back to index
ML Lecture 9-1: Tips for Training DNN
link |
講的是各種deep learning的,我要講的是幾個deep learning的題。
link |
那其實呢,這一段本來是要在CNN之前講的啦。
link |
那在CNN那一段裡面呢,我們留下兩個問題。
link |
第一個是,在CNN裡面呢,有Max pooling這樣的架構。
link |
但是,這個Max pooling這樣的架構顯然不能為分啊。
link |
你把它放在一個network裡面,你再用做gradient descent在為分它的時候,你到底是怎麼處理的。
link |
那第二個問題呢,是我們剛才看到的L1的regularization,但是我們還沒有解釋它是什麼樣的東西。
link |
那這個呢,我們都會在這份投影片裡面解釋。
link |
好,那本來是要先講這份投影片才講CNN的啦。
link |
但是因為為了要講作業三的關係,所以就先講了CNN。
link |
講完這段投影片以後,之前的一些問題呢,就可以被解決。
link |
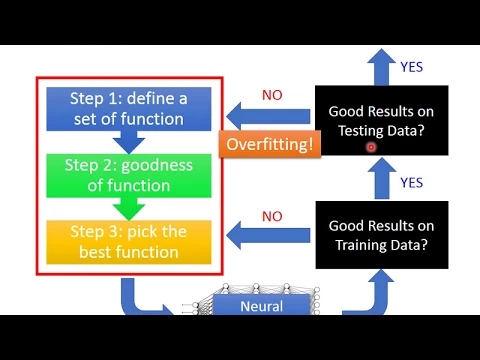
好,那首先這邊呢,最重要的一個觀念是deep learning的recipe。
link |
如果你在訓練一個deep learning的network的時候,你在做deep learning的時候,它的流程呢,應該是什麼樣子。
link |
那我們都知道說deep learning是三個step。
link |
define function,然後define你的function set,define你的network structure,然後決定你的loss function,接下來你就可以用gradient descent去做optimization。
link |
做完這些事情以後,你會得到一個neural network,得到一個嫩好的neural network。
link |
其實你第一件要檢查的事情是,這個neural network在你的training set上有沒有得到好的結果。
link |
不是testing set喔,你要先檢查這個neural network在training set上有沒有得到好的結果。
link |
如果沒有的話,你就回頭去呢,看看說在這三個step裡面,是不是哪邊出了問題,你可以做什麼樣的修改,讓你在training set上呢,能夠得到好的結果。
link |
那這邊這個先檢查training set的performance,其實是一個deep learning非常unique的地方。
link |
如果你想想看其他的方法,比如說你今天如果是用的是,雖然這些方法我們還沒有講過,但你或多或少都知道,比如說k-nearest neighbor,或者是decision tree。
link |
其實像k-nearest neighbor或decision tree這種方法,你做完以後,你其實不太會想要檢查你training set的結果。
link |
因為在training set上performance,正確率就是100這樣子。你做完decision tree,做完k-nearest neighbor,你得到的正確率就是100,ok,沒有什麼好檢查的。
link |
所以有人說,這個deep learning,看這個model裡面這麼多參數,感覺一點很容易overfitting的樣子。
link |
我跟你講,這個deep learning的方法,它才不容易overfitting。我們說的overfitting就是在training set上performance很好,在testing set上performance沒有那麼好嘛。
link |
像這個k-nearest neighbor,decision tree,他們一做下去,在training set上正確率都是100,那個才是非常容易overfitting。
link |
而對deep learning來說,overfitting往往不是說deep learning沒有overfitting的問題,而是說,在deep learning裡面overfitting不是你會第一個遇到的問題。
link |
你第一個會遇到的問題是,你在training的時候,它並不是像k-nearest neighbor這種方法一樣,你一train,就可以得到非常好的正確率了。
link |
它有可能在training set上,根本沒有辦法給你一個好的正確率。
link |
所以這個時候,你要回頭去檢查說,在前面的step裡面,你要做什麼樣的修改,好讓你在training set上可以得到好的正確率。
link |
那假設現在呢,幸運的是,你已經在training set上得到好的performance了。
link |
你要用deep learning在training上得到100%的正確率,其實沒那麼容易的,但可能你在at least上得到一個99.8%的正確率了。
link |
好,接下來呢,你就把你的networkapply到testing set上。
link |
testing set上performance才是我們最後真正關心的performance。
link |
好,那你現在把你的結果呢,apply到testing set上。
link |
那在testing set上performance怎麼樣呢?如果現在得到的結果是no的話,那就是overfitting,這個情況才是overfitting。
link |
你在training set上得到好的結果,但是在testing set上得到的是不好的結果,這個時候呢,這個情況才叫做overfitting。
link |
那你要回頭過去做某一些事情,然後試著去解決overfitting這個problem。
link |
但有時候你加了新的technique,去想要overcomeoverfitting這個problem的時候,你其實反而會讓training set上的結果變壞了。
link |
所以你在做這一步的修改以後,你要先回頭去檢查說training set上的結果是怎麼樣。
link |
如果training set上的結果變壞了的話,你要重頭去再重新對你的network的training的process做一些調整。
link |
那如果你同時在training set還有你手上的testing set都得到好的結果的話,最後你就可以把你的系統用在真正的application上面,你就成功了。
link |
那這邊有一個重點就是,不要看到所有不好的performance,就說是overfitting。
link |
舉例來說,這個是文件上的圖,但我在現實生活中也常常看到這樣子的狀況。
link |
在testing data上面,橫坐標是model參數update的次數,重坐標是error rate,所以越低越好。
link |
如果我們現在比較一個20層的neural network,它是黃線,跟56層的neural network,它是紅線。
link |
那你會發現說,56層的neural network,它的error rate比較高,它的performance比較差。20層的neural network,它的performance是比較好的。
link |
有些人看到這個圖就會馬上得到一個結論說,所以56層太多了,參數太多了,56層果然沒有必要,這個是overfitting。
link |
但是真的是這樣子嗎?你在說現在得到的結果是overfitting之前,你要先檢查一下你在training set上的結果。
link |
對某些方法來說,你不用檢查這件事,比如說k-nearest neighbor,或者是decision tree,你不用檢查這件事,但是對neural network來說,你是需要檢查這件事情的。
link |
為什麼呢?因為有可能你在training set上得到的結果是這個樣子。橫軸一樣是參數update的次數,重軸是error rate。
link |
如果我們比較20層的neural network跟56層的neural network的話,你會發現說,在training set上,20層的neural network,它的performance本來就比56層好。
link |
在training set上,56層的neural network,它的performance是比較差的。那為什麼會這樣子呢?
