back to index
ML Lecture 20: Support Vector Machine (SVM)
link |
方法之間呢,其實如果你很熟悉整個Machine Learning的原則的話,不同的方法之間,它們其實是非常像的,所以其實就算你沒有辦法把所有方法都學過,其實也是一法通萬法通,就Machine Learning的方法其實非常非常多的,我覺得你其實並不需要很積極盈盈的把所有的方法都覺得你應該要學過一遍,掌握幾個大原則,其實你就可以了解大部分的方法。
link |
Support Vector Machine是什麼呢?Support Vector Machine呢,它有兩個特色,第一個呢,是它用了Hinged Loss,等一下我們會講Hinged Loss是什麼,另外一個呢,是我覺得它最厲害的地方,它有一個Kernel Tree,把Hinged Loss加上Kernel Tree,就是Support Vector Machine,就是SVM。
link |
我們現在講一下Hinged Loss是什麼,回到我們在開學的時候講過的Binary Classification的問題,我們講過說在理想上Binary Classification應該要怎麼做呢?在理想上我們期待說,我們知道說一個Machine Learning的Solution,它往往就有三個Step,在Binary的Classification裡面,第一個Step是,我們想要第一個Function,G of S。
link |
這個G of S呢,它裡面有另外一個Function,F of S,當F of S大於0的時候,它的Output就是正1,代表某一個Class,當F of S小於0的時候,它的Output就是負1,代表另外一個Class。
link |
那我們現在的Training Data呢,我們是Supervisor Buffer,所以每一筆Data都有一個Label,White Hat,我們現在假設White Hat就用正1和負1來表示,分別代表兩個不同的Class,而之前在講Logistic Regression的時候,我知道說我們在講White Hat的時候,我們是用1跟0表示,那這邊要用正1和負1來表示比較順。
link |
那你知道說用正1和負1來表示,用1跟0來表示是講一件事情,講的是同一件事情,就只是朝三暮四的差別而已。
link |
但是這邊如果用正1和負1的話,等一下在寫式子的時候是會比較順,所以這邊用正1和負1,只要記得它的差別就好。
link |
那Loss Function呢,理想上,一個最理想的Loss Function,就是寫成像下面這個樣子。
link |
當今天呢,這個G of X的Output跟White Hat不一樣的時候,Machine就得到一個Loss1,如果一樣的時候就沒有Loss。
link |
所以一個很理想的Loss Function是Summation over我們今天所有的Training Data,然後呢,對每一筆Training Data都代進G of X裡面看它的Output是多少,它可能Output正1也可能Output負1。
link |
接下來看它的Output跟White Hat是一樣的還是不一樣,如果是不一樣的,你就得到一個Loss1,反之呢就是0。
link |
我這邊用Delta加一個括號的意思就是,裡面這件事情如果為真的話,Delta這個Function的Output就是1。
link |
所以如果G不等於Y,那Delta的Output就是1。
link |
所以我們現在的Loss就變成,G在Training Set上總共犯了幾次錯誤,那我們當然希望它犯的錯誤是越小越好。
link |
但是在今天這個Task裡面,你要做Optimization,你要用第三步找一個好的Function,這件事情變得有點困難,因為你的Loss是不可為分的。
link |
這個東西是沒有辦法為分的,所以你根本沒有辦法用Gradient Descent來解它。
link |
