back to index
ML Lecture 8-1: “Hello world” of deep learning
link |
好,那我今天要教大家的這個托品啊,是Keras。
link |
那你可能想說,怎不教TensorFlow呢?TensorFlow的新星數不是那個Deep Learning的托品裡面最多的嗎?
link |
應該要教TensorFlow。那其實是這樣子的,在另外一門Deep Learning的課裡面我們教的是TensorFlow。
link |
那其實TensorFlow沒有那麼好用。應該怎麼說呢?應該是這樣,TensorFlow跟另外一個跟它非常相近的托品Diego,
link |
它們是非常的flexible,也就是說你甚至可以把它想成是一個微分器。
link |
它甚至不是,它可以做Deep Learning,它完全可以做Deep Learning以外的事情,因為它做的事情就是幫你算微分。
link |
然後它把微分的值算給你以後,你就可以拿去做這個Weighted Descent。
link |
所以它非常的flexible,那這麼flexible的托品學起來呢,是有一些難度的,至少我覺得,
link |
比如說在接下來的課裡面我們大概有半個小時的時間,那你沒有辦法在半個小時以內精通這個熟悉這個托品。
link |
但是另外一個托品Keras呢,我覺得你是可以在數十分鐘內就精通,就可以非常熟悉它,然後用它來implement一個自己的DNN的。
link |
那這個Keras呢,其實是TensorFlow跟Piano的interface,所以就有人覺得說TensorFlow其實也沒有那麼好用,
link |
所以它搭了TensorFlow的interface,就叫做Keras。所以你用Keras其實就等於你是在用TensorFlow了,只是有人幫你把操縱TensorFlow那件事情先幫你寫好。
link |
那其實它比較好學,而且它其實也有足夠的彈性,很多你想要做的事情,多數你想要做的東西,除非你想要自己做DNN的研究,
link |
你想要自己兜奇奇怪怪的Network,不然多數你想到的Network其實這裡面都已經有現成的function可以call了。
link |
而且它背後就是TensorFlow或者是Piano,所以你永遠可以去,就有一天如果你想要更精進自己的能力的話,
link |
你永遠可以去改Keras背後的TensorFlow的code,然後做更厲害的事情。那其實這邊有一個,我知道一個小道消息是,
link |
因為Keras的作者呢,他其實是在Google工作,所以據說呢,Keras即將要變成這個TensorFlow的官方的API,
link |
所以當時呢,我選擇叫Keras真的是站對邊了。
link |
好,那這邊稍微講一下Keras是什麼意思,Keras其實是牛角的意思,在西亞文裡面是牛角的意思,這個我有特別查過。
link |
這個來源就是,因為Keras是一個叫做夢精靈的project裡面被develop出來的,然後根據這個我忘了是伊利亞的還是奧德賽裡面的傳說,
link |
就是夢精靈呢,在來到人世間的時候,它會通過兩種門,一種門是象牙座的門,一種是牛角座的門。
link |
那如果是通過象牙座的門的夢精靈呢,那個夢的內容就不會被實現,如果是通過牛角的門,也就是Keras來的夢精靈呢,
link |
那你的夢就會被實現,那個project叫做夢精靈,所以在那個project開發出來的Torquay就叫做Keras。
link |
那以下呢是它的documentation還有一些example,這個助教會在助教時間跟大家講一下怎麼安裝Keras,所以如果你不會安裝的話,
link |
當然它其實安裝的process它其實是很清楚啦,如果你不會安裝的話,助教會跟你講,所以等一下我們就只是看一下說Keras如果運作起來,
link |
在操控的時候大概看起來像是什麼樣子。那以下呢是某位同學使用Keras的心得,那他把他的心得呢做成那個六格的圖,放在Facebook上面。
link |
他說,一個deep learning的研究生他都在做什麼事情呢?朋友覺得他在做alpha go,他媽覺得他坐在電腦前面,大眾覺得他在做很潮的東西,
link |
直到教授知道是在疊一個optimization problem,他以為自己很潮這樣子,我覺得應該是這個意思啦。
link |
然後事實上呢,你在做的事情就是疊積木,那這個並不是他玩得很開心的意思,這個疊積木的意思就是說,當你在使用Keras的時候,
link |
