back to index
ML Lecture 18: Unsupervised Learning - Deep Generative Model (Part II)
link |
題目很黃,我也不知道為什麼,就是了,好,好,沒關係,那,呃,好,那我們上次呢,講了這個,呃,叫做Generation這件事情,然後呢,呃,可以用Pixel RNN來做,然後這邊呢,Create了一個這個Generative的Task。
link |
然後呢,上次還講了VAE,但沒有講太多它的原理,那我們來複習一下VAE做的事情,那Autoencoder我想大家都很熟悉了,那VAE做的事情是什麼呢?VAE做的事情啊,是說,呃,你有,你一樣有一個Encoder,一樣有一個Decoder,那你現在呢,Decoder呢,會Output兩組Vector,好,這邊是一組是M1到M3,另外一組是Sigma1呢,到Sigma3。
link |
那接下來呢,你會Generate一個Normal Distribution,那這個Normal Distribution,你會Generate一個Vector,這個Vector呢,是從一個Normal Distribution的Sample出來的,那接下來呢,你把Sigma這個Vector呢,去Exponential,然後呢,再乘上呢,Random Sample出來的這個Vector,再加上原來M這個Vector,得到你的Code的C,把那Code呢,丟進Decoder裡面,產生Image,那你希望說,Input跟Output越接近越好。
link |
另外Auto Encoder,還有另外一項Control,那不幸的是,我發現我上次的投影片呢,寫的是相反的,所以差了一個負號,如果按照原來的寫法,這邊應該是Maximize,那如果我還是用Minimize的話,下面就應該加一個負號。
link |
好,那再來的問題就是,為什麼要用VAE這個方法?原來的Auto Encoder會有什麼樣的問題呢?那如果你看文獻上的話呢,VAE,你看它原來的Paper的話,它有很多很多的式子,你是會看得一頭霧水的,那在講那些式子之前呢,我們先來看這個Intuitive的理由,為什麼要用VAE。
link |
如果是原來的Auto Encoder的話,那原來的Auto Encoder呢,它做的事情是,我們把每一張Image變成一個Code,假設我們現在的Code呢,就是一維,就是這個圖上的這條紅色的線。
link |
那你把滿月的這個圖呢,變成Code上的一個Value,然後呢,再從這個Value做Decode,它就把它變回原來的圖。那如果是弦月的圖呢,也是一樣變成Code上的一個Value,然後接下來呢,你再把從Code上那個Value,可以把它變回原來的圖。
link |
那假設我們今天是在滿月和弦月的Code中間Sample一個點,你覺得它原來,然後再把這個點做Decode,變回一個Image,它會變成什麼樣子呢?你心裡或許期待著說,它會變成滿月和弦月中間的樣子。
link |
但是這只是你的想像而已。其實,因為我們今天用的Encoder和Decoder,我們今天用的這個Encoder和Decoder,它都是nonlinear的,它都是一個neural network,所以你其實很難預測說,在這個滿月和弦月中間,到底會發生什麼事情。
link |
你可能想像是滿月和弦月中間的月相,但未必,它可能根本就是另外一個東西。那如果用VAE有什麼好處呢?如果用VAE的好處是,實際上VAE在做的事情,就等於我下面說的這件事情。
link |
當你把這個滿月的圖變成一個Code的時候,它會在這個Code上面再加上Noise,那它會希望再加上Noise以後,這個Coderecontract以後,還是一張滿月,也就是說,原來的Autoencoder只有這個點需要被recontract回滿月的圖。
link |
但是對VAE來說,你會加上Noise,在這個範圍之內的圖recontract回來以後,都應該仍然要是滿月的圖,這個弦月的圖也是一樣。弦月的Code再加一個Noise,recontract回來以後,這個range的Code都要變成弦月的圖。
link |
那你會發現說,在這個位置,在這個地方,這個Code的這個點,它同時希望被recontract回弦月的圖,同時也希望被recontract回滿月的圖。可是你只能夠recontract回一張圖而已啊,怎麼辦?
link |
那VAE training的時候,你要minimize這個mean square error,所以最後這個位置所產生的圖,會是一張介於滿月和弦月中間的圖,你要同時讓它最像滿月也最像弦月。
link |
那你產生的圖會是什麼樣子呢?也許或許就是介於滿月和弦月之間的月相。所以如果你用VAE的話,你從你的這個Code的space上面去sample一個Code,在產生image的時候,你可能會得到比較好的image。
link |
那如果是原來的autoencoder的話,你random sample一個Code,你得到的東西可能看起來都不像是一個真實的image。好,所以VAE就是這樣。
link |
這個encoder的autoencoder代表是原來的Code,那這個C代表是加上noise以後的Code,那decoder要根據加上noise以後的Code把它recontract回原來的image。
link |
那這個sigma跟e是什麼意思呢?這個sigma它就代表了現在這個noise的variance,它代表了你的noise應該要有多大。
link |
因為variance是正的,所以這邊會取一個exponential,因為neural network的output,假設你沒有用那個activation function去控制它的話,它的output可正可負嘛。假設你這邊是linear的output的話,它的output可正可負,所以取一個exponential確保它一定是正的,可以被當作variance來看待。
link |
好,那現在當你把這個sigma乘上這個e,這個e是從一個normal distribution裡面sample出來的值,當你把這個sigma乘上e再加到n的時候,就等於是你把n加上了noise,就等於是你把原來的Code加上noise。
link |
那這個e是從一個normal distribution sample出來的,所以它的variance是固定的,但是乘上了這個不同的sigma以後,它的variance的大小就有所改變,所以這個variance決定了這個noise的大小。
link |
而這個variance的大小呢,這個variance是從encoder產生的,也就是說machine在training的時候,它會自動去認說這個variance應該要有多大。但是如果就只是這樣子的話是不夠的。
link |
假如你現在的training,你就只考慮說,我現在input一張image,然後我中間有這個加noise的機制,那noise的variance是自己認的,然後decode要reconstruct回原來的image,那你要minimize這個reconstruction error,如果你只有做這件事情的話,是不夠的。
link |
你train出來的結果呢,並不會如同你預期的樣子。為什麼呢?因為這個variance現在是自己學的啊,假設你讓machine自己決定說variance是多少,那它一定會決定說variance是0就好了。
link |
就像大家決定自己分數是多少,那每個人都會是100分了。所以這邊這個variance,如果你只讓machine自己決定的話,它就會覺得說variance是0就好了,那你就等於是原來的autoencoder。
link |
因為variance是0的話,就不會有這個不同的image overlap的情形,這樣你reconstruction的error是最小的。
link |
所以你要在這個variance上面去做一些限制,你要強迫它的variance不可以太小。怎麼做呢?所以我們另外再加的這一項,其實就是對variance做了一下限制。
link |
那怎麼說呢?這一項是這樣子,你看看這邊,由exponential sigma i-1加sigma i,那exponential sigma i呢,畫在圖上的話呢,它是藍色的這一條線。
link |
這個1加sigma i呢,畫在圖上的話呢,它是紅色的這一條線。當你把藍色這一條線減紅色這一條線的時候,你得到的是綠色的這一條線。綠色的這一條線的最低點呢,是落在sigma等於0的地方。
link |
注意一下,sigma之後會再乘以exponential,所以sigma等於0,意味著說它的variance是1,exponential 0是1。所以sigma等於0的時候,loss最低,意味著說你的variance等於1的時候,loss最低。
link |
所以machine就不會說,讓variance等於0,然後minimize reconstruction error,它還要考慮說variance呢,是不能夠太小。那最後這一項,NI平方,對這個code做這個,要minimize code的這個L2 node,怎麼解釋呢?
