的partial w分之partial cn算出來,再summation over所有training data,
link |
你就可以把total loss對某一個參數的偏為分算出來了,
link |
所以等一下我們就只focus在怎麼計算對某一筆data它的cost cn對w的偏為分,我們只focus在怎麼計算這一項上面。
link |
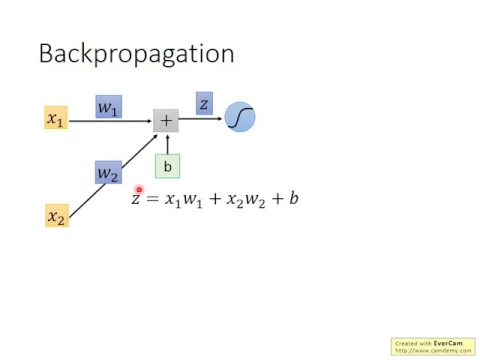
那怎麼做呢?我們先考慮某一個neuron,我們先從底下這個neuron network裡面,
link |
哪一個neuron出來考慮它,那這個neuron它是在第一個layer的neuron,
link |
所以它前面的input就是外界給它的input x1 x2,
link |
那x1跟x2分別,就假設它只有兩個input,x1跟x2分別乘上weight w1 w2再加上b會得到z,
link |
我想這個大家應該都非常熟悉,這個z就是x1w1加x2w2加上b,
link |
那得到這個z以後,通過activation function在經過了非常非常多的事情以後,你會得到最終的output y1y2。
link |
那現在的問題是這樣,假設我們從這邊拿一個w出來,等一下我們就拿w當作例子,
link |
但是b也是一樣的,我們就拿weight當作例子來看怎麼計算某一個weight對某一個example的cost的偏為分,
link |
那b的話呢,想必你可以以此類推就把它算出來。
link |
好,那partial w分之partial c怎麼算?這個partial w分之partial c就按照chain rule就可以把它拆成兩項,
link |
partial w分之partial z,partial z分之partial c,這個z可以把它消掉所以沒有問題。
link |
所以partial w分之partial c可以根據chain rule拆成兩項,那這兩項我們就分別去把它計算出來,
link |
那前面這一項是很簡單的,後面這一項是比較複雜的。
link |
那計算前面這一項,計算partial w分之partial z的這個process,我們稱之為forward pass,
link |
那等一下我們會知道為什麼叫forward pass。
link |
那計算後面這一項partial z分之partial c的process,我們稱之為backward pass,
link |
那我們等一下會講說為什麼它叫做backward pass。
link |
那我們就先看一下怎麼來計算這個partial w分之partial z,怎麼來計算partial w分之partial z。
link |
那我們先看這個w1,你怎麼計算partial w1分之partial z呢?
link |
是不是秒算,就是秒算,因為z就長這個樣子嘛,然後w1在這邊,所以一眼就知道說它是x1。
link |
那partial w2分之partial z呢?所以一眼就可以看出說它就是x2,這個都是秒算。
link |
那它的規律是這樣,它的規律就是這個partial w分之partial z啊,
link |
就是看這個w前面接的東西是什麼,那微分以後就是什麼。
link |
這個w1前面,它的input是接x1,它的input是x1,所以微分以後就是x1。
link |
那partial w2呢?它前面的input是x2,所以微分以後就是x2,它的規律就是這個樣子。
link |
所以今天呢,假如給你一個neural network,那它裡面有一大堆的參數,一大堆的參數。
link |
但是你要計算這裡面每一個參數對z的偏微分,你要計算這裡面每一個參數的partial w分之partial z。
link |
這件事情呢,非常非常的容易,因為我們剛才知道它的規律就是partial w分之partial z,就是看你那個w的input是什麼,它就是什麼。
link |
所以如果有人問你說,現在input是1跟-1,那這個1它對它的activation function的input z的偏微分是什麼呢?
link |
你就可以瞬間回答告訴他說就是-1,因為這個1前面接-1,所以這個參數對z的偏微分就是-1。
link |
同理呢,比如說這個-1,它對z的偏微分就是1,這個-2,它對z的偏微分就是-1,這個1,它對z的偏微分就是1,以此類推。
link |
那接下來呢,接下來假如有人問你說,這個w對它的activation function的input z的偏微分是什麼呢?
link |
你其實也可以瞬間就回答他,你只要知道說,這個w前面接的input是什麼。
link |
那這個w前面接的input是某一個neuron的output,對不對?
link |
這個w前面接的input是第一個hidden layer的neuron的output。
link |
那這個hidden layer的neuron的output怎麼算呢?這個大家應該都知道,對不對?
