back to index
ML Lecture 15: Unsupervised Learning - Neighbor Embedding
link |
接下來呢,我要講的是neighbor embedding,我們在最後一個作業的投影片裡面,助教有提到一個東西,叫做TSNE。TSNE我相信你在很多不同的場合也常常聽到,但是如果有人問你說TSNE是什麼的時候,大家往往都答不出來,現在我們要來講一下TSNE是什麼。
link |
TSNE的NE其實就是neighbor embedding的縮寫。那我們現在要做的事情呢,其實就是我們之前講過的降維,只是我們要做的事情是非線性的降維。
link |
我們想要做到的事情是說,我們知道說data point它可能是在高維空間裡面的一個manifold,也就是說data point的分布,它其實是分布在一個低維的空間裡面,只是被扭曲了塞到一個高維空間裡面。
link |
那講到manifold的時候,常常舉的例子就是這個地球,地球的表面就是一個manifold,它是一個二維的平面,但是被塞到了一個三維的空間裡面。
link |
那在一個這樣子的情況下呢,在一個manifold裡面呢,只有這個很近的距離的點,在很近的距離的情況下,Euclidean distance才會成立。
link |
如果今天距離很遠的時候呢,這個歐式幾何呢,它就不一定成立。也就是說,假如我們在這個S型的空間裡面呢,取某一個點放在這邊,那我們用Euclidean distance比較這個點跟這個點之間的距離,比較它跟它之間的距離和它跟它之間的距離,或許這件事情是make sense的,它跟它比較不像,它跟它可像。
link |
但是如果今天是距離比較遠的時候,你要比較這個點跟這個點的相似程度,跟這個點跟這個點的相似程度,你在高維空間中直接算它們的Euclidean distance就變得不make sense了。
link |
因為如果根據Euclidean distance,它跟它比較近,它跟它比較遠,但是實際上呢,很有可能它跟它是比較近的,它跟它是比較像的,它跟它是比較不像。
link |
所以manifold learning要做的事情,是把S型的這一塊東西要把它展開,把塞在高維空間裡面的低維空間呢,攤平。那攤平的好處就是,現在如果我們把這個低維空間攤平以後,我們做降維,然後把這個塞在高維空間裡面的manifold攤平以後,
link |
那我們就可以在這個manifold上面用Euclidean distance來,我們就可以在這個平面上用Euclidean,在降維以後我們就可以用Euclidean distance來計算點和點之間的距離。
link |
這會對接下來如果你要做clustering,或者是你要做接下來的supervised learning,都是會有幫助的。那類似的方法有很多,那我們今天就很快的介紹幾種方法,最後呢,講一下這個TSNE。
link |
TSNE叫做Locally Linear Embedding,這個方法的意思是說,在原來的空間裡面,你的點的分佈是長這個樣子,有某一個點叫做xi,然後我們先選出這個xi的neighbor,然後我們叫做xj。
link |
那接下來呢,我們要找這個xi跟xj的關係,那xi跟xj的關係呢,我們寫做wij,wij代表xi和xj的關係。
link |
這個wij是怎麼找出來的呢?這個wij是這個樣子,我們假設說每一個x呢,每一個xi呢,都是可以用它的neighbor做linear combination以後組合而成。
link |
那這個wij就是拿j去組合i的時候,wij就是拿xj去組合xi的時候的linear combination的weight。
link |
那要找這一組wij怎麼做呢?你就說,我們現在呢,要找一組wij,這組wij對xi的所有neighbor xj做weighted sum的時候,它可以跟xi越接近越好。
link |
或者xi減掉summation over所有的j,wij乘以xj,它的to none呢,是越接近越好,xi跟xj的linear combination,它們是越接近越好,然後summation over所有的data point i。
link |