link |
你想想看,你在做neural network training的時候,有太多太多的問題可以讓你的training的結果是不好的。比如說,我們有local minima的問題,有settle point的問題,有plateau的問題,有種種的問題。
link |
所以有可能這個56層的neural network,它一train的時候,它其實就卡在一個local minima的地方,所以它得到了一個差的參數。
link |
所以這個並不是overfitting,是在training的時候就沒有train好。有人會說這個叫做underfitting,我覺得這個可能不叫做underfitting,但這只是名詞定義的問題,所以你要怎麼說都行。
link |
在我心裡面,underfitting的意思是說,這個model的capacity,這個model的參數不夠多,所以它的能力不足以解除這個問題。但對這個56層的neural network來說,雖然它得到比較差的performance,但假如這個56層的network,它其實是在這26層的network後面,後面再堆另外36層的network,那它的參數其實是比20層的network還多的。
link |
理論上,20層的network可以做到的事情,56層的network一定可以做到。你前面已經有那20層,你前面那20層就做跟20層network一樣的事情,後面36層就啥事都不幹,都是identity就好了。你明明可以做到跟20層一樣的事情,你為什麼做不到呢?但是因為有很多問題就是讓你沒有辦法做到。
link |
所以這個56層的network比20層差,並不是因為它能力不夠,它只要前20層都跟它一樣,後面都是identity,明明就可以跟20層一樣好,但它卻沒有得到這樣的結果。所以它能力是夠的,所以我覺得這不是undefeated,它這個就是沒有train好。
link |
我不知道有沒有什麼名詞專門指稱這個問題就是了。所以它其實就是像小智的噴火龍一樣,它等級是夠的,但它就不想要打。
link |
所以在deep learning的文件上,如果當你讀到一個方法的時候,你永遠要想一下說,這個方法它是要解什麼樣的問題。因為在deep learning裡面有兩個問題,一個是training set上的performance不好,一個是testing set上的performance不好。
link |
當這一個方法proposed的時候,它往往就是針對這兩個問題的其中一個來做處理。舉例來說,你等一下可能會聽到一個方法叫做抓爆。抓爆可能大家都或多或少都知道它是一個很有deep learning特色,很潮的一個方法。
link |
但是很多人就會說,哦,這麼潮的方法,所以我今天只要看到performance不好,我就apply抓爆。但是你就要仔細想一下抓爆是什麼時候用的。抓爆是你在testing的結果不好的時候,你才會apply抓爆。
link |
你在testing的結果好的時候,你是不會apply抓爆的。就是說,抓爆是你在testing的結果不好的時候才apply抓爆。如果今天的問題是你training的結果不好,你apply抓爆,你只會越勸越差而已。所以,不同的方法對治什麼樣不同的症狀,你是必須要在心裡想清楚的。
link |
我們這邊就休息十分鐘,等一下再繼續講。
link |
我們剛才講說在deep learning的recipe裡面,在train deep learning的時候有兩個問題,所以等一下我們就是要這兩個問題分開來討論,看看當你遇到這兩個問題的時候有什麼樣解決的方法。
link |
首先,如果你今天在training的結果上不好的時候,你可能可以看看說,是不是你在做network架構的設計的時候,是不是設計的不好。
link |
舉例來說,你可能用的activation function是比較不好的activation function,是對training比較不利的activation function,你可能會換一些新的activation function,他們可以給你比較好的結果。
link |
那我們知道說,在1980年代的時候,比較常用的activation function是一個sigmoid function,那我們之前有試著稍微reason一下為什麼要用sigmoid function。
link |
今天如果我們用的是sigmoid function的時候,在過去,其實你會發現說deeper並不一定imply better,這個是在mnist上面的結果,在手寫數字辨識上的結果。
link |
當你layer越來越多的時候,你的accuracy一開始持平後來就掉下去了,在你的layer是九成十成的時候,整個結果都崩潰了。有人看到這個圖就會覺得說,九成十成參數太多了,overfitting。
link |
這個不是overfitting,為什麼呢?首先呢,我們說你要檢查說,你現在performance不好是不是來自於overfitting,你要看你training set的結果嘛,對不對?那這個線是training set的結果。
link |
所以,這個不是overfitting,這個是在training的時候就破壞掉了,不信的話,我們實際來用keras實做一下。一個原因是這樣子,這個原因叫做vanishing的gradient。
link |
這個原因是這樣,當你把network疊得很深的時候,在input的幾個layer,在最靠近input的地方,你的gradient,你的這些參數,對最後的loss function的微分會是很小。
link |
而在比較靠近output的地方,它的微分值會是很大的。因此,當你設定同樣的learning rate的時候,你會發現說,靠近input的地方,它參數的update是很慢,靠近output的地方,它參數的update是比較快。
link |
所以你會發現說,在input還是幾乎random的時候,output就已經converge了。在input這些layer,在靠近input的地方,這些參數,它還是random的時候,output的地方就已經根據這些random的結果找到了一個local minima,然後它就converge了。
link |
這個時候你就會發現說,你這個參數的loss的下降的速度變得很慢,你就覺得說卡在local minima之類的,然後就傷心的把程式停掉了。
link |
這個時候你得到的結果是很差的,為什麼呢?因為這個converge是幾乎based on random的參數,它幾乎based on random的output,然後去converge,所以你得到的結果是很差的。
link |
為什麼會有這個現象發生呢?如果你自己把backpropagation的式子寫出來的話,你可以很輕易的發現說,用sigmoid function會導致這件事情的發生。
link |
但是我們今天不看backpropagation的式子,我們其實從直覺上來想,你也可以了解說為什麼這件事情發生。
link |
怎麼用直覺來想,一個參數的gradient值應該是多少呢?我們知道說,某一個參數w,對total cost c的偏微分,它的直覺的意思就是說,當我今天把某一個參數做小小的變化的時候,它對cost的影響是怎麼樣?
link |
我們可以把一個參數做小小的變化,然後觀察它對cost的影響,以此來決定說,這個參數它的gradient值有多大。
link |
所以怎麼做呢?我們就把第一個layer裡面的某一個參數加上delta w,看看對network的output和target之間的loss有什麼樣的影響。
link |
那你會發現說,如果我今天這個delta w很大,通過sigmoid function的時候,這個output是會變小,也就是說,改變了某一個參數的weight,對某一個neuron的output的值會有影響。
link |
但是這個影響是會衰減的。為什麼這麼說呢?因為假設你用的是sigmoid function,我們知道sigmoid function的形狀就長這樣,那sigmoid function它會把負窮大到正無窮大之間的值都硬壓到0到1之間。
link |
也就是說,如果你有很大的input的變化,通過sigmoid function以後,它output的變化會是很小。
link |
所以今天你就算這個delta w有很大的變化,造成sigmoid function的input有很大的變化,對sigmoid function來說,它的output的變化是會衰減的。
link |
而每通過一次sigmoid function,變化就衰減一次。所以當你的network越深,它的衰減的次數就越多,直到最後,它對output的影響是非常小的。
link |
也就是說,你在input的地方改一下你的參數,對output的地方,它最後output的變化其實是很小的,因此最後對cost的影響也很小,因此就造成說,在靠近input的那些位置,它對它的衰減的值是小的。
link |
那怎麼解決這個問題呢?有人就說,原來比較早年的做法是train那個restricted Boltzmann machine,做這個layer-wise的pre-training。
link |
也就是說,你先認好第一個layer,因為我們現在說,如果你把所有的network都起來,你做backpropagation的時候,第一個layer你幾乎沒有辦法被調到。
link |
所以用RBM做pre-training的時候,它的精神就是,我先把第一個layertrain好,再train第二個,再train第三個。最後你在做backpropagation的時候,雖然說第一個layer幾乎沒有被train到,那無所謂,一開始在pre-train的時候就已經把它pre-train好了。
link |
所以這就是為什麼RBM做pre-train可能有用的原因。後來有人發現說,我記得Hinton跟Benjo幾乎在同一個時間不約而同提出同樣的想法,改一下exervation function,可能就可以handle這個問題了。
link |
所以現在比較常用的exervation function叫做rectified linear unit,它的縮寫是ilu,或常常有人叫它relu。
link |
這個exervation function它長這樣子,這個Z是exervation function的input,A是exervation function的output。
link |
如果今天exervation function的input大於0的時候,input等於output,如果exervation function的input小於0的時候,output就是0。那選擇這樣的exervation function有什麼好處呢?有以下幾個理由。
link |
一個理由是它比較快,跟sigmoid function比起來,它的運算是快很多的,sigmoid function裡面還有exponential,那個是很慢的。如果你是用這個方法的話,它是快得多的。
link |
如果你是用這個方法的話,裡面會告訴你說,這個exervation function的想法其實是有一些生物上的理由的,它把這樣的exervation跟一些在生物上的觀察結合在一起。
link |
我之前有說過,ilu這樣的exervation function,其實等同於是無窮多的sigmoid function疊加的結果。無窮多的sigmoid function,它們的bias都不一樣,疊加的結果會變成ilu的exervation function。
link |
它最重要的理由是,它可以handle vanishing gradient的這個問題。它怎麼handle vanishing gradient這個問題呢?我們來看一下,這是一個ilu的neural network,它裡面的每個exervation function都是ilu的exervation function。
link |
那我們知道說ilu的exervation function,它作用在兩個不同的region,一個region是當exervation function的input大於0的時候,input等於output,另外一個region是exervation function的input小於0,所以output就是0。
link |
所以現在每一個ilu的exervation function,它作用在兩個不同的region,一個region是每一個exervation function的,一個可能是exervation function的output就是0,另外一個可能是exervation function的input就等於output。
link |
當input等於output的時候,其實這個exervation function就是linear的。對那些output是0的neuron來說,它其實對整個network是一點影響都沒有的,它output是0嘛,所以它根本就不會影響最後output的值。
link |
所以假如有一個neuron它的output是0的話,你根本可以把它從network裡面整個拿掉。當你把這些output是0的network拿掉,剩下的neuron又都是input等於output都是linear的時候,你整個network不就是一個很瘦長的linear的network嗎?
