back to index
ML Lecture 11: Why Deep?
link |
教授我們說,network越deep,從一層到七層,果然error rate不斷地下降。
link |
那問題是,如果你仔細地思考一下這個問題,你的network越深,如果implied是你的參數越多的話,那這個有什麼好說嘴的?
link |
你的model比較複雜,那你的data如果比較多的話,本來performance就會比較好啊。
link |
所以,你真正要比較deep和shallow的model的時候,你應該做的事情是,你要調整deep和shallow的model,讓他們的參數是一樣多的。
link |
那很多人在比較deep和shallow的model的時候,是沒有注意到這件事情的,所以那個評比是不公平的。
link |
如果你要給deep和shallow的model一個公平的評比,你要故意調整他的參數,讓他們的參數是一樣多的。
link |
那在這個情況下,shallow的model就會是一個矮胖的model,deep的model就會是一個高瘦的model。
link |
那接下來的問題就是,在這個公平的評比之下,是shallow比較強,還是deep比較強呢?
link |
所以剛才那個實驗結果裡面呢,是有後半段的。
link |
這後半段的實驗結果是這樣說的,他說,我們用五層,每層兩千個neuron,得到error rate是17.2,error rate是越小越好。
link |
那今天用一層3772個neuron,得到error rate是22.5。
link |
為什麼是3772個neuron呢?這個並不是什麼lucky number,就是為了要讓一個hidden layer的network跟有五層的hidden layer的network,他們的參數是接近的。
link |
好,那如果我們只有一層的network,這個時候他的error rate是22.5,那這個error rate遠比他大。
link |
那如果我們看另外一個case,七層,每層兩千個neuron跟一層四六三四個neuron,他們的參數的數目是接近的,這個時候你會發現說只有一層,他的performance是比較差的。
link |
甚至如果你今天再增加network的參數變成一層,但是有16k個neuron,有好多好多的neuron,有原來這個case的四倍,那你的error rate也只有從22.6降到22.1而已。
link |
當你用一個只有一層但非常非常寬的network跟也是只有一層但沒有那麼寬的network來比,因為他的參數比較多,所以他的performance還比他強,但如果你比較這個有兩層的network跟這個只有一層的network,這個有兩層的network他的參數遠比他少,這個參數是少的,這個參數是多的。
link |
但是結果這個case只有兩層,他的performance還是比只有一層的network的performance還要好,現在接下來的問題就是為什麼會這樣,為什麼會這樣,因為在很多人的想像裡面deep learning會work,就是因為有人覺得說deep learning是一個暴力碾壓的方法,我弄一個很大很大的model,然後我collect一大堆的data,所以就得到了比較好的performance。
link |
他就是一個暴力的方法,那你有沒有發現實際上不是這個樣子,如果你今天只是單純的增加parameter,但是你是讓network漲寬而不是漲高的話,其實你對performance的幫助是比較小的,把network漲高對performance的影響是很有幫助,把network漲寬,幫助沒有那麼好,為什麼會這樣呢?
link |
我們可以想像說,當我們在做deep learning的時候,其實我們就是在做模組化這件事情,什麼意思呢?大家應該都會寫程式,所以你就知道說,當你在寫程式的時候,你不能把所有的程式都寫在你的main function裡面,比如說你不能把五千行的程式都寫在main function裡面,你會寫一些sub function,對不對?
link |
你會在你的main function裡面去call sub function1,sub function2和sub function3,然後sub function2裡面可能還會去call sub sub1,sub sub2,sub sub3,然後sub sub function2會再call sub sub sub function2這樣子,它是一層一層,它是有這個結構化的結構,但是這個程式呢,你要有這個結構化的架構,這樣做的好處是,有一些function是可以共用的,
link |
比如說,搞不好這個function是sorting,然後你只要在其他的更high level的function裡面call sorting,都會call到這個function,你就不用每一次在每一個sub function裡面,需要做sorting的時候,都implement一個完整的sorting function,你可以把它變成模組,然後需要的時候再去call它,這樣你就可以減少你程式的複雜度,可以讓你的程式比較簡潔。
link |
那如果用在machine learning上面呢,你可以想像我們現在有這樣一個test,假設我們要做影像分類,那我們要把image分成比如說四類,比如長頭髮的女生,長頭髮的男生,短頭髮的女生,短頭髮的男生,那你可能說,我對這四類我們要分類的影像,通通去collect data,比如說,長頭髮的女生可以collect到一堆data,然後長頭髮的男生也有一些data,短頭髮的女生,短頭髮的男生,都有一些data,你就去train,四個classify,那你就可以sort data。
link |
但是問題就是,長頭髮的男生你的data可能是比較少的,比如說在立法院裡面只有林昶佐是長頭髮,他現在不是長頭髮,所以data是比較少的,所以你沒有太多的training data,所以你train出來的,長頭髮的男生classify就比較weak了,所以你detect長頭髮的男生performance就比較差,那怎麼辦呢?你可以用模組化的概念。
link |
假設我們現在不是先直接去解那個問題,而是把原來的問題切成比較小的問題,比如說,我們認一些classify,這些classify它的工作是去detect有沒有某一種的attribute出現,比如說,它不是直接去detect說是長頭髮的男生還是長頭髮的女生,它是把這個問題切成比較小的問題,它把這個問題切成,我們先決定說input一張image,它是男生還是女生。