怎麼辦呢?我們把這個Delta用另外一個Approximate的Loss來表示,直接Minimize這個Delta做不到。
link |
所以我們不直接Minimize這個Delta,我們Minimize另外一個Loss Function,我這邊寫成小寫的L。
link |
那至於這個Loss Function可以長什麼樣子,你就可以自己隨便定了。
link |
這是我們的G,它裡面有一個F of X,這個橫軸啊,這個圖上的橫軸啊,是Ym hat乘上F of X。
link |
那我們會希望說,因為這個Ym hat可以是正一,也可能是負一。
link |
那麼希望如果Ym hat是正一的時候,F of X要越positive越好。
link |
Ym hat如果是正一的話,F of X要越大越好。Ym hat如果是負一的時候,F of X應該要是越負越好。
link |
所以整體說來,你會希望Ym hat乘上F of X兩者相乘以後,它的值越大越好。
link |
它們要是同項,它們要是同號的,它們兩個乘起來要越大越好。
link |
所以今天原則就是,如果我們把縱軸當作是Loss的話,原則就是越往右,Ym hat乘F of X越大,Loss就應該要越小。
link |
那我們剛才講的理想的狀況是什麼樣子呢?我們剛才講的理想的狀況是,假設今天Ym hat跟F of X它們是反向的。
link |
它們相乘以後,你得到的值是負數的話,那你得到的Loss就是1。
link |
反之如果它們是同項的,你的Loss就是0。這個是理想的狀況,但這件事情是沒辦法為分的。
link |
那我們現在做一個proximation,我們把delta用L來取代,我們把delta用L來取代。
link |
這個縱軸就是L的值,你可以選各種各式各樣不同的function來當作L這個function。
link |
舉例來說,你可以說我現在Loss的定法是,我希望當Ym hat等於1的時候,F of X跟1越接近越好。
link |
Ym hat等於負1的時候,F of X跟負1越接近越好。這個是square loss。
link |
那square loss它其實可以寫成這個樣子,square loss的這個Loss可以寫成Ym hat乘上F of X減1的平方。
link |
為什麼呢?如果我們今天Ym hat代1的話,這個function就變成F of X減1的平方。
link |
如果Ym hat代負1的話,這個function就變成負F of X減1的平方。
link |
那負F of X減1的平方可以寫成,因為它在平方裡面,所以可以把負號拿掉,F of X加1的平方,也就是F of X減負1的平方。
link |
所以當你寫這個式子的時候,你就意味著如果Ym hat等於1的時候,F of X要跟1越接近越好。
link |
Ym hat等於負1的時候,F of X要跟負1越接近越好。
link |
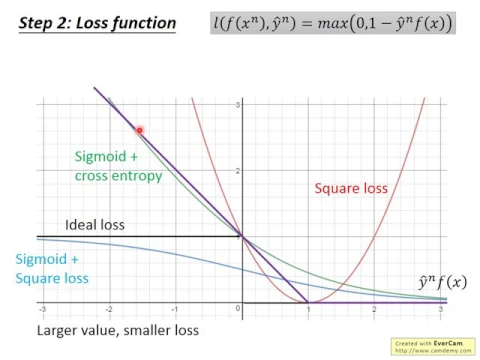
square loss的function,你把這個function畫出來,它對Ym hat乘以F of N的變化是寫成這樣子。
link |
但是這個東西是不合理的,我們一開始在講binary classification的時候,我們就講過,你用square loss是不合理的。
link |
從這個圖上你又可以更明確的看出它的不合理性,因為我們不希望說Ym hat跟F of N乘起來很大的時候,居然有一個很大的Loss。
link |
另外一個是sigmoid加square loss,這邊我們sigmoid function就用一個sigma來表示。
link |
我們希望Ym hat等於1的時候,F of Xn趨近於1等於負1的時候,F of Xn趨近於0。
link |
為什麼呢?如果你把Y hat N代1的話,那沒有問題,很直覺的就是希望這個output跟1越接近越好。
link |
代負1的話,變成sigma of F of sigma of負F of X減1的平方。
link |
sigma of負F of X是什麼呢?