link |
你整個network其實變成是一個linear的network。那這個時候,我們剛才說我們的那個gradient會遞減,是因為通過exervation,是因為通過sigmoid function的關係,sigmoid function會把比較大的input變成比較小的output,但是如果你是linear的話,input等於output,你就不會有那個exervation function遞減的問題了。
link |
講到這邊,有沒有人有問題呢?講到這邊,我有一個問題。現在如果我用IOU的時候,整個network都變成linear了,可是我們要的不是一個linear的network,我們之所以用deep learning,就是因為我們不想要我們的function是linear,我們希望它是一個nonlinear比較複雜的function,所以我們用deep learning。
link |
當我們用IOU的時候,它不是變成一個linear的function了嗎?這樣不會有問題嗎?這樣不是變得很弱嗎?其實是這樣子,這整個network,它整體來說,它還是nonlinear的,大家聽得懂嗎?
link |
當每一個neuron的operation region是一樣的時候,它是linear的。也就是說,如果你對input只做小小的改變,不改變neuron的operation region,它是一個linear的function。
link |
但是如果你對input做比較大的改變,你改變了neuron的operation region的話,它就變成是nonlinear的。這樣大家可以接受嗎?
link |
好,那有另外一個問題,這個也是我常常被問到的問題,這個不能微分啊,這不能微分,這樣你不覺得很苦惱嗎?
link |
我們之前說我們做gradient descent的時候,你需要對你的loss function可以做微分,意思就是說,你要對你的neural network是可以做微分,你的neural network是一個可微的function,IOU不可微啊,它至少在這個點是不可微的,那怎麼辦呢?
link |
其實實作上你就這個樣子啊,當你的region在這個地方的時候,gradient微分就是1,region在這個地方的時候微分就是0,反正不可能真的input正好是0嘛,所以就不要管它,結束這樣。
link |
好,那我們來真的實際試一下,如果我們把activation function換成IOU的時候,會得到什麼樣的結果,比如說,我們就這樣子,把sigmoid換成IOU,好,把sigmoid換成IOU。
link |
那我剛才看到用sigmoid的時候,training和testing的accuracy都很差,我們就簡單的把它換成IOU,什麼其他事都沒做。
link |
好,等我一下,那IOU其實還有種種的變形,那有人覺得說呢,如果是IOU的時候,如果是原來的IOU,它在input小於0的時候,output會是0,這個時候微分是0,你就沒有辦法update你的參數了。
link |
所以我們應該讓在input小於0的時候,output還是有一點點的值,比如說input小於0的時候,output是input乘上0.01,這個東西叫做立體的IOU。
link |
那這個時候有人就會問說,為什麼是0.01呢?為什麼不是0.078之類的呢?所以就有人提出了parametric的IOU,他說呢,在負的這邊,outputA等於inputZ乘上一個alpha,然後alpha是一個network的參數,它可以透過training data被學出來,甚至每個neuron都可以有不同的alpha值。
link |
但是又會有人問說,為什麼一定要是IOU這個樣子呢?可不可以是別的樣子?所以後來又有一個更進階的想法,叫做mixed out network。
link |
那在mixed out network裡面呢,你就是讓你的network去自動學它的activation function,那因為現在activation function是自動學出來的,而IOU,所以IOU就只是mixed out network的一個special case。
link |
就mixed out network,它可以學出IOU當activation function,但是它也可以是其他的activation function,用training data來決定說現在activation function應該要長什麼樣子。
link |
那mixed out network長什麼樣子呢?假如現在有input,是一個two dimension的vector,x1,x2,然後我們就把x1,x2乘上不同的weight變成一個value,然後再乘上不同的weight得到7,再乘上不同的weight得到3,再乘上不同的weight得到1。
link |
那本來這些值應該要通過activation function,不管是sigmoid function還是IOU得到另外一個value,但是現在在mixed out network裡面,我們做的事情是這樣子。
link |
你把這些valuegroup起來,哪些value應該被group起來這件事情是事先決定的,比如說現在這兩個value是一組,那你在同一個組裡面選一個值最大的當作output,比如這個組就選7,這個組就選1。
link |
那這件事情其實就跟max pooling一模一樣對不對,只是我們現在不是在image上做max pooling,我們是在一個layer上面做max pooling,我們把layer裡面的,本來要放到neuron裡面的activation function,我們本來要把它放到neuron裡的activation function的這個input的值group起來,然後只選max的當作output,然後就不用activation function了,就不加activation function了。
link |
得到的值是7跟1,那你可以想說這個東西就是一個neuron,只是它的output是一個vector而不是一個值。
link |
好,那接下來這個7跟1又乘上不同的weight,又得到另外一排不同的值,然後你一樣把它們做grouping,然後你一樣從每個group裡面選最大的值,比如說1跟2就選2,4跟3就選4。
link |
那其實在實作上幾個element要被放在同一個group裡面,這件事情是你可以自己決定的,它就跟network structure一樣,是一個你需要調的參數,所以你可以不是兩個element放一組,你可以是三個四個五個都可以,這個是你自己決定的。
link |
好,那我們現在先說,max-out-network它是有辦法做到跟IOU一模一樣的事情,它可以模仿IOU這個activation function,怎麼做呢?
link |
我們知道說,假設我們這邊有一個IOU的neuron,它的input就一個value x,那你會把x乘上這個neuron的weight w,再加上bias b得到z,然後通過activation function IOU得到a。
link |
所以現在如果我們看x跟a之間的關係是怎麼樣子呢?假設x是橫軸,那這個x是橫軸,假設y軸是這個z的話,它就是這個wx加b,而z跟x之間的關係是linear的,是linear是這個樣子。
link |
那如果你選a呢?那如果a呢?a跟z有什麼樣的關係呢?因為現在通過的是IOU的activation function,所以如果你今天的z的值大過0的時候,a等於z,z的值小於0的時候,a就是0。
link |
所以a跟x的關係是這個樣子的,在這個地方a等於z,在這個地方a等於0。所以如果我們今天用IOU的activation function和input和output,x和a之間的關係是長這個樣子。
link |
如果我們今天用max out network,你把input x乘上weight w加上bias得到z1,你再把x乘上另外一組weight加上另外一個bias得到z2,那我今天假設說這個另外一個weight跟另外一個bias就都是0,所以z2等於0。
link |
然後你做這個max pooling,你就可以選z1,z2其中一個比較大的當作a。
link |
所以現在如果我們看z1跟x之間的關係,我們得到的是藍色的這一條線,如果我們看x跟z2之間的關係,我們得到的是水平這一條線,因為z2總是0。
link |
那我們現在做的是max out,我們是在z1,z2裡面選一個大的當作output a,所以如果今天x是在這個region的時候,你的a就會等於z1是這個region,如果今天x是在這個region的時候,你的a就會等於比較大的那個z2,所以它會是這個region。
link |
那今天你只要這個w跟這個b等於這個w跟這個b,你就可以讓這個IOU的input output的關係等於這個max out network的input和output的關係,所以由此可知IOU是max out network可以做得到的事情,只要它設定出正確的參數。
link |
但是max out network它也可以做出更多的不同的exervation function,比如說現在如果這兩個weight不是0,而是w'b',那會怎樣呢?你就得到藍色這一條線z1跟紅色這一條線z2,因為w'b'是不一樣的值,所以它可能是另外一條斜直線長的是這樣子。
link |
那接下來你做max pooling的時候,你會在z1,z2裡面選一個大的,所以在這個範圍內你選了z1,在這個範圍內你選了z2,所以你就得到了一個不一樣的exervation function。
link |
而這個exervation function長什麼樣子,是由network的參數wb,w'b'決定的,所以這個exervation function它是一個learnable的exervation function,它是一個可以根據data去driven出來的exervation function,而每一個neuron根據它不同的weight,它可以有不同的exervation function。
link |
IOU是這樣子,它可以做出任何的piecewise linear convex的exervation function,如果你看一下它的性質,有不難理解這件事情。
link |
至於這個piecewise linear convex的function裡面有多少個piece,就決定於你現在把多少個element放成一個group。
link |
假如說兩個element一個group,那你可以有長這樣子的exervation function,這是IOU,你可以有一個exervation function,它的作用就是取絕對值。
link |
那假設你是三個element一個group,你可以有長這樣子的exervation function,你也可以有長這樣子的exervation function等等。
link |
接下來我們要面對的另外一個問題就是,這個東西怎麼train?這裡面有個max啊,它不能微分啊,這個東西怎麼train呢?
