back to index
ML Lecture 16: Unsupervised Learning - Auto-encoder
link |
好,接下來呢,我們要來講這個DeepAutoEncoder,那什麼是AutoEncoder呢?
link |
AutoEncoder的想法是這樣,我們首先去找一個Encoder,那這個Encoder呢,你可以input一個東西,
link |
比如說我們這邊要做的是影像辨識的話,你要做的是跟影像有關的東西的話,就input一張,
link |
假如我們要做inlist的話,就input一張digit,它是784位的vector。那接下來呢,這一個Encoder,它可能就是一個neural network,
link |
它的output呢,就是一個code,那這個code通常是遠比784位還要小的,所以它會有類似壓縮的效果。
link |
這個code呢,代表了原來input這張image的某種compact的某種精簡的有效的representation。
link |
但是現在問題是這樣子,我們現在做的是unsupervised learning,你可以找到一大堆的image當作這個Encoder的input,
link |
但是我們沒有任何的output,我們並不知道說一個image,如果你把它變成一個code,這個code到底應該要長什麼樣子。
link |
那你要run一個network,你要有input output啊,只有input,你沒辦法run它。那沒有關係,我們先想說我們要做另外一件事情,我們想要run一個decoder。
link |
所以decoder它做的事情是說,input一個vector,它就通過這個decoder,它也是一個nn,它的output呢,就是一張image,input給它一個code,
link |
它output呢,就根據這個code裡面的information,output呢,就是一張image。
link |
接下來呢,你也沒有辦法trainnn的decoder,你也沒辦法train它,因為你只有這個network的output,你沒有它的input。
link |
這兩個network,encoder和decoder單獨一個人呢,你都無法train它,但是我們可以把它接起來,然後一起train。
link |
也就是說呢,我們接一個neural network,input一個image,中間變成code,再把code通過decoder變成原來的image,
link |
你就可以把這個encoder和decoder呢,一起學,那你就可以同時把encoder和decoder呢,學出來了。
link |
那我們剛才在PCA裡面呢,其實看過非常類似的概念,我們來看一下,先從剛才講過的PCA開始講起。
link |
我們剛才講過說,PCA啊,實際上它在做的事情是這樣,input一張image x,那我們在剛才我們的例子裡面,我們會把x減掉它的平均x bar當作input,
link |
但是這個減掉x bar,並不總是,這邊我們把它省略掉,那把它省略掉並不會太奇怪,因為通常你在做NN的時候呢,你拿到data起手是你就先做normalize,
link |
你先把它變成min是0,variance是1,所以你的data呢,通常min呢,其實就是0的,所以你就不用再減掉min了。
link |
好,那你把x呢,乘上一個weight,乘上一個weight,通過NN的一個layer,得到呢,你的這個component的weight,我們這邊呢,寫成c。
link |
那這個component的weight呢,再乘上呢,一個matrix呢,w的transpose,得到x的hat,那這個x的hat呢,是根據這些component的reconstruction,根據這些component的weight,還有那component呢,就放在這個weight裡面,根據component的weight和component呢,做reconstruction的結果。
link |
我們說在PCA裡面,我們要做的事情,就是minimize input跟reconstruction的結果,我們要讓x跟x hat,它的這個有clear distance呢,越近越好,然後x跟x hat呢,它們越接近越好。
link |
這個是PCA做的事,如果把它當成neural network來看的話,那input的x就是input layer,output的x hat就是output layer,中間component的weight就是hidden layer,在PCA裡面,它是linear。
link |
那這個hidden layer呢,中間這個hidden layer,我們通常要叫它bottleneck layer,為什麼叫bottleneck layer呢,因為你的這個code的數目嘛,因為你現在就是要做dimension reduction嘛,所以你的這個component的數目呢,通常會比你的input的dimension還要小得多,這樣才會達到dimension reduction的效果。
link |
所以,如果把它當成一個layer來看的話,它是一個特別窄的layer,所以我們叫它bottleneck layer,它就是一個瓶頸的意思。
link |
前面這個部分就是在做decode,把input變成一組code,後面這個部分就是在做decode,你如果把component的weight想成code的話呢,後面這件事情就是把code變回原來的image。那hidden layer的output就是我們要找的那些code。
link |