link |
input一張image,它是長頭髮還是短頭髮。雖然說長頭髮的男生的data很少,雖然說長頭髮的男生的data很少,但女生的data和男生的data你都可以分別collect到足夠的data。雖然長頭髮的男生的data很少,但是長髮的人跟短髮的人的data你都可以collect到夠多。
link |
所以,這樣子你train這些basic classifier的時候,你就不會train得太差,這些basic classifier都是有足夠的data把它train好。
link |
所以接下來,如果你要解最後的這個我們要真正處理的問題的時候,你的每一個classifier就去參考這些basic attribute的output,也就是最後要下決定的這個classifier,它是把前面的basic classifier當作module去call它的output,而每一個classifier都共用同樣的module,只是可能用不同的方式來使用它而已。
link |
對classifier來說,它看到前面的basic classifier告訴它說,是女生,是長頭髮,那這個classifier的output就是yes,反之就是no,所以它們可以對後面這些classifier來說,它可以利用前面的這些classifier,所以它只要用比較少的training data,就可以把結果train好。
link |
雖然說classifier2的data很少,但是現在要做的事情是比較簡單的,因為真正複雜的事都被basic classifier做掉了,所以classifier2要做的事情比較簡單,所以比較少的data就可以把它train好。
link |
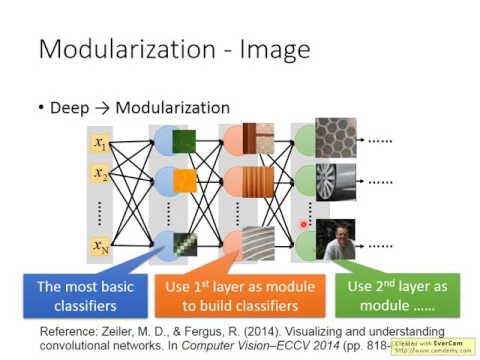
那deep learning怎麼跟模組化這個概念扯上關係呢?你想想看,每一個neuron其實就是一個basic classifier,第一層neuron它是最basic classifier,第二層neuron是比較複雜的classifier,它用第一層的basic classifier的output當作它的input,它把第一層的classifier當作module,而第三層的neuron又把第二層的neuron當作它的module,以此類推。
link |
當然這邊要強調的是說,在做deep learning的時候,怎麼做模組化這件事情是machine自動學到的,那我覺得這件事情還頗神奇,machine就自動學到說,比如說在image裡面,第一層classifier就是detect最單純的attribute等等。
link |
那我們剛才說,做modularization的好處是什麼?做modularization的好處是讓我們的模型變簡單了,對不對?我們是把本來的複雜的問題變得比較簡單,所以當我們把問題變簡單的時候,就算training data沒有那麼多,我們也可以把這個task做好,這個是modularization的,這是模組化的精神。
link |
如果deep learning做的是模組化的話,那其實神奇的事就是deep learning需要的training data是比較少的,這有沒有跟你的認知是相反的呢?我知道現在因為deep learning很紅,然後新聞上都有各種各式各樣的說法,常常聽到有人說AI就等於big data加deep learning,
link |
那很多人就會覺得說,所以deep learning會work,是因為big data的關係,沒有big data,deep learning就不會work了,那其實我認為並不是這個樣子的,如果你仔細想想看,假設我有真正很大的big data,假設我今天要做image classification,
link |
然後我的database實在是太大了,大到我可以把全世界的image統統收集進來,你testing的每一張image都在我database裡面有一張,那我何必做machine learning,我就table look up就好了。
link |
所以其實machine learning跟big data在某種程度上其實是相反的,你有真正的big data的時候,你就不用認它,你就table look up,我們之所以不能table look up,就是因為我們沒有足夠的data,所以我們才需要machine去做舉一反三這件事情,
link |
我們才需要machine去做學習這件事情,所以這邊有沒有跟你的認知是不太一樣的呢?其實當我們做deep learning的時候,就是因為我們沒有足夠的training data,所以我們需要deep learning,那這個我們剩下就留待下一次再說,謝謝。
link |
好,各位同學大家好,我們開始上課吧,那上週我們講到說為什麼我們需要用到deep learning,然後這是我們已經講過的,我們說如果你用deep learning的話,你其實是在做模組化這件事情,
link |
所以如果從這個模組化的觀點來看的話,deep learning它所給我們帶來的優勢並不是就像有人說的,我就用一個比較大的model,然後有比較多的參數,然後可能有比較多的training data,然後硬train下去,所以performance be shallow的model,那可能不是這樣,因為我們說deep learning的好處,它是來自於模組化,
link |
那模組化的好處是我現在是用比較efficient的方式來使用我的參數,在影像上面你可以觀察到類似模組化的現象,那接下來我要講的是語音的部分,那我們知道deep learning在影像和語音上面它的表現特別好,
link |
那我們再來講一下在語音上為什麼我們會需要用到模組化的概念,那我們先非常非常簡短的介紹一下人類語言的架構,當你說一句話的時候,比如說你說what do you think,那這句話其實是由一串phony所組成的,所謂的phony它的中文翻成音數,
link |
如果你不知道phony,它是這個語言學家定出來的人類發音的基本單位,那如果你不知道phony是什麼的話,你就把它想成是音標,所以what由四個phony組成,do由兩個phony組成,u由兩個phony組成等等,然後接下來同樣的phony,它可能會有不太一樣的發音,為什麼呢?
link |
當你發do的物的時候跟你發u的物的時候,你心裡想的是同一個phony,你心裡想要發的都是物,但是因為人類這個口腔的器官的限制,所以你沒有辦法每次發的物都是一樣的,為什麼呢?