link |
這個做法是這樣子的,假設現在這個z1跟這兩個值比較大的是上面這個值,我們現在把這個group裡面比較大的值用框框框起來。
link |
比較大的值就會等於這個max operation的output,所以這個值等於這個值,這個值等於這個值,這個值等於這個值,這個值等於這個值。
link |
所以max operation其實在這邊就是一個linear的operation,只是它會選擇在前面這個group裡面的,它只接給前面這個group裡面的某一個element。
link |
也就是說其實這些沒有被接到的element,它就沒用啦,它就不會影響network的output啦,所以就可以把它拿掉。
link |
所以其實當我們在做max out的時候,當你給它一個input的時候,你其實也是得到一個比較細長的linear的network,所以你在train的時候,其實你train的就是這個比較細長的linear network裡面的參數。
link |
你就是去train這些,連到這一個element的這些參數,連到這個element的這些參數,連到這個element的這些參數,連到這個element的這些參數。假設我給你一個這樣的linear的network,你當然是知道它怎麼train的,你就用fabrication train就好了,你知道它是怎麼train的。
link |
那這個時候呢,你就會有一個問題,那沒被train到的人怎麼辦呢?如果某一個這個element它不是最大的值,那它連接的那些weight不就不會被train到了嗎?
link |
你做fabrication的時候,你只會train在這個圖上的比較深顏色的這些實線,你不會train到這個weight啦,這個weight不就沒被train到了嗎?怎麼辦呢?怎麼辦?
link |
看起來表面上是一個問題,但實作上它不是一個問題,為什麼呢?因為當你input不同的,當你給它不同的input的時候,你得到的這些z的值是不一樣的,你給它不同的input的時候,max的值是不一樣的。
link |
所以每一次你給它不同的input的時候,這個network的structure都是不一樣的,而因為我們有很多很多筆training data,而network的structure不斷的變換,所以最後每一個weight在實際上都會被train到。
link |
maxout就是這麼做的,maxout network就是這麼做的。所以如果我們回到maxboolean,maxboolean跟maxout是一模一樣的operation,就只是換一個說法而已。所以你會train maxout,你就會train maxboolean,就是一模一樣的做法。
link |
講到這邊,大家有沒有什麼問題呢?沒有嗎?好,那另外一個我們要講的是adaptive learning rate,其實adaptive learning rate我們之前已經有講過了,我們之前有講過adagren,我們之前有講過adagren。
link |
adagren它的做法就是,我們現在每一個parameter都要有不同的learning rate,而這個learning rate是怎麼給它這種adaptive learning rate呢?
link |
我就把一個固定的learning rate eta,除掉這個參數過去所有gradient值的平方和開根號,把這項除以平方和開根號,就得到新的parameter。
link |
這個adagren它的精神就是說,如果我們今天考慮兩個參數w1跟w2,如果w1是在這個方向上,如果w1在這個方向上,它平常gradient都比較小,代表它是比較平坦的,所以給它比較大的learning rate。
link |
反過來說,在這個方向上,平常gradient都是比較大的,所以它是比較陡峭的,所以給它比較小的learning rate。好,但是實際上呢,我們面對的問題有可能是比adagren可以處理的問題更加複雜的。
link |
也就是說,我們之前在做什麼logistic,在做什麼linear regression的時候呢,我們看到的這個optimization的function,我們loss function是這樣complex的形狀,但實際上當我們在做deep learning的時候,這個loss function它可以是任何形狀,你知道嗎?
link |
它可以是任何形狀,有時候它可以是這樣怪異的一個越型的形狀。那當如果今天你的error surface是這個形狀的時候,那你會遇到的問題是,就算是同一個方向上,你的learning rate也必須要能夠快速的變動。
link |
就我們剛才在convex function的時候,在每個方向上,你這個方向很平坦就一直很平坦,這個方向很陡峭就一直很陡峭,但是如果今天在更複雜的問題的時候,有可能你考慮w1改變的這個方向,在某個區域,它很平坦,所以它需要比較小的learning rate,但是到了另外一個區域,它又突然變得很陡峭,這個時候需要比較大的learning rate。
link |
所以真正要處理deep learning的問題,用adagrad可能是不夠的,你需要更dynamic的調整這個learning rate的方法。
link |
所以這邊有一個adagrad的進階版叫rnsprop,那rnsprop我覺得是一個蠻神奇的方法,就是你好像找不到它的paper,因為這個是在Hinton的那個MOOC的course裡面他提出來的,他在他的線上課程裡面提出一個方法,大家要scitech的時候,要scitech那個線上課程的youtube連結。
link |
這招還真的有用,這個rnsprop是這樣做的,它講我們現在把固定的learning rate除掉一個值,我們稱之為sigma,那這個sigma是什麼呢?
link |
在第一個時間點,這個sigma就是你第一次算出來的gradient值g0,那在第二個時間點,你算出另外一個新的gradient,g1,這個時候你的新的sigma值sigma1就是原來的sigma值的平方乘上alpha。
link |
再加上新的g的值,g1的平方,再乘上1-alpha,而這個alpha的值呢,是你可以自由去調的,也就是我們原來在做,或者我們在看下一個例,我們現在有一個,在下一個時間點我們要算出g2,我們得到sigma2,sigma2怎麼算的呢?
link |
它是把原來的sigma1取平方乘上alpha,再加上1-alpha乘上g2的平方,再開根號,得到這個sigma2。
link |
那跟原來的algebra不一樣的地方是,原來的algebra,你在這邊分母放的值,就是把g0,g1,g2都取平方和開根號,但是在這邊的時候,在rnsprop裡面呢,這個sigma1,它裡面包含了g0跟g1,那這邊也包含了g2,所以它根號裡面也同樣包含了g0,g1,g2,就跟algebra一樣。
link |
但是你現在可以給它乘上weight的alpha,或者是1-alpha,所以你可以調整說,我比較傾向,你可以調整這個alpha的值,這個alpha的值就也是像learning rate這個你要手動設的值,讓你就設個0.9之類的。
link |
你可以手動去調這個alpha的值,讓它說,如果你把這個alpha的值設得小一點,那意思就是說,你傾向於相信新的gradient所告訴你的這個error surface的平滑或陡峭的程度,就傾向於相信新的gradient,而比較無視於舊的gradient所提供給你的information。
link |
我想大家應該可以了解這個結果。所以在t的時間點你算出來的sigma,就是把sigma t-1的平方乘上alpha,加上1-alpha乘上在t的時間點算出來的gradient的平方。
link |
所以,當你做rmsprop的時候,你一樣是在算gradient的rooming square,但是你可以給現在你新看到的gradient比較大的位置,給過去看到的gradient比較小的位置。
link |
好,那除了learning rate的問題以外,我們知道說在做deep learning的時候,大家都會說我們會卡在local minima。那我之前也有講過說,我們不見得是卡在local minima,你有可能卡在settle point,甚至你有可能卡在settle的地方。
link |
大家聽到這個問題都非常的擔心,覺得說做deep learning是非常困難的,因為你可能是胡亂做一下就有一大堆的問題。那其實呢,Jan Larkin他在07年的時候有一個蠻特別的說法,他在07年的時候就講過這件事情了。
link |
他說,你不用太擔心local minima的問題。我不知道這件事情有多確切,就我沒有verify過,但如果你有什麼verify的結果的話,記得跟我分享。
link |
Jan Larkin的說法是這樣說的,他說,其實呢,在這個error surface上沒有太多local minima了,所以你不用太擔心。為什麼呢?他說,你要是一個local minima,你在每一個dimension都必須要是這樣子的形狀,對不對?