那PCA是這麼做的,那你其實也可以用gradient descent來解PCA,但PCA只有一個hidden layer,你就可以想說,我們要不要把它變成更多hidden layer,當然可以把它變成更多hidden layer,你就逗一個很深的neural network,它有很多很多層。
link |
然後呢,在這個很多很多層neural network裡面呢,你input一個x,那你會,它最後得到的output呢,是x hat,那你會希望呢,你training的target呢,就是希望這個x呢,跟x hat呢,越接近越好,越接近越好。
link |
那training的方法完全沒有什麼特別的,就是back propagation,就跟我們之前在neural network的時候講的呢,是完全一模一樣的東西,那中間呢,你會有一個特別窄的layer,這個特別窄的layer,它有特別少的neural,那些neural的output,這個layer的output呢,就代表了一組code。
link |
那從input到這個bottlenecklayer的部分呢,就是encoder,那從bottlenecklayer的output到最後的x hat,到最後整個neural的output,就是你的decoder,所以你把input做encoder變成bottlenecklayer的output,再把bottlenecklayer的output呢,做decode,變回原來的image,這個就是decode。
link |
那其實呢,這個deep的autoencoder啊,我覺得最早是出現在06年的Hinton的science的paper,然後那個時候,其實deep autoencoder沒有那麼好train,你有可能train一train以後呢,結果就壞掉,那個時候需要用RBM呢,做layerwise的initialization,然後呢,才可能把deep autoencoder呢,train得比較好一點。
link |
好,那如果是按照我們剛才在PCA裡面看到的,這個從input到第一個hiddenlayer的這個weight w1,好像應該要跟最後一個hiddenlayer的output,跟outputlayer中間的這個weight呢,互為transpose,最後一個,這個layer是weight w1,這個layer好像應該是w1transpose,這個是w2,這個好像應該是w2transpose。
link |
那你在training的時候,你可以做到這件事情,你可以把這邊的weight跟這邊的weighttie起來,讓他們在做training的時候,永遠保持他們的值呢,是一樣的,你可以做到這件事情,你可以做到這件事情,做這件事情的好處呢,是你現在的autoencoder它的參數呢,就少一半,它就比較不會呢,有overfitting的情形。
link |
但是這件事情呢,並不是必要的,沒有什麼理由說,這邊的weight跟這邊的weight一定要互為transpose,所以現在常見的做法呢,就是double neural network,然後用backpropagation呢,直接train下去,那管他train出來的weight是什麼,就是你得到的結果。
link |
好,那這邊呢,是從Hinton06年的這個science的paper上面呢,截出一些那時候看起來呢,相當驚人的結果,現在是覺得還好,因為現在誰都順手就可以reproduce這些結果,那時候是覺得是相當驚人的。
link |
好,那這個是這樣子的,如果我們今天,這是原來的image,在at least上面,它長這個樣子,如果你做PCA,把它從784微降到30微,然後再從30微呢,reconstruct回784微,那你得到的image呢,是這個樣子,你可以看出說,它是比較模糊的,它是有一點霧霧的感覺。
link |
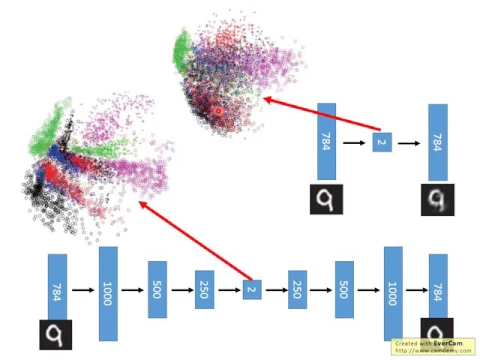
那如果你今天是用deep autoencoder的話,在Hinton的那個paper裡面呢,它是這麼做的,784微先擴展成1000微,再把1000微降成500微,再把500微降成250微,再降到30微,你很難知道說為什麼它設計這個樣子,然後再把30微呢,變成250微,500微,100微,然後再把它解回來,然後再把它解回來。
link |
那你會發現說,如果你今天用的是deep autoencoder的話呢,它的結果呢,看起來呢,就非常的好,它的結果呢,看起來就非常的好。
link |
那如果你今天呢,不是把它降到30微,而是把它降到2微的話,你把它降到2微,再去visualize它的話,你會發現,如果你是做PCA的話,在這個2微的平面上,所有的digit呢,它是被混在一起的,這邊不同顏色呢,就代表了不同的數字。
link |
你會發現,如果今天呢,是用PCA把它分配到2微的話,所有的數字呢,它是混在一起的。如果你是用deep autoencoder的話呢,你會發現說,這些數字呢,是分開的,你可以輕易看到說呢,不同的數字呢,會變成一群一群的。
link |
那現在呢,你其實可以很輕易的reproduce這樣子的結果。好,那其實我後來又做了一個無聊的事情,我沒有看到什麼特別的東西,就是把寶可夢的data又做了一下,用一個hidden layer的autoencoder呢,硬做了一發,但是我沒有看到什麼特別的東西。
link |
好,那這個autoencoder呢,也可以把它用在這個文字處理上。如果把它用在文字處理上的話,像是怎樣呢?比如說我們會想要把一篇文章壓成一個vector,壓成一個code。那為什麼我們會想要把一篇文章壓成一個code呢?