link |
其實很容易解釋,你就想成是我們現在加了L2的regularization,我們本來常常在churn autoencoder的時候,你就會在你的code上面呢,加一些regularization,讓它的結果呢,比較fast,比較不會overfitting,比較不會認出這個太過trivial的solution。
link |
好,那這個是直觀的理由。那如果比較正式的解釋的話,要怎麼解釋它呢?你可以這樣,那以下呢,就是paper上比較常見的說法。假設我們回歸到我們到底要做的事情是什麼?
link |
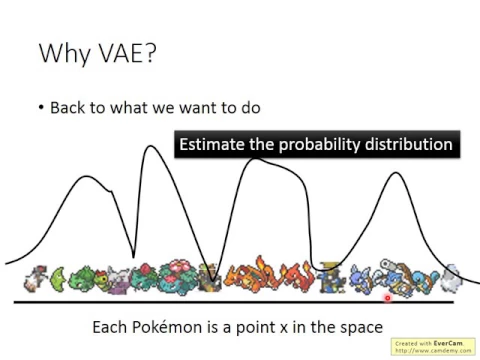
假設你現在要叫machine做的事情是generate這個寶可夢的圖的話,那每一張寶可夢的圖,你都可以想成是高維空間中的一個點。而一張image,假設它是20x20的image,它在高維空間中就是一個20x20,也就是400維的點。
link |
我們這邊呢,寫做x,雖然在圖上我們只用一維來描述它,但這個其實是一個高維的空間。那麼現在要做的事情,其實就是estimate這個高維空間上面的機率分布,P of x。
link |
我們要做的事情就是estimate這個P of x,只要我們能夠estimate出這個P of x的樣子,注意x其實是一個vector,假設我們可以estimate出P of x的樣子,我們就可以根據這個P of x去sample出一張圖,那找出來的圖就會像是寶可夢的樣子。
link |
因為你取這個P of x的時候,你會從機率高的地方比較容易被sample出來。所以這個P of x理論上應該是在有寶可夢的圖的地方,就是如果你今天這個圖長得像一隻寶可夢的話,它的機率是大的。
link |
這個是噴火龍家族,它的機率是大的,這是水箭龜家族,它的機率是大的。而如果是一些怪怪的圖的話,比如這個看起來像是皮卡丘又有點不像,這個看起來像是一個綿羊又像是一個魚,這邊機率是低的。
link |
如果我們今天能夠estimate出這個probability的distribution,那就結束了。那怎麼estimate一個probability的distribution呢?我們可以用Gaussian mixture model,我不知道在座有多少人知道Gaussian mixture model。
link |
我就好奇問一下,知道Gaussian mixture model的同學舉手一下。好,手放下,謝謝。很多人都知道Gaussian mixture model,那太好了。比如說如果你修過語音課的話,你可能就會聽過Gaussian mixture model。
link |
那Gaussian mixture model在做什麼呢?我們現在有一個distribution,它長這個樣子,黑色的,很複雜很複雜。那我們說這個很複雜的黑色的distribution,它其實是很多個Gaussian,我們這邊這個藍色的代表Gaussian,有很多個Gaussian用不同的weight疊合起來的結果。
link |
只要你今天Gaussian的數目就夠多,你就可以產生很複雜的distribution。雖然黑色的很複雜,但它背後可能其實是有很多Gaussian疊合起來的結果。
link |
那這個式子怎麼寫它呢?你會把它寫成這樣。首先,如果你要從這個P of X sample一個東西的時候,你怎麼做?你先決定你要從哪一個Gaussian sample東西。假設現在有一把Gaussian。
link |
那這個每一個Gaussian,它背後都有一個weight,每一個Gaussian有一個自己的weight。那這邊有一把Gaussian,每一個都有它自己的weight。
link |
那接下來,你再根據每一個Gaussian的weight,去決定你要從哪一個Gaussian sample data,然後再從你選擇的那個Gaussian裡面sample data。如果你選擇1這個Gaussian的話,那你就是從這個地方sample data。那如果你選擇2的話,就從這個地方,3就從這個地方,4就從這個地方,5就從這個地方,以此類推。
link |
所以,怎麼從Gaussian mixture model sample一個data呢?你就這樣做。首先,你有一個這個multinomial distribution,你從這個multinomial distribution裡面決定你要去sample哪一個Gaussian。今天m代表第幾個Gaussian,它是一個integer。
link |
那決定好你要從哪一個N sample Gaussian以後,你要從哪一個Gaussian sample這個data以後,決定哪一個Gaussian以後,每一個Gaussian有自己的這個mean,μ上標N,有一個自己的variance,σ上標N。
link |
所以,你有了這個N以後,你就可以找到這個mean跟variance,根據這個mean跟variance,你就可以sample一個X出來。所以,今天整個P of X寫成summation over所有的Gaussian,那個Gaussian的weight P of N在乘上,有了那個Gaussian以後,從那個Gaussiansample出X的幾率,P of X given N。
link |
好,那在Gaussian mixture model裡面有種種的問題,比如說你需要決定這個mixture的數目,但是如果你知道mixture的數目的話,接下來給你一些dataX,你要estimate這一把Gaussian,跟它的每一個Gaussian的weight,跟它的mean跟variance,其實是很容易的。
link |
你只要用E and L本人就好了,你不知道這個是什麼,沒有關係,反正就是,這是很容易的事情。好,那現在每一個X呢,它都是從某一個mixture被sample出來的。