他是非常的容易的,你在做的事情就是把現成的module呢,把現成的function呢,疊來疊去而已,所以用Keras就好像是在疊積木一樣。
link |
好,那等一下我們就是用我在前一堂課講的handwriting的digital classification,來當作例子來示範的Keras使用。如果你這輩子都還沒有寫過deep learning的程式的話,那今天這個就是deep learning的Hello World。
link |
我用的data呢,就是analyst的data,那analyst的data就好像是machine learning的果蠅一樣,果蠅知道嗎?果蠅就是,如果你很快,你想要很快做一個實驗,你就用analyst,
link |
因為他的data量少,然後做起來就是做起來。好,然後這個在analyst裡面,你就是要我們去做的事情,就是input一個image,然後output就是這個image是0到9的哪一個數字。
link |
那input的image的size是28乘以28,它是一個matrix,28乘以28的matrix。那其實Keras呢,有provide自動下載analyst的data的function。
link |
好,那如果用Keras的話,你要怎麼做呢?那我們之前有講過說deep learning就是三個步驟,第一個步驟就是決定一下你的function set,就決定一下你的neural network要長什麼樣子。
link |
那在Keras裡面呢,你就是先宣告model等於sequential,就先宣告一個model,然後接下來你就看你的network想要長什麼樣子,你就自己決定它要長什麼樣子。
link |
舉例來說,我這邊想要疊一個network,它有兩個hidden layer,然後每一個layer都有500個neural。我想要做這件事情的話,我應該要怎麼做呢?其實很容易。
link |
你先宣告一個model,接下來你就說model.add,就是加一個東西,加什麼?這邊我們要加一個fully connected的layer,fully connected的layer就是用dense來表示,但可以加別的layer,比如說convolution的layer。
link |
所以這邊宣告dense括號input dimension是28x28,output dimension是500,那你就是input一個28x28的vector,這個vector代表一個image,然後你output等於500,就是說你今天要有500個neural。
link |
接下來你要告訴network說你的activation function要用什麼,這邊就直接寫說model.add activation function,括號sigmoid,那你就是用sigmoid當作你的activation function。
link |
那你可以選別的,keras裡面有選別的,比如說soft path,soft sign,如果要tangent,等等一大堆別的,而且你要加上自己新的activation function,其實也蠻容易的,你只要找到keras裡面寫activation function的地方,然後自己再加一個自己的function進去就好了。
link |
然後呢,如果要再加一個layer的話怎麼辦呢,你就一樣下model.add一個dense layer,然後output是500,這邊你就不需要再給他input了,因為下一個layer的input就等於前一個layer的output,所以你不需要再redefine input的dimension是多少,
link |
你只要直接告訴他說output也要500個neuron就好,不需要告訴他說input也是500個neuron,這個keras自己知道。activation function這邊一樣就是用sigmoid。
link |
最後,output是要做數字分類嘛,對不對,就10個數字,所以你output一定要10位,你可以設別的數字,設11,12什麼的,那都不問了。所以你這個output就是設10位,output dimension就是10位。
link |
那你這邊呢,我們說在output的layer,如果把它當成一個model class classifier來看的話,我們會用softmax,那你也可以用別的,你完全可以用sigmoid什麼的都可以,然後這邊呢,選擇用softmax。
link |
好,那接下來我們要決定一個function的,要有辦法evaluate一個function的好壞,怎麼evaluate一個function的好壞呢?你要做的事情就是model compile,然後定義你的loss是什麼。
