back to index
ML Lecture 13: Unsupervised Learning - Linear Methods
link |
我把Dimension Reduction分成兩種,一種做的事情叫做化繁為簡,它可以分成兩大類,一種是做Clustering,一種是做Dimension Reduction。
link |
所謂的化繁為簡的意思是說,你現在有很多種不同的input,比如說你現在找一個function,然後它可以input看起來像樹的東西,output都是這個抽象的樹,也就把本來比較複雜的input變成比較簡單的output。
link |
那在做Unsupervised Learning的時候,你通常只會有function的其中一邊,比如說我們要找一個function,它可以把所有的樹都變成抽象的樹,但是你所擁有的training data就只有一大堆的image,一大堆的各種不同的image,你不知道說它的output應該要是長什麼樣子。
link |
那另外一個Unsupervised Learning可以做的事情是Generation,也就是無中生有。
link |
它做的事情是這樣,我們要找一個function,這個function你隨機給它一個input,比如說給它一個random number,要輸入一個數字1,然後它就output這一棵樹,輸入數字2就output另外一棵樹,輸入數字3就output另外一棵。你輸入給它一個random number,它就自動的畫一張圖出來,輸入不同的number給它,它畫出來的圖就不一樣。
link |
那在這個task裡面,我們要找的這個可以畫圖的function,你只有這個function的output,但是你沒有這個function的input,你就只有一大堆的image,但是你不知道輸入什麼樣的code才可以得到這些image。
link |
那在這份投影片,我們先focus在dimension reduction這件事情上,而且我們只focus在linear的dimension reduction。那我們先來說一下clustering,什麼是clustering呢?
link |
clustering就是說,這個太直覺了,其實也沒什麼好直覺的,這個地方比較沒有什麼特別好講,就是有一大堆的image,假設我們現在要做image clustering,就有一大堆image,然後你就把它們分成一類一類一類的。
link |
那之後你就可以說,這邊所有的image都屬於class1,這邊都屬於class2,這邊都屬於class3,就給它們貼標籤的意思。那這樣你就把本來有些不同的image,但是都用同一個case來表示,就可以做到化繁為簡這件事情。
link |
那這邊最critical的問題就是,到底應該要有幾個case?那這個東西沒有什麼好的方法,這個就跟neural network要集成一樣,是empirical的去決定你需要幾個case。
link |
那當然不能太多,比如說你多到說,這邊有九張image,也就是九個case,那你乾脆就不要做case就好了,每張image都是幾個case,那這樣有做跟沒有做意思是一樣的。
link |
或者是你說,我全部的image都class成,我只有一個card,全部image都放在同一個class裡面,那也是有做跟沒有做一樣。但是要怎麼選擇適當的class,這個你就要empirical的來決定它。
link |
那在classing的方法裡面,最常用的叫做k-means,然後很快的講一下k-means怎麼做的。k-means就是這樣,我們有一大堆的data,它們都是unlabeled,有一大堆的data,x1一直到xn,那這邊每一個x可能就代表一張image,那我們要把它做成大k的class。
link |
怎麼做呢?我們要先找這些class的center,那假如這邊每一個object都是用一個vector來表示的話,這邊的這些center也是一樣長度的vector。
link |
那我們每一個class都要先找一個center,那有大k的class,我們就需要c1到c,大k的center。那這些center,這個初始的center怎麼來呢?你可以從你的training data裡面,就隨機的找大k的object出來,就是你的k的center。
link |
接下來,你要對所有在training data裡面的x,都做以下的事情,都做什麼事情呢?你決定說現在的每一個object,屬於1到大k的哪一個class。
link |
那假設現在你的object xn,跟某一個class的center,第一個class的center最接近的話,那xn就屬於ci。
link |
那我們用一個binary的value,b上標n下標i,來代表說n這個object,第二個object有沒有屬於第i個class。如果第二個object屬於第i個class的話,那這個binary的value就是1,反之就是0。
link |
接下來,你要update你的class,怎麼update你的class呢?這個方法也是很直覺,你就把所有屬於,假設你要update第二個class的center,你就把所有屬於第二個class的object,通通拿出來,做平均,你就得到第二個class的center,然後你要反覆的做。
link |
那這邊之所以你在做initialization的時候,你會想要直接從你的database裡面去挑k個example,挑k個object出來做center的,有一個很重要的原因是,假設你是純粹隨機的,你不是從dataphone裡面去挑的,
link |
你很有可能在第一次assign這個object的時候,就沒有任何example跟某一個class很像,你就有可能是有某一個class,他沒有任何example,你現在update的時候,你程式就會segmentation full,所以你最好就是從你的training data裡面,選k個example出來當做initialization。
link |
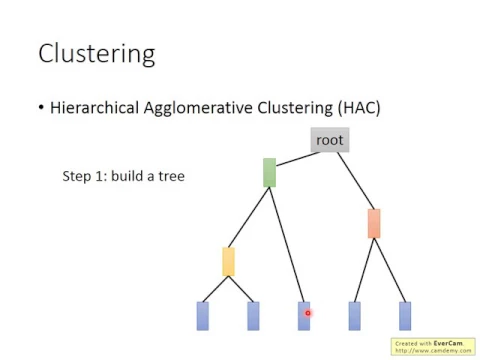
好,那classing有另外一個方法叫做hierarchical or relative classing,那這個方法是先建一個tree,假設你現在有五個example,你想要把它做classer,先做一個tree structure,怎麼建這個tree structure呢?
link |
你把這五個example量量量量去算它的相似度,然後挑最相似的那個pair出來,假設現在最相似的pair是第一個和第二個example,你就把第一個example和第二個examplemerge起來,比如說把它們平均起來,得到一個新的vector,這個vector同時代表第一個和第二個example。
link |
接下來你再算說,現在變成有四個example了,現在剩下只剩四筆data了,把這四筆data再量量去算它的相似度,然後發現說第三筆和第四筆,最後這兩筆是最相似的,那你再把它們merge起來,把它們平均起來,得到另外一筆data。
link |
現在只剩三筆data,再去量量算它的singularity,發現說黃色這一個和中間這個最像,你就再把它們平均起來,最後只剩紅色跟綠色,那就只好把它平均起來,就得到這個tree的root。
link |
你就根據這五筆data,它們之間的相似度,就建立出一個tree structure。接下來你要決定一個,像你沒有做class的人,只是建了一個tree structure,所以這個tree structure可以告訴我們說哪些example是比較像的,就是比較早分枝代表比較不像。
link |
比如說這三個跟這兩個,一開始在root的地方就分成兩類,所以它們這三個和這兩個就比較不像。接下來你要做class,你要決定在這個樹上,在這個tree structure上面切一刀,比如說你決定切在這邊。
link |
如果你切在這個地方的時候,你就把你的五筆data變成三個class,根據這一刀,這兩個example是一個class,它自己一個class,這兩個example是一個class。
link |
如果你這一刀切在這個地方,那你就變成這三筆是一個class,這三筆是一個class,這兩個一個class。如果你這一刀切在這邊,那你就變成分成總共四個class。這個是HAC的做法。
link |
HAC跟剛才講的K-means,我覺得最大的差別就是你如何決定一個class的數目。在K-means裡面,你要決定大K的value是多少,有時候你覺得說到底有多少class不容易想,你可以換成HAC。
link |
好處就是,你現在不直接決定幾個class,而是決定你要在樹上切,切在這個樹的structure的哪裡。有的人會覺得說,有時候你會覺得這樣子是比較容易的話,那HAC對你來說就有一些benefit。
link |
但是光只做class是非常卡的。在做class的時候,我們就是以偏概全,因為每一個object都必須要屬於某一個class。這個就好像是說,我們知道念能力有分成六大類,然後每一個人都會被assign成六個念能力裡面的其中一類。
link |
那你要怎麼決定它是哪一類呢?你就做水箭式,你就是拿一杯水,然後看看它會有什麼反應,然後就把它assign成某一類。比如說水滿出來了,就是強化系,所以小傑就是屬於強化系。
link |
那我們知道說,這樣子把每一個人都assign成念能力裡面的某一個系是不夠的,是太過粗糙不斷的。比如說像比斯基就有說,小傑其實是接近放出系的強化系念能力者。
link |
所以小傑,如果你只是說他是強化系的,其實是lost掉很多information。你應該這樣來表示小傑,你應該說他強化系是0.7,放出系是0.25。其實強化系跟變化系是比較接近的,所以有強化系其實你也會有一部分變化系的能力,所以也是0.05。
link |
像小傑可以用剪刀,那個是變化系的能力,然後其他系的能力是0。如果你只是把你手上所有的object分別assign到它屬於哪一個class,這樣是以偏概全量太粗了,你應該要用一個vector來表示你的object。
link |
這個vector裡面的每一個dimension就代表了某一種特質,某一種attribute。這件事情就叫做distributed representation。如果你原來的object是一個非常high dimension的東西,比如說image,你現在把它用它的attribute,把它用它的特質來描述,它就會從比較高微的空間變成比較低微的空間。
link |