link |
舉例來說,假設我們現在要做文字的搜尋。那在文字搜尋裡面呢,有一招你可能都聽過,叫做vector space model。那這個vector space model它非常的單純,它就是說,我們現在呢,把每一篇文章都表示成一個空間中的一個vector,都是空間中的一個點。
link |
所以這個圖上每一個藍色的圈圈呢,就是一篇文章。那接下來呢,我們也把假設使用者輸入一個查詢的詞彙,那我們把那個查詢的詞彙也變成空間中的一個點。
link |
接下來呢,你就是計算這個輸入的查詢詞彙,跟每一篇文章它們之間的inner product,inner product,或者是cosine similarity等等,而不是說cosine similarity會有normalize的效果,你可能會得到比較好的結果,可以做cosine similarity等等。
link |
那如果距離最近,cosine similarity的結果最大,那你就會retrieve這些document,比如說如果你輸入紅色這個query的話,你可能就會retrieve這一篇document跟這一篇document,因為它們跟紅色這個query的cosine similarity是比較大的。
link |
那這個模型要work,就depend你現在把一個document變成一個vector,你表示的好呢,還是表示的不好。假設你今天做的是,要怎麼把一個document表示成一個vector呢?就trivial的方法叫做back of word。
link |
這個back of word的想法是說,我們現在就開一個vector,這個vector的size就是lexicon的size,假設你今天世界上有十萬個詞彙,這個vector的size就是十萬維。
link |
那假設現在有一篇document,它只有一個句子,就是list as an apple,那這個document呢,如果把它表示成一個vector的話呢,就是在list那一維是1,is那一維是1,at那一維是1,apple那一維是1,其他都是0。
link |
就這樣子,這個沒有什麼特別好講的。那有時候你會想要把它做得更好,你會把它乘上這個inverse document frequency,你每一維呢,不只會用那一個詞彙呢,在這個document裡面出現的次數,你會把它再乘上一個weight,代表那一個詞彙的重要性,那這個重要性呢,你可以用不同的方法衡量它,比如說用inverse document frequency來衡量它。
link |
所以比舉例來說,is,它可能在每一篇document都有出現,所以它重要性很低,所以1呢,就會乘上一個比較小的字,apple,只有在某些document有出現,比較重要性比較高,所以它就會被乘上一個比較大的字,等等。
link |
但是呢,用這個模型,它很weak,它沒有辦法考慮任何semantic相關的東西,它沒有辦法考慮任何語意相關的東西,比如說它會不知道說台灣大學指的就是台大,它會不知道說apple跟orange都是水果,等等,它沒有辦法知道這些事情。
link |
對它來說,每一個詞彙都是independent,對它來說,apple跟pan,apple跟and,apple跟is,就是不同的詞彙,它們中間是完全沒有任何相關性的。
link |
那我們可以用autoencoder,讓語意這件事情被考慮進來。舉例來說,你認一個autoencoder,它的input就是一個document,或者是一個query,就是一段文字,那這個在Hinton的science paper上面是有實驗的,那它只有用比較小的less than size,就只有2000個詞彙,反正一個document,你就把它變成一個vector。
link |
那你把這個vector通過一個encoder,然後把它壓成二維,那在這個Hinton的paper上,你會看到它的結果是這個樣子,我記得它做的是Funding News Group的那個Compass,在這個Compass裡面,document會有標說它是屬於哪一類,這邊不同顏色的點,每一個點代表一篇document,不同顏色的點就代表說這篇document屬於哪一類。
link |