link |
因為這個物前面跟後面有接了其他的phony,因為人類這個發音器官的限制,所以你的phony的發音會受到前後的form所影響,所以為了表達這件事情,我們會給同樣的phony不同的model,這個東西叫做triple。
link |
那triple表達的方式是這樣,你把這個物加上前面的phonyd跟後面的phonyy,跟這個物加上前面的phonyy跟後面的phonyth,就是triple。
link |
那有人看到這種表示方式就覺得說,triple就是三個form,看起來像是本來只考慮一個form,現在考慮三個form,這不是這個意思,這不是考慮三個form的意思,這個意思是說,現在一個form我們用不同的model來表示它,如果一個phony它的context不一樣,這兩個物的context不一樣,我們就用不同的model來模擬這樣的,來描述這樣的phony。
link |
那一個phony它可以拆成幾個state,state有幾個其實是你要自己定的,是engineer自己定的,比如說我們通常就定成三個state。
link |
好,那這個是人類語言的基本架構。那怎麼做語音辨識呢?語音辨識其實非常複雜,我們現在只講語音辨識的第一步。第一步你要做的事情是把acoustic feature轉成state。
link |
這是一個單純的classification的problem,這個classification的problem就跟比如說你在做作業3,把input一張image分成十類是一樣的,我們現在只是要input一個acoustic feature,然後把它分說它是屬於哪一個state。
link |
那所謂acoustic feature是什麼呢?在這邊我們不會細談,所謂的acoustic feature簡單想起來就是input聲音訊號它是一串waveform,那你把這個在這個waveform上面取一個window,這個通常取,這個不會取太大,比如說250個minutesecond。
link |
你把一個window裡面就把它用一個feature來描述這個window裡面的特性,那這個東西就是一個acoustic feature。
link |
那你在這個聲音訊號上面,你會每個一個時間點,每個一小段時間就取一個window。所以一段聲音訊號就會變成一串vector sequence,這個叫做acoustic feature sequence。
link |
那在做語音辨識的第一階段,你需要做的事情就是決定每一個acoustic feature它屬於哪一個state。你要build一個classifier,這個classifier告訴我們說第一個acoustic feature它屬於state A,state A,state B,第三個屬於state A,接下來屬於state B,接下來屬於state C,等等。
link |
不過光只有做這樣子是沒有辦法做一個語音辨識系統的,這個東西只是state而已,你要把state轉成form,phoning,然後再把phoning轉成文字,然後接下來你還要考慮這個同音異字的問題,用language model考慮同音異字的問題,等等。
link |
這個就不是我們今天要講的。我想比較一下過去在用deep learning之前和deep learning之後在語音辨識上的模型有什麼不同,這個時候你就更能體會說為什麼deep learning在語音上會有非常顯著的成果。
link |
我們說我們要機器做的事情,在語音辨識裡面第一階段就是做分類這個問題,也就是決定一個acoustic feature它屬於哪一個state。
link |
傳統的方法叫做HNN-GNN,這個GNN這個方法是怎麼做的呢?這個方法是說,我們假設每一個state它就是一個stationary的,它裡面這個訊號的分布,每一個屬於某一個state的acoustic feature的分布是stationary的,所以你可以用一個model來描述它。
link |
比如說這個state,第一當作中心的這個tri-foam的第一個state,它可以用一個GNN來描述它,那另外一個state可以用另外一個GNN來描述它,這個時候給你一個feature,你就可以算說這個acoustic feature從每一個state產生出來的機率,這個東西叫做Gaussian mixture model,叫做GNN。
link |
但如果你仔細想想,你會發現這一招其實根本不太work,為什麼呢?因為這個tri-foam的數目太多了,一般語言,中文、英文都有三十幾、將近四十個foaming,我們就算三十個好了。
link |
那在tri-foam裡面,每一個foaming隨著它context的不同,你要用不同的model,所以到底有多少的tri-foam,你有三十的三次方的tri-foam,你有九千個,你有兩萬七千個tri-foam,那每一個tri-foam又有三個state,所以你有數萬個state,你每一個state都要用一個Gaussian mixture model來描述,那參數太多了,
link |
你的training data根本不夠,所以傳統上在有deep learning之前,怎麼處理這件事呢?我們說有一些state,其實它們會共用同樣的model distribution,這件事情叫做tie state,那你可能會覺得有點抽象,什麼叫做不同的state共用同樣的distribution呢?
link |
意思就是說,假如你在寫程式的時候,不同的state的名稱就好像是pointer一樣,實際上在真的寫程式的時候也就是這麼寫,state的名稱是pointer,那不同的pointer,它們可能會指向同樣的distribution,所以有一些state,它的distribution是共用的,有些沒有共用。
link |
那到底哪些要共用,哪些不要共用,就變成說你要憑著經驗,還有一些語言學的知識,來決定說哪些state它們的聲音是要共用的,可是這樣是不夠的,如果只分state的distribution要共用或不共用,這樣太粗了,所以有的人就會開始提出一些想法說,如何讓它部分共用等等。
link |
那在deep learning火紅之前,在前一個提出來比較有創新的方法叫做subspace GMA,而且它裡面有這個modularization的影子,有這個模組化的影子,在這個subspace GMA裡面呢,這個方法是說,我們原來是每一個state它就有一個distribution,在subspace GMA裡面它說,我們先把很多很多的Gaussian先找出來,我們先找一個Gaussian的pool,
link |
那每一個state它的information就是一個key,那個key告訴我們說,這個state要從這個Gaussianpool裡面挑哪些Gaussian出來,比如說,可能有某一個state1它挑第一、第三、第五個Gaussian,某一個state2它挑第一、第四、第六個Gaussian,
link |
那如果你這樣做的話,這些state它們有些時候state就可以share部分的Gaussian,那有些時候又可以完全不shareGaussian,那至於要share多少的Gaussian,這個東西呢,可以是從training data去把它學出來的,這個是在DNN火紅之前的做法。
link |
但是你如果仔細想想,剛才講的這個HNN GMA的方式,所有的home或者是state是independent model的,這件事情是不efficient的,對model人類的聲音來說,因為如果你想看人類的聲音,不同的phoning,雖然我們把它歸類為不同的因素,我們在分類的時候把它歸類為不同的class,
link |
但這些phoning之間並不是完全無關的,它們都是由人類的發音器官所generate出來的,它們中間是有根據人類發音器官發音的方式,它們是有某些關係的。
link |
舉例來說,在這個圖上畫出了人類語言裡面所有的母音,而這個母音的發音其實就只受到三件事情的影響而已,一個是你舌頭的前後的位置,一個是你舌頭上下的位置,還有一個就是你的嘴型。
link |
所以一個母音的發音其實只受到這三件事的影響而已。
link |
比如在這個圖上,你可以找到常見的英文的五個母音,R、A、E、O、U。這個R、A、E、O、U,它們之間的差別就是,當你從R到A到E的時候,你的舌頭是由下往上,那個E跟U的差別是你舌頭是放在前面或放在後面的差別。
link |
所以如果你發R、A、E、O、U的話,你的舌頭變化的方式就會像這一張圖一樣。我相信這個時候你心裡一定是在默念R、A、E、O、U,然後你會想說,怎麼感覺不太出來?