link |
如果你了解這個sigmoid function的特性的話,你把裡面的值取一個負號,其實就是1減sigma of F of X。
link |
我想這個不會想一下的話應該可以體會,減1的平方。
link |
然後這個1可以消掉,所以就變成sigma of F of X的平方。
link |
總之你寫這個式子的意思,就是希望F of X通過sigma function以後,如果它的答案是1,它就要接近1,如果答案是負1,它就要接近於0。
link |
我們之前有講過說,其實你在做logistic regression的時候,你不會用square loss當作你的loss,因為它的performance不好。
link |
我們之前應該也有實地操作過,你不會用square loss,其實你會用cross entropy。
link |
如果用cross entropy的話,在logistic regression的時候,我們其實真正用的是cross entropy。
link |
cross entropy的意思我們其實之前講過,就是你的sigma of F of X代表了一個distribution,代表一個distribution。
link |
你的ground truth是另外一個distribution,兩個distribution之間的cross entropy,就是你要去minimize的loss。
link |
如果你回頭過去把square loss的function寫出來的話,你會發現,其實這個function可以寫成log一加exponential負y n hat F of X。
link |
這邊我們就不做多餘的推導,這比較麻煩,自己回去推一下就知道了。
link |
這個式子是不是合理的呢?它其實是合理的。你想想看,當你今天的y n hat乘上F of Xn,趨近於無窮大的時候,
link |
當它趨近於無窮大的時候,exponential負的無窮大是0,那就變成log一加0,得到的結果是0。
link |
所以當這一項趨近於無窮大的時候,這個sigma一加cross entropy這樣的loss function,它是綠色的這一條,它會趨近於0。
link |
如果你今天y n hat F of X它的負很大的時候,exponential裡面會是正的很大,再加上1,它的值會很大,再取log以後,它還是無窮大。
link |
log只能跟exponential消掉,如果exponential這裡面是無窮大的話,得到的結果還是無窮大,所以你得到的值是無窮大。
link |
我在這邊我特別偷偷把它除了一個log2,你對loss function除一個constant,不會影響你最後找出來的解。
link |
我們這邊偷偷除了一個log2,為什麼呢?因為我們要偷偷除log2以後,你可以讓它變成剛才ideal的loss的upper bound。
link |
也就是說,我就可以claim說,我們雖然沒有辦法minimize ideal的loss,就黑色這一條線,但是我們可以去minimize它的upper bound,希望minimize upper bound就可以順便minimize這個ideal的loss function。
link |
那我們可以比較一下這兩條曲線,你可以比較這兩條曲線,你就可以比較了解說,為什麼我們之前會選擇用cross entropy,而不是用square error來當作我們的loss function,在我們做logistic regression的時候。
link |
可以想想看,我們今天如果我們把ylhat,所以f of x,從-2移到-1的時候,如果是square error,它的變化很小,如果是sigmoid加cross entropy,它的變化就非常大。
link |
那所以對sigmoid的這個function來說,它在這種極端的case,在你的值非常的negative的時候,在值非常negative的時候,照理說應該要有很大的規定,你應該趕快調整你的值。
link |
但是實際上不是如此,因為在值很大的時候,當你在這一項,ylhat乘上f of x非常negative的時候,你調整你的值,對你最後的total loss影響不大。
link |
所以就會變成說,對這個sigmoid加square loss的case來說,就算是它調整了它negative的值,它也沒有辦法得到太多的回報,所以它就會不想要調整那些非常negative的值。
link |
那對這個cross entropy來說,它的努力是可以得到回報的,所以它就會很樂意把原來很negative的值,把它往正的地方推。
link |
所以我們用cross entropy的時候,在實作上,你會比square error還更容易training,所以我們在做logistic regression的時候,都是用cross entropy。
link |
那hinged loss呢?hinged loss它是寫成一個很特別的式子,它寫成這樣,它說我們的loss function是maximum,其實我們剛才在講zero-sharp learning的時候,其實是有看到類似的function。
link |
我們這邊寫成maximum括號0跟1減y-hat f of x,0跟1減y-hat f of x。今天如果y-hat代1,那loss function就是max0跟1減f of x。
link |
那什麼樣的狀況下,今天我們會有一個zero的loss呢?因為這邊是max0跟1減f of x,所以這個function最小值是0。
link |
什麼時候會是達到這個function最小值,會達到loss是0最完美的狀況呢?只要1減f of x小於0就行了。
link |
1減f of x小於0的時候,這個loss的值就會是0,也就是說只要f of x大於1的時候,這個loss就會是0。
link |
那如果今天y-hat等於負1的時候,這個loss function會寫成0跟1加f of x的max。
link |
那要讓loss等於0,我們就是要讓1加f of x小於0,也就是要讓f of x小於負1。
link |
所以今天你用pinch loss做training的時候,你想要讓Machine做到的事情,什麼時候Machine會覺得它的loss是0,它已經做到完美的case了呢?