這件事情就叫做dimension reduction。它們其實是一樣的事情,只是有不同的稱呼而已。
link |
我們從另外一個角度來看一下為什麼dimension reduction可能是有用的。舉例來說,假設你的data的分布是長這個樣子,在3D的空間裡面,你現在的data的分布是長這個螺旋的樣子。但是用3D的空間來描述這些data其實是很浪費的。
link |
你從直覺上就會知道說,其實你可以把這個類似地毯捲起來的東西把它攤開,把它攤平,就變成這樣。所以你其實只需要在2D的空間就可以描述這個3D的information。你根本不需要把這個問題放到3D來解。
link |
你要是把問題複雜化,你其實在2D就可以做這個test。或者是我們舉一個比較具體的例子,比如說我們考慮at least。在at least裡面,每一個input的1 digit,它是一個image,它都用28x28的dimension來描述它。
link |
但是實際上,多數28x28的dimension的vector,你把它轉成一個image,看起來都不像是一個數字。你random sample一個28x28的vector,轉成image,看起來可能是這樣,它其實根本就不像數字。
link |
所以在這個28x28的空間裡面,4digit的vector其實是很少的。所以其實你要描述一個digit,或許你根本不需要用到28x28。你要描述一個digit,你要用的dimension可能是遠比28x28少。
link |
所以如果我們舉一個很極端的例子,比如說這邊有一堆3,然後這堆3,如果你是從pixel來看待它的話,你要用28x28來描述每一張image。然而實際上,這些3只需要用一個維度就可以來表示了。
link |
為什麼呢?因為這些3其實就只是說,把原來的3放正,是中間這張image,右轉10度就變成它,轉20度就變成它,左轉10度就變成它,左轉20度就變成它。
link |
所以你唯一需要記錄的事情只有,今天這張image,它是左轉多少度,右轉多少度。你就可以知道說,它在28維的空間裡面,應該長什麼樣子。你只需要抓住這個重點,你只要抓住這個角度的變化,你就可以知道28維空間中的變化。
link |
所以你只需要用1維就可以描述這些image。所以這就像我剛才舉的例子,這個是繁腰的鬍子,這個就是它的頭。
link |
那怎麼做dimension reduction呢?在做dimension reduction的時候,我們要做的事情就是找一個function。這個function的input是一個vector x,它的output是另外一個vector z。但是因為是dimension reduction,所以你output的vector z,它的dimension要比input的x還要小,這樣你才是做dimension reduction。
link |
在做dimension reduction裡面,最簡單的方法是feature selection。這個方法就沒有什麼好講的,這個方法是這樣,就是現在如果你把你的data的分布拿出來看一下,本來是在2維的平面上,但是其實你發現都集中在x2這個dimension而已。
link |
所以x1這個dimension沒什麼用,把它拿掉,就只有x2這個dimension,你就等於是做到dimension reduction這件事了。那這個方法不見得總是有用,因為有很多時候是,你的case是,你任何一個dimension其實都不能拿掉。
link |
那另外一個方法,另外一個常見的方法叫做principle component analysis,叫做PCA。這個PCA怎麼做呢?這個PCA做的事情是這樣,它說這個function是一個很簡單的linear function。
link |
這個input x跟這個output z之間的關係,就是一個linear transform,也就是你把這個x乘上一個matrix w,你就得到它的output z。
link |
那現在要做的事情就是,根據一大堆的x,我們現在不知道z長什麼樣子,我們只有一大堆的x,根據一大堆的x,我們要把這個w找出來。那如果你要知道比較細節的東西的話,你可以看一下Bsharp的第12章。
link |
接下來我們來介紹一下PCA。我剛才講過,PCA要做的事情就是找這個w。那這個w怎麼找呢?假設我們現在考慮一個比較簡單的case,我們考慮一個one-dimensional的case。
link |
什麼意思呢?我們現在假設,我們只要把我們的dataproject到一維的空間上,也就是我們的z呢,它只是一個一維的vector,所謂一維的vector其實就是一個scalar,我們的z是一個scalar。
link |
或者是說,我們可以這樣寫,如果我們z這邊只是一個scalar的話,那我們w呢,其實就是一個row,對不對,只有一個row而已。那我們就用w1呢,來表示w的第一個row。
link |
那我們把x跟w的第一個row,w1做inner product,我們就得到一個scalar,z1。接下來我們要問的問題是,我們要找的這個w1,應該要長什麼樣子?
link |
首先呢,我們先假設這個w1的長度是1,w1的q0是1,這個假設是有必要的,等一下你會看得更清楚為什麼我們一定要有這個假設。
link |
如果w1的q0是1的話,那w1跟x做inner product,得到的z1意味著什麼呢?它意味著說,我們現在呢,w跟x是高維空間中的一個點,w1是高維空間中的一個vector。
link |
那所謂的z1就是x呢,在w1上面的投影,它這個投影的這個值呢,就是w1跟x的inner product,這個就沒有什麼問題,這個就是打印線代裡面教過的東西。
link |
好,那所以我們現在做的事情就是,把一堆x又透過w1把它投影變成z1,我們就得到一堆z1,每一個x都變成一個z1。
link |
那現在的問題就是,這個w1應該長什麼樣子呢?我們該選哪一個w1呢?舉例來說,假設這個是x的分布,這個x的分布是什麼呢?
link |
它是橫坐標,這個每一個點呢,代表了一隻寶可夢,它的橫坐標是攻擊力,它的縱坐標呢,是防禦力。
link |
那今天如果我要選,我要把這個二維投影到一維,我應該要選什麼樣的w1呢?我可以選這樣的w1,我可以選w1指向這個方向,我也可以選w1指向這個方向。
link |
我選不同的方向,我最後得到的結果,得到的projection的結果,它會是不一樣的。
link |
那我們會想要呢,那你總是要給我們一個目標,我們才知道要選什麼樣的w1啦。
link |
那現在的目標是這樣,我們希望呢,選一個w1,它經過projection以後得到的這些z1的分布呢,是越大越好。也就是說,我們不希望說,透過這個projection以後,所有的點呢,通通擠在一起。
link |
就變成把本來這個datapoint和datapoint之間的歧異度呢,拿掉。我們是希望說,經過這個projection以後,不同的datapoint它們之間的區別,我們仍然是可以看得出來。
link |
所以我們希望找一個projection的方向,它可以讓projection後的variance呢,越大越好。
link |
那如果我們看這個例子的話,你就會覺得說,如果是選這個方向的話,經過projection以後你的點呢,可能是分布在這個地方,大概分布在這個range。
link |
那如果是projection在這個方向的話,那你點的分布可能是這個range。
link |
所以如果projection在這個方向上的話,你會有比較大的variance,那在這個方向上的話,你會有一個比較小的variance。所以你要選w1的時候,你可能w1的方向呢,會指向這個方向。
link |
那其實這個w1代表什麼意思呢?如果你從這個圖上就可以看到說,這個w1其實是代表了這個寶可夢的強度啦。
link |
因為寶可夢有一個,可能有一個隱藏的factor就代表它的強度,那這個隱藏的factor同時影響了它的這個防禦力跟攻擊力。
link |
所以防禦力跟攻擊力呢,是會同時上升的。
link |
那如果我們要用equation來表示它的話,你就會說,我們現在要去maximize的對象是z1的variance。
link |
z1的variance就是summation over所有的z1,然後z1-z1 bar的比方,而z1 bar就是所有z1的平均啦,就是所有z1的平均。
link |
好,那這樣子,假設你,我們先等一下再講怎麼做,我們等一下再講怎麼做。
link |
假設你知道怎麼做,你解一解,你找到一個w1,你就可以讓z1最大,那你就找到這個w1的結束了。
link |
好,再來呢,但是你可能不要只投影到一維,你想要投影到更多維,比如說你想要投影到一個二維的平面。
link |
所以,那如果你想要投影到二維的平面的時候,這個時候你就把x跟另外一個w2呢,做inner product,得到z2。
link |
這個z1跟z2串起來就得到這邊的z,這個w1跟w2的transpose排起來就是w的第一個row跟第二個row。
link |
好,那這個z2,我們要怎麼找這個w2呢?跟剛才找z1一樣,我們希望首先w2它的tunon是1,然後接下來的這個z2,它的分布呢,也是越大越好。
link |
但是,如果你只是要讓z2的variance越大越好,也讓這個式子越大越好,那你找出來不就是w1嗎?w1剛才已經找過了,對不對?
link |
所以,你就等於什麼事都沒有做。所以,你要再加一個constraint,這個constraint是,我們剛才已經找過w1了,這個w2呢,要跟w1是垂直的。
link |
或者是,w1跟w2呢,是osobel的w1跟w2,它們做inner product呢,等於0。
link |
好,藉由這個方法呢,你就可以先找w1,再找w2,再找w3,就看你要project到幾維。
link |
然後project到幾維,是你要自己決定的,這個就跟那種要幾個cluster,要幾個healer那樣,也是自己決定的。
link |
那你要project到大K維,那你就找w1、w2到w大K,那就把你所有找出來的w1、w2到w大K排起來,當作大W的row放在這邊,就結束了。
link |
那這邊有一件事情,就是這個找出來的大W啊,它會是一個osobel的matrix,為什麼呢?如果你看它的row的話,它的w1跟w2是osobel的,然後w1的2none跟w12的2none都是1。
link |
所以它的row是none是1,而且互相之間是osobel的,所以它是一個osobel的matrix。接下來的問題就是,怎麼找w1跟w2呢?怎麼解這個問題呢?