link |
這件事情其實就很像是在做classification一樣,每一個我們所看到的X,它都是來自於某一個分類,它都是來自於某一個class。但是我們之前有講過說,把data做classification,做clustering,其實是不夠的。
link |
更好的表示方式是用distributed representation,也就是說,每一個X呢,它並不是屬於某一個class,某一個cluster,而是它有一個vector來描述它的各個不同面向的attribute,描述它各個不同面向的特性。
link |
所以,VAE其實就是Gaussian mixture model的distributed representation的版本。那怎麼說呢?首先呢,我們要sample一個Z,這個Z呢,是從一個normal distribution sample出來的。
link |
Z是一個vector,它從一個normal distribution被sample出來。那這個Z是一個vector,這個vector的每一個dimension就代表了某種attribute,代表你現在要sample的那個東西的某種特質。
link |
Z的每一個dimension就代表了它要sample的某種東西的特質。假設Z呢,它長這樣,它是一個Gaussian distribution,那現在我們在這個圖上呢,就假設它是一維的。
link |
它可能是一個十維的、一百維的vector,到底有幾維是你自己決定的。假設現在Z呢,就是一維的一個Gaussian。然後接下來呢,你sample出這個Z以後,根據Z呢,你可以決定μ跟σ,你可以決定Gaussian的mean跟variance。
link |
那剛才在那個Gaussian mixture model裡面,你有十個mixture,你就是十個mean跟十個variance。但是今天在這個地方,你的Z有無窮多的可能,它是continuous,它不是discrete。
link |
所以你的Z呢,有無窮多的可能。所以你的μ跟整個這個mean跟variance也有無窮多的可能。那怎麼找到這個mean跟variance呢?怎麼給一個Z找到這個mean跟variance呢?
link |
你這邊的做法就是,假設這個μ跟,表示這個mean跟variance呢,都來自一個function,都來自一個function。你把Z帶進產生mean的這個function,它就給你μ of Z。
link |
μ of Z代表說,現在如果你的這個hidden的東西啊,你的這個attribute呢,是Z的時候,那你在這個X這個space上面的mean呢,是多少?那同理呢,σ of Z代表說,你的這個variance呢,是多少?
link |
代表說,你現在如果從這個latent的space裡面得到Z的時候,你的variance是多少?那所以,實際上這個你要從P of,所以實際上這個P of X是怎麼產生的呢?
link |
每一個,在這個Z這個space上面,每一個點都有可能被sample到,只是在中間這邊呢,這個點被sample到的機率比較大,在tail的地方呢,點被sample到的機率比較小。
link |
當你sample出一個點以後,當你在Z的space上面sample出一個point以後呢,那個point會對應到一個Gaussian。
link |
這個點對應到這個Gaussian,這個點對應到這個Gaussian,這個點對應到這個Gaussian,這個點對應到這個Gaussian,這個點對應到這個Gaussian,等等。
link |
每一個點都對應到一個Gaussian,那至於某一個點對應到什麼樣的Gaussian,它的mean跟variance是多少,是由某一個function所決定的。
link |
所以當你用這個概念,當你今天你的這個Gaussian是從一個normal distribution所產生的時候,現在呢,你等於就是有無窮多的Gaussian。
link |
原來Gaussian mixture model裡面最多什麼,就五一二個,那個太少了,現在無窮多的Gaussian。
link |
那另外一個問題就是,那我們怎麼知道每一個Z應該對應到什麼樣的mean跟variance呢,這個function怎麼找呢?
link |
我們知道說,neural network就是一個function,所以你可以說,我就是train一個neural network,這個neural network的input Z,然後呢,它的output呢,就是兩個vector。
link |
第一個vector代表了input是Z的時候,你Gaussian的mean,這個sigma呢,代表了variance。
link |
那variance雖然說它是一個這個matrix,你可以說,你可以把matrix拉直當作它的output,或者是你可以指output,diagonal的地方,然後假設呢,diagonal的地方都是0。
link |
好,反正呢,我們有一個neural network,它可以告訴我們說,在這個space,在Z這個space上每一個點,它對應到Xspace的時候呢,你的這個distribution mean跟variance分別是多少。
link |
那現在,這個P of X的distribution會長什麼樣子呢?
link |
這個P of X的distribution呢,就會變成是,這個P of Z的機率跟,呃,我們知道Z的時候,X的機率,在對所有可能的Z呢,做積分。
link |
這邊不能夠是這個相加,不能夠是summation,必須要是積分,因為這個Z呢,是continuous的。
link |
那有人可能會有一個困惑就是,為什麼這邊一定是這個gaussian呢?為什麼這邊一定是gaussian呢?