link |
它如果今天對一個positive的example來說,f of x大於1的時候,就是完美的case。
link |
對一個negative example來說,它的f of x小於負1的時候,它就是一個完美的case。
link |
它的值不用太大,你把f of x變成2,loss也不會比較小,你把f of x變成負2,loss也不會比較小。
link |
如果你把hinged loss畫出來的話,它長得像是這個樣子,它是紫色的這一條線。
link |
那你會發現說呢,在紫色的這一條線上,在這一段,只要y-hat乘上f of x大於1的時候,就已經夠好,你的loss就已經是0,再更大都沒有幫助。
link |
但是今天如果y-hat f of xn是positive的example,是positive的,是positive還不夠好。
link |
就是如果今天y-hat跟f of xn是同項,那machine在做classification的時候,它已經可以得到正確的答案。
link |
根據我們剛才定出來的step1定出來的function,它已經可以得到正確的答案。
link |
但是對hinged loss來說,這樣還不夠好。
link |
它會說你只得到正確的答案還不夠,你要比正確的答案還要好過一段距離,這個距離就是margin。
link |
也就是說,當你今天y-hat乘上f of x,當y-hat乘上f of x還沒有大於1的時候,你其實還是會有penalty的,促使這個machine讓y-hat乘上f of x大於1。
link |
你可以想想看,如果這邊是1的話,hinged loss才會是ideal loss的一個type的upper bound。
link |
如果你用其他值的話,它可能就不是一個那麼tight的upper bound。
link |
所以hinged loss跟我們剛才看到的cross entropy一樣,它也是一個我們ideal loss function的upper bound。
link |
所以我們也會期待說,我們可以minimize hinged loss,然後就可能可以得到minimize ideal loss function的效果。
link |
那如果我們比較hinged loss跟cross entropy的話,你會發現說,它們最大的不同來自於它們對待已經做得好的example的態度。
link |
今天如果我們把y-hat乘上f of x從1挪到2,對cross entropy來說,你可以得到loss的下降。
link |
所以cross entropy它會想要好還要更好。如果你今天已經可以把y-hat乘上f of x的值做得夠大,
link |
cross entropy它有動機要讓它的值更大,因為這樣還可以減少loss。
link |
但是對hinged loss來說,如果你採用的是hinged loss function,它是一個及格就好的loss function。
link |
所以今天只要你的值大過你的margin的時候,就結束了。
link |
OK,就這樣子了,它就不會想要再做得更好。
link |
Nathan問說,在實作上到底hinged loss跟cross entropy它們的performance有什麼樣的差別呢?
link |
在實作上的差別可能沒有你想像的那麼顯著。
link |
有一些時候我們會看到hinged loss可以略勝cross entropy,但其實也沒有贏那麼多。
link |
那你採用hinged loss的時候有一個好處是它比較不害怕outlier,
link |
比較不害怕outlier,那你認出來的結果會是比較robust的。
link |
那這個等一下我們在講kernel的時候會比較明顯的看到這個結果。
link |
那如果你看這個hinged loss跟cross entropy的差別的話,這個cross entropy就好像是說,
link |
你現在期末可能有很多科目要讀,但是你就只想要拼死讀一科而已,
link |
你想要把某一科考到100分,其他如果你唸不起來了,你就會放棄,
link |
那hinged loss它會顧全所有的科目,它所有的科目都考到及格就好了,
link |
所以如果今天你有outlier的時候,hinged loss會給你比較好的結果,
link |
cross entropy會給你比較差的結果。
link |
等一下我們在別的角度來看這個問題的時候可能是會更清楚的。
link |
好,那現在什麼是linear的SVM?
link |
linear的SVM是說我們現在的function就是linear,
link |
我們現在的f of x就是feature x裡面的每一個feature xi乘上它的對應的位wi,
link |
那我們可以把這件事情看作是兩個vector的inner product,
link |
其中一個vector是model的parameter w跟bconcatenate起來的一個vector,
link |
另外一個vector是feature的vector,x這個x的feature的vector跟econcatenate起來的結果。
link |
如果你把這兩個vector做inner product的話,那你就會得到左邊這個式子。
link |
所以在等一下以下的說明裡面,我們把w跟b串起來的那個vector,
link |
這個東西是你的model的參數,是要透過training data把它找出來的。
link |
下面的x跟econcatenate起來的結果,我們就當作是一個新的feature,
link |
你就想像每一個feature下面都有concatenate的e,
link |
這樣你就可以把bias這一項省略掉。
link |
所以一個function,你就寫成w的transpose乘上x,
link |
或w跟x的inner product。
link |
那在SVM裡面,你的這個f長這個樣子,
link |
然後你就說f大於0的時候是屬於某一個class,
link |
f小於0的時候是另外一個class。
link |
那如果是loss function呢?如果是loss function的話,
link |
在SVM裡面,它的特色就是它採用了hinge loss這個loss function。
link |
那通常呢,你還會加上一個這個regularization的term。
link |
那這個loss function呢,它是一個convex的function。
link |
為什麼呢?因為我們知道hinge loss的loss function,
link |
它長得是這個樣子,就像IOU的那個activation function的形狀。
link |
所以它是一個convex的function。
link |
而這項L2的regularization,它也是一個convex的function。
link |
所以你所有的loss都是convex的function,
link |
regularization也是convex的function。
link |
當你把這些convex的function疊加起來以後會發生什麼事情呢?