link |
這邊其實有一個解法,其實是蠻容易的,怎麼解呢?你其實要用Lagrange multiplier,這邊有個warning of map,如果你沒有聽懂的話,就算了。
link |
這個都直接call套件,這個其實call套件就有了,而且就算是你不會下面這一套東西的話,你其實可以用gradient descent的方法,這個我們之後會講。你可以把PCA這件事情描述成一個neural network,然後就用gradient descent的方法來解它。
link |
所以不一定要用Lagrange multiplier來做這個PCA。這個PCA可以把它看成像是一個neural network一樣,但我們先來很快的講一下Lagrange multiplier這個方法。
link |
這是個很經典的方法,它是怎麼做的呢?我們說z1等於w1跟x的inner product,那z1的平均值是summation over all的z1,也就是summation over all的w1跟x的inner product。
link |
這邊是summation over all的data point跟w1無關,所以可以把w1踢出來,變成先summation over all的x再跟w1做inner product,得到w1跟x的平均的inner product。
link |
接下來,我們說我們要maximize的對象是z1的variance,那z1的variance我們可以寫成z1減它的平均值的平方再summation over all的z1。
link |
我們先把這一項整理一下,這一項整理一下變成什麼樣子呢?z1是w1跟x的inner product,z1 bar是w1跟x bar的inner product,然後再取平方。
link |
那都有w1,所以可以把w1踢出來,變成summation over w1乘以x減x bar的inner product的平方。
link |
那這個平方,你可以把它做一下轉化,怎麼轉化呢?w1是一個vector,x減x bar是另外一個vector,兩個vector,比如說w1就是a,x減x bar就是b。
link |
a跟b的inner product的平方可以寫成a的transpose乘以b的平方,可以寫成a的transpose乘以b,再乘上a的transpose乘以b。
link |
然後這一項其實可以寫成a的transpose乘以b,然後乘上a的transpose乘以b,然後再transpose。
link |
為什麼這邊可以直接加一個transpose呢?因為a transpose b是一個scalar,所以再transpose還是它自己。好,那transpose以後,a transpose b的transpose就是把它們順序對調再加上transpose,所以變成a transpose b,b transpose a。
link |
然後把這個,把a帶回w1,b帶回x減x bar,你就得到這樣一個式子,w1的transpose乘上x減x bar,x減x bar的transpose再乘上w1。
link |
接下來呢,你這邊是summation over所有的data,所以跟w無關,所以把w1的transpose拿出去,注意一下這邊summation是summation over這個x減x bar乘以x減x bar的transpose而已,w1被拿出去了。
link |
那x減x bar的transpose,x減x bar乘以x減x bar的transpose,summation over所有的data point是什麼呢?它是這個x的covariance,對不對,它是x的covariance matrix。
link |
所以這一項其實就是w1的transpose乘以x的covariance matrix乘上w1,我們用x來描述x的covariance matrix。
link |
所以現在呢,我們要解的問題是這樣,找一個w1,它可以maximize w1的transpose,乘上一個matrix x,再乘上w1。
link |
但這個optimization對象是有constraint,如果沒有constraint的話,這個問題它會有無聊的solution,你就把w1變它每一值都是無窮大,就結束了這樣子。
link |
所以你要有constraint,它的constraint是說,這個w1的tuner要等於1。
link |
好,那有了這些以後呢,我們就要解這個optimization的方法了。
link |
那這邊這個x啊,x是covariance matrix,x的covariance matrix,它是symmetric的。
link |
而且因為它是covariance matrix的關係,它又是半正定,它是positive semi-demonic,也就是說它所有的eigenvalue都是nonactive的。
link |
如果你對這件事有困惑的話,你就回去翻一下現代課本,你其實可以在我的個人網頁上找到現代的教學,就在這個machine learning的網頁下面。
link |
好,那我們就先講結論,假設你不想聽中間的過程的話,結論就是,這個programming的problem,它的solution就是,w1是covariance matrix的eigenvector。
link |
它不只是一個eigenvector,它是對應到最大的eigenvalue,λ1的那一個eigenvector,這個就是結論。
link |
那中間的過程是怎麼樣呢?中間的過程是,首先我們要用Lagrange multiplier,如果你對這個東西有困惑的話,這不是我們這堂課應該講的,你就看一下Psharp的appendix。
link |
好,在做Lagrange multiplier的時候,你就列一個式子,這個式子長這樣,它是先把這一項拿到這邊,再減掉α,乘上這個constraint。
link |
然後接下來呢,你把這個g,對所有的w做偏為分,w裡面有,w是一個vector嘛,對不對,w是一個vector,它裡面有很多個element。
link |
所以你把這個function,對w的第一個element做偏為分,對第二個element做偏為分,然後令這些式子通通等於0。
link |
然後整理一下以後呢,你會得到一個式子,這個式子是這樣告訴我們的,這個式子告訴我們說,這邊的這個solution,它會滿足下面這個式子。
link |
s乘上w1-α乘上w1等於0,再整理一下,變成這樣。如果你寫成這樣,s乘上w1等於α乘上w1的話,那w1就是一個eigenvector,w1就是s的eigenvector。
link |
因為w1乘上s等於s,等於自己乘上我們的scalar,所以w1是s的eigenvector。
link |
好,那,但是現在s的eigenvector有一大把,有很多,而且你可以找到一大把eigenvector,它的norm都是1。
link |
所以接下來你要做的事情是,看哪一個eigenvector帶到這個式子裡面,可以maximize這個w1的transpose乘上s乘上w1。
link |
誰可以maximize它呢?我們把這個整理一下,把w1的transpose乘上s乘上w1,整理一下,它變成,這個s乘上w1就是α乘上w1,所以這一下就變成α乘上w1的transpose乘上w1。
link |
w1的transpose乘上w1,這個是1,所以這邊就得到個α。然後接下來就是找,那誰可以讓這個α最大呢?
link |
在這個值給α的話,誰可以讓α最大呢?就是w1是對應到最大的eigenvalue的那個eigenvector的時候,它可以讓α最大,那這個α就是最大的eigenvalue,讓它1。
link |
如果你沒有聽懂的話,你就記得這個結論就好。第二個,如果我們要找w2的話,我們要解什麼樣的式子呢?我們如果要找w2的話,我們要解的是這樣子的一個equation。
link |
我們要解說,我們要maximize根據w2投移以後的variance,這個寫成這樣,w2的transpose乘上s乘上w2,同時w2要滿足null等於1。
link |
同時,w2跟w1的inner product,w1跟w2的terminal is orthogonal,那這個結論是什麼呢?你解完這個問題,你會得到什麼呢?你會得到說,w2也是covariance matrix S的一個eigenvector,然後它對應到第二大的eigenvalue,α2。
link |
好,那現在我們就要用Lagrange multiplier來解它。這個解法就是,你先寫一個function tree,這個function tree裡面包括了你要maximize的對象,還有你的兩個constraint,然後分別要乘上α跟β。
link |
接下來,你對你所有的參數做偏微分,你對你的w2裡面的每個參數都偏微分,你對w2的第一個element,w2的第二個element,以此類推都偏微分,做完以後,你得到這個式子。
link |
S乘以w2減α乘上w2減β乘上w1等於0。接下來,左邊同乘w1的transpose,乘w1的transpose,乘w1的transpose,乘w1的transpose。乘w1的transpose會發生什麼事呢?乘w1的transpose以後,w1的transpose乘w1等於1。
link |
這邊,w1的transpose乘w2等於0。然後這邊,w1的transpose乘s乘上w2等於什麼呢?因為這一項嘛,它是一個scalar,這是一個vector,這是一個matrix,這是一個vector,所以乘完以後是一個scalar。
link |
scalar在做transpose還是它自己,所以你可以直接把它transpose,結果是一樣的。做完transpose以後,你得到w2的transpose乘上s的transpose乘上w1,因為s是symmetric的,所以它做transpose還是它自己。
link |
所以這一項,s transpose變成它自己,所以變成這樣。然後接下來呢,我們已經知道w1是s的eigenvector,而且它對應到最大的eigenvalue lambda1,所以s乘w1等於lambda1w1,所以s乘w1等於lambda1w1。
link |
然後w1乘以w2的transpose就等於0,所以這一項,第一項也是0。所以從這邊我們得到什麼結論呢?我們得到的結論是β等於0,然後結論是β等於0。
link |
好,如果β等於0的話,這一項就會被拿掉,所以剩下的就是s乘上w2減αw2等於0,然後它會告訴我們說s乘上w2等於α乘上w2。
link |
所以你知道w2是一個eigenvector,但是它是哪一個eigenvector呢?如果你選它是,我們知道說這一項等於eigenvalue的值,但是你不能夠選eigenvalue最大的那個eigenvector,
link |
因為它跟w1不是orthogonal,但是你可以選第二大。憑什麼說選第二大的就跟第一大的是orthogonal呢?你就去查一下你的現代課本,因為s是symmetry的,所以你可以這麼做。
link |
好,那我們今天就把math的部分講完,最後這個地方要說,在這個end of warning之前剩下最後一頁投影片。這一頁投影片要說什麼呢?這一頁投影片要這樣說的,說z等於w乘上x。
link |
這個有個神奇的地方,就是z的covariance會是一個diagonal的matrix,也就是說,如果我們今天做PCA,你原來的data的distribution可能是這個樣子。
link |
做完PCA以後,你會做decorrelation,你會讓你的不同的dimension間的covariance治理,也就是說,如果你算z這個vector covariance matrix的話,會發現它是diagonal。
link |
這樣做有什麼好處呢?這樣做有時候會有幫助的。假設呢,你現在的這個PCA所得到的新的feature,你這個z呢,是一種新的feature,這個新的feature是要給其他的model用的。
link |