link |
你可以不是gaussian這樣,它可以是一朵花的樣子,在文獻上確實有人會把它弄成一朵花的樣子。
link |
它可以是任何東西,它可以是任何東西,這個是你自己決定的。
link |
當然這個gaussian,呃,說起來是合理的,你就假設說,呃,每一個attribute呢,它的分布就是gaussian。
link |
就比較極端的case總是比較少的嘛,那比較沒有特色的東西總是比較多的嘛,然後attribute和attribute之間是independent的。
link |
這個,這樣假設其實也是合理的,不過這個形狀呢,是你自己假設的,你可以假設任何形狀,你可以假設任何形狀。
link |
那現在這個,呃,但是你不用擔心說呢,你如果假設gaussian,會不會對這個P of X呢,帶來很大的限制。
link |
會不會說,如果是假設Z是gaussian distribution的話,有些P of X你就沒有辦法描述,其實你就不用太擔心這個問題。
link |
因為不要忘了,這個NN是非常powerful的,NN可以represent任何function,假如neuron夠多,NN可以represent任何function。
link |
所以,今天從Z到X中間的mapping可以是很複雜,所以就算是你的Z是一個normal distribution,最後這個P of X呢,它也可以是一個非常複雜的distribution。
link |
好,那再來呢,所以我們現在的式子是這樣子的,我們知道P of X可以寫成呢,呃,對Z的積分,然後乘上P of Z,乘上P of X given Z。
link |
P of Z是一個normal distribution,這個這個X given Z呢,是我們先知道Z是什麼,然後我們就可以決定呢,這個X它是從什麼樣的mean跟variance的gaussian裡面呢,被sample出來。
link |
但是,這一個function,有Z,它有什麼樣的mean跟variance,它們中間的關係,是不知道的,是等著要被找出來的。
link |
但是問題是怎麼找呢,它的criterion就是要maximize我們的likelihood,我們現在手上已經有一筆dataX,那你希望找到一組mu的,找到一個mu的function,找到一個sigma的function。
link |
它可以讓呢,這個你現在已經觀察到的data,你現在手上已經有的image,它的這個,這個每個X代表一個image嘛,你現在手上已經有的image,它的P of X取log以後呢,它的值呢,相加以後呢,是被maximize的。
link |
這個就是maximize我們已經看到的image的likelihood。好,這邊只是複習一下,這個Z怎麼產生這個mu跟sigma呢,它是透過一個NN。所以我們要做的事情就是,調這個NN裡面的參數,調這個NN裡面每個newon的weight跟bias,使得這個likelihood呢,可以被maximize。
link |
那在這邊等一下會引入另外一個distribution,它叫做Q of Z given X,它跟這個NN是相反的,它是given Z決定這個X的mean跟variance,這邊是given X決定在Z這個space上面的這個mean跟variance。
link |
也就是說我們有另外一個NN,這邊寫成NN',你input X以後,它會告訴你說,對應的Z的mean跟對應的Z的variance。你給它X以後呢,它會決定這個Z呢,要從什麼樣的mean跟什麼樣的variance呢,被sample出來。
link |
那上面這個NN呢,其實就是VAE裡面的decoder,下面這個NN呢,其實就是VAE裡面的encoder。好,那我們現在先不要管NN這件事情,我們現在就先只看這個式子就好。
link |
這個P of X given Z,我們先不要在意它是不是從NN產生的,反正這個就是一個機率,我們要去把它找出來。那怎麼找呢?這個log P of X,它可以寫成呢,對,O over Z的積分,然後Q of Z given X,然後log P of X dz這樣。
link |
那你想說這個為什麼是這樣呢?因為Q of Z given X它是一個distribution,這個式子對任何distribution都成立。我們假設Q of Z given X現在就是一個從路邊撿來的distribution,它可以是任何一個distribution。
link |
那任何一個distribution你都可以寫成這個樣子,對不對?因為這個積分跟這個P of X是無關的,所以你可以把P of X這一項提出來,然後積分的部分就會變成1,所以左勢就等於右勢。
link |
這個沒有什麼好講,這個式子是什麼都沒有做。再來也是一個其實是什麼都沒有做的式子,這個P of X可以寫成P of Z X除以P of Z given X,那你把P of Z given X展開一下就會發現說這一項等於這一項,這也沒什麼好講。
link |
接下來又是一個什麼都沒有做的式子,本來我們把P of Z X除掉Q of Z given X,然後再把Q of Z given X除掉P of Z given X,左勢也等於右勢,因為這個Q其實是可以消掉的。
link |
這個小學生應該就知道,這個式子也等於是什麼事都沒有做。接下來這個東西被放在log裡面,我們知道log相乘等於拆開後相加,所以log這一項乘這一項等於log這一項加log這一項。
link |
接下來觀察一下這兩項到底代表了什麼事情。右邊這一項代表了一個KL divergence,這個P of Z given X是一個distribution,Q of Z given X是另外一個distribution。
link |
現在X是給定的,所以你有兩個distribution,當有兩個distribution的時候,你可以算一個東西叫做KL divergence,KL divergence代表的是這兩個distribution的相近的程度。
link |
如果這個KL divergence它越大,代表這兩個distribution越不像,這兩個distribution一模一樣的時候,KL divergence會是0,所以KL divergence它是一個距離的概念,它衡量了兩個distribution之間的距離,所以這一項就是KL divergence的式子。
link |
這一項是一個距離,所以它一定是大於等於0的,最小的也是0而已。至於為什麼KL divergence是什麼的,反正你就記起來就是了。
link |
因為這一項一定是大於等於0的,所以這一項會是L的lower bound,就是L一定會大於等於這一項,這一項你可以再猜一下,P of Z X等於P of X given Z乘上P of Z,所以L一定會大於這一項。
link |
這一項就是一個lower bound,我們叫它LB。現在我們知道的事情是這樣子的,這個lower probability,就是我們要maximize的這個對象,它是由這兩項加起來的結果。
link |
LB它長得這個樣子,在這個式子裡面,P of Z是normal distribution,是已知的,我們不知道的是P of X given Z跟Q of X given Z。
link |
那我們本來要做的事情是,找那個P of,我們本來要做的事情是要找這個P of X given Z,讓這個P,讓這個log,讓這個likelihood越大越好。
link |
現在我們要做的事情,變成找P of X given Z和Q of Z given X,讓LB越大越好。我們本來只要找這一項,現在順便也要找這一項,把這兩項合起來,我們現在同時找這兩項,然後去maximize這個LB。
link |
突然多找一項到底是要做什麼呢?如果我們現在只找這一項的話,假設我們現在只找這一項,然後去maximize LB的話,你可以找,你如果maximize這一項,你如果調整這一項,你如果找這一項P of X given Z,讓LB被maximize的話,
link |
因為你要找的這個likelihood,它是LB的upper bound,所以你增加LB的時候,你有可能會增加你的likelihood,但是你不知道你的likelihood跟你的lower bound之間到底有什麼樣的距離。
link |
理想上你希望做到的事情是,當你的lower bound上升的時候,你的likelihood是會比LB高,然後likelihood也跟著上升,但是有可能你會遇到一個比較糟糕的狀況是,你的lower bound上升的時候,likelihood反而下降,雖然它還是比LB大,但是它有可能下降,因為你根本不知道它們之間的差距是多少。
link |
所以引入Q這一項,其實可以解決剛才說的那個問題,為什麼呢?因為你看,這個是likelihood,likelihood等於LB加KL divergence,如果你今天去調這個Q of Z given X,調Q這一項,去maximize LB的話,會發生什麼事呢?