link |
就是把1跟-1丟進去,然後根據我們熟悉的neuron的運算,然後看看它的output是什麼就是什麼。
link |
在這個例子裡面呢,假如這個function是這個simoy function,算出來就是0.98跟0.12。
link |
那如果你可以算出這兩個neuron的output是0.98跟0.12的話,那這個w,它做完偏微分以後,
link |
這個w對它的activation function的input z做完偏微分以後,顯然就是0.12,因為它接到前面接的w是0.12。
link |
這個-1也是0.12,這個-2是0.98,這個-2是0.98,這個也很直覺。
link |
所以常常的process你就反覆的在做,你可以得到這兩個紅色neuron的output是0.86跟0.11,
link |
那你就可以瞄反應說,它對z的偏微分就是0.11。
link |
所以你要算出這個neuron network裡面的每一個w對它的activation function的input z的偏微分,
link |
你就把那個input丟進去,然後計算每一個neuron的output就結束了。
link |
所以這個步驟叫做forward pass,它是非常容易理解的。
link |
再來我們要講的是backward pass,也就是怎麼算partial z分之partial c。
link |
這個你就會覺得很困難了,因為這個z它要通過activation function以後得到output,
link |
然後後面還有非常非常複雜的process,它才得到這個c,根據非常複雜的process才能夠得到c。
link |
所以這個partial z分之partial c顯然是很複雜的。
link |
不過我們可以用chain rule再把這一項做一下拆解。
link |
假設這個activation function是sigmoid function,我這邊就寫一個sigma of z,
link |
而z通過sigmoid function得到a,這個neuron的output是a。
link |
這個a會通過某一個weight,會乘上某一個weight,再加其他一大堆的value得到z'.
link |
它是下一個neuron的activation function的input。
link |
這個a會乘上另外一個weight,這邊寫成w4,再加上其他一堆東西得到z''。
link |
後面這個z''跟z''之後可能還會發生很多很多的事情,
link |
不過我們就先只考慮下一步會發生什麼事情。
link |
所以呢,我們知道說這個partial z分之partial c,
link |
你可以寫成partial z分之partial a,partial a分之partial c,
link |
那這個沒有什麼問題,partial a可以消掉。
link |
那partial z分之partial a是什麼呢?
link |
我們知道說a就是等於sigmoid of z,
link |
那這個partial z分之partial a其實就是這個sigmoid function的微分。
link |
那sigmoid function長這個樣子,綠色這一條線,
link |
那它的微分你就算一下,它長這個樣子,
link |
所以partial z分之partial a也沒有問題。
link |
接下來的問題就是partial a分之partial c應該長什麼樣子呢?
link |
那我們就接下來再看說這個partial a跟c的關係是怎樣。
link |
所以partial a分之partial c,
link |
你可以寫成partial a分之partial z'乘以partial z'分之partial c,
link |
加上partial a分之partial z''除以partial z''分之partial c。
link |
就這個藍色的neuron的下一個layer,
link |
那這邊這個圈如果你的summation就是summation over一千項。
link |
接下來partial a分之partial z'
link |
這z'等於a,z'等於a乘上w3再加上一些有的沒的東西。
link |
最後的問題就是,這個z'對c的偏為分怎麼算?
link |
所以我們搞不清楚後面會發生什麼事情,
link |
所以我們一下子不知道這兩項要怎麼算。
link |
我們已經商號透過某種方法把它算出來,
link |
我們就可以把這個z'c輕易的算出來,
link |
我們就可以算 partial z分之partial c,
link |
所以算 partial z'分之partial c,
link |
跟partial zw'分之partial c,
link |
就會算 partial z分之partial c,
link |
partial z分之partial c的式子裡面,
link |
sigma' of z乘上w3 partial z'分之partial c,
link |
加上w4 partial z'分之partial c,
link |
但我們可以從另外一個觀點來看待這個式子,
link |
你可以想像說現在有另外一個neuron,
link |
這個neuron並不在我們原來的network裡面,
link |
那這個neuron的input就是partial z'分之partial c,
link |
跟partial zw'分之partial c,
link |
那第一個input partial z'分之partial c,
link |
partial zw'分之partial c,
link |
再乘上activation function sigma' of z,
link |
得到output就是partial z分之partial c,
link |
畫出來看起來像是一個neuron一樣,
link |
因為z其實已經在計算forward pass的時候,
link |
這個sigma' of z它就是一個常數,
link |
所以這個neuron其實跟我們之前看到,
link |
sigmoid function是不一樣,
link |
它並不是把input通過一個long linear的轉換,
link |
而是把input直接乘上一個constant,
link |
sigma' of z就得到一個output,
link |
所以我把這個neuron畫成三角形的,
link |
圓形的neuron的運作方式是不一樣的,
link |
我們假設現在紅色的這兩個neuron,
link |
就這兩個紅色的neuron是在output layer裡面,
link |
他們的output就已經是整個network的output,
link |
它的output就已經是整個network的output了,
link |
所以今天你要算partial z'分之partial c,
link |
那很簡單就根據chain rule,
link |
算partial z' partial y1,
link |
partial y1分之partial c,
link |
partial z'分之partial y1,
link |
只要知道這個activation function的長什麼樣子,
link |
partial y1分之partial c,
link |
就depend on你的這個cost function是怎麼定義的,
link |
你output跟它的target間是怎麼做evaluate的,
link |
你可以用cross entropy,
link |
可以用mean square error,
link |
partial z''分之partial c,
link |
partial z''分之partial c,
link |
就是partial z''分之partial y2,
link |
partial y2分之partial c,
link |
所以今天假設這個藍色的neuron後面,
link |
它的下一個layer就已經是output layer了,
link |
它在最後一個hidden layer裡面,
link |
它後面就已經是output layer了,
link |
你就已經可以把這個w1跟w2的對c的偏為分算出來,
link |
那我們真正煩惱的問題是case 2,
link |
它並不是整個network的output,
link |
那它後面的其他東西可能長什麼樣子呢?