link |
如果你的loss是cross entropy的話,那你的loss就是,它在那個keras裡面,它是cross entropy,它是寫成categorical cross entropy,就是cross entropy,寫說你的loss等於cross entropy就行了。
link |
那其實它有支援很多其他的loss function,在不同的場合你會需要用到不同的loss function,這個就留給大家自己去看keras的documentation。
link |
好,那再來呢是training的部分,在training之前你要先下一些configuration,告訴它說你training的時候,你打算要怎麼做。
link |
所以現在呢,你要下的第一個東西是optimizer,也就是說你要找最好的function的時候,你要用什麼樣的方式來找最好的function。雖然說這邊optimizer後面好像你可以接不同的方式,但是這些不同的方式其實都是這個gradient descent base的方法。
link |
只是他們用的這個learning rate,就是learning rate你可以,就一般我們在做一般的這個gradient descent的時候,你要自己設一個learning rate對不對,但是有一些方法是machine會自動的跟empirically決定learning rate的值應該是多少。
link |
所以有一些方法是不需要給他learning rate,machine自己會決定learning rate應該要是多少,那這邊有支援各式各樣的方法。
link |
那最後就是決定好要怎麼做gradient descent以後,再來就是真的去跑gradient descent,再來就是真的給他做下去。那這一步呢,很簡單,你就給他四個input,第一個input是training data,在我們的case裡面training data就是一張一張的image。
link |
那你要給每一張training data的label,在這邊我們就是要告訴machine說現在training data裡面每一張image它對應到0到9的哪一個數字,後面那兩個flag我們等一下再解釋。
link |
我們來看一下實際上這個Xtrain跟Ytrain應該是長什麼樣子,在這個case裡面你的training的image就是要存這個non-pi array啦,那就不要問我說怎麼把image存到non-pi array裡面去了,這個應該作業裡我們做過了對不對。
link |
好,那你要把你的image存到non-pi array裡面去,那它的存法是這樣子,這個non-pi array是two dimension的non-pi,它的是一個two dimension的metric,它的第一個dimension代表你有多少個example,如果你有一萬個example,第一個dimension就是一萬位。
link |
第二個dimension就是看你的image有多大,有幾個pixel,那第二個dimension就有多大,其實在這個case裡面,在Andes這個case裡面有28x28個pixel,所以有784個pixel,所以第二個dimension就是784位。
link |
好啦,那我們來看Ytrain,Ytrain這個每個image的level怎麼表示呢,一樣這個第一個dimension代表你有幾個training的example,你有幾個training的example,第一個dimension就有多少位。
link |
那第二個dimension呢,第二個dimension就是10,因為我們現在的output就是10位嘛,我們level就有10個可能而已,0到9而已,所以output dimension就是10位。然後呢,今天這個image所對應的數字啊,它就會是1,就在那邊是塗黑的,其他是0。
link |
舉例來說,第一個image這個是5,所以在它的level裡面,這個數字是0,1,2,3,4,5,它從0開始算,所以就是對應到5的那一位是1,其他是0。
link |
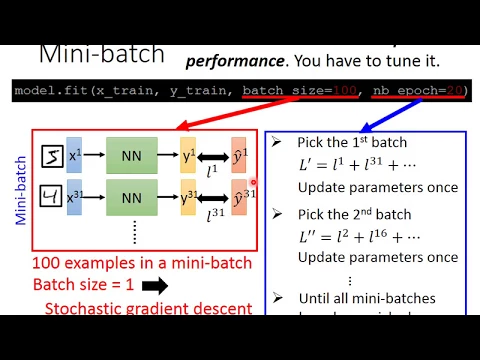
比如說,第四個數字,它是1,那在這邊呢,就是對應到1的那一位是1,其他是0。好,那前面有兩個我們還沒有解釋過的東西,一個是batch size,一個是number of epochs,它們是什麼意思呢?