link |
這個我發現你自己念,你其實不太會感覺你的舌頭的位置在哪裡。這個你要知道說,舌頭的位置是不是真的跟這個圖上一樣。你就回去張大嘴巴對著鏡子念R、A、E、O、U,你會發現說,你舌頭的位置就跟這個圖上是一模一樣。
link |
在這個圖上,同一個位置的母音代表說舌頭的位置是一樣的,但是嘴型是不一樣的。比如說我們看左上角,在最左上角的位置有兩個母音,一個是E,一個是U。
link |
E跟U的差別,他們的舌頭位置是一樣的,只是嘴型是不一樣的。如果是E的話,嘴是比較扁的,然後U的話,嘴是比較圓的。所以你只要改變嘴型的位置,就可以從E變成U。
link |
你改變一下嘴型,它的發音就不一樣了。所以說,因為不同的phoning之間是有關係的,所以如果你說我們每一個phoning都搞一個自己的model,這件事情其實是沒有效率的。
link |
那如果今天是用deep learning是怎麼做的呢?如果是deep learning的話,那你就是去認一個deep neural network,這個deep neural network的input就是一個acoustic feature,那它的output就是這個feature屬於每一個state的機率。
link |
這是一個很單純的classification的problem,跟你作業3做在影像上是沒有什麼差別的。認一個DNN,input是一個acoustic feature,然後output就是告訴你說,這個acoustic feature屬於每一個state,它屬於state A,屬於state C,屬於state C的機率。
link |
那這邊最關鍵的一點是,所有的state都共用同一個DNN。在這整個辨識裡面,你就只有一個DNN而已,你沒有每一個state都有一個DNN。
link |
所以有人覺得說,所以有些人他沒有想清楚這個deep learning到底powerful在哪裡,他會說,從GNN變到deep learning厲害的地方就是,本來GNN你看才,通常你最多也做64個Gaussian mixture而已,那DNN有10層,每層都有一千個neuron,果然參數很多,參數變多,所以performance變好,這是一個暴力碾壓的方法,其實也沒什麼。
link |
其實DNN不是暴力碾壓的方法,你自己想想看,在做HMM、GNN的時候,你說GNN只有64個mixture,好像覺得很簡單,但是其實你是每一個state都有一個Gaussian mixture,所以真正合起來它的參數是多得不得了的。
link |
如果你仔細去算一下GNN用的參數跟DNN用的參數,我曾經在不同的test上估測過這件事情,他們用的參數你會發現,其實幾乎是差不多多的,就DNN它只用一個很大的model,GNN是用很多很小的model,但當我們把這兩個東西拿來比較的時候,其實他們用的參數量是差不多多的。
link |
但是DNN它把所有的state通通用同一個model來做分類,會是比較有效率的做法。為什麼這樣是比較有效率的做法呢?
link |
舉例來說,如果你今天把一個DNN它的某一個hidden layer拿出來,然後把那個hidden layer,比如說它其實只有一千個neuron,你沒有辦法分析它,但是你可以把那一千個layer的output降到二維。
link |
所以在這個圖上面,每一個點代表了一個acoustic feature,然後它通過DNN以後,它把這個output layer降到二維,你可以發現說它的分布是長這個樣子。
link |
在這個圖上的顏色代表什麼意思呢?這邊的顏色其實就是RAEO5,特別把這五個母音用跟這邊圖的顏色一樣的框框把它框起來。
link |
你會發現神奇的是,這邊這五個母音的分布跟這一個圖的分布其實幾乎是一樣的,你看這邊是RAEO5,這邊是RAEO5。
link |
所以你可以發現說,DNN在做的事情,它的比較lower的layer做的事情,它並不是真的要馬上去偵測說現在input這個發音它是屬於哪一個home或者是哪一個state,它做的事情是,它先觀察說當你聽到這個發音的時候,人是用什麼樣的方式在發這個聲音的,它的舌頭的位置在哪裡,它的舌頭位置是高還是低呢,它的舌頭位置是在前還是後呢等等。
link |
然後lower的layer,比較靠近input的layer,先知道了發音的方式以後,接下來的layer再根據這個結果去決定說現在的發音是屬於哪一個state或者是哪一個home。
link |
所以所有的foam會用同一組detector,也就是那些lower的layer是一個人類發音方式的detector,而所有的foam的偵測都是用同一組detector完成的,所有foam的偵測都share同一組的參數,所以它這邊就有做到模組化這件事情。
link |
當你做模組化的時候,你是用比較少的參數來,你是用比較有效率的方式來使用你的參數,所以我們回到我們很久以前就提過的universality的theory,就過去有一個理論告訴我們說,任何的continuous的function,它都可以用一層neural network來完成,只要那一層neural network夠寬的話。
link |
在90年代,這是很多人放棄做deep learning的一個原因。你想想看,只要一層hidden layer就可以完成所有的function,一層hidden layer就可以表示所有的function,那做deep learning的意義何在呢?所以很多人覺得說,deep是沒有必要的,我們就只要一個hidden layer就好。
link |
但是呢,這個理論有一件事情沒有告訴我們的是,它只告訴我們可能性,但它沒有告訴我們說,要做到這件事情有多有效率,就是沒錯,你只要有夠多的參數,你只要這個hidden layer夠寬,你就可以描述任何的function。
link |
但是這個理論沒有告訴我們的事情是,當我們用這一件事情,我們只用一個hidden layer來描述function的時候,它其實是沒有效率的。當你有multilayer,當你是有hierarchy的structure,你用這種方式來描述你的function的時候,它是比較有效率的。