那其實我們在作業室就是要做類似的事情,希望你可以得到一樣漂亮的圖案,你會發現說同一類的document就都集中在一起,散佈就像一朵花一樣,所以如果你今天要做搜尋的時候,今天輸入一個詞彙,今天輸入一個查詢詞,那你就把那個query也通過這個encoder把它變成一個二維的vector。
link |
假設那個query落在這邊,你就可以知道說這個query這個字是energy market,它是跟energy market有關的,那就把這邊的documentretrieve出來,所以這個autoencoder在這邊看起來結果是相當驚人的。
link |
如果你用LSA的話,你得不到類似的結果,如果你用LSA的話,你會發現說,我們剛才有講LSA,就是建一個matrix,然後你可以找每一個詞彙跟每一個document它背後的latent vector,一樣假設我們用LSA,然後每個document用二維的latent vector來表示它,那你得到的結果看起來像是這個樣子,看起來像是這個樣子。
link |
那這個autoencoder也會用在image的搜尋上面,你可以說怎麼做,就做在以圖找圖上面,那怎麼做以圖找圖呢?最簡單的方法就是拿一張,假設這個是你要找的對象,假設這是你的image的query,
link |
你去計算這個image的query跟其他你的database裡面的image它的相似程度,你可以算它們在pixel上面的相似程度,然後你再看說最像的幾張就是要retrieve的結果。
link |
如果你只是這麼做的話,你其實得不到太好的結果,你得到的結果,假設這個是你的query,這個是Michael Jackson的Michael Jackson,那如果你拿這一張image去跟其他database的image算相似度的話,你找出來最像的大概是這幾張。
link |
你會發現說Michael Jackson他跟這個馬蹄鐵是很像的,這個是很像,這個說實在也是很像。所以如果只是這麼做,在pixel上面做比較,你找不到好的結果了,那怎麼辦?
link |
你可以用deep autoencoder,把每一張image變成一個code,然後在code上面再去做搜尋。
link |
而且因為今天做這件事情是unsupervised的,認一個autoencoder是unsupervised的,所以你要collect多少data都行,懂嗎?你就可以collect很多很多很多的data,你要collect多少data都行,這種autoencoder的data是永遠不缺的,不像你做supervised learning的時候你是很缺data,但做unsupervised learning的時候你是不缺data。
link |
那現在怎麼把它變成一個code呢?這個也是從inton的paper上來的,他說input一個32x32的image,其實每一個pixel用rgbi標示,所以32x32x3,然後把這個image變成8192位,再變成4096位,再變成2048位,2052位到256位。
link |
也就是說這張image你用一個256位的vector來描述它,然後你再把這個code通過另外一個decoder,只是它的形狀跟這個東西一樣,只是是反過來的,那你會變回原來的image。
link |
得到的結果呢,它的reconstruction結果是這樣,它是可以reconstruct回來的。如果你不是在pixel上面算相似度,而你是在這種code上面算相似度的話,你就會得到比較好的結果。
link |
比如來說,如果是用Michael Jackson當作input的話呢,你其實就找到的都是人臉。雖然這些image可能在pixel的level上面看起來是不像,但是你通過很多個hidden layer把它轉成code的時候,在那個256位的空間上,它們看起來是不像的。
link |
比如說這個是黑頭髮,這個是金頭髮,看起來其實沒有那麼像,但是通過很多個轉換以後,可能在那個256位裡面,有某一個dimension就代表人臉。
link |
所以它們都知道說,這些image都對應到人臉那一個customer。那AutoEncoder在過去有一個很好的application呢,是可以用在pre-training上面。
link |
大家都知道說,你在train一個neural network的時候,你有時候很煩惱說,你要怎麼做參數的initialization。那有沒有一些方法呢,讓你找到一組比較好的initialization?