link |
所謂的batch size是這樣,首先呢,這邊有一個秘密,就是我們其實在做gradient descent的時候,在做deep learning的時候,我們並不會真的去minimize total loss。
link |
我們做的是什麼呢?我們會把training data分成一個一個的batch,也就是說,你把你的training data,比如說一萬張,你拿出來,然後每次random就選一百張進來,作為一個batch。
link |
那這個batch你要隨機的分,如果你batch沒有隨機的分,比如說你某一個batch裡面通通都是1,而另外一個batch裡面通通都是數字2,你可以自己試試看,你這樣測起來呢,會有問題的,這個對你的performance是會有不小的影響的。
link |
好,那接下來呢,怎麼做呢?首先你先random initialize level的參數,就跟一萬回一點descent一樣,接下來呢,隨機的選一個batch出來,比如說我們選了第一個batch出來,然後接下來我們計算對第一個batch裡面的element的total loss。
link |
不是全部training data的total loss,而是第一個batch裡面的element的total loss,我們計算說Lπ等於L1加L31加上別的batch,同一個batch裡面其他example的loss。
link |
然後接下來呢,根據Lπ去update參數,也就是去計算參數對Lπ的偏微分,然後update參數。接下來再隨機選一個batch,比如說這邊選的是第二個batch,你就計算說現在你的total loss變成Ldoubleπ,它不是total L,它是L2加L16,再加其他同一個batch裡面的其他的example。
link |
接下來你計算你的參數對Ldoubleπ的偏微分,然後呢,去update你的參數。你就反覆做這個process,直到把所有的batch呢,通通選過一次。
link |
所以今天假設你有100個batch的話,你就把這個參數update100次,那把每一個batch都看過以後,把所有的batch都看過一次,叫做一個epoch。
link |
那我們要做的事情就是重複以上的process,所以你在train一個network的時候,你會需要好幾十個epoch,而不是只有一個epoch。
link |
所以這邊呢,這兩個flag,一個是batch size,就是告訴Keras說,我們的一個batch要有多大。舉例來說,這邊batch size的100,就是說我們要把100個example放在一個batch裡面。
link |
那Keras會自動幫你隨機的放,所以這個部分你就不需要自己寫code。那number epoch就是說呢,每一個batch看過一次叫做一個epoch。那我們到底要有幾個epoch呢?
link |
這邊epoch等於20,就是以上這個process重複20次,也就是每一個batch被看過20次。那你要注意,我們並不會在一個epoch裡面,我們已經update很多次參數了,我們每看一個batch就update一次參數。
link |
假設我們現在100個batch,那一個epoch裡面我們就已經update100次參數了。20個epoch就是update20x100,就是2000次參數了。所以並不是說,這邊設20個epoch就是update20次參數的意思。
link |
在一個epoch裡面,會update很多次參數。那我們記得我們之前,林中文老師應該有講過stochastic gradient descent,所以今天如果我們的batch size設為1的話,那就是equivalent to stochastic gradient descent,對不對?
link |
那我們之前有講過stochastic gradient descent的好處,它的好處就是,它的速度比較快,對不對?相較於原來的gradient descent,它的速度是比較快的。
link |
因為原來的gradient descent,你update一次參數的時候,你用stochastic gradient descent,假設你有100筆training data的話,那你已經update100次參數了。
link |
雖然說每次update參數的方向是不穩定的,但是就是天下武功唯快不破。
link |
雖然它的出拳常常落空,但是它可以在別人出一拳的時候,它就出100拳了,所以它是比較強的。
link |
那你可能會想說,既然是這樣子的話,為什麼我們就不用stochastic gradient descent就好了,還要用minibatch呢?那接下來就是一些實作上的問題,讓我們必須要用minibatch。
link |
minibatch這件事很重要,但是它的最主要要用minibatch的理由,其實是一個實作上的issue。
link |
我們之前有講說,舉例來說,這邊我們有5萬個example,那我們的batch size,如果你設1,也就是stochastic gradient descent的話,那在一個app裡面,你會update5萬次參數。
link |
如果你今天你的batch size設為10的話,在一個app裡面,你會update5千次參數。
link |
這樣看起來好像是stochastic gradient descent比較快,minibatch設為10,你在一個app裡面才update5千次參數,但stochastic gradient descent它可以update5萬次參數。
link |
它的速度好像應該是它的10倍,但是實際上,當你batch size設不一樣的時候,一個app需要的時間是不一樣的。
link |
大家了解我的意思嗎?你會想說,這個training data都5萬筆嗎?結果training data固定都是5萬筆,你設batch size等於1,設batch size等於10,運算量不是一樣多的嗎?