link |
如果剛才模組化的概念你沒有聽得很明白的話,我們這邊舉另外一個例子。如果你是EE的background,然後你修過交換電路的話,我相信你聽了這個例子以後,就會對deep為什麼powerful不會有太多的懷疑。
link |
我想EE background的人都修過邏輯電路,其實邏輯電路可以跟neural network類比。我們知道在邏輯電路裡面,整個電路是由一堆邏輯閘,N gate、O gate所構成的。在neural network裡面,整個network是由一堆neural神經元所構成的。
link |
如果你有修過邏輯電路的話,你會知道說,其實只要兩層邏輯閘,你就可以表示任何的boolean function。如果你修過邏輯電路的話,你應該知道這件事,這件事應該不會讓你特別的驚訝。
link |
所以其實,既然兩層邏輯閘可以表示任何的boolean function,那有一個hidden layer的neural network,有一個hidden layer的neural network其實也是兩層嘛,它有一個hidden layer,一個open layer,所以它也是兩層。有一個hidden layer的neural network,它可以表示任何的continuous function,其實也不會讓人覺得特別驚訝。
link |
但是,雖然我們可以用兩層邏輯閘就描述任何的boolean function,但是實際上你在做電路設計的時候,你根本不可能會這樣做,對不對?你可以用兩層邏輯閘就做一台電腦,但是沒有人會這麼做。
link |
為什麼呢?因為當你用hierarchical的架構的時候,當你不是用兩層邏輯閘,而是用很多層的時候,這個時候你拿來設計一個電路是比較有效率的。雖然兩層邏輯閘可以做同樣的事情,但這麼做是沒有效率的。
link |
如果類比到neural network的話,其實意思是一樣的。你用一個hidden layer可以做到任何事情,但是用多個hidden layer是比較有效率的。
link |
所以,如果從邏輯閘這邊來看,你用多個邏輯閘,你可以用多層的架構,可以用比較少的邏輯閘就完成一個電路。你用比較多層的neural network,你就可以用比較少的neural就完成同樣的function,所以你會需要比較少的參數。
link |
比較少的參數意味著什麼?比較少的參數意味著你比較不容易overfitting,或者是你其實只需要比較少的data,你就可以完成你現在要train的任務。
link |
所以,這件事情有沒有跟你的認知,平常認知是相反的呢?有很多人的認知是deep learning就是很多data一年壓過去。其實不是。當我們用deep learning的時候,其實我們可以用比較少的data就達到同樣的任務。
link |
好,那我們從邏輯閘這邊再舉一個實際的例子。假設我們現在要做parity check,你要設計一個電路做parity check,那什麼是parity check呢?就是你希望input一串數字,input一串binary的數字,那如果裡面出現的1的數目是偶數的話,它的output就是1,如果出現的是奇數的話,它的output就是0。
link |
那假設你input的sequence的長度總共有digabits的話,那用兩層邏輯閘,理論可以保證你要2的低次方的gate,你要2的低次方的gate才能夠描述這樣子的一個電路。
link |
但是如果你用多層次的架構的話,你就可以用比較少的邏輯閘就做到parity check這件事情。舉例來說,你可以把好幾個Xnode gate接在一起,如果你把這個邏輯閘用這種方式接的話,現在input1跟0,我把這個Xnode gate的真值表放在右上角,input1跟0,它的output就是0,然後input0跟1,它的output就是0。
link |
input0跟0,它的output就是1,那你就做parity check這件事情了。那這邊用的就是一個hierarchical的架構,當你用這種比較多層次的架構的時候,你其實只需要這個big O of d的gates,你就可以完成你現在要做的這個任務了。
link |
所以當你用比較多層次的架構來設計電路的時候,你可以用比較少的邏輯閘就達到他們的事情。所以對neural network來說也是一樣的,你可以用比較少的neural去描述同樣的function。
link |
如果剛才舉的這個例子你沒有聽懂的話,假如你沒有修過邏輯電路,你沒有聽懂的話,以下是一個日常生活中你就會碰到的例子。這個例子是剪窗花。剪窗花大家知道嗎?剪窗花就是說,這個應該不用解釋啦,就是給你一個設置,然後把它摺起來,然後再剪一剪,然後就可以變成這個樣子,你並不是真的去把這個形狀的花樣剪出來,這樣太麻煩了,你先把紙摺起來,然後才剪。
link |
這個跟deep learning有什麼關係呢?你想想看,我們用之前講的這個例子來做比喻。假設我們現在input的點有四個,那這個紅色的點是一類,藍色的點是一類。
link |
我們之前講說,如果你沒有hidden layer的話,如果你是一個linear的model,你怎麼做都沒有辦法把藍色分在一邊,把紅色分在一邊。但是當你加了hidden layer的時候會發生什麼事呢?當你加了hidden layer的時候,你就做了一個feature的transformation。
link |
你把原來的X1,X2,你把原來的X1,X2,project到另外一個平面,轉換到另外一個平面,變成X1',X2',變成X1',X2'。所以原來的紅色的這個點跑到這裡,原來的紅色這個點跑到這裡,原來這兩個藍色的點都跑到這裡。
link |
這兩個藍色的點是重合在一起的。所以當你從這裡通過一個hidden layer變到這裡的時候,其實你就好像是把原來的這個平面對折了一樣。
link |