然後呢,接下來呢,我們就要做dimension reduction,把所有別人來說的xi跟xj轉成zi和zj。但是現在這邊的原則就是,從xi跟xj轉成zi跟zj,它們中間的關係呢,wij呢,是不變的。
link |
這個東西呢,就是那個白居易的《長恨歌》裡面講的這句話。我想,那句話叫做什麼?我想,這一句話是出自《長恨歌》的結尾。
link |
它是:「臨別殷勤重記辭,辭中有事兩心知。七月七日長生殿,夜半無人詩與詩。在天願作比翼鳥,在地願為憐立之。天長地久有時盡此恩,綿綿不盡此。」
link |
並不是我國文特別強。啊,謝謝,謝謝,謝謝,謝謝。這樣子啦,你不要誤會可能是我國文特別強,我國文其實沒有很強。
link |
為什麼會背?其實我可以從頭背到尾。為什麼呢?因為小時候呢,我不知道犯了什麼錯,被老師懲罰,被《長恨歌》這樣子,然後我就整首背起來了。
link |
小時候背的東西只要長大,其實就不會忘。好,那這個是什麼意思呢?所謂的在天就是XI跟XJ在原來的space上面,比翼鳥就是WIJ,在地就是把XI跟XJtransform到另外一個space,就是ZI跟ZJ,憐立之就是比翼鳥就等於憐立之,所以他們的關係還是WIJ。
link |
好,那所以LLE它做的事情是這樣子的。首先WIJ呢,在原來的space上面找完以後,就fix住它,就不要去動它。接下來呢,你為每一個XI跟XJ找另外一個vector,那我們現在要做dimension reduction,
link |
所以你新找的vector要比原來的dimension還要小,原來一百維,你降維以後變得比較少,十維兩維之類的。所以ZI跟ZJ是另外的vector。那我們要找這個ZI跟ZJ,它可以minimize什麼呢?它可以minimize下面這個function。
link |
也就是說,原來這些XJ它可以做linear combination產生XI,這些ZJ它也可以用同樣的linear combination產生ZI,我們就是要找這一組Z可以滿足這個WIJ給我們的constraint。
link |
所以現在呢,在這個式子裡面,WIJ變成是已知的,但是我們要找一組Z讓ZJ透過WIJ做weighted sum以後,它可以跟ZI越接近越好。ZJ用這一組weight做linear combination以後,它可以跟ZI越接近越好,要submission over所有的data points。
link |
好,那這個LLE你要注意一下,其實它並沒有一個明確的function告訴你說我們怎麼做dimension reduction,不像我們在做autoencoder的時候,你認出一個encoder的network,你input一個新的data point,然後你可以找出它dimension的結果。
link |
今天在LLE裡面,你並不會找到一個很明確的function,並沒有一個function告訴我們說怎麼從X變到Z,Z完全就是另外憑空找出來的。
link |
所以其實如果你用LLE或者是其他類似的方法有一個好處,就算是你原來這個XIXJ你不知道,你只知道WIJ,你不知道XIXJ用什麼vector來描述它,你只知道它們的關係,你其實也可以用LLE這種方法。
link |
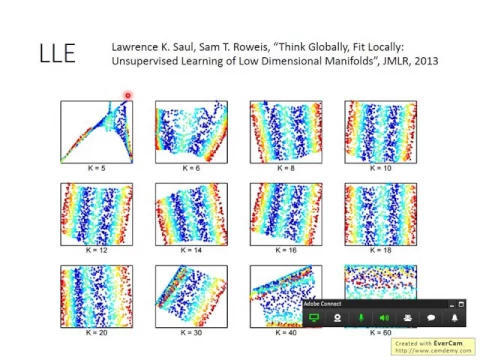
那LLE你其實需要好好的調一下你的neighbor選幾個,你neighbor選的數目要剛剛好才得到好的結果,這邊是從原始的paper裡面截出來的圖。
link |
原始的paper它的題目實在是太潮了,它是think globally, fit locally,很好的一個題目,然後它調了不同的K,如果你今天K太小得出來的結果會不太好,K太大得到的結果也不太好。
link |
為什麼K太大得到的結果不太好呢?因為我們之前的假設就是每一個Euclidean distance只在很近的距離之內可以被這樣想。
link |
所以這個點和點之間的data point和data point之間的關係,在transform前transform後可以被keep住,只有在距離很近的時候才能夠成立。
link |
當你K選很大的時候,你會考慮一些距離很遠的點,你會考慮一些transform以後relation沒有辦法keep住的點,有些關係太弱了transform以後沒有辦法keep住,那它不是比翼鳥或連理子的關係,它太弱了無法keep住,但是你不應該把它考慮進來,所以你K要選一個適當的值。