link |
你會發現說,首先Q這一項跟log P of X是一點關係都沒有的,對不對?log P of X只跟P of X given Z有關,這個Q到底帶什麼東西,這個值都是不變的,所以這個值都是不變的,藍色這一條長度都是一樣。
link |
但是我們現在卻去maximize LB,maximize LB代表說,你minimize了這個KL divergence,也就是說,你會讓你的lower bound跟你的likelihood越來越接近,如果你maximize Q這一項的話。
link |
所以今天假如你固定住這個P,假如你固定住這個P of X given Z這一項,然後一直去調這個Q of Z given X這一項的話,你會讓這個LB一直上升一直上升一直上升,最後這個KL divergence會完全不見。
link |
假如你最後可以找到一個Q,它跟這個P of Z given X正好完全distributed,一模一樣的話,你會發現說,你的likelihood就會跟LB完全平在一起,它們就完全是一樣大的。
link |
這個時候呢,如果你再把LB上升的話,那因為你的likelihood一定要比LB大,所以這個時候你的likelihood呢,你就可以確定它一定會上升,所以這個就是引入這個Q這一項很有趣的地方。
link |
那今天也會得到一個副產物,當你在maximize Q這一項的時候,你會讓這個KL divergence越來越小,意味著說呢,你就是讓這個Q呢,跟這個P of Z given X,注意一下,這兩項是不一樣的,這個方向是不一樣的。
link |
你會讓這個Q of Z given X跟P of Z given X呢,越來越接近。所以我們接下來要做的事情呢,就是找這一個跟這一個,然後可以讓LB呢,越大越好。
link |
讓LB越大越好,就等同於我們可以讓likelihood呢,越來越大,而且你順便呢,會找到這個Q呢,它可以去approximate P of Z given X。好,那這一項LB呢,它長什麼樣子呢?
link |
這一項LB呢,我們剛才講過它就是它長這個樣子,然後呢,log裡面的相乘可以把它拆開。我們把P of Z除以Q of Z given X放在一邊,把這一項呢,放在另外一邊。
link |
那如果你觀察一下的話,會發現這個P of Z是一個distribution,Q of Z given X也是一個distribution。所以這一項呢,是一個KL divergence,這一項呢,是這個P of Z跟Q of Z given X的這個KL divergence。
link |
那如果複習一下,這個Q是什麼呢?Q是一個neural network的,Q是一個neural network,當你給X的時候,它會告訴你說,這個Q of Z given X啊,它是從什麼樣的mean跟variance的Gaussian裡面呢,sample出來的。
link |
那所以呢,我們現在如果你要minimize這個P of Z跟Q of Z given X的KL divergence的話呢,你就是去調呢,這個output,這個output。
link |
你就去調你的這個Q對應的那個neural network,調你的那個Q對應的那個neural network,讓它產生的distribution可以跟這個一個normal distribution呢,越接近越好。這件事情的這個推導呢,我們就把它放在這個,你就請參照這個VAE的原始的paper。
link |
那minimize這一項,其實就是我們剛才說的這一項,就是剛才說的在reconstruction error外,另外再加的那個看起來像是regulation的式子。
link |
然後做的事情就是minimize這個KL divergence,然後做的事情就是希望說,這個Q of Z given X的output跟normal distribution呢,是接近的。
link |
那我們還有另外一項,另外一項是這樣,另外一項呢,是要這個積分over Q of Z given X乘上log P of X given Z,對Z呢,做積分。
link |
這一項的意思就是,這一項的意思就是,你可以想像是,我們有一個log P of X given Z,然後呢,它用Q of Z given X來做這個weighted sum,來做weighted sum。
link |
那所以你可以把它寫成呢,這個log P of X given Z,根據Q of Z given X的這個期望值,根據它的期望值。所以這邊這個式子的意思呢,這邊這個式子的意思就好像是說,我們從Q of Z given X去sample data。
link |
就給我們一個X的時候,我們去計算,我們去根據這個Q of Z given X的這個機率分布,去sample一個data,然後呢,要讓log P of X given Z的機率呢,越大越好。
link |
那這件事情,其實就是autoencoder在做的事情,什麼意思呢?怎麼從Q of Z given X去sample一個data呢?你就把X丟到neural network裡面去,它產生一個mean跟一個variance,根據這個mean跟variance,你就可以sample出一個Z。
link |
然後接下來,我們要做的事情,你已經做這一項了,這邊就是這一項,你已經根據現在的X,sample出一個Z。
link |
接下來呢,你要maximize這一個Z,產生這個X的機率。那這個Z產生這個X的機率是什麼呢?這個Z產生這個X的機率,是把這個Z丟到另外一個neural network裡面去,它產生一個mean跟variance。
link |
那要怎麼讓這個機率越大越好呢?要怎麼讓這個nn output所代表的這個distribution產生X的機率越大越好呢?假設我們無視這個variance這件事情的話,因為後來一般在實作裡面,你可能就不會把variance這件事情考慮進去,你只考慮mean這一項的話,那你要做的事情就是,讓你的這個mean跟你的X越接近越好。
link |
你現在是一個Gaussian distribution嘛,那Gaussian distribution在mean的地方的機率是最高的。所以,如果你讓這個nn output的這個mean,正好等於你現在的這個data X的話,那這一項log p of X given Z,它的值呢,是最大的。
link |
所以現在這整個case就變成說,input一個X,然後呢,產生兩個vector,然後呢,sample一下產生一個Z,再根據這個Z呢,你要產生另外一個vector,這個vector要跟原來的X越接近越好。