link |
你要是一個山谷的谷底,每一個dimension都是山谷的谷底。我們假設這個山谷的谷底出現的機率是P,在每個位出現的機率是P。因為我們的network有非常非常多的參數,所以假設有一千個參數,你每一個參數都是山谷的谷底,那機率就是P的一千字吧。
link |
你的network越大,參數越多,這個出現的機率就越低。所以,local minima在一個很大的neural network裡面,其實沒有你想像的那麼多。一個很大的neural network,它看起來其實搞不好是很平滑的,根本沒有太多local minima。
link |
當你走走走,走到一個你覺得是local minima的地方卡住的時候,它八成就是global minima,或者是很接近global minima,給大家參考。好,如果你有什麼特別的想法再告訴我。
link |
有一個heuristic的方法可以稍微處理一下我們上述說的local minima和plateau的問題。這個方法,你可以說是從真實的世界得到了一些靈感。
link |
我們知道在真實的世界裡面,如果這個是一個地形,是一個山坡,你把一個球從左上角丟下來,滾下來,然後它滾滾滾,滾到plateau的地方,它不會停下來,因為有慣性嘛,所以它還會繼續往前走。
link |
它就算是走到這個上坡的地方,然後這個坡沒有很陡,因為慣性的關係,它搞不好走走走還是可以翻過這個山坡,最後它就可以走到比這個local minima還要好的地方。
link |
所以我們要做的事情就是把這個慣性這個特性塞到gradient descent裡面去。這件事情就叫做momentum。這個東西怎麼做呢?我們先很快地秒複習一下一般的gradient descent。
link |
一般的gradient descent是怎麼做的呢?我們是這樣做的。這個是選一個初始的值,然後計算一下它的gradient,gradient說是這個方向,那我們就走gradient的反方向乘上一個learning rate eta,得到θ1,再算gradient,再走一個新的方向,再算gradient,再走一個新的方向,再算gradient,再走一個方向,以此類推,一直得到gradient等於零的時候,或者是很趨近於零的時候,我們就停止。
link |
當我們加上momentum的時候,我們是怎麼做的呢?當我們加上momentum的時候,我們每一次移動的方向不再是只有考慮gradient,而是我們現在的gradient加上在前一個時間點移動的方向。
link |
這樣聽起來可能很抽象,所以我們實際的來看一下它是怎麼運作的。一樣選一個初始值θ0,然後我們用一個值叫做V去記錄我們在前一個時間點移動的方向。
link |
V記錄我們前一個時間點移動的方向,因為現在是初始值,之前沒有移動過,所以前一個時間點移動的方向是零。接下來計算在θ0的地方的gradient,算出現在θ0的地方的gradient,算出來是紅色這個箭頭。
link |
然後我們現在要移動的方向並不是紅色箭頭告訴我們的方向,而是前一個時間點的momentumV0,再加上negative的gradient,然後我們得到現在要移動的方向V1。
link |
你知道這個就好像是慣性一樣,如果我們之前走的方向是V0,那今天有一個新的規定並不會讓你現在參數update的方向完全轉向,它會改變你的方向,但是因為有慣性的關係,所以原來走的方向還是有一定程度的影響。
link |
我們或許看下一個例子會比較清楚。我們現在在上一個時間點移動的方向是V1,接下來再計算以下的歸點,就是紅色的箭頭。
link |
接下來要決定說,在第二個時間點我們要走的方向是什麼樣。第二個時間點要走的方向是過去的走的方向V1,減掉learning rate乘上歸點。如果我們看這個圖上的話,歸點告訴我們說要走這個方向。
link |
負的eta乘上歸點是這個方向,但是前面的movement是綠色的箭頭,它是這個方向。我們會把這個movement乘上一個lambda,這個lambda其實也是一個跟learning rate要手要調的參數。
link |
它告訴你說現在慣性這件事情影響力有多大,lambda大的話慣性影響力就大,lambda小慣性影響力就小。
link |
總之,慣性告訴我們走這邊,歸點告訴我們走這邊,這兩個合起來就走了一個新的方向,就是這邊,這個就是V2。
link |
以此類推,新的歸點告訴我們走這邊,新的歸點告訴我們走紅色這個虛線的方向,慣性告訴我們走綠色虛線的方向,合起來最後就是走藍色的方向。
link |
Update參數以後,歸點告訴我們走紅色虛線的方向,慣性告訴我們走綠色虛線的方向,合起來就是走藍色的方向。
link |
你可以用另外一個方法來理解這件事情,其實Vi,你在每一個時間點移動的movement,在第一個時間點移動的步伐Vi,移動的量,方向的Vi,其實就是過去所有算出來的歸點的總和。
link |
為什麼這麼說呢?我們知道V0等於0,V1在這邊,V1是lambda乘V0減到eta乘上在theta0的歸點,而V0等於0,所以V1等於負的eta乘上歸點,所以是這個樣子。
link |
那V2呢?V2我們就把V1是負的eta乘上歸點,帶進去,我們把V1帶到這邊,再乘上lambda,再減掉eta乘以在theta1的歸點,得到的結果就是這樣。
link |
得到的結果就是,你把theta0的地方的歸點減掉lambda乘以eta,再減掉eta乘以在theta1的歸點,你得到V2。
link |
所以V2裡面同時有V在theta0的時候算出來的歸點,同時也有theta1的地方算出來的歸點。
link |
只是這兩個歸點的weight是不一樣的,如果你lambda你都設小於0的值的話,越之前的歸點,它的weight就越小,越之前的歸點你就越不去理它,你越在意現在的歸點。
link |
但是你過去的歸點也會對你現在要update的方向有一定程度的影響力,這個就是momentum。
link |
如果你看數學是不太喜歡的話,那我們就從直覺上來看一下,到底加入momentum以後是怎麼運作的。
link |
在加入momentum以後,每一次移動的方向是negative的歸點加上momentum建議我們要走的方向,這個momentum其實就是上一個時間點的movement。
link |
所以現在假設我們初始的參數是在這個位置,那歸點建議我們往右走,所以最後就往右移動。
link |
如果說之後移到這個位置,歸點建議我們往右走,而momentum也會建議我們往右走,因為我們是從左邊這邊移過來的,所以前一個步伐我們是向右的。
link |
所以如果你考慮momentum的時候,我們也會向右。
link |
所以你把歸點建議我們走的方向和momentum建議我們走的方向合起來,你就得到這個藍色的箭頭,所以會繼續向右。
link |
如果我們今天走到local minima的地方,走到local minima的地方,歸點是0,所以歸點會告訴你說就停在這裡。
link |
但是momentum會告訴你說,之前是從右邊走過來的,所以你仍然應該要繼續往右走,也就是綠色的箭頭的方向。
link |
所以最後你參數update的方向仍然會繼續向右。
link |
甚至你可以樂觀的期待說,如果今天再往右的時候走到這個地方,歸點要求我們向左走,而現在是左邊,如果你算微分的話,如果考慮歸點的話,參數應該往左移動了。
link |
但是momentum建議我們繼續向右走,因為你是從左邊過來的,你從左向右過來的,所以momentum建議你繼續向右走。
link |
如果今天momentum其實比較強的話,你最後就會還是向右走。
link |
所以你有一定的可能性可以跳出local minima,如果local minima不深的話,你有可能藉由慣性的力量跳出local minima,然後走到比較好的local minima,比較低的local minima。
link |
如果你今天把rnspop加上momentum的話,其實你就得到A等,現在如果你沒有什麼prefer的話,你就先選A等。我發現在作業2裡面其實還蠻多人implement A等的。
link |
太強了,太強了,你都自己implement A等,我想這個你應該都很熟吧,也沒什麼特別好講的。雖然你可能看這個algorithm感覺好像有點複雜,但是好多人都有implement這個東西。
link |
其實A等就是rnspop加上momentum,這兩個東西綜合起來就是A等。我們非常快的來看一下這個式子。
link |
在這個式子裡面,要一開始先初始一個東西叫做ending,ending就是momentum,就是前一個時間點的movement。它這邊有另外一個值叫做v0,v0就是我們剛才在rnspop裡面看到的sigma。
link |
這個東西就是之前的歸點的平方和,就是v0。它先算一下歸點就是gt,然後根據gt,你就可以算出新的mt,也就是現在要走的方向。
link |
現在要走的方向是考慮過去要走的方向再加上歸點。然後接下來算一下要放在分母的地方的vt,這個vt是過去前一個時間點的vt加上歸點的平方,等一下要開根號。
link |
這邊它做了一個跟原來rnspop跟momentum裡面沒有的東西,叫做bias correction,它會把mt跟vt都除上一個值,這個值本來比較大,這個值本來比較小,後來會越來越接近1。
link |
至於為什麼要這麼做,那個paper裡面會告訴你它的理由。最後,你在update的時候,你把momentum建議你的方向nt head,去除掉rnspop,繼續乘上learning rate alpha,再除掉rnspop,建議rnspop normalize以後的learning rate,最後得到你update的方向。
link |
這個就是add-on。我猜你或許沒有聽得太懂,不過沒有關係,因為在toolkit裡面其實都只是打個指令而已。我們就在這邊先休息10分鐘,等一下再繼續,謝謝。
link |
我們來上課吧。剛才講的都是說,如果你今天在training data上的結果不好的話怎麼辦?