link |
找比較好的initialization的方法呢,就叫做pre-training。那你可以用AutoEncoder來做pre-training。怎麼做呢?假設我現在要做,比如說,init recognition。
link |
那我可以說,我dog a network,它是7、8,input 7、8、4位,第一個hidden layer,1000,第二個hidden layer,1000,第三個hidden layer,500,然後到10位,這樣子。好,那我在做pre-training的時候,我就先train一個AutoEncoder。
link |
它input 7、8、4位,然後中間有個1000位的vector,然後再把它變回7、8、4位,那我希望input跟output越接近越好。
link |
但是在做這件事情的時候,其實你是需要稍微小心一點的,因為我們一般在做AutoEncoder的時候,你會希望你的code比那個dimension還要小,對不對?那如果比dimension還要大的話,會遇到什麼問題呢?
link |
你會遇到說,它就不認了,它要recontract,它就只要把784位止住,放到這1000位裡面去,然後再解回來,就結束了。它會就啥都沒認到,認一個identity,接近identity的metric。那所以你要很小心,如果你今天你發現你的hidden layer是比你的input還要大的時候,你的code是比input還要大的時候,你要加一個很強的regularization在這個1000位上。
link |
所謂的很強的regularization是說,你可以對這1000位的output做比如說L1的regularization,你會希望說這1000位的output是sparse的,就這1000位裡面可能只有某幾位是可以有值的,其他位都必須要是0。
link |
這樣你就可以避免說autoencoder直接把input硬背起來再輸出的這種問題。總之如果你今天你的code是比input還要大的,你要注意一下這種問題。
link |
好,那我們現在先認了一個autoencoder,認好以後,我們把從724位到1000位的weight w1把它保留下來,然後把它fix住。
link |
接下來你就把所有你的database裡面的digit通通變成1000位的vector,接下來你再認另外一個autoencoder,它把1000位的vector變成1000位的code,再把1000位的code轉回1000位的vector。
link |
你再認一個這樣的autoencoder,然後它是會讓input跟output越接近越好的,然後你再把w2把它保存下來。
link |
接下來你fix住w2的值,再認第三個autoencoder,這第三個autoencoder,input1000位,code500位,output1000位,認好這個autoencoder,得到它的weight w3,那你再把w3保留下來。
link |
接下來,這個w1,w2,w3就等於是你在認你整個neural network的時候的initialization,然後你最後在random initialize最後500到100的weight,再用band propagation去調一遍。
link |
有時候我們稱這個步驟叫fine-tune,因為可能w1,w2,w3都已經是很好的weight了,你只是微調它,所以我們有時候把它叫fine-tune。
link |
這邊重複了一遍,你把它的值調一下,那你就可以認好這樣的neural network了。這一招pre-training在過去,如果你要認一個很deep的neural network的話,可能是需要的。
link |
不過現在基本上neural network不用pre-training,基本上現在training的技術進步以後,不用pre-training往往都會train得起來。但是pre-training的妙用就是,如果你今天有很多的unlabeled data,只有少量的unlabeled data,你可以用大量的unlabeled data去把w1,w2,w3先認好,先initialize好,那你最後的unlabeled data就只需要稍微調整你的weight就好。
link |
所以pre-training這招在你有大量的unlabeled data的時候還是有用的。
link |
那有一個方法可以讓autoencoder做得更好,這個叫做denoising的autoencoder,那我把reference列在下面給大家參考。
link |
那它的概念其實很簡單的,你把原來的input x加上一些noise變成x',然後你把x' encode以後變成你的code c,再把c decode回來變成y。
link |
但是要注意一下,我們現在的y,本來我們在做一般的autoencoder的時候,你是要讓input跟output越接近越好,但是現在在denoising autoencoder,你是要讓output跟原來的input,在加了noise之前的input越接近越好。
link |
那如果你有做這件事情的話,你認出來的結果會比較robust,因為你可以想像說很直覺的解釋就是encoder現在不只認到了encode這件事,它還認到了它可以把雜訊濾掉這件事情。
link |
那還有另外一招叫做contractive autoencoder,這邊就沒有要細講,那contractive autoencoder它做的事情是這樣子,它會希望說我們在認這個code的時候,我們加上一個constraint。
link |
這個constraint是什麼呢?這個constraint是說當input有變化的時候,對這個code的影響是被minimize的。這件事情其實很像denoising autoencoder,只是從不同的角度來看。
link |
denoising autoencoder是說我加了noise以後,你還要contract原來沒有noise的結果。那uncontractive autoencoder是說我們希望說當input變了,也就是加了noise以後,對這個code的影響是小的。