link |
另外一個方法叫Laplacian的Eigenmap,它的想法是這樣子,我們之前在講semi-supervised learning的時候,我們有講過smoothness的assumption,我們有說如果你想要比較這個點和這個點之間的距離,算它的Euclidean distance是不足夠的。
link |
你要看的是它們在這個high density的region之間的distance,如果兩個點之間它們有high density的connection,它們才是真正的很接近。
link |
那這件事情你可以用一個graph來描述這件事情,也就是說你把你的data pointconstruct成一個graph,你算你的data point兩兩之間的相似度,如果相似度超過一個threshold,就把它們connect起來,而且一個graph的方法有很多,你可以把它擁有很多不同的方法,總之你就把比較近的點把它們連起來變成一個graph。
link |
那你把點變成這個graph以後,你考慮這個smoothness的距離,就可以被這個graph上面的connection來approximate。
link |
那我們之前在講semi-supervised learning的時候,我們是這樣說的,如果今天x1跟x2在high density的region上面,它們是相近的,那它們的label,y1 head和y2 head很有可能是一樣的。
link |
所以在做semi-supervised learning的時候,我們可以這麼做,我們有一項是考慮有label的data的項,有另外一項是跟label data沒有關係的,我們只可以利用unlabel的data。
link |
那這一項的作用呢,它是要考慮說我們現在得到的label是不是smooth的,它的作用很像一個regularization的term。那這個s這一項,它等於yi-yj的距離乘上wij。
link |
也就是說,那個wij是什麼呢?wij是說,如果今天兩個data point,xi跟xj,它們在圖上是相連的,那wij就是它們的相似程度,而如果在圖上是沒有相連的,它就是0。
link |
然後我們說,如果今天wi跟wj它們很相近的話,那wij就有一個很大的值,那你就會希望yi跟yj越接近越好,反之如果wij是0,那yi跟yj要是什麼值呢?就都可以。
link |
那這個s呢,就是evaluate說你現在得到的label有多麼的smooth。那我們還說呢,這個s可以寫成一個y的vector,乘上l再乘上y,這個l呢就是graph的laplacian,那l呢等於d減w,這個大家回去check一下之前的投影片就知道了。
link |
那同樣的道理可以被apply在完全unsupervised的test上面,我們可以說,如果x1跟x2在high density的region它們是close的,那我們就會希望z1跟z2它們也是相近。
link |
所以我們可以一樣把剛才那個smoothness的式子寫出來,我們可以寫說,我這邊可能寫平方可能是比較不好啦,因為我這邊應該寫這個Euclidean distance比較好,或者寫它的這個Qnone distance比較好。
link |
那今天這個把x1跟x2變成z1跟z2以後,你的這個z1z2應該是長什麼樣子呢?
link |
你今天應該是這樣子,如果今天xi跟xj啊,如果這個i跟j這兩個data point它們之間的wij很像,那zi跟zj做完dimensional reduction以後它們的距離就很近。反之呢,如果它們的這個wij很小,那它們距離要怎樣呢?就都可以。
link |
你覺得這樣ok嗎?我們就找一個zi跟zj minimize這個s的值。你不覺得這麼做是有問題的嗎?給大家五秒鐘想想看這個問題出在哪裡。
link |
其實這個問題是這樣,你不需要告訴我wij是什麼,我一秒就可以告訴你說要minimize s的時候,我應該選什麼值,心算就可以得到了。
link |
選什麼值呢?我把所有的zi跟zj統統設一樣的值就好,結束。所有的zi跟zj我統統都設一樣的值,如果統統都設0,那s就等於0。
link |
這個問題就結束了。所以光只有這個式子是不夠的。那你可能說剛才在semi-supervised learning的時候你怎麼不講這句話呢?