link |
等一下我要講的是,如果今天你已經在training data上得到夠好的結果,但是你在testing data上的結果仍然不好,那你有什麼可行的方法?
link |
以下會很快的介紹三個方法,一個是Early Stopping,Regularization,Dropout。Early Stopping跟Regularization是很typical的做法,它們不是specific design for deep learning的,這是一個很傳統的做法。Dropout是一個還蠻有deep learning特色的做法,所以在講deep learning的時候我們需要講一下。
link |
我們來講一下Early Stopping,Early Stopping是什麼意思呢?我們知道說,隨著你的training,你的total loss呢,如果你今天的learning rate調的對的話,你的total loss通常會越來越小。
link |
當然有可能你learning rate沒有設好,loss變大也是可能的,但理想上learning rate調的很好的話,那你在training set上的loss應該是逐漸變小。
link |
但是因為我們知道說training set跟testing set它們的distribution並不完全一樣,所以有可能當你的training的loss逐漸減小的時候,你的testing data的loss卻反而上升了,這是有可能的。
link |
所以理想上,假如你知道testing data的loss的變化,你應該停在不是training set的loss最小,而是testing set的loss最小的地方。你在train的時候,你不要一直train下去,你可能train到這個地方的時候就停下來了。
link |
但是實際上,你根本不知道你testing set的error是什麼,所以我們其實會用validation set來verify這件事情。
link |
所以有個地方或許我需要稍微講得清楚一點,就是這邊的testing set並不是指真正的testing set,它指的是你有label data那些testing set,比如說如果你今天是在做作業的時候,這邊的testing set可能指的是cargo上的public set,或者是你自己切出來的validation set。
link |
希望大家可以知道我的意思,這個只是名詞用的不同而已。但是你不會知道真正的testing set的變化,所以其實我們會切一個validation set來verify說,什麼時候呢?
link |
用validation set模擬testing set來看說什麼時候呢?這個validation set的loss最小的時候,你的training就停下來了。其實在cargo裡面就可以支援你做這件事,所以你就自己看一下documentation。
link |
那regularization是什麼呢?我們重新定義了我們要去minimize的loss function,我們原來有一個loss function,我們原來要minimize的loss function是defined在你的training data上的,比如說minimize square error或minimize cross entropy。
link |
那在做regularization的時候,我們會加另外一個regularization的term。這個regularization的term比如說它可以是你的參數的L2null,什麼意思呢?
link |
假設我們現在我們的參數theta裡面,它是一組參數,w1,w2等等一大堆的參數,那這個theta的L2null就是你把你的model裡面的每一個參數都取平方,然後加起來,就是這個theta2。
link |
因為我們現在用L2null來做regularization,所以這件事稱之為L2的regularization。那我們之前有講過說在做regularization的時候,一般我們是不會考慮bias這一項的。
link |
因為我們之前有講過說加regularization的目的是為了要讓我們的function更平滑,而bias這件事情跟function的平滑程度通常是沒有關係的,所以通常我們在算regularization的時候,不會把bias考慮進來。
link |
好,那如果我們把L2的regularization放在這邊,我們會得到什麼樣的結果呢?如果說微分的話,會得到什麼樣的結果呢?如果我們把這個新的objective function,我們把新的這個loss function,
link |
也就是Lπ等於L,加上parameter的Qnull,做gradient的話,我們會得到Lπ對某一個參數w的偏微分,等於L對某一個參數w的偏微分,加上浪打乘上某一個參數。
link |
因為這一項是所有參數的平方和,所以把這一項對某一個參數w做偏微分,你得到的結果就是w。
link |
所以呢,你現在update參數的式子會變成這樣,本來我們update參數的式子是把原來的參數減掉eta,乘上w對這個loss function的偏微分,就得到新的參數。
link |
那現在這個loss function呢,這個Lπ呢,這個partial w分之partial Lπ,你可以換成這個樣子,那你把這一項塞到這個地方,你把這一項塞到這個地方。
link |
然後你會發現說呢,這邊有出現原來的參數,這邊也有出現原來的參數,所以你可以把這幾項整理在一起,就變成這樣。
link |
你把這一項,這一項提出來,變成1-eta乘上λ乘上wt,再減掉參數,你的參數對原來的loss function的歸零。
link |
那所以,如果根據這個式子,你就會發現說,其實在update我們參數的時候,每一次在update之前,你就把參數先乘個1-eta乘上λ。
link |
也就是每次呢,你在update你的參數之前,通常你這邊的這個η就是你的running rate嘛,它是一個很小的值。
link |
那這個λ呢,你通常也會設一個很小的值,比如說0.001之類的。
link |
所以η乘λ就是一個很小的值,1-η乘λ通常是一個接近1的值,比如說0.99。
link |
所以,今天如果你看這個update的式子的話,如果我們不管原來的這個新的loss function是怎麼寫的,你只看這個update式子的話,
link |
等於你在update你的參數的時候,你做的事情是,每次update參數之前,不分青紅皂白就先乘個0.99再說。
link |
也就是說,你每次都會讓你的參數越來越接近0。
link |
不一定是越來越小,因為如果今天w是負的,比如說是負的乘上0.99,它就變大了嘛,它就接近0嘛,對不對。
link |
所以今天呢,每一個參數在update之前就都胡亂乘上一個小於0的值,所以它每次都越來越靠近0,越來越靠近0。
link |
那有人就會想說,越來越靠近0,那最後不就通通變0嗎?這很崩潰啊,聽起來就不make sense。
link |
那不會最後所有的參數都變0,為什麼?因為你還有後面這一項啊,沒有後面這一項,每次update參數越來越小,最後就通通變0。
link |
但是問題就是後面還有這個從微分那邊得到這一項,那這一項會跟前面這一項最後取得平衡,所以並不會最後所有的參數都變成0。
link |
那因為如果我們使用這個L2的regularization的時候,我們每次都會讓weight呢,小一點小一點小一點,所以這一招呢,叫做weight decay。
link |
那其實是這樣子啊,在deep分析裡面,regularization雖然有幫助,但是它的重要性啊,跟其他方法,比如說SVM比起來並沒有那麼高。
link |
就regularization的幫助往往沒有那麼顯著,那我覺得一個可能的原因是,如果你看前面的early stopping,我們可以決定說什麼時候training應該要被停下來。
link |
因為我們現在在做這個neural network的時候,通常初始參數的時候,我們都是從一個很小的值,接近0的值呢,開始初始參數。
link |
因為我們初始的時候都是給它一個很小的接近0的值。那你在做update的時候,通常就是讓參數離0越來越遠,越來越遠,越來越遠。
link |
而做regularization這件事情,它要達到的目的就是希望我們參數不要離0太遠嘛。
link |
那讓我們參數不要離0太遠,加上regularization curve所造成的效果,跟減少update次數所造成的效果,其實可能是很像的。
link |
那你今天做early stopping,減少update次數其實也會避免你的參數離那些接近0的值太遠。
link |
那跟regularization做的事情可能是很接近的。
link |
所以在neural network裡面regularization雖然也有幫助,但是沒有那麼重要。
link |
沒有重要到比如說你看像SVM,它是explicitly把regularization這件事情寫在它的objective function裡面的,對不對?
link |
因為在做SVM的時候,它其實要解一個convex optimization的problem,所以實際上它解的時候不一定會有那個iteration的過程,它是一步就解出那個最好的結果了。
link |
所以你不像deep learning裡面它有early stopping這件事,SVM裡面沒有early stopping這件事,你一步就走到結果了。
link |
所以你沒有辦法用early stopping這件事防止它離0太遠,所以你必須要把regularization的explicitly加到你的loss function裡面去。
link |
那如果我們看L1的regularization,這個有人就會問說為什麼一定要平方,能不能用別的?
link |
你當然可以用別的,比如說你可以做L1的regularization。
link |
你可以把你的regularization換成你的參數的1-none,也就是換成你參數裡面,換成你的參數的集合裡面,每一個參數的絕對值的合。
link |
所以如果我們把這一項換掉的話,如果我們把這一項從2-none換成1-none的話,會得到什麼事呢?