link |
他們做的事情其實是蠻類似的。那其實還有很多nonlinear dimension reduction的方法,比如說一個是restricted Boltzmann machine,其實我們這邊就沒有打算要講restricted Boltzmann machine。
link |
restricted Boltzmann machine看起來很像neural network,但它其實不是,有很多人都用neural network來想它,你就看這個文件怎麼看都是一頭霧水,因為它不是neural network。
link |
那還有另外一個東西叫做deep belief network,那deep belief network聽起來很像一個deep neural network。
link |
這邊問一下大家的意見,你覺得deep belief network跟deep neural network是一樣的東西嗎?你覺得是一樣的東西的同學舉手。
link |
你覺得它是不一樣的東西的同學舉手,手放下,大家都知道它是不一樣的東西,沒錯,這是很正確的概念,它們只是顏值相而已,然後看起來的架構,有人看那個paper,乍看之下你也會覺得說是不是一樣的東西,但實際上它們是不一樣的東西。
link |
這deep belief network還有restricted Boltzmann machine,它們是graphical model,它們只是看起來很像neural network,你把它的概念直接套用到neural network上,你讀文件會卡到不行。但是我們就沒有打算,還沒有要講graphical model這個部分,我們就沒有辦法細講,但是就留一些reference在這邊給大家參考。
link |
再來我們講一下CNN的auto encoder,如果我們今天要處理的對象是image的話,我們都知道說你會用CNN,那在image裡面,在CNN裡面,在處理image的時候,你會有一些convolution的layer,你會有pooling的layer,用convolution和pooling交替,然後讓image變得越來越小,最後去做flatten。
link |
那今天如果是做auto encoder的話,你不只要有一個encoder,你還要有一個decoder。那如果encoder的部分是做convolution再做pooling,做convolution再做pooling,理論上decoder應該就是做跟encode相反的事情,對不對?
link |
就是decode的時候你應該就是做,你做完這些process,你又得到一個code,接下來你應該就做反過來的事情,本來有一個pooling,你就做unpooling,本來有convolution,你就做deconvolution。
link |
但是這個unpooling跟deconvolution到底是什麼呢?training的規則是一樣的,就是讓input和output越接近越好。但是這個convolution跟deconvolution,他們是什麼呢?
link |
我們來看一下這個unpooling的部分。我們知道說在做pooling的時候,我們現在得到一個4乘以4的matrix,接下來你把這個matrix裡面的pixel分組,四個一組,四個一組,四個一組,四個一組。
link |
接下來從每一組裡面挑一個最大的,比如說在這個例子裡面你挑了這個東西,挑了這個東西,挑了這個東西,挑了這個東西,然後你的image就變成原來的四分之一。
link |
但是如果今天你要做的是unpooling的話,pooling是這麼做的,但如果你要做unpooling的話,你會做另外一件事情,就是你會先記得說我剛才做pooling的時候,我是從哪裡取值的。
link |
我在這個例子裡面,我是從左上角,左上邊的四個方塊我從左上角取值,所以這邊就是白的。這四個方塊我從右下角取值,所以這邊右下角就有個紀錄。我從這個地方取值,這邊有個紀錄,我從這個地方取值,這邊有個紀錄。
link |
你要記得說你是從哪裡取值的。接下來如果你要做unpooling的時候,你要做unpooling的時候,你要把原來比較小的matrix擴大,比如說原來做pooling的時候是比較大的matrix變成原來的四分之一,
link |
而且要把比較小的matrix變成原來的四倍。那怎麼做呢?這個時候你之前記錄的pooling的位置就可以派上用場。你之前記得說你在pooling的時候,是從左上角擴值。
link |
那現在你在做unpooling的時候,就把這個值放到左上角,其他都補0。你記得在這裡取值,你就把這個值放到右下角,其他補0。這裡取值,你就把這個值放到這裡,然後這邊補0。這裡取值,你就把這個值放到這邊,其他補0。
link |
這個就是unpooling的其中一種方式。所以做完unpooling以後,本來比較小的image會變得比較大。比如說原來14乘以14的image會變成28乘以28的image。
link |
而你會發現說,它就是把原來14乘以14的image做一下擴散。有一些地方,藍色的就是補0。每一個原來在14乘以14的image裡面的值,擴散到28乘以28裡面,它都會加上三個0。
link |
那其實這個不是unpooling唯一的做法。在Keras裡面它的做法是不一樣的。就我所知,在Keras裡面的做法,它是直接repeat那些value。也就是你不用去記說之前pooling的位置。
link |
你就直接把這個值複製四份。你就把每一個值複製四份,複製四份,複製四份,就行了。就我所知,Keras裡面是這麼做的。接下來比較難理解的地方,叫做deconvolution。
link |
原來convolution已經很難懂了。deconvolution到底是什麼呢?大家很難搞清楚它是什麼。事實上,deconvolution就是convolution。這樣大家知道我的意思嗎?