link |
這件事情其實就是autoencoder在做的事情,你要讓你的input跟output越接近越好,它就是autoencoder在做的事情。所以,這兩項合起來,就是剛才我們前面看到的這個vae的這個loss function。
link |
如果你聽不懂的話,也沒有關係就是了,我前面有提供一個比較intuitive的想法。那其實vae有另外一個是叫做conditional的vae,conditional的vae我們這邊就簡單講一下概念就好。
link |
conditional vae它可以做的事情是說,比如說如果你現在讓vae可以產生手寫的數字,讓vae可以產生手寫的數字,它就是看一個,給它一個digit,然後它把這個digit的特性抽出來。
link |
它抽出它的特性,比如說它有多它的筆畫的粗細等等。然後接下來呢,你在丟進encoder的時候,你一方面給它有關這個數字的特性的一個distribution,你另外一方面告訴decoder說它是什麼數字,那你就可以generate一大排。
link |
以及你就可以根據這一個digit,generate跟它style很相近的digit。這個是在,這應該是在enlist上面的結果,reference在下面,這是enlist上面的結果,這是在另外一個數字的copen上面的結果。
link |
你會發現說conditional vae確實可以根據某一個digit畫出其它的style相近的數字。這邊是一些reference給大家參考。那vae其實有一個很嚴重的問題,就是因為它有這個問題,所以之後又propose了GAM,又propose了GAM。
link |
那vae有什麼樣的問題呢?vae其實它從來沒有去真的學怎麼產生一張看起來像真的image,對不對?因為它所學到的事情是,它想要產生一張image,跟我們在database裡面的某張image越接近越好。
link |
但是它不知道的事情是,我們在evaluate它產生的image,跟database跟image的相似度的時候,我們是用比如說mean square error等等,來evaluate兩張image中間的相似度。
link |
今天呢,假設我們這個decoder的output跟真正image之間有一個pixel的差距,他們有某一個pixel是不一樣的,但這個不一樣的pixel它落在不同的位置,其實是會得到非常不一樣的結果。
link |
假設這個不一樣的pixel它是落在這個地方,它只是讓7的筆畫比較長一點,跟它落在另外一個地方,它落在這個地方,對人來說,你一眼就可以看出說,這個是machine generated,它是怪怪的digital。
link |
這個搞不好是真的,因為你根本看不出來跟原來這個7有什麼差異,它只是稍微長一點,看起來還是很正常。但是對VAE來說,都是一個pixel的差異,對它來說,這兩張image是一樣的好或者是一樣的不好。
link |
所以VAE它學的事情只是怎麼產生一張image跟database裡面的image一模一樣,它從來沒有想過說,要真的產生一張可以以假亂真的image。
link |
如果你用VAE來做training的時候,其實你產生出來的image,VAE所產生出來的image,往往都是database裡面的image裡面的linear combination而已,因為它從來沒有學過說要產生新的image,它唯一做的事情只有模仿而已。
link |
它只是唯一做的事情只有希望它產生的image跟database的某張image越像越好,它只是模仿而已,或者是最多就是把原來database裡面的image做linear combination,它沒有辦法產生一些新的image。
link |
所以這樣感覺沒有非常intelligent,所以接下來就有另外一個方法,叫做generative adversarial的level,adversarial是對抗的意思,然後它的縮寫是game,你會發現它是很新的paper,它最早出現的時候是2014年的12月,所以大概是兩年前的paper。
link |
以下呢,我這邊引用了這個Jan Larkin對game的comment,就是有人在Portal上面問了說,unsupervised linear approach哪一個是最有potential的,然後Jan Larkin他親自來回答,他說呢,adversarial training is the coolest thing since sliced bread.
link |
sliced bread大家知道是什麼意思嗎,我google了一下,這是個片語,如果翻譯成中文的話就是由此以來的意思。這個since sliced bread是什麼意思呢,sliced bread是切片麵包的意思,這個片語的典故好像是說,在過去麵包店是不幫你切麵包的,就吐司麵包烤完以後他不幫你切,所以你買回去要自己切很麻煩,後來就有人發明說應該要先切了以後再賣,然後大家都很高興這樣子。
link |
since sliced bread他在英文片裡面叫做由此以來的意思,他說這是由此以來最強最酷的方法。
link |
這邊還講了一些別的,他說,what missing the moment is a good understanding of it, so we can make it work reliably. It's very finicky, sort of like convolutional nets were in the 1990s, when I had the reputation of being the only person who could make them work, which wasn't true。
link |
這其實gain非常難勸,感覺好像只有Ian Goodfellow的proposal他們可以做得起來,其他人做得起來,你可以google一下這個gain的code,很多人都在admins的上面,他們產生的digi都不是很好看,王BAE隨便做都可以打包那些東西,所以這才產生image的怪。
link |
但是你如果看paper的話,他的performance是蠻好的,所以他裡面還有很多不為人知的技巧,像過去大家相信說只有楊瓦昆可以train起來是一個人,不過其實不是這樣子。
link |
其實我很無聊,我又找到另外一則了,有人問說有沒有什麼最近的breakthrough在deep learning裡面,然後楊瓦昆又來回答了,他說,the most important one, in my opinion, is adversarial training, also called gain.