而你的model假設比如說是一個generated model,那你用Gaussian來描述某一個class的distribution,而你在做這個Gaussian的假設的時候,你假設說你的input data,它的covariance就是diagonal,你假設不同的dimension之間沒有correlation,這樣子可以減少你的參數量。
link |
所以你做PCA的時候,接下來的model就可以,你把你原來的input data做PCA以後,再丟給其他的model,其他的model就可以假設現在的input data,它是dimension間沒有correlation,所以它就可以用比較簡單的model來處理你的input data,這樣可以避免overfitting的情形。
link |
這件事情怎麼說明呢?這個也是很trivial,z的covariance就是z減z的平均,再乘上z減z的平均的transpose,那這一項你仔細想想看,把它展開,它是w乘上s乘上w的transpose,s是x的covariance。
link |
然後你就把它展開,這個w的transpose,它的第一個column就是w1,一直到dk的column是wk,把s乘進去,變成這個樣子。
link |
把s乘進去以後,這個sw1是什麼呢?w1是s的eigenvector,所以w1乘s等於λ1乘w1,wk乘s等於λk乘wk,這個w是eigenvector,然後λ是eigenvalue,然後我們再把w乘進去。
link |
那w乘w1會是什麼呢?這樣看,w1其實是w的第一個row,而w是一個orthogonal的matrix,所以w乘w1會等於1萬,1萬就是一個vector,它第一位是1,其他都是0。
link |
w乘wk會等於1k,1k就是,dk也是1,其他都是0。
link |
那這個東西就是一個diagonal的matrix,然後光景的部分就講完了。
link |
那這個部分或許你覺得沒有太容易理解,那我們下次從另外一個角度來看PCA,你可能就會更清楚說PCA是在做什麼。
link |
各位同學大家好,我們來上課吧。我們上次講到PCA,然後PCA有一個很冗長的證明,
link |
然後說PCA我們每次找出來的w,第一次找出來的w1是這個covariance matrix對應到最大的eigenvalue的eigenvector,
link |
然後第二個找出來的w2就是對應到第二大的eigenvalue的eigenvector,以此類推等等。
link |
然後有一個很長的證明告訴你說,這麼做的話,我們每次投影的時候都可以讓variance最大。
link |
那假如以下這些東西你聽不懂的話呢,就算了。我們來看看另外一個可能是比較直觀的說明。
link |
另外一個比較直觀的PCA的想法是這樣子的,假設我們現在考慮的是手寫的數字,那我們知道說這些數字其實是由一些basic component所組成的,
link |
這些basic component可能就是代表筆劃。舉例來說,人手寫的數字可能是由這些basic component所組成的,有斜的直線、橫的直線、比較長的直線,然後還有小圈、大圈等等所組成的。
link |
這些basic component把它加起來以後就可以得到一個數字。那這些basic component,我們這邊寫做u1、u2、u3等等,這些basic component其實就是一個一個的vector。
link |
假設我們現在考慮的是at least的話,at least的一張image是28x28px,也就是28x28y的一個vector,那這些component其實也就是28x28y的vector。
link |
那把這些vector加起來以後,你所得到的那個vector,把這些component所代表的vector加起來以後,你所得到的vector就代表了一個digit。
link |
或者如果我們把它寫成formulation的話,寫起來像是這個樣子。x代表了某一張image裡面的pixel,某一個image可以用一個vector來表示它,這個vector這邊寫做x。
link |
一直加上u2這個component乘上c2,一直加到u大k這個component乘上c大k,假設我們現在總共有大k個component的話。
link |
然後再加上這個xbar,xbar是所有的image的平均,所以每張image就是有一堆component的linear combination,然後再加上它的平均所組成的。
link |
舉例來說,我們說7是這個component,這個component和這個component加起來以後的結果。
link |
所以對7來說,假設這個7就是x的話,c1就是1,c2就是0,c3就是1,以此類推。
link |
你可以用c1,c2到c大k來表示一張image,假設你這個component的數目是遠比pixel的數目少的話,你就可以用這些component的weight來描述一張image。
link |
那如果component的數目比image的pixel數目少的話,那這個描述是會比較有效的。舉例來說,7是1倍的u1,1倍的u3加1倍的u5所組合成的。
link |
所以7你就可以說,它是一個vector,它第一維、第三維和第五維是1。那我們現在知道說,x等於一堆component的linear combination,再加上平均。
link |
我們現在把平均移到左邊,所以x減掉所有image的平均,等於一堆component的linear combination。那我們說,這些linear combination的結果,我們寫作x hat。
link |
那現在假設我們不知道這些component是什麼,我們不知道u1到u大k的這些大k的vector,它們長什麼樣子。那我們要怎麼找這大k的vector出來呢?那我們要做的事情就是,我們要去找這大k的vector,使得x hat跟x減x bar越接近越好。
link |
我們要找大k的vector,讓x減x bar跟x hat越接近越好。那它們中間的差呢,沒有辦法用這個component來描述的部分,叫做reconstruction error。
link |
那接下來我們要做的事情就是,找大k的component,其實就是大k的vector,它可以minimize這個reconstruction error。那這個reconstruction error,如果你要把formulation寫出來的話呢,就是我有一個reconstruction error寫成L。
link |
然後我們要找大k的vector去minimize它,要minimize的對象呢,就是x減x bar,x減x bar,減掉這個下面這一下的x hat,減掉x hat的to node,x hat是一堆component的linear combination。
link |
那我們先來回憶一下PCA,在PCA裡面我們講說呢,我們要找一個matrix W,那我們原來的vector x乘上matrix W以後,就得到這個dimensional reduction以後的結果Z。
link |
那我們可以把這個W的每一個row寫出來,就是W1,W2到W大k,然後x乘上W1的transpose得到Z1,x乘上W2的transpose得到Z2,以此類推。
link |
W1,W2到W大k都是covariance matrix的eigenvector。那事實上呢,如果你要解這個式子,你要解這個式子,找出U1,U2到U大k,這個W1到W大k,就是你用PCA找出來的這個解,其實就是可以讓上面這個式子最小化的,就可以讓這個reconstruction error最小的U1到U大k。
link |
那這個在bchop裡面呢,是有proof的,那我這邊講的跟bchop有點不一樣,我有一個比較簡單的方式來說明給大家聽。
link |
我們現在呢,在database裡面有一大堆的x,那現在假設有一個x1,這個x1減掉平均xbar,等於U1乘上component的weight,C上標1下標1。
link |
上標1代表說,它是這個x1的U1這個component的weight,我想這個大家應該知道我的意思。
link |
好,那所以x1減xbar呢,就等於C1乘U1加C2乘U2,那x1減xbar呢,它是一個vector,那我們把這個vector拿出來。那這個U1,U2到U大k呢,它們是一排vector,那我們就把它排起來。
link |
其實它排起來就是一個matrix,它的這個column的數目呢,是大k的column。那前面C1跟C1C2呢,它們就是我們把這個C1C2,這邊有一個錯誤的動畫,我們把這個C1C2把它排成一排,排成一排在這邊。
link |
那你現在把這個C1乘上它,把這個C2乘上它,就會得到這個vector,也就是說你把這一個vector,你把這些component的weight排成一排,它這個是一個vector,這個vector乘以這個matrix,就會得到這個vector。
link |
那我們的這個data set裡面不是只有一筆data,我們還有很多,這邊有個x2,那x2減xbar,它就是第二個黃色的vector。那U1U2呢,就在這邊,那C1C2,第二個component的C1C2。
link |
而第二個component的C1C2跟第一個component的C1C2,它們是不一樣的,它們是不一樣的,它們notation這邊是不一樣的。那我們把這個值呢,這個值呢,擺在這邊,擺在這邊。
link |
那這個vector乘上這個matrix,就會得到這個vector,以此類推,你把這個vector,第三個x3的component的weight,乘上component,就會得到這個vector。
link |
那如果我們data都用這個式子來表示,都把它畫在下面的話,那這邊呢,我們就得到一個matrix。那這個matrix的橫軸呢,它的這個column的數目呢,就是你的data的數目,你有一萬筆data,這個橫軸就是一萬。
link |
那我們呢,現在要做的事情就是,用這一個matrix去乘上這一個matrix,這兩個都是matrix,把這一個matrix乘上這一個matrix,那希望它越接近這一個matrix越好。
link |
所以你要minimize這兩個相乘以後得到的matrix,跟左邊這個matrix之間的差距,你要minimize這個reconstruction error。那怎麼解這個問題呢?假如你有修過大一現代的話,你就知道這個問題是怎麼解的。
link |
那這個是我教現代的時候的投影片,放在這邊給大家參考。那這個在現代裡面是怎麼說的呢?每一個matrix X,每一個matrix X,就這邊這個matrix X,你可以用SVD把它拆成一個matrix U乘上一個matrix Sigma乘上一個matrix V。
link |
那這個U呢,是M by K 為,這個Sigma是K by K 為,這個V呢,是K by N 為,這個K啊,它就是這個component的數目。所以我們把這個X呢,可以分解成U Sigma 跟V,這一個U就是這一個,那這一個Sigma乘上V就是這一個。
link |
那我們知道說,如果我們今天的這個,我們用SVD的方法呢,把X拆成這三個matrix相乘,那右邊這三個matrix相乘的結果,跟左邊這個matrix它們之間的這個forbearance的那個norm呢,是會被minimize的。
link |
也就是說,用SVD提供給我們的一個matrix的拆解方法,你拆出來的這三個matrix相乘,它跟左邊這個matrix是最接近的。那解出來的結果是怎麼樣呢?如果你還記得的話,解出來的結果是這樣子的。
link |
這個U這個matrix它的K個column啊,其實就是一組of a normal的vector,而這組of a normal的vector,它們是X乘上X的transpose,它們是X乘上Xtranspose的這個eigenvector。
link |
而它們這邊總共有K個vector,這邊總共有K個of a normal的vector,這K個of a normal的vector,它們就對應到X乘上Xtranspose最大的K個eigenvalue的eigenvector。
link |
這個大家聽得懂嗎?講得大家有問題嗎?好,那你會發現說,這個X乘Xtranspose是什麼啊?這個X乘Xtranspose是什麼?這個X乘Xtranspose不就是covariance matrix嗎?