link |
你要把5萬筆每一個example都看過一遍,同一個app裡面,它需要做的運算不是一樣多的嗎?這一樣多的運算就是一樣多的時間,但是batch size設成1,你可以update5萬次,聽起來好像是比較厲害。
link |
但是實際上,在實作上,當你batch size設不一樣的時候,它運算的時間是不一樣的。就算是同樣多的example,但它運算的時間是不一樣的,等一下會解釋為什麼。
link |
我們來看看實際上的例子,這個就是在GTS980跑在NIST的5萬個training sample上面,一個batch需要的時間,當我設不同的batch size的時候。如果今天batch size設1,也就是opacity gradient descent,一個app要166秒,也就是接近3分鐘。
link |
如果今天batch size設10的話,那一個app是17秒。所以你會發現說,如果你今天設100,1000,10000,它當然就是越來越快,每一個app都越來越快。
link |
所以你會發現說,今天過了166秒,它才算一個app。在166秒,在下面batch size設等於10個case,它已經算10個app了啦,幾乎已經算10個app了。
link |
所以這樣比較起來,因為它算一個app要166秒,同樣的時間它已經算10個app,它一個appupdate5萬次,它一個appupdate1000次,但是它可以在同樣時間已經跑10個app,所以會變成說,在參數update的數目,batch size設1跟batch size設10,幾乎是一樣。
link |
然後再來呢,如果今天幾乎這兩件事情在同樣時間內,參數update的次數幾乎是一樣的,那你其實會想要選batch size等於10。
link |
為什麼?因為如果你選batch size等於10的時候,是會比較穩定啊。我們之前之所以從gradient換成stochastic gradient,目標就是因為這樣測比較快,給update次數比較多。
link |
可是現在如果你要用stochastic gradient,其實也不會比較快,那你為什麼不選一個比較穩定,然後update次數也比較多呢?
link |
所以你這邊你就會選擇batch size等於10的case。那接下來有人就會想說,接下來我們的下一個問題就是為什麼batch size設比較大的時候,速度會比較快?
link |
那這個就是因為我們使用了平行運算,用GPU,我在下一頁會更仔細的解釋它。你就先知道說,因為我們用了平行運算,所以這10個example它是同時運算的。
link |
所以你算10個example的時間,算一個batch裡面10個example的時間,跟算一個example的時間,其實是可以幾乎是一樣。
link |
那你會想說,既然batch size越大,它會越穩定,而且batch size變大的話你還是可以平行運算,那你為什麼不把batch size開超級大就好了?
link |
這邊有兩個claim,第一個claim就是,如果你把batch size開到很大,最終GPU會沒有辦法平行運算,它終究是有它的底線。
link |
也就是說,它同時考慮10個example跟考慮一個example的時間是一樣,但它同時考慮1萬個example的時候,它的時間就不會跟一個example一樣。
link |
所以batch size考慮到硬體真正的限制的話,你也沒有辦法無窮盡的增長。那撇開硬體的限制不談,另外一個batch size你不應該設太大的理由是,
link |
你其實可以自己試試看,如果你把batch size設很大,在train gradient descent,在做deep learning的時候,你跑兩下你的neural就卡住了,跑兩下你就陷到settle point或local minima裡面去了。
link |
在那個neural level的error surface上面,它不是一個complex optimization problem,它有很多的坑坑洞洞,如果你今天是4的batch,原來的gradient descent你沒有切mini-batch,
link |
那你就是完全順著total loss的gradient方向走,你發現說你沒走兩步就卡住了,你可以自己回去試試看,你把batch size設成整個4batch,
link |
那如果你的GPU跑得動的話,它還是可以得到一個結果,但是你的performance就會很差,因為你會發現說你在training set上的loss,你才跑兩下就整個就卡了,
link |
你就沒有辦法再train,它就卡到一個local minima或settle point的地方,你就無法再train。但是如果用stochastic的好處就是,如果你有隨機性,