link |
把convex function疊加起來仍然是convex function。
link |
所以你今天的loss function其實就是一個convex的function。
link |
好,如果是convex的function的話呢,
link |
你不管從哪個地方做initialization,
link |
那你可能會問說,這個東西它在某些點不可為啊,對不對?
link |
你這個hinged loss,它在某些點是不可為的,
link |
那你把很多這些不可為的convex的function疊起來,
link |
它就長這樣,它還有很多稜稜角角的地方,
link |
你想想看,我們之前在講deep learning的時候,
link |
你有IOU的exclamation function,你有mixed out network,
link |
但是其實呢,你都是可以用歸根descend去做optimization,
link |
我們可以用歸根descend去做optimization,
link |
好,其實呢,如果我們比較logistic regression跟linear SVM的差別,
link |
它唯一的差別就只是我們怎麼定loss function,
link |
你用Hinged loss就是linear SVM,
link |
你用Cross entropy loss就是logistic regression,
link |
而這個function,它沒有必要一定要是linear,
link |
只是它如果是linear的話,有很多好的特質,
link |
但是如果它不是linear的,也ok,
link |
你也可以用歸根descend來check,
link |
所以SVM是可以有deep的版本的,
link |
我這邊列一個reference給大家參考,
link |
當你今天在做deep learning的時候,
link |
你不是用Cross entropy當作你的minimization的對象,
link |
當作你的loss function,而是改用Hinged loss的話,
link |
你其實就是有一個deep版本的SVM,
link |
我做的是deep learning,我做的是SVM,
link |
怎麼用歸根descend來learn SVM呢?
link |
我知道你傳統上聽到的方法都不是用歸根descend來learnSVM,
link |
但SVM確實是可以用歸根descend來做training的,
link |
有一個用歸根descend來train SVM的方法叫做Picasso,
link |
我這邊忘了附reference,我之後再附上去,
link |
總之SVM是可以用歸根descend train,
link |
我們現在的loss function長這個樣子,
link |
然後它是一個Hinged loss,
link |
我們只要能夠對我們的model裡面的某一個位Wi,
link |
對這個summation裡面的某一個loss可以做偏微分,
link |
所以我們可以把這一下拆成partial f分之partial loss function,
link |
我們先用f對loss function做偏微分,
link |
因為我們知道f of xn就是一個linear的function,
link |
它是兩個vector的inner product,
link |
那你得到的其實就是xn的第一個dimension的value,
link |
那前面這個用f對loss function做偏微分,
link |
這個f它就是這個Hinged loss的loss function,
link |
這個Hinged loss的loss function,
link |
它有兩個operation的region,
link |
它可以是operate在0是max的case,
link |
它可以是operate在1減y乘上f of x是max的case,
link |
如果它operate在0是max的case,
link |
它operate在1減y f of x是max的case,
link |
那什麼時候會operate在哪一個case呢?