link |
那我們說之前PCA找出來的那些W,就是covariance matrix的eigenvector,而我們在這邊要說,我們做SVD,你解出來的U的每一個column,就是covariance matrix的eigenvector。
link |
所以這個U這個解,其實就是PCA得出來的解。所以我們知道說,PCA現在在做的事情,你找出來的,你根據PCA,你找出來的那些W,你找出來的那個dimensional reduction的transform,其實就是在minimize the reconstruction error。
link |
那dimensional reduction的結果呢,你得到的其實就是這些vector,你在PCA裡面你得到的那些W,其實就是component。
link |
好,那如果大家知道這些的話呢,我們等一下會看說PCA跟neural network有什麼樣的關係。那我們現在已經知道說,從用PCA找出來的W1到W大K,就是K個component,U1,U2到U大K。
link |
那我們說呢,我們有一個根據component linear combination的結果叫做x-hat,它是WK乘上CK做linear combination的結果。
link |
那我們會希望說呢,這個x-hat跟x-x-bar,這個是x-bar,x-x-bar,它的平均呢,是越小越好。你想minimize這個reconstruction error。那我們現在已經根據SVD找出來了這個W,W已經找出來了。
link |
那這個CK的值到底應該是多少呢?這個CK啊,是每一個example,如果是image recognition的話,就是每一個image都有一組自己的CK。
link |
所以你要找這個CK,就每個image呢,各自找就好,每個image各自找就好。那這個問題其實就是問說,我現在呢,有一個有大K維的vector,他們做span以後呢,得到一個space。
link |
那如果我現在呢,要用C1到C大K,對它做linear combination,怎麼樣才能夠最接近x-x-hat,怎麼樣才能最接近x-x-bar呢?
link |
因為現在這大K的vector,他們是of normal的,所以你要得到這個CK呢,其實很簡單的,你只要把x-x-bar跟WK做inner product,你得到的就是CK。
link |
你要找一組CK可以minimize左邊這個跟右邊這個的error,你只需要把這個x-x-bar跟WK做inner product就好了。
link |
這個性質是來自於說,這K的vector是of normal的。這個如果你有困惑的話,你可以回去check一下線性代數的課本。
link |
那我們現在已經知道了這些事情,我們已經知道說CK就是長得這個樣子。
link |
那這一件事情呢,這個做linear combination的事情,其實你可以想成用neural network來表示它。
link |
什麼意思呢?假設我們的x-x-bar就是一個vector,這邊呢,寫做一個三維的vector。
link |
那我們假設現在呢,K呢,只有兩個component,K呢,等於2。
link |
那我們先算出C1跟C2,怎麼算C1呢?C1就是x-x-bar跟W1的inner product。
link |
所謂的inner product就是element wise的相乘,也就是把x-x-bar的每一個component乘上W1的每一個component,接下來呢,你就得到C1。
link |
這件事情就好像是說,這個是neural network的input,這是一個neural,這是neural的weight。
link |
這個neural,它是linear的neural,它沒有exervation function,它是linear的。
link |
那這個neural,你把這個東西input乘上這個weight,你就得到C1。
link |
那C2也是一樣,OK,C2,我們這邊,好,這邊是這樣子。那我們接下來呢,要把C1呢,我這邊犯了一個錯誒,這個應該是下標,這個應該是下標。
link |
如果要統一起來的話,這個K呢,應該是下標。
link |
好,那我們把這個C1呢,要乘上W1。所謂的C1乘上W1是什麼意思呢?你就把C1乘上W1得到,把C1呢,乘上W1的第一位得到一個value,乘上W1的第二位得到一個value,乘上W1的第三位得到一個value。
link |
OK,所以這一項呢,就是C1乘上W1。好,接下來呢,我們再算一下C2,C2一樣就是這個input乘上,跟這個W2呢,所謂inner product,得到C2。
link |
然後呢,再把這個C2呢,乘上W2的三個element,這跟原來W1這邊乘的三個element加起來,你就得到最後的output。
link |
這一項呢,就是x hat,這一項就是x hat。
link |
那接下來我們training的criteria呢,就是minimize,我們要讓這個x hat跟x-x bar呢,越接近越好。
link |
所以我們就是希望這個neural network的output跟x呢,-x bar呢,越接近越好。
link |
我們把這個,這是我們的input x-x bar,它乘上一組weight,然後在hidden layer的output是C1,C2,再乘上另外一組weight,得到x hat,那我們希望這個x-x bar呢,越接近越好。
link |
那你就會發現說,其實PCA呢,可以表示成一個neural network,它可以表示成一個neural network,然後這個neural network它只有一個hidden layer,然後這個hidden layer是linear的activation function。
link |
那這個,然後呢,我們現在train這個neural network的criteria,是要讓input一個東西得到output,然後結果這個output呢,要跟input呢,越接近越好。
link |
這個output要跟input越接近越好,這個output要跟input呢,越接近越好。
link |
這個東西呢,就叫做autoencoder。
link |
那這邊你就會,這邊呢,我們就有一個問題,我們這邊就有一個問題,假設我們現在這個weight不是用PCA的方法,也就不是用找那個什麼eigenvector的方法去找出這些w1,w2,wk,而是都一個neural network,直接用我們要minimize error這個criteria,然後用這個gradient descent去train一發的話,
link |
那你覺得你得到的結果,會跟用PCA解出來的結果一樣嗎?
link |
有些同學覺得會一樣,好,手放下,你覺得會不一樣的同學舉手?
link |
也有一些同學覺得會不一樣,覺得不一樣的稍微多一點。
link |
其實是會不一樣的,你仔細想想看,PCA解出來的這些w,他們是orthonormal的,他們是orthonormal的,他們是垂直的。
link |
那你今天如果你用neural network,你就多一個這樣的neural network,硬扔一發,你得到的結果,你沒有辦法保證weight是垂直的,你會得到一個solution,但是你沒有辦法保證說,這組weight,這個w1跟w2是垂直的,你得到的是另外一組解。
link |
那我們剛剛前面的SVD的證明裡面已經說,PCA找出來的這一組解,w1到w2大K,它可以讓我們的reconstruction error被minimize。
link |
那你用這個neural network的方法,去用great entity再硬解一發,你其實也不可能找出來,你不可能讓你的reconstruction error比PCA找出來的reconstruction error還要小。
link |
那所以如果是在linear的情況下,或許你就會想要直接用PCA來找這個w是比較快的,你用neural network或許是比較麻煩。
link |
但是用neural network的好處就是,它可以是deep的,這邊為什麼只可以有一個hidden layer呢?它的一個hidden layer就要改成很多個hidden layer,所以這個就是我們等一下會講的,下一堂課會講的deep autoencoder。
link |
那PCA其實有一些很明顯的弱點,一個就是因為它是unsupervised,所以今天假如給它一大堆點,沒有label,那對PCA來說,假設你只要把它project到一位置上,PCA會找一個可以讓data,variance最大的那個dimension。
link |
那在這個case裡面,或許它就把它project到這一位置上,把每一個綠色的點都project到這一位置上。但是有一個可能是,或許其實這兩組data point,它們分別代表了兩個class。
link |
如果你用PCA這個方法來做dimension reduction的話,你就會使得這兩個藍色跟橙色的class被merge在一起,它們在PCA找出來的single dimension上完全被混在一起,就無法分別。
link |
那這個時候怎麼辦呢?你可能會需要引入label data,那LDA是考慮這個label data的一個降維的方法,不過它是supervised,所以這邊就不是我們要講的對象,這個LDA是linear discriminant analysis的縮寫。
link |
那另外一個PCA的弱點就是,它是linear的。我們剛才在一開始舉的例子的時候,我們會說,這邊有一個S型的manifold,這邊有一堆點,它的分布像是一個S型的。
link |
那我們期待說做dimension reduction以後,可以把這個S型的曲面把它拉直。但這件事情對PCA來說是做不到的,你要它做這件事情其實是強人所難。因為你要把這個S型的曲面拉直,是一個nonlinear transformation,PCA做不到這件事情。
link |
如果你做PCA的話呢,你得到的結果呢?如果你把這個S型的曲面做PCA,你得到的結果就是這樣。你就是把它從藍色這邊,把它這樣打扁。
link |
有沒有發現說,藍色跟紅色的點呢,就被壓在一起,然後綠色的點在這邊,黃色的點在這邊。你會把它打扁,而不是把它拉開。因為把它拉開這件事情,是PCA辦不到的。那我們等一下會講nonlinear transformation。
link |
再來呢,我們就把PCA用在一些實際的問題上。比如說,我用它來分析寶可夢的data。我們這一門課的例子,都是寶可夢的例子。寶可夢呢,我們都知道說,它總共有八百種寶可夢。
link |
其實有人說是七百二十一種,因為那八百種裡面呢,有一些是重複的。我也不知道怎麼解釋就是了。反正就是,就假設有八百種好了。那每一種寶可夢,你可以用六個feature來表示它,分別是生命值、攻擊力、防禦力、特殊攻擊力和特殊防禦力,還有它的速度等等。
link |
所以他們就是,每一個寶可夢就是一個六維的data point,就是一個六維的vector。那我們現在呢,要用PCA來分析它。
link |
在用PCA的時候,常常會有人問的一個問題就是,我需要有多少個component?我到底要把它project到一維還是二維還是三維?這個資訊量才足夠呢?這depends on你想要做什麼。
link |
如果你放在六維,你沒有辦法了解寶可夢它們之間的個性有什麼樣的關係,因為六維你沒有辦法看,所以你可能就想要把它project到二維,那就比較容易分析。
link |
要用多少個principal component,就好像是neural network要有幾個layer,每個layer要多少個hidden variable,要有幾個neural一樣,所以這個是你要自己決定的。一個常見的方法是這樣,一個常見的方法是說,我們去計算每一個principal component的浪達。
link |
我們知道每一個principal component就是一個eigenvector,然後那個eigenvector都對應到一個eigenvalue,就是這邊的浪達。那這個eigenvalue代表什麼意思呢?