link |
你的第一個問題可能就是,絕對值不能微分啊。給你最簡單的回答就是,這個東西implement在Keras、TensorFlow裡面都沒有問題,所以顯然是可以微分的。
link |
實際的回答是這個樣子的。這個東西是取絕對值,取絕對值input和output的關係不就是長這個樣子嗎?不就是一個V的形狀嗎?
link |
然後在V的一邊,微分值是1,在另外一邊微分值是-1,那不能微的地方其實只有在0的地方而已嘛,就不要管它這樣子。
link |
真的走到0,真的出現0的時候,你就胡亂給它一個值,比如說給它0就好了。
link |
所以說,如果你把這一項對W做微分的時候,你得到的結果是怎麼樣呢?如果你今天W是正的,那微分出來就是正1,W是負數,微分出來就是負1。
link |
所以我們這邊寫了一個W的side function,W的side function的意思就是說,如果W是正數的話,這個function output就是正1,W是負數的話,這個function output就是負1。
link |
好,那如果我們把這一項塞到參數update式子裡面會得到什麼結果呢?就變成這樣。那我們可以把這個展開來,就變成這樣。那這個式子告訴我們什麼?
link |
我們現在每一次update參數的時候,我們就不管31、21都一定要去減一個Era乘讓打再乘一個W的side。也就是說,今天如果W是正的,這一項就是正1,所以就變成是減一個positive的值,就會讓你的參數變小。
link |
如果W是負的,這一項是負1,那就變成是加一個值,就會讓你的參數變大。也就是說,只要你的參數是正的,就減掉一些,只要你的參數是負的,就加上一些。
link |
那不管那個參數原來的值是多少。所以如果你把這個L1跟L2做一下比較的話,你會發現說,他們同樣是讓參數變小,但是他們做的事情是略有不同的。因為如果你是用L1的時候,每次都減掉一個固定的值,你用L2的時候,你是每一次都乘上一個小於1固定的值。
link |
所以如果今天W是一個很正的值的話,比如說它是100萬,那你乘上一個0.99,你其實是把W減掉很大的值。但是對L1來說,它每次減掉的值都是固定的,不管W是100萬還是0.1,它減掉的值都是固定的。
link |
所以對L1來說,對L2來說,只要W有出現很大的值,它的很大的W下降很快,它很快就會變得很小,但是如果你今天是L1的話,那就不一樣。如果W有很大的值,它的下降的速度跟其他很小的W是一樣的。
link |
所以透過L1的training以後,你有可能認出來的model裡面還是有一些很大的值。但是如果我們考慮很小的值的話,對L2來說,很小的值,它的接近0的值,比如說0.1、0.11,它的下降的速度就很慢。
link |
所以在L裡面,它會保留很多training出來的結果,它會保留很多接近0的值。但L1每次都下降一個固定的value,所以在L1裡面,它不會保留很多很小的值。
link |
所以如果你用L1做training的時候,你得到的結果就是會比較sparse。所以比較sparse的意思是說,你認出來的參數裡面有很多接近0的值,但是也有很大的值。不像如果是L2的話,你認出來的結果,你的值是平均的都比較小。
link |
所以他們認出來的結果是略有差異的。我們剛才在講CN的時候有講過L1,就是要產生一個image的時候,有產生L1。在剛才那個APEX裡面,L1是比較適合的,因為我想要看到很sparse的結果。
link |
我有試過用L2,但是結果就沒有L1看起來的圖那麼明顯。雖然L1看起來的圖也沒有很明顯,但L1看起來的結果還比較像是一個digit。
link |
我們在人腦裡面也會做weight decay,我記得龍騰的生物課本上有這個圖。這個是剛出生的時候,嬰兒的神經是這樣,六歲的時候有很多很多的神經。但是到十四歲的時候,神經間的連結又減少了。
link |
所以Neural Network會跟人類很類似的事情。如果有一些weight,你都沒有去update它,它每次都會越來越小,最後就接近零,就不見了。這跟人腦運作是有異曲同工之妙的。
link |
最後我們要講一下Dropout。我們先講Dropout是怎麼做的,然後才講為什麼這樣做。Dropout是怎麼做的呢?它是這樣。在training的時候,每一次我們要update參數之前,我們都對每一個neural,其實也包括input的地方,input的這個input layer裡面的每一個element也算是一個neural。
link |
我們對network裡面的每一個neural做sampling。這個sampling是要決定說,這個neural要不要被丟掉。每一個neural有p%的機率,會被丟掉。
link |
如果一個neural被sample到要丟掉的時候,你也知道這個neural被丟掉了,所以跟它相連的weight也失去作用,也都被丟掉,所以就變成這樣。所以做完這個sample以後,你的network的structure就變瘦了,變得比較細長。
link |
然後呢,你再去train這個比較細長的network。而要注意一下就是,這個sampling是每一次update參數之前都要做一次。所以每一次update參數的時候,你拿來train你的network的structure是不一樣的,每一次你都要重新做一次sample。所以你每一次再做重新sample的時候,你得到的這個結果會是不一樣的。
link |
那testing的時候呢,其實這邊呢,當你在training的時候使用抓爆的時候,你的performance是會變差的。
link |
了解我的意思嗎?就是因為本來如果你不要抓爆的話,本來好好的做不要抓爆的話,在endless上你大概可以把正確率做到100%,但是如果你這樣抓爆的時候,因為你的神經元在train的時候,有時候莫名其妙就會不見。所以你在training的時候performance是會變差的,比如說本來可以train到100%,它就會變成只能train到98%,因為有一些neural不見了嘛。
link |
所以當你加了抓爆的時候,你在training上會看到結果變差,但是抓爆它真正要做的事情是,它就是要讓你的training的結果變差,但testing的結果是會變好的。
link |
也就是如果你今天遇到的問題是你training做得不夠好,你再加抓爆,你就是越做越差這樣子。
link |
好,那在testing的時候怎麼做呢?在testing的時候要注意兩件事。第一件事情就是testing的時候不做抓爆。testing的時候就是所有的neural我都要用,不做抓爆。另外一個地方是,在testing的時候,假設你的抓爆rate,在training的時候抓爆rate是p%,那在testing的時候所有weight都要乘以1-p%,也就是說,假如現在抓爆rate是50%,
link |
那我們在training的時候認出來的weight等於1,那testing的時候你要把那個weight設0.5,這有沒有很奇怪?我看很多人都看起來都皺眉頭這樣子。
link |
這個步驟非常的神妙這樣子,我覺得這是第一個想出來的,這個hint of a problem,如果憑空想出這樣的方法真的是非常神妙。那你自己在implement抓爆的時候,過去在還沒有那麼多toolkit的時候,常常有人說,來給我看個程式,說,噢,我做抓爆,perform沒有進步啊,老師,你看看怎麼辦?
link |
然後我看到就覺得,噢,你忘了除這個0.5,難怪沒有進步。不過現在toolkit會自動幫你除0.5,所以就不用再擔心這些事情了。
link |
那為什麼抓爆有用?直覺的想法是這樣子,training的時候我會丟掉一些neuron,就好像是說你要練輕功的時候,你會在腳上綁一些重物,然後你實際上戰鬥的時候,實際上testing的時候是沒有抓爆的,所以實際上testing的時候你就把重物拿下來,所以就會變得很強。
link |
這個是小李,他平常都綁一個重物,只有在我介紹貫徹自己的忍道的時候才拿下來,所以最後還是打輸我愛羅就是了。
link |
另外一個直覺的理由是這樣子,一個neuron network裡面的每一個neuron就是一個學生,大家被連結在一起,大家team up要做final project,你知道說在一個團隊裡面總是有人會擺爛,他是會抓爆的。
link |
所以假設你覺得說你的隊友其實是會擺爛的,所以這個時候你就會想要好好做,那實際上你就想要去carry他,那實際上最後在testing的時候,大家都有好好做,沒有人需要被carry,那因為每個人都做得更努力,所以結果是更好。
link |
所以在testing的時候不用抓爆。那另外一個要解釋的就是,直覺要解釋的是為什麼要抓爆Rate50的時候就要乘1.5,為什麼training跟testing用的weight是不一樣的呢?