你把這個平面對折,所以這個藍色的點跟這個藍色的點,這兩個藍色的點重合在一起。這就好像是說我們在做剪窗花的時候,先把色紙對折一樣。你把這個平面對折,就好像是把色紙對折一樣。
link |
當你把這個色紙對折的時候,如果你在這個地方戳一個洞,到時候你把色紙展開的時候,看你折幾折,它在這些地方都會有一個洞。
link |
所以如果你把剪窗花這件事情想成是training,你把剪色紙這件事情想成是根據我們的training data,training data告訴我們說,這個有劃斜線的部分是positive,這個沒劃斜線的部分是屬於negative sample。
link |
假設我們先已經把這個平面像色紙一樣折起來的時候,這個時候training data只要告訴我們說,在這個範圍之內,在這個範圍之內,在這個範圍之內,是屬於positive的。
link |
它只要告訴我們,這個小的區間裡面的data展開以後,我們就可以做出複雜的圖樣。本來training data只告訴我們比較簡單的事情,但是因為現在有把空間對折的關係,現在要把空間做各種各樣的對折的關係,所以展開以後,你就可以有非常複雜的圖案。
link |
或者是說,你只要在這個地方戳一個洞,在其他地方也就都等於戳一個洞。所以一筆data它就可以,如果用這個例子來看的話,一筆data它就可以發揮無比data的效力。
link |
所以當你做deep learning的時候,你其實是用比較有效率的方式來使用你的data。那你可能想說,真的是這樣子嗎?我在文獻上沒有看到太好的例子,這個比較像是我的臆測,但是我做了一個toy example來展示這件事情。
link |
這個toy example是這樣子的,我們有一個function,它的input是二維R2,它的output是0跟1,這個function是一個地毯形狀的function。
link |
在這個紅色的菱形的範圍內,它的input這個R2就是座標,那紅色的這個菱形的範圍內,它的output就要是1,藍色的菱形範圍內,它的output就要是0。
link |
那現在我們來考慮,如果我們用了不同的training的example,不同量的training example,在一個hidden layer跟三個hidden layer的時候,我們看到什麼樣的情形。
link |
我們有特別調整一個hidden layer和三個hidden layer的參數,所以並不是說當有三個hidden layer的時候,它的參數是比一個hidden layer多的。所以一個hidden layer的neural network它是一個很胖的neural network,三個hidden layer的neural network它是一個很瘦的neural network,所以它們的參數是調整到接近的。
link |
所以你要注意一下,當你在比一個shallow的neural network跟比較deep的neural network的時候,一個公平的評比應該要讓它們有一樣的參數量。
link |
那現在如果你給它看這邊是十萬筆data的話,這兩個neural network都可以認出這樣子的training data。就你從這個function裡面sample十萬筆data,然後給它去學,然後它學出來長的就是這樣。
link |
那對一個hidden layer來說,反正它可以模擬任何function,等它厚寬就可以模擬任何function,所以像這種菱形的function,這種地毯的function應該也不是什麼問題。
link |
那現在如果我們減少參數的量,減少到只用兩萬筆,就我們只從這裡sample出兩萬筆來做training,這個時候你會發現說,如果只有一個hidden layer的時候,你的結果就崩掉了。
link |
比較多的時候還要差。但是你會發現說,如果你用三個hidden layer的時候,它的崩壞是有次序的崩壞。你看這個結果,它這個結果就像是你今天要剪窗花的時候,你把色紙摺起來,最後剪壞了,然後展開以後,長成這個樣子。
link |
而且你會發現說,在比較少的training data的時候,你有比較多的hidden layer,最後得到的結果其實是比較好的。
link |
當我們用deep learning的時候,另外一個好處是我們可以做end-to-end learning,所謂的end-to-end learning的意思是這樣,有時候我們要處理的問題非常的複雜,比如說語音辨識就是一個非常複雜的問題。
link |
那我們說我們要解一個machine learning的problem的時候,我們要做的事情就是先找一個hypothesis的function set,也就是找一個model。當你要處理的問題是很複雜的時候,你這個model裡面,它會需要是一個生產線。
link |
你這個model裡面,它表示一個很複雜的function,這個很複雜的function是有很多比較簡單的function串接在一起。比如說你要做語音辨識的話,先把聲音訊號送進來,再通過很多的function一層一層的轉換,最後變成文字。
link |
當你做end-to-end learning的時候,意思就是說你只給你的modelinput跟output,你不告訴它說中間每一個function要怎麼分工,你就只給它input跟output,然後讓它自己去學,讓它去學會說中間每一個function,每一個生產線的每一個點,每一站它應該要做什麼事情。
link |
這件事情,如果你在deep learning裡面要做這件事情的時候,你就是疊一個很深的neural network,那每一層就是生產線上的一個點,每一層就是一個simple的function,那每一層會自己學到說它應該要做什麼樣的事情。
link |
比如說在語音辨識裡面,在還沒有用deep learning的時候,在還是shallow learning的時代,我們怎麼做語音辨識呢?我們可能是這樣做的,你先有一段聲音訊號,然後要怎麼把聲音訊號對應成文字呢?