link |
這個是depend on你現在的model w是多少,
link |
也就是說假如你現在的1減y f of x,
link |
1減y hat f of x大於0,
link |
這個f of x的值取決於你現在的model w,
link |
那就是y hat乘上f of x小於1這樣,
link |
當y hat乘上f of x小於1的時候,
link |
你的model作用在這個region,
link |
作用在這個region就得到這個為分值,
link |
summation over all the training data,
link |
再看每一筆training data的y hat乘上f of x是不是小於1,
link |
dependent現在的參數是什麼,
link |
你就把wi減掉learning rate,
link |
乘上你的第二個feature裡面的di為,
link |
所以SVM是可以用歸電descent來解的,
link |
所以如果你只是要寫linear的SVM的話,
link |
那我們現在把我講的hinge loss的function,
link |
我們現在把這個hinge loss,
link |
0,1減yn hat乘上f of xn,
link |
1減yn hat乘上f of xn,
link |
我只是換了一下notation而已,
link |
我們現在的目標就是要minimize total loss,
link |
你說我們要0跟1減yn hat f of x裡面,
link |
也大於1減yn hat乘上f of x,
link |
εn大於等於1減yn hat乘上f of x,
link |
這個εn它是0跟1減yn hat的max,
link |
然後我今天說εn可以大於0也可以大於它,
link |
但是它不見得是正好等於它們的max,
link |
它可以是它們的max加1加2加100萬,
link |
所以上面跟下面這兩個式子好像是不一樣,
link |
就假設我們不考慮這個loss function的話,
link |
所以變成yn hat乘上f of x,
link |
你今天加了minimize loss function l這件事情以後,
link |
因為我們現在要去minimize l of f,
link |
雖然我們下面只有下constraint說,
link |
εn要大於等於1減yn hat f of x,
link |
它不需要正好等於1減yn hat f of x,
link |
它就符合這個constraint了,
link |
也大於它就符合這個constraint,
link |
它不需要等於它們兩個之間比較大的那一個,
link |
就符合下面這個constraint,
link |
當我們要做的事情是要minimize l的時候,
link |
那當εn它的constraint是要大於等於0,
link |
跟大於等於1減yn hat f of x,
link |
要minimize total loss的時候,
link |
會跟下面這個紅框框裡面的式子是一樣的,
link |
所以當我們把上面這個紅框框裡面的式子,
link |
轉成下面這個紅框框裡面的式子的時候,
link |
這個就是你所熟悉的SVM了,對不對?
link |
就yn hat跟f of x要是同號的,
link |
但是呢,這個margin是soft的,
link |
有時候你沒有辦法滿足這個margin,
link |
沒有辦法讓yn hat乘上f of x大於等於1,
link |
你把你的margin稍微做一下放寬,
link |
所以這個εn叫做slack variable,
link |
它可以讓你的margin變得比較鬆,
link |
它必須要,它有一個constraint,
link |
你會有一個你要minimize的對象,
link |
它是一個quadratic programming的problem,
link |
那你就可以帶一個quadratic programming的solver,
link |
那其實你不見得要帶quadratic programming的solver來解,
link |
SVM其實可以用gradient descent來解。
link |
kernel map,你隨便google就有一大堆的東西,
link |
實際上啊,我們找出來的weight,
link |
可以minimize loss function的那個weight,
link |
是我們的data的linear combination,
link |
其實是summation over,
link |
所有的training data的vector point xn,
link |
對所有的xn都乘以上一個weight,
link |
其實就是你的data point的linear combination,
link |
用Lagrange multiplier,
link |
我們可以用gradient descent,
link |
gradient descent的式子呢,
link |
那這個是對Wi update的時候的式子,
link |
假設現在W有k位update的式子呢,
link |
把這邊W1到Wk串成一個vector,
link |
到xk上標n也串成一個vector,
link |
乘上summation over xn,
link |
你的W是一個zero vector,
link |
你都是加上一個data point,
link |
linear combination,
link |
your gradient descent解出來的W,
link |
就是W的linear combination,
link |
這個cn of W是F對loss function的偏微分,
link |
如果我們今天用的是hinged loss,
link |
如果我們是用的是hinged loss的話,
link |
它有兩個operation的region,
link |
如果它作用在max等於零的那個region的話,
link |
所以當你在用hinged loss的時候,
link |
你用hinged loss的時候呢,
link |
也就是不是所有的xn都會被拿來加到W裡面去,
link |
它的這個linear combination的weight可能會是sparse,
link |
所謂linear combination的weight是sparse的意思是說,
link |
它對應的alpha star值等於零,
link |
它的alpha star不等於零的那些xn呢,
link |