link |
這個eigenvalue代表說,我們用這個principal component去做dimension reduction的時候,在這個principal component的dimension上,它的variance有多大,那個variance就是浪達。
link |
今天這個principal component的data總共有六維,所以它的covariance matrix是六維,所以你可以找出六個eigenvector,你可以找出六個eigenvalue。
link |
那我們現在來計算一下每個eigenvalue的ratio,我們就把每個eigenvalue除掉六個eigenvalue的總和,那你得到的結果會是這個樣子。就第一個eigenvalue,它佔全部的eigenvalue的0.45,第二個是0.18,第三個是0.13,以此類推。
link |
所以看到這個結果呢,我們可以從這個結果看出來說,這邊是0.45,0.18,0.13,0.12,再來是0.07,0.04,所以這個第五個principal component和第六個principal component,它們的作用其實是比較小的。
link |
你用這兩個dimension來做projection的時候,你project出來的variance是很小的,代表說現在寶可夢的這些特性在這第五個和第六個principal component上是沒有太多的information的,那variance很小,所以它沒有太多的information。
link |
所以如果我們今天要分析寶可夢的data的話,感覺只需要前面四個principal component就好了,所以我們就實際來分析一下。如果你做PCA以後,我們得到的四個principal component就是這個樣子。
link |
每一個principal component就是一個vector,現在每一個寶可夢它是用六維的vector來描述它,所以每一個principal component就是一個六維的vector,這四個principal component就是四個六維的vector。
link |
那我們來看一下每一個principal component它在做的事情是什麼呢?如果我們看第一個principal component,第一個principal component它的每一個dimension都是正的。
link |
這個東西是什麼意思?這個東西其實就代表了寶可夢的強度。如果你要產生一隻寶可夢的時候,每一個寶可夢都是由這四個vector做linear combination的。
link |
每一個寶可夢可以想成是,它的數值可以想成是這四個vector做linear combination的結果,這是combined weight,每一隻寶可夢是不一樣的。所以你如果在選第一個principal component的時候,你給它的weight比較大,那這個寶可夢就是它的六維都是強的。
link |
那如果選擇值小呢,就是它的六維都是弱的。所以這第一個principal component就代表了這一隻寶可夢的強度。那第二個principal component是什麼呢?第二個principal component它在防禦力的地方是正值,它在速度的地方是負值。
link |
也就是說,這個防禦力跟速度是成反比的。你今天給第二個component一個weight的時候,你會增加那隻寶可夢的防禦力,但是會減低它的速度。所以寶可夢防禦力提升的時候,它的速度會下降。
link |
那如果我們把第一個和第二個principal component把它畫出來的話,你會發現是這個樣子。這個圖上有八百個點,然後每一個點就對應到一隻寶可夢,把它畫到二維平面上。
link |
那這樣我們很難知道每一隻寶可夢是什麼。所以我就做了一件發狂的事,做網頁。而如果我們看第三、第四個component的話,那會發現說第三個component呢,它是special defense是正的,然後攻擊力跟HP是負的。
link |
也就是說,這是用攻擊力跟HP來換取特殊防禦力的寶可夢。那最後一個呢,最後一個是它的HP是正的,然後攻擊力和防禦力是負的,也就是它是用攻擊力和防禦力來換取生命力的寶可夢。
link |
那這些分別是什麼呢?如果我們把第三個和第四個principal component畫在圖上的話,其實它們也是橢圓的形狀。我們基本上考慮的是統計的結果,所以會有一些outlier,不過統計的結果最後算出來,它是decorrelation的。
link |
其實呢,特殊防禦力用攻擊力和生命值換特殊防禦力的,其實也是活潑。它不只是一個防禦力特別高的寶可夢,它也是一個特殊防禦力特別高的寶可夢。第二名是這個冰柱機器人。
link |
然後如果我們看生命力的話,第四個component就是生命力特別強的。那這個其實跟我們的預期是一樣的,就是這個是吉利蛋跟幸福蛋,對不對?
link |
所以今天至少我們回答到一個問題,我們知道最強的寶可夢其實是超夢,還有那三隻神獸是特別強的。如果我們可以拿它來做其他test,比如說我們拿它來做手寫影像數字的辨識的話,那會怎麼樣呢?
link |
我們可以把每一張數字都拆成component的weight乘上component,加上component的weight乘上另外一個component。但其實每一個component都是一張image,對不對?
link |
每一個component都是一個二十八乘二十八微的vector,所以你可以把它畫在圖上,把它變成一張image。我們如果畫PCA得到前三十個component的話,你得到的結果其實是這個樣子的。
link |
白色的地方代表有筆畫的,這個是1,這個看起來有點像9,這個看起來是0,中間接一條線,這個看起來像是這樣的勾勾,後面這個很複雜,看起來像瑪雅文字那麼複雜。
link |
然後你用這些component做linear combination,你就可以得到所有的digit,就可以得到0到9。所以這些component就叫做eigendigit,這個叫做eigendigit,就是說這些component其實都是covariance matrix的eigenvector,所以叫它eigendigit。
link |
用這個eigendigit做linear combination,你就可以得到各種不同的digit。那如果做人臉辨識的話,如果你做處理人臉的話,得到的結果大概是這樣。
link |
這邊有一大堆的人臉,你就找它的principle component,找前三十個principle component,你就會發現找出來的就是這樣,每一個都是那個哀怨的臉。
link |
這叫做eigenface。你看每一個都是一個臉,每一張都是一個臉。你把這些臉做linear combination以後,你就可以得到所有的臉。
link |
但是這邊,你有沒有覺得有些地方跟你預期的不太一樣呢?我第一次看到這個結果的時候,我覺得跟我預期的不太一樣,是不是存受bug?因為我們說PCA找出來的是component,對不對?
link |
我們把很多componentlinear combine以後,它會變成一個face,會變成一個digit。但我們現在找出來的不是component,我們找出來的每一個圖,幾乎都是完整的臉。
link |
你剛才看前一個數字,你找出來每一個i跟digit,看起來都是瑪雅文字,它們不是component,不是一筆畫這種東西,不是圈圈、筆數這種東西。
link |
為什麼會這樣呢?如果你仔細想想看PCA的特性,你會發現說會得到這個結果是可能的。因為在PCA裡面,你的linear combination的weight,它可以是任何值,它可以是正的,也可以是負的。
link |
所以當我們用這些principle component組成一張image的時候,你可以把這些component相加,也可以把這些component相減。所以這會導致說你找出來的component不見得是一個圖的basic的東西。
link |
舉例來說,假設我想要畫一個9,那我可以先畫一個8,然後再把下面的圈圈減掉,然後再把一槓加上去。這樣大家了解我的意思嗎?