link |
你要先做DFT,你不知道這個是什麼也沒有關係,反正就是一個function,就是生產線上的某一個站,然後它變成spectrogram。那這個spectrogram通過builder bank,你不知道builder bank是什麼關係,就是生產線上另外一站,再得到output,然後再取log。
link |
取log我想大家應該都知道了,但是它的原理其實是,這個取log其實是非常有道理的,不過我們這邊就不講就是了。然後再做DCT,然後最後得到NFCC,然後再把NFCC丟到GNN裡面,然後最後你可以得到語音辨識的結果。
link |
當然這個GNN其實你把它換成DNN,也是會有非常顯著的improvement。那在這整個生產線上面,只有最後一個block,只有最後這個GNN這個部分,藍色這個block,是由training data學出來的。
link |
那前面這個綠色的部分,這些都是人手訂的,都是過去有古聖先賢,他們研究了各種人類生理的知識以後,訂出了這些function。
link |
它非常非常的強,就是減一分而太肥,增一分而太瘦。你就不要想在這個上面再去改什麼東西,改得都會比較差。就這樣子卡了大概二十年,感覺古聖先賢實在太厲害了。
link |
但是後來有了deep learning以後,我們可以把這些東西取代成用neural network把它取代掉。就是說你可以把你的deep neural network多加幾層,然後你就把DCT拿掉。
link |
那這件事情現在已經是typical的做法了。過去NFCC這種feature,如果你上語音課的話,你很有可能知道NFCC是什麼。過去可能二十年,這個feature是dominate語音辨識這件事情。
link |
但是現在已經不再是這樣子了。你可以直接從log的output開始做,甚至比較多人從log的output開始做。你把你的neural network疊深一點,直接從log的output開始做,你會得到比較好的結果的。
link |
我記得在2014年的語音會議上的時候,NSR的語音research team的鄧力有說bye byeNFCC,大家也沒有什麼特別的意見。
link |
現在甚至你可以從spectrogram開始做,你把這些都拿掉,通通都拿deep neural network來取代掉,也可以得到更好的結果。那deep neural network學到它要做的事情,你會發現,如果你分析deep neural network的weight的話,它可以自動學到要做filter bank這件事情。
link |
filter bank是模擬人類的聽覺器官所制定出來的filter,但是deep learning可以自動學到這件事情。接下來有人就會想要挑戰說,我們能不能夠疊一個很深很深的neural network?
link |
我們能不能夠疊一個很深很深的neural network,直接input開domain上的聲音訊號,然後output直接就是文字,然後中間完全不要做filter transform之類的。如果連filter transform都不用做的話,那你就不需要學訊號與系統。
link |
但是還好這件事情後來結局是這個樣子的。這件事情的結局是這樣,有好多好多人前仆後繼地在做這件事情,甚至曾經一度在conference裡面有兩個session都是在做這件事情。
link |
最後Google有一篇paper是這樣的,它最後的結果是,它拼死去認了一個很大的neural network,input就是聲音訊號,完全不做任何其他的事情,input就是row的waveform,它最後可以做到跟有做filter transform的結果打平,但是也僅止於打平而已。
link |
我目前還沒有看到有一個結果是可以input聲音訊號,就input開domain的聲音訊號,不做filter transform,然後結果比filter transform好。所以可見filter transform很強,或許它已經是訊號處理的極限了。
link |
就算是machine learning認出來的結果,其實也就是filter transform。如果你觀察Google的paper,它其實會分析一下machine做的事情,它做的事情就很像是在做filter transform。但是做出來也就跟filter transform一樣好了,也沒有辦法比filter transform做得更好。所以說訊號系統還是必要的。
link |
那如果是,剛才講的都是語音的例子,影像的話其實也是差不多啦,那這個我想大家應該都知道知道,所以我們就稍微跳過去。
link |
過去影像也是疊很多很多的block,有很多很多人定的handcrafted feature,那你只在,你用很多很多的block,很多很多handcrafted feature去處理你input的影像,然後只有在最後一層用一個比較簡單的shallow classifier。
link |
但是現在你就直接兜一個很深的network,然後input就直接是pixel,然後output就是裡面影像是什麼,你就不需要抽feature了。
link |
那deep learning還有什麼好處呢?有時候我們會做,通常我們真正在意的task,它是非常的複雜的。那在這種非常的複雜的task裡面,有時候非常像的input,它會有很不一樣的output。
link |
舉例來說,你在做影像辨識的時候,白色的狗跟北極熊其實看起來是很像的,但是你的machine要知道說要output狗,看到這個要output狗,看到這個要output北極熊。
link |
那有時候不一樣的東西,有時候看起來很不一樣的東西,其實是一樣的,比如說這個是火車,正面看是這個樣子,橫看城嶺側城峰,橫著看就變成這樣子。
link |
所以它們是不一樣的,但output都要是火車。如果你今天的network只有一層的話,你只能做簡單的transport,你沒有辦法把一樣的東西變成很不一樣,你沒有辦法把不一樣的東西變得很像。你要讓原來input很像的東西,在結果看起來很不像,你需要做很多層次的轉換。
link |
舉例來說,如果我們看下面這個例子,這個是語音的例子。在這個圖上,這邊做的事情是把NFCC投影到二維的平面上。
link |
而不同的顏色代表的是不同的人說的話。紅色代表是某個人說的句子,綠色代表是某個人說的句子,藍色代表是某個人說的句子。
link |
要注意一下,這些人說的句子是一樣的。在語音上,你會發現說同樣的句子,不同的人說,它的聲音訊號看起來是非常不一樣的。
link |