link |
之前在semi-supervised learning的時候,我們還有supervised learning,supervised那個label data給我們那一項。
link |
所以如果你把所有的y所有的label都設成一樣的,那你在supervised那一項,你得到的loss就會很大。那我們要同時balancesupervised那一項跟semi-supervised那一項,我們要同時balancesupervised那一項的cost跟regularization的term,
link |
所以你不會選擇讓所有的y統統都是一樣。但在這邊,少了supervised的東西,所以變成選擇所有的z都是一樣,反則是一個最好的solution,所以這件事情是行不通的。
link |
所以怎麼辦呢?你要給你的z一些constraint,什麼樣的constraint呢?會給的constraint是這樣,如果今天z降為以後的空間是n為的空間,比如說n-2之類的,
link |
你不會希望說你的z還分佈在一個比n還要小的dimension裡面,我們現在要做的事情是希望把高維空間中塞進去的低維空間展開。
link |
我們不希望說我們展開以後,其實展開的結果,它在一個更低維的空間裡面。所以今天假如你的z的dimension是n的話,你會希望你找出來的那些點,假設現在總共有n個點,z1到z大n,
link |
他們做span以後會等於Rn,也就是說z它不是活在一個比n為更低維的空間裡面,它就會佔據整個n為的空間。
link |
其實如果你要解這個式子的話,你解一解你就會發現說,你解出來的這個z跟我們前面看到的那個graph Laplacian L是有關係的。它其實就是graph Laplacian的eigenvector,對應到比較小的eigenvalue的那些eigenvector。
link |
這個大家再自己check一下文獻就好了,所以它叫做Laplacian eigenvector,因為我們找的是Laplacian matrix的eigenvector。
link |
如果你今天先找出z以後,你再去做clustering,你先找出z,再用k-means做clustering的話,這一招有一個很潮的名字,叫做Spectral Clustering。
link |
接下來我們就要講TSNE,TSNE它是T-distributed stochastic neighbor embedding的縮寫。TSNE它解決什麼樣的問題呢?前面那些問題,有一個最大的問題就是,它只假設相近的點應該要是接近的。
link |
但它們沒有假設說,不相近的點沒有要接近,它沒有假設說,不相近的點要分開。所以,如果比如說你用Lle在at least上,你會遇到這樣的情形。
link |
它確實會把不同的點,它確實會把不同的顏色代表不同的class,它確實會把不同的class都塞在一起,然後它確實會把同一個class的點都聚集在一起。
link |
但它沒有防止說,不同class的點不要疊成一團。如果它疊成一團的時候,沒有這個顏色,這些點還是擠在一起,還是沒有辦法分開。這是另外一個例子。
link |
這個例子我們做在COIL20上面。COIL是一個image的corpus,它裡面的image就是某一個圖,比如說一個玩具車,然後把它轉一圈,然後拍很多張不同的照片。
link |
這邊同樣的顏色代表同一個object,你會發現說它找到一些圈圈,這個圈圈代表什麼意思呢?這個圈圈代表同一個object在做旋轉的時候,它每一張圖都很像。
link |
但是旋轉的時候,每一張圖都很像,但是你看一個東西的正面和側面,它卻是非常不一樣。所以這個圈圈就顯示,你把某一張圖做旋轉以後,再做dimension reduction以後,你所得到的結果。
link |
但是一樣,你會發現說不同的object,其實它們是擠成一團的,擠成一團的,沒有辦法分開。所以如果做TSNE的話,做TSNE是怎樣呢?做TSNE我們一樣是要做降維,把原來的data point X變成比較low dimension的vector Z。
link |
那在原來的X這個space上面,我們會計算所有的點的pair,Xi和X之間的similarity,這間寫成S of Xi跟Xj。
link |
接下來會做一個normalization,我們會計算一個P of Xi given Xi,這個P of Xi given Xi,它是從Xi跟Xj的similarity來,我們等一下會說這個similarity要怎麼算。
link |
這個P of Xi given Xi就是在分子的地方是Xi跟Xj的similarity,然後分母的地方就是summation over除了Xi以外,所有其他的點和Xi之間所算出來的距離。
link |
所以會發現說Xi對其他所有的data point,它所算出來的這個P of Xi given Xi,它的summation應該要是1。
link |
另外假設我們今天已經找出了一個low dimension的representation,就是Zi跟Zj的話,我們把X變成Z的話,我們也可以計算Zi和Zj之間的similarity,這邊的similarity我們寫成S'.