link |
照理說training用什麼weight就要用在testing上啊,你就在training跟testing的時候居然用的是不同的weight,為什麼這樣呢?直覺的理由是這樣。
link |
假設現在抓爆Rate是50%,那在training的時候,你的期望總是會丟掉一半的neuron,對不對?對每一個neuron來說,總是期望說他有一半的neuron是不見的,是沒有input的。
link |
所以你現在如果認好一組weight的時候,假設你在這個情況下認好一組weight,但是在testing的時候,testing的時候是沒有抓爆的啊,所以對同一組weight來說,假如你在這邊用這一組weight得到Z,跟這邊用這一組weight得到Zπ,他們得到的值其實是會差兩倍的,對不對?
link |
因為在這個情況下你總是會有一半的input不見,在這個情況下你所有的input都會在,而如果你用同樣一組weight的話,變成Zπ就是Z的兩倍了,這樣變成training跟testing不match,你performance反而會變差。
link |
所以怎麼辦?把所有weight都乘0.5啊,乘0.5以後做一下這個normalization,把所有weight都乘0.5,這樣變成Z就會等於Zπ,所以這是怎麼回事?
link |
把這個weight乘上一個值以後,反而會讓training跟testing是比較match的。這個是比較直觀上的結果,如果你要更正式講的話,其實抓爆有很多理由,這個東西還是一個可以探討的問題,可以在文獻上找到很多種不同的觀點來解釋為什麼抓爆會work。
link |
我覺得我比較能夠接受的是,抓爆是一種終極的ensemble的方法。什麼是ensemble的方法呢?ensemble的方法在比賽的時候常用,ensemble的方法的意思是說,我們有一個很大的training set,那你每次從training set裡面只sample一部分的data出來。
link |
你記得我們在講bias跟variance的tradeoff的時候,我們不是有講過打靶有兩種狀況,一種是你的bias很大,所以你打不準,一種是你的variance很大,所以你打不準。
link |
如果你今天有一個很複雜的model,很笨重很大的model的時候,它往往是bias準,但variance很大。但是如果你這個笨重的model有很多個,雖然它variance很大,最後平均起來,結果就很準。所以今天ensemble做的事情,其實就是要利用這個特性。
link |
我們trade很多個model,我們把原來的training data裡面sample出很多subset,然後trade很多個model,每一個model甚至是structure不一樣。雖然說每一個model,它們可能variance很大,但是如果它們都是很複雜的model的時候,平均起來,這個bias就很小。
link |
你真正在testing的時候,你train了一把model,然後在testing的時候,丟一筆training data進來,它通過所有的model得到一大堆的結果,再把這些結果平均起來,當作你最後的結果。
link |
如果你的model很複雜的話,這一招往往有用,像random forest也是實踐這個精神的一個方法。如果你用一個decision tree,它都很弱,胡亂做overfitting,但是如果你用random forest,它就沒有那麼容易overfitting。
link |
為什麼說dropout是一個終極的ensemble的方法呢?我們知道在做dropout的時候,我們每次sample一個mini-batch,我們每次要update參數的時候,你拿一個mini-batch出來要update參數的時候,你都會做一次sample。
link |
所以你拿第一個mini-batch的時候,你train的network長這個樣子,你拿第二個mini-batch的時候,你train的network可能長這樣,你拿第三個長這樣,你拿第四個長這樣。所以在做dropout的時候,你等於是一個終極的ensemble的方式。
link |
假設你有n個neuron,每個neuron可以drop或不drop,所以你可能的neuron的數目有2的n次方格。當你在做dropout的時候,你等於就是在train這2的n次方格network。
link |
你每一次都只用一個mini-batch的data去train一個network,你用這個mini-batch裡面的data,一個mini-batch可能就100筆data嘛,你用這些data去train這個network,用這些data去train這些network,用這些data去train這些network。
link |
那總共有2個n次方格可能的network,當然因為你最後update的次數是有限的,你可能沒有辦法把2個n次方格network每一個都train一遍,但是你可能就train了好多好多的network。
link |
你有做幾次update產品就train幾個network,但是每個network就只用一個batch來train。那每個network用一個batch來train可能會讓人覺得很不安,一個batch才100筆data,怎麼train一整個network呢?
link |
沒有關係,因為這些不同的network之間的參數是shared的,也就是說,這個network的這個參數就是這個network的這個參數,就是他的這個參數,就是他的這個參數,這4個參數其實是同一個參數。
link |
所以雖然說一個network的structure他只用一個batchtrain,但是一個weight他可能用好多的batch來train,比如說這個weight他在這4個batch裡面,在這4個batch做抓抱的時候都沒有把這個weight丟掉,那這個weight他就是拿這4個batch合起來train的結果。
link |
所以當你做抓抱的時候,你就是train了一大把的network structure,理論上每一次update參數的時候你都train了一個network出來。
link |
那testing的時候呢,按照ensemble這個方法的邏輯應該就是,你把那一大把的network通通都拿出來,然後呢,你把你的testing data丟到那一把network裡面去,每一個network都給你train的結果,然後把所有的結果平均起來,這是最終的結果。
link |
但是在實作上也沒辦法這麼做,因為這一把network實在太多了,這一把network實在太多了,你沒有辦法把它通通都拿出來,每一個都丟一個input進去,看看output是什麼,最後再平均起來,這樣運算量太大。
link |
所以抓抱最神奇的地方是,他告訴你說,當你把一個完整的network不做抓抱,但是把它的weight乘上1-p%,然後你把這一個東西,把你的training data丟進去,然後得到它的output的時候,神奇的就是,這個ensemble的結果跟這一個把weight乘上1-p%的結果是可以approximate的。
link |
那你可能會想說,何以見得呢?我們來舉一個例子。我們train一個很簡單的network,它就只有一個neural,它的activation function是linear的。
link |
我們這邊就不考慮bias,我們這邊有一個neural,然後它的input是x1,x2,然後x1,x2分別乘上,經過training以後,x1,經過抓抱的training以後,你是認出來的weight是w1,w2,所以它的output就是w1,x1,加上w,x2。
link |
這個neural沒有activation function,或activation function是linear的。如果我們今天要做ensemble的話,theoretically應該就是這麼做。
link |
每一個neural,我們做抓抱的時候,你不會dropoutput的neural,你只會drophidden layer跟input的neural。那這邊每一個input,它可以被drop或不被drop,所以我們總共有四種structure,一個是通通沒被drop,一個是dropx1,一個是dropx2,一個是x1,x2都drop掉。
link |
最後得到的output呢?這個neural,假設你input x1,x2,這個neural給我們的就是w1,x1,加上w,x2,同樣的input,但是x1被drop掉,你得到output w2,x2,這邊給我們w1,x1,這邊給我們output4.
link |
然後我們要做ensemble,所以你要把這四個neural它的output通通都average起來。那average起來的結果是不是就是,這邊有四個值嘛,然後w1,x1出現兩次,w2,x2出現兩次,所以得到的結果是1w1,x1,加1w2,x2,對不對?
link |
好,那如果我們現在做的事情是把這兩個weight都乘1w1乘1w2乘1w2,同樣input x1,x2,那得到的output也一樣是1w1,x1,1w2,x2。
link |
OK,所以這邊想要呈現的是說,在這一個最簡單的case裡面,ensemble這件事情,就不同的neural structure做ensemble這件事情,跟我們把weightmultiply一個值,而不做ensemble所得到的output,其實是一樣。
link |
那你可能會說,這個例子這麼簡單,在這個例子上會work,我想也是很直覺啦,大概小學生都知道說這個是equivalent的,但是在,比如說假設這邊是sigmoid function,或者它是很多個layer,它會work嗎?
link |
結論就是不會equivalent,只有是linear的network,ensemble才會等於multiply一個weight,左邊跟右邊要相等的前提是你的network是linear的,但是network不是linear,所以它們其實不equivalent。
link |
這是Dropout最後一個很神奇的地方,雖然不equivalent,但最後結果還是work。所以根據這個結論,有人有一個想法是說,既然Dropout在linear的時候,linear的network上ensemble才會等於乘一個weight。
link |
所以今天如果我的network很接近linear的話,應該Dropout的performance會比較好,比如說什麼時候network會比較接近linear,比如說你用IOU,比如說你用maxout network,它們是相對於sigmoid是比較接近linear的。
link |
所以Dropout確實在用IOU和sigmoid,或者是maxout network的時候,它的performance是確實有比較好的,如果你去看maxout network的paper的話,它裡面也有point這一點,就是它的maxout network跟Dropout加起來的進步量是比sigmoid方面還要大的,這個是作者相當自豪的一點。
link |
好,這邊我要講的其實就是這樣了,其實我們還有十分鐘。