link |
如果你看Keras的code的話,在作業3裡面不是有一個連結叫做怎麼做convolution的嗎?不知道怎麼回事,大家好像都有做的樣子。雖然我還沒有講,但大家都有做。那你會發現,你看那個code,根本就沒有什麼deconvolution這種東西。
link |
它就是做convolution,它在做decode的地方就是在做convolution。這到底是怎麼回事?我們不是本來應該是做一個convolution的相反,叫deconvolution嗎?那怎麼又是在做convolution?其實deconvolution就是convolution。
link |
我們來解釋一下這件事情。所以有人說deconvolution的名字取得不好,會讓大家覺得相當困惑。我們舉一維的convolution,就是說我們平常做image的時候是二維的,可是圖畫有點累,所以我們舉一維的當作0。
link |
一維的convolution是怎麼樣呢?我們假設input有五個dimension,然後我們的filter size是3,那我們就把input的這三個value分別乘上紅色、藍色跟綠色的位置,得到一個output。
link |
再把這個filter shift的一個,把這三個value分別乘上紅色、藍色、綠色的位置,得到下一個output。再shift的一個,乘上紅色、藍色、綠色的位置,再得到一個output。這個是convolution。
link |
deconvolution到底應該怎麼樣呢?你的想像可能會是這個樣子的。deconvolution就是convolution的相反。所以本來是三個值變成一個值。
link |
那在做deconvolution的時候,你就應該是一個值變成三個值。然後我發現這邊動畫有一個錯,這個圈圈不應該出現。請無視它。
link |
所以你現在應該是一個值變成三個值。所以怎麼做呢?你的想像是這樣,一個值分別乘上紅色、藍色、綠色的位置變成三個值。這個值也乘上紅色、綠色、藍色的位置變成三個值。
link |
因為它已經有貢獻在這邊一些值了,那它也要貢獻在這邊一些值怎麼辦呢?就加起來。它產生三個值,它也產生三個值,重疊的地方就加起來。
link |
然後它也產生三個值,重疊的地方就加起來。事實上,這件事情等同於是在做convolution。為什麼呢?