link |
就是z'再通過activation function得到a'再乘上另外一個weight w5,
link |
然後你再把a'乘上w6再加上其他一大堆東西得到zb,
link |
丟進另外兩個activation function裡面,
link |
我們想要求partial z'分之partial c,
link |
如果我們知道partial za分之partial c,
link |
跟partial zb分之partial c,
link |
我們就可以計算partial z'分之partial c,
link |
假設我們知道partial z'分之partial c,
link |
跟partial z'分之partial c,
link |
我們就可以算前面一個layer的partial z分之partial c,
link |
如果我知道partial za分之partial c,
link |
跟partial zb分之partial c,
link |
我們就可以算partial z'分之partial c,
link |
就我們剛才看到的op amp的式子,
link |
所以你就把partial za乘上w,
link |
partial zb分之partial c乘上w6,
link |
再乘上op amp就得到partial z'分之partial c的output,
link |
我們剛才說知道z'跟z''的偏微分就可以算z,
link |
現在知道za跟zb的偏微分就可以算z',
link |
但是我們又不知道za跟zb的偏微分怎麼算,
link |
這個綠色的neuron如果它是output layer的話,
link |
假設它不是output layer的話,
link |
它的activation function的input對c的偏微分,
link |
它們不是output layer的話,
link |
你就再去推下一個layer的偏微分是什麼樣子,
link |
你要一路往後走,一直走到network的output,
link |
從output layer的partial z分之partial c開始算,
link |
它的運算量跟原來的neural network,
link |
它的acclimation function,
link |
input分別是z1,z2,z3,一直到z6,
link |
本來我們應該是想要知道z1的偏微分,
link |
你才算出z3的偏微分,z4的偏微分,
link |
你才能算出z1的偏微分,跟z2的偏微分,
link |
如果我們今天是從z1,z2的偏微分開始算,
link |
但是如果你反過來你先算z5,z6的偏微分的話,
link |
這個process就突然之間變得有效率起來了,
link |
你就可以算得出z3,z4對c的偏微分,
link |
然後你就可以算出z1,z2對c的偏微分,
link |
就是σ'z1,σ'z2,σ'z3,σ'z4,
link |
σ'z5分之σ'c,σ'z6分之σ'c,
link |
然後再把這個偏微分值跟這個偏微分的值,
link |
再通過OPAMP你就得到這兩個偏微分的值,
link |
再通過一個OPAMP就得到一些偏微分的值,
link |
所以你在算back propagation的時候,
link |
這個步驟叫做backward path,
link |
你在做這個backward path的時候,
link |
建另外一個neural network,
link |
我們本來有一個正向的neural network,
link |
裡面的activation function可能是sigmoid function,
link |
那現在你在算backward path的時候,
link |
你就是建一個反向的neural network,
link |
但是從右邊到左邊反向的neural network,
link |
這個反向的neural network,
link |
它的activation function你要先算完forward path以後,
link |
接下來這個反向的neural network,
link |
然後其他部分就跟一般neural network的運算一樣,
link |
你就做一個backward path,
link |
但是其實就是做一個neural network的運算,
link |
你就可以把每一個z對c的偏微分就都算出來了,
link |
這個就是backward path,
link |
所以我們就summarize一下backward path是怎麼做的,
link |
首先你做一個forward path,
link |
在做forward path的時候,
link |
只要你知道每一個activation function的output,
link |
那activation function的output,
link |
就是它所連接的weight的partial w跟partial z,
link |
那在backward path裡面,
link |
你要把原來的neural network的方向倒過來,
link |
你把原來的neural network的方向倒過來,
link |
那在這個倒過來的neural network,
link |
你就知道某一個weight對w的偏微分是什麼了,
link |
因為我相信應該有百分之七十五以上的好奇,