link |
因為現在我們不一定是把這些component加起來,我們可以把這些component相減,所以就變成說你可以先畫一個很複雜的圖,然後再把多餘的東西減掉。
link |
這是為什麼我們剛才會看到一堆瑪雅文字的關係。這些component其實不見得是類似筆畫這種東西。
link |
那如果你想要得到類似筆畫的東西的話怎麼辦呢?你要用另外一個技術叫做non-negative matrix vectorization。
link |
在non-negative matrix vectorization裡面,我們剛才講說PCA它可以看作是對matrix X做SVD,SVD就是一種matrix vectorization的技術,就是一種矩陣分解的技術。
link |
它分解出來的兩個matrix的值可以是正的,可以是負的。
link |
那現在如果你用NF的話,我們沒有打算講它的細節,我等一下列個reference給大家參考就好。
link |
如果我們現在用NF的話,我們會強迫所有的component都是正的。
link |
首先我會強迫所有component的weight都是正的。
link |
是正的的好處就是現在一張image必須有component疊加得到,而你不能說我先畫一個圖,很複雜的東西,然後再把複雜的東西去掉一些部分得到一個digit。
link |
那現在因為每一個weight都一定要是正的,所以你只能相加。
link |
再來就是所有的component,它的每一個dimension也都必須要正的。
link |
如果你用NF的話,你會讓你的每一個dimension都是正的。
link |
那如果你用PCA的話,你得到的dimension不見得每一個weight都是正的。
link |
你找出來的principle component裡面,它會有一些負值。
link |
那你知道如果你現在要畫一張image的話,其實負值你是有點不知道該怎麼處理的。
link |
如果我今天把那個負值都當作沒有筆劃就是0的話,你整張圖看起來都黑漆漆,大部分的圖都黑漆漆,就很怪。
link |
我前面那幾張圖的做法是,如果有負值又有正值,我會把它normalize,把它做一個平移,讓負的也都變成正的。
link |
那這個就有點麻煩,如果你用NF就不會有這個問題了,你找出來的component都是正的,所以那些component就很自然的會形成一張image。
link |
下面這個是reference給大家參考。
link |
所以如果在同樣的task上,比如在手寫數字的task上,一樣applyNF的時候,這個時候你找出來的那些principle component就會清除很多。
link |
這顯然都是筆劃,這個是正的,這個是0的兩邊,這個是斜的,一小點,一直線,一撇,一橫線,一撇。
link |
你會發現你找出來的每個東西就都變成是筆劃了,這跟我們本來想要找的東西是比較像的。
link |
如果你看臉的話,你就會發現說它長得是這個樣子,它比較像是臉的一些部分,比如說這個是人中的地方,這個是眉毛,這個是下巴,這個是嘴唇,這個也是嘴唇等等。
link |
如果你今天是用NF來對你對這個人臉的圖片做NF的話,你得到的結果會比較像是你期待要找的像是component一樣的東西。
link |
接下來剩下時間我們講一下這個matrix的factorization。
link |
那matrix的factorization是這樣,有時候你會有兩種東西,你會有兩種object,它們之間是受到某種共通的latent的factor去操控的。
link |
什麼意思呢?就假設我們現在做一下調查,調查每個人手上每個人有買的公仔的數目,然後ABCDE代表五個人,我們調查一下每個人手上有的公仔的數目。
link |
比如說調查A有五個良宮村的公仔,B有四個,C有一個,D有一個,然後這個是玉斑美琴,A有三個,B有三個,C有一個等等。
link |
這是解釋,D有四個,E有五個,這個是小微,這是平則微,然後C有五個,C有四個,D有四個。
link |
那你會發現說在這個matrix上面,每一個table裡面的block並不是隨機出現的,你會發現說如果有良宮村公仔的人,就比較有可能有玉斑美琴的公仔,有解釋公仔的人就比較有可能有小微的公仔。
link |
所以說每一個人跟那個角色背後是有一些共同的特性,有一些共同的factor來操控這些事情發生的。
link |
Otakus這個是御宅族的意思,每一個御宅族和每一個角色後面是有一些共同的factor在操控他們的。
link |
其實動漫宅或許可以分成兩種,有一種是萌傲嬌的,有一種是萌天然呆的,每個人其實就是在萌傲嬌和萌天然呆的平面上的一個點。
link |
A是比較偏萌傲嬌的,每一個角色他可能是有傲嬌屬性或者是有天然呆的屬性,所以每一個角色也都是平面上的一個點,每一個角色你也都可以用一個factor來描述他。
link |
如果某一個人萌的屬性跟某一個角色他本身所具有的屬性是match的話,所謂的屬性match是說他們背後的這個factor很像,他們背後的這個factor,比如說inner product的時候值很大,那這個人就會買很多亮光春日的公仔。
link |
他們有沒有match的degree,他們這個匹配的程度,就取決於他們背後的這個latern factor是不是匹配。所以可能A、B、C他們背後的這個萌的角色是大概這個樣子,A是萌傲嬌的,B也是萌傲嬌的,但沒有A那麼強,然後C是萌天然呆的。
link |
每一個動漫人物的角色後面也都有傲嬌和天然呆這兩種屬性,每一個角色都有他不同的屬性。如果他們背後的屬性是match的話,那這個人就會買這個公仔。這個世界操控的邏輯是這個樣子的。
link |
但是這些factor,就一個人到底是萌傲嬌還是萌天然呆,這件事情是沒有辦法直接被觀察的,因為其實沒有人在意一個阿宅他心裡想什麼。所以這些事情是沒有人知道的,你也沒有辦法直接知道說每一個動漫人物他背後的屬性是什麼,這個也是沒有辦法直接觀察到的。
link |
所以我們有的東西是什麼呢?我們有的是這個動漫人物跟阿宅中間的關係,也就是他手上有的公仔的數目,他們之間的關係。
link |
我們要憑著這個關係去推論出,每一個人跟每一個動漫人物他們背後的latent factor,他們每一個人背後都有一個二維的factor,分別代表了他萌傲嬌或者是萌天然呆的程度,他都是用一個factor來表示。
link |
每一個人物他背後也都有一個vector,代表他的傲嬌的屬性還有天然呆的屬性。而我們知道的每一個阿宅他手上有的公仔的數目,你就可以把它合起來看作是一個matrix X。
link |
這個matrix X,它的row的數目就是otaku的數目,它的column的數目就是動漫角色的數目。
link |
我們現在要做的事情是做一個假設,這個假設是這樣子的。每一個這個matrix裡面的element,它都來自於兩個vector的inner product,它都來自於兩個vector的內積。
link |
這個5呢,為什麼A會有五個良弓春日的公仔呢?是因為RA跟R1的inner product很大,他們的inner product是5,所以它就會有五個良弓春日的公仔。
link |
而如果RB跟R1的inner product是4的話,那B就會有四個良弓春日的公仔,一次類推。這個世界運作的邏輯就是這個樣子的。那這件事情,如果你要用數學式來表示它的話,你可以寫成這樣子。
link |
我們把RA到RE排成一排,把R1到R4也當作是另外一個matrix的row把它排起來。那這個K呢,是latent vector的數目,這個東西我們是沒有辦法知道的。
link |
我們把人分成只有萌傲嬌和萌天然胎,這樣是一個不精確的分析方式。如果我們有更多的data的話,我們應該可以更準確的知道說應該有多少vector。
link |
但是實際上要有多少vector,這件事情你必須要是試出來,就像是principle harmonic的數目或者是這個neural network的乘數一樣,這個是你要事先決定好。
link |
我們現在就假設說,latent vector的數目就是K。所以這個RA到RE,你把它當作matrix的row,這邊就有N乘K一個,就是一個N乘K的matrix。
link |
你把R1到R4當作column,那就是K乘N的matrix。那你把這個N乘K的matrix,K乘N的matrix乘起來,你就會得到一個,我寫錯了,這個應該是N,這個應該是有N個octave,所以是有N個人。
link |
所以把這個N乘以K乘上K乘以N,得到一個N乘以N的matrix。那它的每一個dimension分別是什麼呢?我們知道說,最左上角這個dimension,如果你現在熟的話,它就是RA乘上R1,對不對?