link |
那一樣你可以計算一個Q of Zj given Zi,它的分子的地方,就是S' of Zi Zj分母的地方,就是summation over Zi跟所有database裡面的data point Zk之間的距離。
link |
那今天有做這個normalization,其實還感覺是必要的,因為如果你又做這個normalization的話,因為你不知道在高額空間中算出來的距離,這個Xi跟Xj跟S' Zi Zj,它們的scale是不是一樣。
link |
如果你今天有做這個normalization,那你最後就可以把它們都變成幾率,那這個時候它們值都會變於在介於0到1之間,它們的scale會是一樣。
link |
那接下來我們要做的事情就是,我們現在還不知道Zi跟Zj它們的值到底是多少,這是我們要被找出來的。
link |
那我們希望找一組Zi跟Zj,它可以讓這一個distribution跟這個distribution越接近越好。
link |
我們要讓原來在根據similarity,在X的原來space上面算出來的distribution跟在dimension reduction以後的space算出來的distribution越接近越好。
link |
那怎麼衡量兩個distribution之間的相似度呢?很直覺地衡量兩個distribution之間的相似度的方法,就是我們之前看到的KL divergence。
link |
所以我們今天要做的事情就是找一組Zi,它可以做到這個Xi的distribution跟Xi對其他point的distribution跟Zi對其他point的distribution,這兩個distribution之間的KL divergence越小越好。
link |
Summation over all data points,你要使得這一項它的值越小越好。然後我把這個值就寫在這邊。
link |
這件事情要怎麼做呢?其實這件事情實際上並沒有很困難,實際上你就是用gradient descent做的。
link |
你想想看,假設你知道這個similarity的matrix,它這個式子長什麼樣子,你知道這個式子長什麼樣子,那你把這些式子帶進去,然後接下來你只要對Zi做微分,然後做gradient descent,就搞定這個問題,就結束了。
link |
今天有一個問題就是你在做TSNE的時候,它會計算所有data point之間的similarity,所以它的運算量有點大,所以TSNE有點麻煩,如果data point比較多的時候,你的電腦會跑不動。
link |
一個常見的做法是你會先做降維,比如說你原來的dimension很大,你不會直接從很高的dimension直接做TSNE,因為你這樣子計算similarity的時間太長,你通常會先用比較快的方法,比如PCA,先用PCA做降維,比如說先降到50維,然後再用TSNE從50維降到2維,這個是比較常見的做法。
link |
其實像我們今天講的這些方法,你會發現說,比如說像TSNE,如果你給它一個新的data point,它是沒辦法做的,對不對?