link |
每一次你走的方向會是隨機的,所以如果你今天走某一步陷到一個local minima裡面去,如果那個local minima不是一個很深的local minima,
link |
或是那個settle point不是一個很特別麻煩的settle point,你只要下一步再加一點random,你就可以跳出那個歸點是0的區域了。
link |
所以如果你沒有這個隨機性的話,你train neural network其實是會有問題的,你如果沒有這個mini-batch的隨機性的話,
link |
你沒有跑兩,你沒train,你才update兩三次參數,你就會卡住了,所以這個mini-batch是需要的。
link |
接下來我們要解釋說,為什麼當有batch的時候,GPU是如何平行的加速。那我們剛才有講過說,整個network你就可以把它看成是一連串的矩陣運算的結果。
link |
不管是forward pass還是backward pass,都可以看成是一連串的矩陣運算的結果。forward pass就是我們圖上看到的這樣。backward pass,我們前一份圖有解釋過,就是把整個network逆轉,然後把neural變成OPAMP而已。
link |
那我們今天就可以比較stochastic gradient descent,也就是batch size等於1,還有batch size等於10的差別。如果batch size等於1,我們看第一個layer,你input一個x,然後你乘上w1,你就得到d1。
link |
就在forward pass的時候你要做這個計算,在backward pass你也會做一個類似的計算。在forward pass你就做這樣一個metric operation。這是第一筆data,然後你做完這些metric的計算以後,你會update你的參數,接下來再讀第二筆預設的x進來,再乘w1,再得到另外一個d1,再update一次參數。
link |
但是在mini-batch的時候,你會把同一個batch裡面的input統統集合起來,每一個input都是一個vector,假設我們現在metric size都是2,那你裡面有黃色這個vector,有綠色這個vector,那你就把黃色的vector和綠色的vector拼起來變成一個metric,再把這個metric乘上w1,你就可以直接得到z1跟z2。
link |
就是我們可以把x1乘上w1得到z1,x乘上w1得到z1,這兩件事情分開來做,也可以把這兩個東西並在一起,再乘上w1,直接得到z1跟z2。
link |
這兩件事情理論上運算量是一模一樣多的,對不對?上面這件事跟下面這件事,它在理論上的運算量是一樣多的,但是就實作上,你覺得哪一件事情是比較快呢?
link |
你覺得上面比較快的同學舉手比較好?你覺得下面比較快的同學舉手比較好?所以我同學都覺得下面比較快,好,手放下。
link |
但是下面就是比較快的,因為如果你今天讓GPU做這個運算和讓GPU做這個運算,它的時間其實是一樣的。對GPU來說,你在這個矩陣相乘裡面的每一個element都是可以進行運算的。
link |
所以今天上面這個運算的時間反而會變成下面這個GPU的運算的時間的兩倍。所以這就是為什麼我們用minibatch再加上GPU的時候,你是可以加速的。
link |
但是如果你今天沒有用GPU,就是說如果你今天用GPU,但是你沒有用minibatch的話,你其實就加速不了太多。所以這個就是有人買了GPU,有人比如說拗了他的老師買了GPU來,但他不知道要設minibatch,所以裝了GPU以後也沒變快。
link |
好,那Keras當然可以save和load model,可以把現團的好model存起來,然後以後再用另外一個程式讀出來。那它也可以幫你做testing,有兩個testing的case。
link |
第一個case是這個evaluation,也就是evaluation case是我今天有一局testing set,testing set的答案我也知道,那Keras就幫你算說你現在的正確率有多少。
link |
所以這個evaluation它有兩個input,就是testing的image和testing的label。那在case2呢,case2叫做predict,這個時候你沒有任何的label data,你只有image。
link |
就是你真的train好這個model,你要放到網路上讓人家用,別人會輸入一個image,然後你就告訴他說你的分類好的數字是多少。
link |
那這個時候,你input就只有x,也就是只有image,output就直接是分類的結果。好,剩下一點時間。