link |
This is the idea proposed by Ian Goodfellow, he said this is the most interesting idea in the last ten years in ML. 所以我們就來看這十年來最有趣的想法到底是什麼樣子。
link |
Gain的概念有點像是擬態的演化,比如說這是一個枯葉蝶,長得就跟枯葉一模一樣。枯葉蝶是怎麼變得跟枯葉一模一樣的呢?怎麼變成這麼像的呢?也許一開始它長得是這個樣子。
link |
但是它有天敵,類似麻雀的天敵,比如說像波波這樣子,它有天敵。天敵會吃蝴蝶,天敵辨識是不是蝴蝶的方式就是,它知道蝴蝶不是棕色,所以它就吃不是棕色的東西。
link |
所以蝴蝶就演化了,它就變成了是棕色的。但是它的天敵也會跟著演化,波波我記得會變成比比鳥。比比鳥知道蝴蝶是沒有葉脈的,所以它會吃沒有葉脈的東西,它會弄有葉脈的東西。
link |
所以蝴蝶要再演化,就會變成枯葉蝶,它就產生葉脈。但是它的天敵也會再演化。其實這個好像是神獸,這個好像不是波波演化來的,不過沒有關係。
link |
它的天敵也還會再演化,所以天敵和貝蝶和枯葉蝶就會共同演化,所以枯葉蝶就會長得越來越像枯葉,直到最後沒有辦法分辨為止。所以這個game的概念是非常類似的。
link |
首先有一個第一代的generator,第一代generator很廢,它可能根本就是random的,就要generate一大堆奇怪的東西,看起來不像是真正的image的東西,假設我們現在要generate的是digit。
link |
接下來有一個第一代的discriminator,它就是那個天敵。discriminator做的事情是,它會根據real的image跟generator所產生的image,去調整它裡面的參數,去評斷說一張image是真正的image,還是generator所產生的image。
link |
接下來,generator根據discriminator,等下會講說generator怎麼根據discriminator去演化。generator根據discriminator,它又去調整了它的參數,所以它第二代的generator,它產生的參數,它產生的digit可能就更像真的。
link |
接下來discriminator會再根據第二代的generator產生的digit跟真正的digit,再update它的參數。接下來,有了第二代的discriminator,會產生第三代的generator。
link |
第三代的generator產生的數字,又更像真正的數字。第三代的generator,它產生的這些數字,可以騙過第二代的generator。第二代產生的這些數字,可以騙過第一代的discriminator。
link |
但是discriminator會再演化,它可能又可以再分辨第三代的generator產生的數字跟真正的數字之間的差距。你要注意的地方就是,這個generator從來沒有看過真正的image長什麼樣。
link |
discriminator有看過真正的image長什麼樣子,它會比較真正的image跟generator的output的不同。但是generator從來沒有看過真正的image,它做的事情只是想要去騙過discriminator而已。
link |
因為generator從來沒有看過真正的image,所以generator它可以產生出來那些image是database裡面從來都沒有見過的,所以這比較像是我們想要我們去做的事情。我們先來看這個discriminator是怎麼train的,這邊是比較直覺的。
link |
discriminator它就是一個neural network,它的input就是一張image,它的output就是一個number,你output就只要給它,它的output就是一個scatter,那可能通過sigmoid function,讓它的值介於0到1之間。
link |
0代表說input這張image是真正的image,假如你是要做手寫數字辨識的話,那input的image就是真正的人手寫的數字,0代表是假的,是generator所產生的。那generator是什麼呢?
link |
generator在這邊,它的架構就跟VAE的decoder是一模一樣,它也是一個neural network,它的input就是從一個distribution,它可以是normal distribution或是任何其他的distribution,從某一個distributionsample出來的一個vector。
link |
你把這個sample出來的vector丟到generator裡面,它就會產生一個數字,產生一個image,那你給它不同的vector,它就產生不同樣子的image。好,那先用generator先產生一堆假的image,然後我們有真正的image。
link |
discriminator就是把這些generator所產生的image都label為0,也都label為fake,然後把這個真正的image都label為1,也是都label為true。接下來就只是一個binary classification的problem,binary classification的problem大家都很熟,那你就可以認一個discriminator。
link |
接下來怎麼認這個generator呢?那generator的認法是這樣子,現在已經有了第一代的discriminator,那怎麼根據第一代的discriminator把第一代的generator再update呢?怎麼update呢?
link |
首先呢,如果我們隨便給輸入一個vector,它會產生一張隨便的image,那這個image可能沒有辦法騙過這個discriminator,那你把這個generator產生的image丟到discriminator裡面,它可能說這有87%像這樣子。
link |
然後呢,接下來要做的事情是什麼呢?接下來我們要做的事情是調這個generator的參數,調這個generator的參數讓現在discriminator會認為說generator generate出來的image是真的,也就是說要讓generator generate出來的image丟到discriminator以後,discriminator的output必須要越接近越好。
link |
所以你希望說generator是長這個樣子的image,它可以騙過discriminator,discriminator的output是1.0,覺得它是一個真正的image。
link |
這件事情怎麼做呢?其實因為你知道這個generator是一個neural network,那discriminator也是一個neural network,你把這個generator的output丟到這個當作discriminator的input,然後再讓它產生一個scatter,嗯,這件事情其實就好像是你有一個很大很大的neural network,
link |
你有一個很大很大的neural network,它這邊有很多層,它這邊也有很多層,然後你丟一個random的vector,它output就是一個scatter,所以一個generator加一個discriminator它合起來就是一個很大的network,而它既然合起來是一個很大的network,
link |
那你要讓這個network再丟進一個random vector,它output1這件事情是很容易的,你就做gradient descent就好,你就gradient descent調參數,希望丟進這個vector的時候,它的output是要接近1的。
link |
但是你這邊要注意的事情是,你在調這個參數的時候,你在調這個network的參數的時候,你在做backpropagation的時候,你只能夠調整這個generator的參數,你只能算generator的參數對output的這個gradient,然後去update generator的參數,你必須要fix住discriminator的參數,如果你今天不fix住discriminator的參數會發生什麼事情呢?
link |
你會發生說,對discriminator來說,要讓它output1,很簡單啊,它最後output的時候bias設1,然後其他weight都設0,它output不就1了,所以discriminator,你要讓這整個network input一個random vector,output是1的時候,你要把discriminator的這個參數鎖住,discriminator的參數必須要是fix住的,然後input一個generator,然後只調generator的參數。
link |
這樣generator產生出來的image才是一個可以騙過discriminator的image。
link |
好,這邊有一個來自Gantt的原始paper的toy example,我們來說明一下這個toy example是什麼意思。這個toy example是這樣子的,它說呢,現在我們的這個z space,也就是這個decoder的input,我們叫decoder input就是一個z嘛,就是一個hidden的vector,hidden的vector。