link |
它只能夠你給它一大群,已經先給它一大堆X,它幫你把每一個X的Zi都找出來,但你找完這些Zi以後,你再給它一個新的X,你要重新跑一遍這一整套演算法,很麻煩。
link |
所以一般TSNE的作用比較不是用在training testing的這種base上面,通常比較常用的做法是拿來做visualization,如果你已經有一大堆的X,它是high dimensional的,那你想要visualize它們在二維空間分布上是什麼樣子,你用TSNE。
link |
TSNE往往可以給你不錯的結果,TSNE現在可能是最多人使用的一種選擇。我們再來要講TSNE一個非常有趣的地方,就是它的similarity的選擇是非常的神妙的。
link |
我們在原來的datapoint space上面,similarity的選擇是選擇RDF的function,就選擇說我們要讓Xi,我們這個evaluate similarity的方式是計算Xi跟Xj的Euclidean distance,然後取一個負號再取exponential。
link |
我們之前有說,如果你要在graph上面算similarity的話,用這種方法比較好,因為它可以確保說只有非常相近的點才有值,那exponential它掉得非常快,所以只要距離一拉開,similarity就會變得很小。
link |
那如果在TSNE之前,有一個方法叫做SNE,就是把前面的T拿掉。SNE就是一個很直覺的想法,在datapoint裡面的space上用這個evaluation的measure,當然在新的space上面你用同樣的measure就好了,選不同的measure,你直覺就選一樣的measure。
link |
TSNE神妙的地方就是,它在dimensional reduction以後的space,它選的measure跟原來的space是不一樣的,它在dimensional reduction以後選的space是T-distribution的其中一種,T-distribution裡面有參數,你可以調它,可以產生很多種不同的distribution。
link |
T-distribution的其中一種,它是1除以1加Euclidean distance的平方。
link |
你可能問說,為什麼要這樣做呢?我可以提供一個很直覺的理由,假設橫軸代表了在原來space上的Euclidean distance,或者是做dimensional reduction以後的Euclidean distance。
link |
紅色這條線是這一項,藍色這條線是這一項,紅色這條線是RBF function,藍色這條線是T-distribution。
link |
你會發現說,如果原來在這個點跟這個點之後做dimensional reduction以後,要怎麼才能維持它原來的space呢?
link |
你就把它變成這個樣子,它就可以維持它原來的space。如果你要維持它們原來之間的距離,如果你今天要維持它們原來的機率的話,要維持原來它們之間相對的關係的話,你就把它變成這樣。
link |
你會發現說,如果本來距離比較近,它們的影響是比較小的。如果本來就已經有一段距離,那從原來的這個distribution變到T-distribution以後,它會被拉得很遠。
link |
T-distribution它的尾巴特別長,所以如果你本來距離比較遠的話,變到T-distribution以上以後,它會變得更遠。也就是說,原來在高額空間裡面,如果距離很近,那做完transform以後,它還是很近。
link |
如果原來就已經有一段距離,有一個gap,那做完transform以後,它就會被拉得很遠。所以你會發現說,TSNE它畫出來的圖往往長得像這樣。它會把你的data point聚集成一群一群一群。
link |
因為你的data point之間本來只要有一個gap,做完TSNE以後,它就會把那個gap強化,那個gap就會變得特別明顯。所以這是TSNE做在anist上面的結果。其實這個不是直接做在anist的pixel上面,直接做在pixel上面的performance看起來沒有這麼好。
link |
TSNE是先做PCA降位以後,再做在anist上面。不同顏色代表的是不同的數字,那你會發現不同的數字會變成一群一群的。
link |
TSNE在col20上的結果其實還蠻驚人的。這邊的每一個圈圈就代表了一個object,就代表了同一個object,然後它只是轉了一圈以後的結果。你會發現這邊有一些被扭曲的圈圈。扭曲的圈圈是什麼意思呢?
link |
TSNE有一些東西,比如說杯子,它這個面長這樣,它轉180度轉過來以後,它還是長得一模一樣。所以你把那個杯子轉360度轉一圈的時候,你就會發現說它在中間某一個地方是很像的image,所以你會看到說這邊有很多看起來像8的符號。
link |
這邊這很多條線,其實好像是說有四部都是小汽車,四部小汽車看起來是蠻像的,所以這邊有四條線是被align在一起的。
link |
這邊有一個從網路上找到TSNE的動畫,它長得是這個樣子。因為它是用Gradient Descent Train的,所以你會看到隨著iteration的process點會被分得越來越開,點會被分得越來越開。
link |
然後不同的點之間,假如這個是做,這個其實不是做在endless,是做在另外一個手寫數字辨識的code上面,你會發現說不同的digit之間,它是會被分得很開的。
link |
好,這個TSNE的地方,我們就講到這邊。