link |
它等同於是把我們input就是三個value,然後我們會把它做padding,在旁邊的補力,把它補力。接下來,我們一樣做convolution。
link |
接下來做convolution的時候,三個input乘上綠色、藍色、紅色的位置得到一個值。三個input乘上綠色、藍色、紅色的位置得到一個值。以此類推。
link |
我們做的事情是一模一樣的。怎麼說呢?我們檢查中間這個值,它是三個value加起來。這三個value分別是它乘上綠色、它乘上藍色、它乘上紅色再加起來。
link |
這邊這個value值也是它乘上綠色、它乘上藍色、它乘上紅色再加起來。所以這件事情跟這件事情是一樣的。你檢查這邊的1、2、3、4、5五個值,跟這邊的1、2、3、4、5五個值,它們是一樣的。
link |
如果你把這個deconvolution跟這個convolution做比較的話,它們不同點在哪裡?不同點是在它們的weight是相反的。它這邊是紅、藍、綠,它這邊是綠、藍、紅,是正好相反。
link |
但是它做的operation一樣也就是convolution這件事情。你把這個input做padding然後再做convolution,其實就等於是deconvolution。所以就發現說在Keras裡面,你根本就不需要另外寫一個deconvolution的layer,你直接call一個convolution的layer就可以了。
link |
我本來想要講sequence的autoencoder,不過這我們可以等到RNN的時候再講。我們知道說,剛才我們看到的autoencoder,它的input通通都是fixed length的vector,都是一個vector。
link |
但很多東西intrinsically,很多東西本質上你不該把它表示成vector。什麼東西比如語音,一段聲音訊號,它有長有短,它不是一個vector。一段文章,有長有短,它不是一個vector。你雖然可以用back of word把它變成一個vector,但那個方法你會失去詞彙和詞彙之間的前後關係,是不好的。
link |
所以我們剛才已經講了dimension reduction。我們剛才都是用encoder來把原來的image變成小的dimension。
link |
但是我們同時也churn了一個decoder不是嗎?那個decoder其實是一個妙用的,你可以拿那個decoder來產生新的image。你就是說,我們把那個length好的decoder拿出來,然後你給它一個random的input number,它的output希望就是一張圖。
link |
這件事可以做到嗎?其實這件事情做起來其實是相當容易的。我就胡亂拿那個endness來秒churn一下,然後我把每一張image,七八四維的image,通過一個hidden layer,然後把它project到二維,再把二維通過一個hidden layer,再解回原來的image。
link |
那在encoder的部分,那個二維的vector畫出來呢,長這樣,跟hidden那個圖其實是有一些像的,那不同顏色的點代表不同的數字,畫出來是這個樣子。
link |
然後接下來呢,我在紅色的這個框框裡面呢,等間隔的去sample一個二維的vector出來,然後把那個二維的vector丟到nn的decoder裡面,然後叫它output一個image出來。
link |
它不見得是某個image compress以後的結果,它不見得原來有對應一個image,它就是某個二維的vector,然後丟到decoder裡面,那看看它可以產生什麼。發現說我們在這個紅色的框框內,等距離的做sample。
link |
我們得到的結果就是這樣,你就可以發現很多有趣的現象,你看從下到上,感覺是圓圈,然後慢慢的就垮了。
link |
這邊原本是不知道是4還是9,然後變8,然後它越來越細就變成1,然後不知道為什麼變成2,還蠻有趣的。
link |
這邊感覺比較差,為什麼呢?因為在這邊其實是沒有image的,image的時候其實不會對到這邊,所以這個區域呢,可能這個區域的vector你sample出來,通過decoder以後它解回來不是一個image,它看起來是一個有點怪怪的東西。
link |
那有人可能會說,你怎麼知道要sample在這個地方?因為我必須要先觀察一下那個二維的vector的分布,才能知道說哪邊是有值的,才知道說從那個地方sample出來比較有可能是一個image。
link |
如果我sample在這個地方,我相信我得到的東西可能就不是,看起來就不像image。可是這樣子你要先分析一下二維的code,感覺有點麻煩,那怎麼辦呢?
link |
怎麼讓它確保說在我們希望的region裡面都是image呢?有一個很簡單的做法,就是在你的code上面加regularization,我在code上面直接加L2的regularization,
link |
讓所有的code都比較接近零,接下來在sample的時候就在零附近sample,你就可以比較有可能你sample出來的vector都可以對應到數字。
link |
所以我就做了這樣的事情,我在train的時候加上L2的regularization在code上面,所以train出來,你的code都會集中在接近零的地方,它就會以零為核心,然後分布在接近零的地方。
link |
接下來我就以零為中心,然後等據在這個紅框內的sample image,你看sample出來就是這個樣子。
link |
從這邊你就可以觀察到很多有趣的現象,你會發現說這個dimension跟這個dimension是有意義的,從左到右,橫軸代表的是有沒有一個圈圈,本來是很圓的圈圈,然後接下來就慢慢變成1。
link |
重的呢,我覺得重的就是本來是正的,然後慢慢就倒了,在這邊也是本來是正的,往上面是正的,然後慢慢就倒了。
link |
所以你可以不只是做encode,你還可以用code來畫一個image,那這個image並不是從原來的image的database裡面sample出來的,它是machine自己畫出來的。
link |
那我們就在這邊休息十分鐘,等一下來講一下作業室。