link |
這個z呢,它是一個one dimensional的東西,那它丟到generator裡面呢,它會產生另外一個one dimensional的東西,這個z可以從任何的distribution裡面sample出來,那這邊在這個例子裡面,它顯然是從一個uniform的distribution裡面sample出來的。
link |
好,然後呢,你把這一個z呢,通過neural network以後,它會每一個不同的z,會給你呢,不同的x。那這個x的分布呢,就是綠色的這個分布,綠色的這個分布。
link |
那現在要做的事情是,希望這個generator的output可以越像real data越好,它這邊的real data呢,就是黑色的這個點,假設有一組real的data,就是黑色的這個點,你要找的這個distribution是黑色這個點,那你希望你的generator的output,也就是這個綠色的distribution,可以跟黑色的這個點呢,越接近越好。
link |
那如果按照Gantt的概念的話,你就是把這個generator的output的x,跟這個real的data,這些黑色的點呢,丟到discriminator裡面,然後讓discriminator去判斷說,現在這個value,其實現在這個x啊,還有這個real data,都只是一個scalar而已。
link |
現在這個scalar,它是來自真正的data的機率,跟來自於generator的output的機率。如果它是真正的data的話,就是1,反之就是0。那discriminator的output呢,就是綠色的curve。
link |
那假設現在呢,generator它還很弱,所以它產生出來的distribution,是這個綠色的distribution。那這個discriminator呢,它根據real data,跟這個generator的distribution,它的樣子呢,你給它這個x的值,它的output可能就會像是這一條藍色的線。
link |
這條藍色的線告訴我們說,這個discriminator認為說,如果是在這一個這一代的點,它比較有可能是假的,它的這個值是比較低的。如果是落在這一代的點,它比較有可能是從generator產生的。
link |
落在這一代的點,它比較有可能是real data。然後接下來呢,generator就根據discriminator的結果,去調整它的參數。generator要做的事情,是騙過discriminator。既然discriminator認為,這個地方比較有可能是real的data,generator呢,就把它的output往左邊移。
link |
它就把它的output往左邊移。那你說,有沒有可能會移太多,就比如說,就通通騙到左邊去了,是有可能的,所以gain很難train。
link |
這個要小心的調參數,小心的調參數,讓它不要移太多。綠色的distribution就可以稍微偏一點,就比較接近真正real的黑色的點的distribution。所以generator為了騙過它,它就產生了新的distribution。然後接下來discriminator呢,會再update這個綠色的這一條線。
link |
那這個process呢,就不斷反覆反覆反覆的繼續進行,直到最後呢,generator產生的output跟real data一模一樣,那discriminator呢,會沒有任何辦法分辨真正的data。
link |
沒有問題嗎?其實這就是現在train gain的時候所遇到最大的問題。你不知道discriminator是不是對的。因為你說discriminator現在得到一個很好的結果,那可能是generator太廢。
link |
比如說discriminator得到一個很差的結果,比如說它認為說每一個地方它都無法分辨說是real的value還是fake的value,這個時候並不代表說generator很像,有可能只是discriminator太弱了。
link |
所以這是一個現在還沒有好的solution的難題。所以真正在train gain的時候你會怎麼做呢?你會一直坐在電腦旁邊看它產生的image。因為你從discriminator跟generator的loss,你看不出來它generate出來的image有沒有比較好。
link |
這就變成說你generatorupdate一次參數,discriminatorupdate一次參數,你就去看看它,你就拿generatorgenerate一些image看看有沒有比較好。如果變差了,方向走錯了,再重新調一下參數。所以這個非常非常困難。
link |
我們這邊其實有人在線上放了一個demo,我們來看一下這個demo。非常realistic的image,這個是open AI產生的image。
link |
如果我們問你說,你覺得左邊是real image還是右邊是real image呢?你覺得左邊是電腦產生image的同學舉手一下。有人,請放下。你覺得右邊是電腦產生image的同學舉手一下。
link |
其實它還是沒有辦法騙過人,它這邊有很多怪怪的東西。這個馬還蠻像的,這個有飛魚,有大嘴巴的貓,有很多怪怪的東西,所以它其實沒有辦法騙過人。
link |
我覺得如果放單一一張,比如光看這個馬的話,它可能可以騙過人。open AI他們有做那個實驗,好像可以騙過有21%machine generated image會被誤判成real,所以它其實是可以騙過部分的人。
link |
另外這邊又有另外一個很驚人的結果,在文獻上非常驚人的結果,就是說先拿很多房間的照片讓machine去get,然後可以generate房間的照片。
link |
他們說那個generator就是你input一個vector給它,它就會output一張image給你。你現在可以在input的space上面去調你的vector,去產生不同的output。所以它說它先random找五個vector,產生五張房間的圖。
link |
接著再從這個點移動你的vector到這個點。所以你就發現說你的image逐漸地變化,然後跑到這個點,然後再逐漸地變化,再跑到這個點。
link |
你會發現一些有趣的地方,比如說這邊有個窗戶,它慢慢地就變成了一個類似電視的東西,或者這邊有個電視,它慢慢地就變成了窗戶。
link |
我覺得最驚人的結果是,有日本人拿來用game畫很神奇的東西,傳說中你只要一旦能夠成功地使用它,它就可以召喚出不可思議的力量,但是大部分的時候你都沒有辦法成功地召喚它。
link |
它有點像是神之卡的感覺,你只要能夠操控那個神,你就可以獲得不可思議的力量,但大部分的時候你都無法操控它。其實我昨天晚上想說我可不可以自己generate一些寶可夢的圖,我弄到五點我都搞不起來,所以我後來想說還是去睡了好了。
link |
這很麻煩,因為它最大的問題就是,你沒有一個很明確的signal,它可以告訴你說現在的generator到底做得怎麼樣。沒有一個很明確的signal可以告訴你這件事。
link |
在一個standard的NN的training裡面,你就看loss,loss越來越小,代表說現在training越來越好。但是在game裡面,你其實要做的事情是,keep你的generator跟discriminator是well matched的,他們必須要不斷處於一種競爭的狀態。
link |
他們要像塔史亮跟近藤光一樣,不斷處於一種勢均力敵的狀態,他們必須要成為對手。我們第三堂課的時候,會請作業一二三做得特別好的同學來分享一下他是怎麼做的。
link |
這很麻煩,因為在game裡面,你要讓discriminator跟generator他們一直維持一種勢均力敵的狀態,所以你必須要用不可思議的平衡感來調整這兩個discriminator跟generator的參數,讓他們一直處於勢均力敵的狀態。
link |
今天這個其實很像是在做alpha go一樣,你有兩個agent,你要讓他們一直處於一樣強的狀態。當今天你的discriminator fail的時候,因為我們最後training的終極目標是希望generator產生出來的東西是discriminator完全無法分別的,也就是discriminator在鑑別真或假的image上面的正確率是零。
link |
但是往往當你發現你的discriminator整個fail掉的時候,並不代表說generator真的generate很好的image,往往你的遇到的狀況只是因為你的generator太弱。
link |
那很多時候我在train的時候常遇到的狀況就是,generator他不管input什麼樣的vector,他output都給你一張非常像的東西,那一張非常像的東西不知道怎麼回事,就騙過了discriminator,那個是discriminator的罩門,他無法分辨那一張image,那他整個就fail掉了,但並不代表你的machine真的得到好的結果。
link |
好,我要說的大概就是這個樣子,後面是一些reference給大家參考。