link |
那這個第一個row,第二個column的這個element,N下標A2,就是RA乘上R2,N下標B1,就是RB乘上R1,N下標B2,就是RB乘上R2。
link |
所以這個matrix是什麼呢?這個matrix其實就是這一個matrix,其實就是這個matrix。就假設我們說,這個matrix就是這個matrix的話,那我們要做的事情就是找一組RA到RE,找一組RA到RE,找一組R1到R4,找一組R1到R4,把這兩個matrix相乘以後,跟這個matrix X,它越接近越好。
link |
minimize這兩個matrix相乘以後,跟這個matrix X之間的這個reconstruction的arrow。那這個東西呢,我們剛才講過,你就可以用SVD來解。你可能說,SVD不是解完會有三個matrix嗎?中間還有一個sigma,你就看你要把sigma變到左邊還是變到右邊都可以,然後你就把這個matrix X拆成兩個matrix,然後它們可以minimize的reconstruction arrow,然後就結束了。
link |
但有時候你可能會遇到這個問題,就是有一些information是missing的,是你不知道這個information的。比如說ABC,你並不知道ABC手上有沒有小野寺的公仔,因為有可能就只是在他所在的那個地區沒有發行這個公仔而已,所以你不知道如果發行的話,他到底會不會賣。
link |
所以這邊其實是問號,這個是問號。就假設這個table上有一些問號的話,怎麼辦呢?這個table上有一些問號的話,你用剛才那個SVD的方法,就會有點卡。你可能說,我把這個值都當作是0,然後硬做一發,這樣也可以啦,不過總覺得有些怪怪的,可以描述得更精確一點。
link |
所以如果今天在這個matrix上面有一些missing的value的話,怎麼辦呢?有一些missing的value的話,我們還是可以做的,我們就用gradient descent的方法來做它。就我們寫一個loss的function,這個loss的function是這樣子。
link |
我們要讓ri,ri指的是每一個otaku背後的latent vector,而rj指的是每一個動漫角色背後的latent vector。你要讓i這個人,他的latent vector乘上j這個角色,他的latent vector,這個inner product,跟他購買的數量nij越接近越好。
link |
重點是說,我今天在summation over這些element的時候,我可以避開這些missing的data,我們可以避開這些missing的data。我在summation over這些ij的時候,如果今天這個值是沒有的,我就不算它,我們只算這個值是有定義的部分。
link |
那接下來怎麼辦呢?接下來你都把loss function寫出來了,那你要找ri跟rj,就用gradient descent就好了,用gradient descent,印算一發,然後就結束了。
link |
所以根據剛才那個例子,我們就可以實際的用gradient descent來做一下,我們假設latent vector的數目等於2,每一個a到1,他們就都會對應到一個二維的vector,所以a的vector是這樣,b是這樣,c是這樣,以此類推。
link |
每一個人都會對應到一個vector,每一個角色也都可以對應到一個vector。我怕大家如果我只寫這個字的話,你們會不知道這是什麼意思,所以這邊也把編號列出來,這個是春日,這個是炮姐,這是解釋,這是小薇。
link |
你就會找出說,每一個角色也都得到一個vector,也都得到一個latent vector,這代表他的屬性,而這個每一個人的latent vector就代表了他蒙哪一種屬性。
link |
所以如果我們把他在兩個維度裡面比較大的維度調出來的話,你就會發現說,a跟b是蒙同一組屬性的,c、d、e是蒙同一組屬性的,1跟2他們有同樣的屬性,然後3跟4他們有同樣的屬性。
link |
你才真的知道說每一個屬性分別代表的是什麼,你不知道說這個維度是代表的是傲嬌還是天然呆,你不知道這個維度代表的是傲嬌還是天然呆,你需要先找出這些latent vector以後,再去分析他的結果,你就可以知道說,因為我們已經事先知道說解釋跟小薇是有天然呆屬性,所以第一個維度代表的就是天然呆的屬性,而第二個維度代表的就是傲嬌的屬性。
link |
接下來有這些data以後,你就可以預測你的missing value,你就可以預測問號的值。怎麼預測問號的值呢?我們如果已經知道R3,我們已經知道RA,那我們知道說一個人會購買公仔的數量,其實是這個動漫角色背後的latent vector跟那個人背後的latent vector做inner product的結果。
link |
所以我們只要把R3跟RA做inner product,你就可以預測說這個人會買多少的公仔。所以做完inner product以後的結果就是這樣子。
link |
這告訴我們說,如果說這個RC跟R3他們的latent vector其實是match的,所以這個C這個人,如果他可以買的話,預期他會買2.2,他會有2.2個解釋的公仔,所以你就可以推薦解釋的公仔給他,也可以推薦他入坑。
link |
所以這種方法常用在推薦系統裡面,大家可能都有聽過Netflix的比賽,如果你今天把動漫角色換成電影,你把中間的數值換成rating的話,你就可以預測說某一個人會不會喜歡某一部電影等等。
link |
那推薦系統呢,現在很多都會使用這樣子的技術。那其實呢,剛才那個model可以做得更精緻一點,我們剛才說A背後的latent vector乘上E背後的latent vector,得到的結果呢,就是table上面的數值。
link |
但是事實上可能還有別的因素會操控他的數值,所以更精確的寫法或許是,我們可以寫成RA跟R1的inner product,加上某一個跟A有關的scalar,再加上某一個跟E有關的scalar,其實才等於。
link |
這個跟A有關的scalar,BA指的是什麼呢?它代表的是說,這個A呢,他有多喜歡買公仔。有的人呢,他其實也不特別萌那個角色,他就只是想要買公仔而已。
link |
所以這個BA代表他本身有多想要買公仔。那這個B1代表說,這個角色他本質上會有多想讓人家購買。這件事情是跟屬性無關的,就是大家本來就會想要購買這個角色。
link |
比如說最近涼光春日慶祝動畫十週年,就出一些藍光DVD什麼的,所以大家就可能會比較想要買涼光春日的公仔,其實也不會,所以就會有這個B1。
link |
所以你今天就改一下這個minimize的式子,就變成說把ri跟rj的inner product加上bi再加上bj,然後你會希望這個值跟nij越接近越好。
link |
你會希望說這兩個latent vector inner product加上代表i本身的scalar,還有代表j本身的scalar,要跟在table上面看到的值越接近越好。
link |
那這個怎麼解呢?這個沒有什麼好講的,你就用歸顛design的硬解一發就好了。那你也可以加regularization,如果你覺得應該要regularization的話,你也可以在這個ri rj bi bj上面加上regularization。
link |
比如說你會希望說ri rj是sparse的,每個人要嘛就是蒙傲嬌,要嘛就是蒙天然呆,不會有模糊的人,那你可能就會想要加上L1的regularization。
link |
然後如果你想要知道更多的話,以下是metric vectorization經典的paper,它講的在這個netflix上面是怎麼做的。那metric vectorization還有很多其他的應用,比如說它可以用在topic analysis上面。
link |
等一下11點多的時候助教會來講一下這個作業室,作業室要做的是跟文字有關的,裡面你可能會需要用到topic analysis的技術。那如果是把剛才講的metric vectorization的方式用在topic analysis上面的話,就叫做latent semantic analysis,LSA。
link |
那它的技術跟我們剛才講的是一模一樣的,就只是換個名詞而已,就只是把動漫人物通通換成文章,把剛才的人都換成詞彙,把人物換成文章,人都換成詞彙。
link |
那TAO裡面的值就是term frequency,就是說投資這個word在document 1裡面出現五次,股票這個word在document 1裡面出現四次,以此類推。
link |
那有時候我們不只會用term frequency,你會把這個term frequency再乘上一個weight,代表說這個term本身有多重要。如果你把一個term乘上比較大的weight的話,今天你在做metric vectorization的時候,那個term就會被比較考慮到。
link |
你就會比較想要讓那個term的reconstruction error比較小。那怎麼evaluate一個term這麼重要呢?有很多方法,比如常用的就是inverse document frequency。
link |
這個我想等一下助教會講,或是如果你不知道的話,你可以自己google一下。所謂inverse document frequency簡單的來講就是,計算某一個詞彙在整個compose裡面有多少比例的document有涵蓋這個詞彙。
link |
假如某一個詞彙是每一個document都有的,比如說d,每一個document都有,那它的inverse document frequency就很小,代表說這個詞彙的重要性是低的。假如某一個詞彙是只有某一篇document有,那它的inverse document frequency就很大,代表這個詞彙的重要性是高的。
link |
那在這個test裡面,如果你今天把這個metric做分解的話,你就會找到每一個document背後的latent vector,你就會找到每一個詞彙背後的latent vector。
link |
那今天這個latent vector是什麼呢?今天這個test裡面你的latent vector可能指的是topic,你可能指的是這個主題。就某一個document它背後要談的主題,有多少部分是跟財經有關的,有多少部分是跟政治有關的。
link |
某一個詞彙它有多少部分是跟財經有關的,它有多少部分是跟政治有關的。比如說可能今天在這個例子裡面,投資跟股票是跟財經有關的,那document 1跟document 2又都有比較多的投資跟股票這樣的詞彙,
link |
那document 1跟document 2它就有比較高的可能性,它背後的latent vector是偏向於財經的。
link |
那其實tabular analysis的方法多如牛毛,雖然它們基本的精神是差不多的,但是有很多各種各樣的變化。
link |
一個常見的是probabilistic latent semantic analysis POSA,還有另外一個是latent Dirichlet allocation LDA,這邊就把reference列在這邊給大家參考。
link |
前面我們也有講過另外一個LDA,就是在machine learning裡面有兩個LDA,它們是完全不一樣的東西,就是怎麼回事。
link |
這邊就是一些reference給大家參考,其實這種dimensional reduction的方式,這邊還沒有列,這邊只列一些跟PCA比較像比較有關係的。
link |
這個dimensional reduction的方法多如牛毛,比如像MDS,MDS它特別的地方是,它不需要把每一個data都表示成feature vector,它要知道的只有feature vector和feature vector之間的distance。
link |
你只要有這個distance,你就可以做dimensional reduction。一般教科書舉的例子都會舉說,我現在有一堆城市,你不知道怎麼把城市描述成一個vector,
link |
但你知道城市和城市之間的距離,每一筆data之間的距離,你就可以把它畫在一個二維的平面上。
link |
其實MDS跟PCA是有一些關係的,你如果用某些特定的distance來衡量兩個data point之間的距離的話,你又做MDS,就等於是做PCA。
link |
所以其實PCA有一個特性是,它保留了原來在高維空間中的距離。如果兩個data point在高維空間中的距離是遠的,在低維空間中的距離也是遠的。高維空間中是接近的,在低維空間中也是接近的。
link |
PCA有機率的版本,PCA有非線性的版本,叫kernel的PCA。另外一個東西叫CCA,CCA是說如果你有兩種不同的source,這個時候你會想要用CCA。
link |
一件事,你的兩個source,一個是聲音訊號,另外一個是假設你今天其實是有螢幕的,你可以看到這個人的唇型,你可以讀他的唇語。你現在有聲音訊號,有那個人嘴巴的image,你把這兩種不同的source都做dimension reduction,這個是CCA。
link |
還有另外一種東西叫ICA,它們名字聽起來都很像,ICA比較常用在source separation上面。它要做的事情是,原來在PCA裡面我們找出來的component是osobono,那ICA裡面我們不見得要找osobono的component,我們找independent的component就好。
link |
它用一套很複雜的方法來定義什麼叫做independent的component。還有剛才有提到的LDA,它是supervised的方式。以上給大家參考,我們在這邊休息十分鐘,謝謝。