你會發現說,紅色看起來跟藍色間沒什麼關係,藍色看起來跟綠色間沒有什麼關係。所以有人看到這個圖就覺得語音辨識不能做,不同的人說話的聲音太不一樣了。
link |
有人看到說同樣的句子,感覺太不一樣了,不能做。如果你今天認一個Neural Network,如果你只看第一層的Hidden Layer Output,你會發現說不同的人講的話,講的同一個句子,還是看起來很不一樣。
link |
但是如果你今天看第八個Hidden Layer Output的時候,你會發現說不同的人說的同樣的句子,它自動的被Align在一起了。也就是說這個DNN在很多個Layer的轉換的時候,它把本來看起來很不像的東西,它知道說它們應該是一樣的。
link |
經過很多個Layer的轉換以後,就把它們兜在一起,就把它們Map在一起了。比如說你看這個圖上面,這邊你會看到一條一條線,那在這一條線裡面,你會看到不同顏色的聲音訊號。
link |
也就是說不同的人說同樣的話,經過八個Hidden Layer的轉換以後,對於Neural Network來說,它就變得很像。本來在Input的時候完全不像,但通過很多個Layer的轉換以後,它就變得像。
link |
或者是如果你今天這個是語音的例子,如果我們看MNIST手寫數字辨識的例子,你自己也可以輕易的做到這些實驗。Input的Feature是長這個樣子。Input就是28x28的Pixel。如果你把28x28的Pixel,28x28的這個Vector,Project到二維的平面的話,那看起來像是這個樣子。
link |
你會發現說在這個圖上,你看這邊,4跟9幾乎是疊在一起的。4跟9很像,我們仔細想想看。4跟9都是一個圈圈,然後再加一條線,4跟9很像。
link |
所以如果你光看Input的Pixel的話,4跟9幾乎是疊在一起的,你幾乎沒有辦法把它分開。但是我們如果看第一個Hidden Layer的Output,這個時候你會發現說4跟9還是很像,它們還是離得很近。7也跟4很像,4、7、9它們是很像的。
link |
這是第一個Hidden Layer的Output。但是如果我們看第二個Hidden Layer的Output,你會發現說4、7、9是逐漸被分開的。到第三個Hidden Layer的Output,它們又被分得更開。
link |
所以如果你今天要讓不一樣的Input被Merge在一起,像剛才語音局的例子,或者是讓原來看起來很像的Input最後被分得很開,那你就需要好多Hidden Layer才能辦到這件事情。
link |
我們要更多用Deep Learning的理由了。有人寫了一篇Paper,Microsoft Researcher Rich Corona寫了一篇Paper,它的Title是Deepness Really Need to be Deep。如果翻譯成中文,就可以翻譯成深度學習是不是過慾了。
link |
這篇Paper有點舊,大概是兩年前Publish的。這篇Paper看起來那個時候覺得很神奇,但是現在已經是common sense了。
link |
它的做法是這樣,它說我們現在來比較一下一層的Hidden Layer跟三層的Hidden Layer,它們在Amnesty和Timmy這些Benchmark focus上的差別。當然結果並不意外,其實就算你調,當你把一個Hidden Layer跟三個Hidden Layer調到一樣參數的時候,當然是三個Hidden Layer performance是比較好的,其實你也可以自己verify這件事情。
link |
如果你有真的有在做Deep Learning的話,這個是common sense。接下來它發現說,一個Hidden Layer參數怎麼增加,performance都不好,它很快就saturate了。
link |
它就想說怎麼會這樣呢?它就做了一件當時看起來很匪夷所思的事,它說一個Hidden Layer的Neural Network,你Learning的target不要用真正的Label。
link |
就是我們本來Learning的時候你要用真正的Label,你就看這個image人告訴你說是1,人告訴你說是0,你的Neural Network就是用這個train的嘛,這是很合理的想法。它說你現在的Neural Network不要用那個Label,你用三層Hidden Layer的output當作你的teacher。
link |
你把所有的image都丟到一個認好的三層的Hidden Layer,然後得到那些output。有一些output是錯的,錯的就管它就是錯的。然後一層的Hidden Layer就去學三層Hidden Layer幫你Label的結果,就算錯了它就學一個錯的。
link |
它的performance會比較好,可以逼近三層的Hidden Layer,甚至幾乎跟三層的Hidden Layer一樣好。照理說你只要一個Hidden Layer你就可以做到任何事,所以沒有理由三層可以得到這個performance,一層得不到這個performance。
link |
但是你直接認一個一層的Neural Network,你就是認不出那個結果。你要去讓一層的Neural Network模擬三層的Neural Network的行為,它才能夠認出這個結果。有人讀了那篇paper覺得說Rich的結論是deep learning不work,其實他的結論不是deep learning不work。
link |
我在conference遇過他本人,我問過他說,你的意思是deep learning不work?他說,不是,我的意思是deep learning是work的。就是你直接認一層的Neural Network是認不起來的,你要先認三層的Neural Network,再用一層的Neural Network去模擬三層的Neural Network的行為,你才認得起來。
link |
這個是我在ASIU2015的時候聽過他的keynote speech,這是他的第一頁投影片。Do deep learning really need to be deep?然後第二頁,yes,然後我們留下很多時間給大家問問題,結束。
link |
然後如果你想要學更多的話,你可以看一下Benjo的deep learning的theoretical motivation,他講了很多非常發人深省的想法。現在deep learning很紅了,所以有更多來自其他領域的解讀,比如說從物理的角度來解釋為什麼要做deep learning,從化學的角度來解釋為什麼要做deep learning,我把連結留在這邊給大家參考。
link |
講到這邊剛好告一個段落,我們就休息十分鐘,等一下再繼續講。