它就是support vector,
link |
那你才會決定說你最後的model呢,
link |
而這些可以決定這個parameter長什麼樣子的data point,
link |
它們就叫做support vector,
link |
所以叫做support vector machine,
link |
不是所有的點都會被選作support vector,
link |
少數的data point會被選作support vector,
link |
你今天如果你的loss function,
link |
你在做logistic regression選的是cross entropy,
link |
因為如果你看cross entropy的那個loss function,
link |
所以你今天你解出來的這個alpha呢,
link |
你解出來的alpha就會是sparse,
link |
今天那些不是support vector的data point,
link |
你把它從data base裡面remove掉,
link |
它對你的最後的結果是一點影響都沒有的,
link |
如果今天有一個奇怪的outlier,
link |
你只要不要把它選做support vector,
link |
如果你是用logistic regression,
link |
每一筆data對你最後的結果都會造成影響。
link |
好,那今天我們把w寫成是data point的linear combination,
link |
最大的好處就是我們可以使用等一下說的kernel的trick,
link |
我們已經知道說w就是data point的linear combination,
link |
我們把所有的data point S1到S大n排起來,
link |
我們把這個matrix乘上這個vector,
link |
X的這個column的linear combination,
link |
也就是matrix S乘上vector α,
link |
所以w可以寫成matrix S乘上vector α。
link |
我們可以改一下我們的function的樣子,
link |
我們本來的function是寫成w的transpose乘上X,
link |
所以f of X就是α的transpose乘上X的transpose乘上X。
link |
X的transpose是一堆row疊在一起,
link |
αtranspose是一個倒下來的vector,
link |
你把這個vector乘上這個matrix,
link |
把這個vector X乘上這個X的transpose以後,
link |
你得到的結果是第一個dimension,
link |
就是X1跟X的inner product,
link |
第二個dimension就是X2跟X的inner product,
link |
最後一個dimension就是Xn跟X的inner product。
link |
接下來你把這個vector跟這個vector,
link |
再做inner product以後,
link |
Summation over αn乘上Xn跟X的inner product,
link |
它跟每一個Xn database裡面的每一個Xn,
link |
都乘上inner product以後,
link |
再把inner product的結果,
link |
哇,那個database裡面每一個Xn,
link |
因為假如你是用hinged loss,
link |
所以你只需要考慮那些α不等於0的vector就好了。
link |
我們會把Xn跟X做inner product這件事情,
link |
就是Xn跟X的inner product,
link |
叫做kernel function。
link |
好,那我們今天已經知道step 1,
link |
把Xn跟X代進kernel function,
link |
再乘上αn再summation以後的結果。
link |
我們今天要maximize的對象變成什麼呢?
link |
inner product裡面沒有參數,
link |
ok,inner product你本來就知道了,
link |
那我們在step 2跟step 3的時候,
link |
它可以讓我們的total loss最小。
link |
我們叫我們loss function,
link |
就寫成summation over所有的每筆data的,
link |
這個小l的loss function。
link |
而小l的loss function,
link |
就是step 1的這個function。
link |
你可以把這個function帶進來,
link |
summation over n前面已經用過了,
link |
summation over n',
link |
但是都是summation over所有的training data。
link |
我們不需要知道x的vector是多少,
link |
其實只有x跟另外一個vector z,
link |
它們之間的inner product的值。
link |
或者是我們只需要知道這個kernel function,
link |
我們就可以做所有的optimization。
link |
k of xn'跟xn的value是什麼,
link |
我只需要知道k of xn跟x的value是什麼,
link |
xn跟xn的vector長什麼樣子,
link |
這個呢,等一下看到這一招可以給我們帶來一些好處,
link |
這一招呢就叫做kernel trick。
link |
那其實這個kernel trick不是只能用在SVM裡面,
link |
這個w等於β的linear combination這件事情,
link |
像logistic regression,
link |
所以你也可以有kernel-based logistic regression。
link |
linear regression,
link |
所以你也可以有kernel-based regression。
link |
好,那這個kernel trick怎麼用呢?
link |
這個kernel trick是這樣,
link |
你可能要對你input的feature,
link |
做一個feature transform,
link |
它才能用linear model來處理。
link |
如果在neural network裡面,
link |
我們就用好幾個hidden layer,
link |
來做feature transform。
link |
先做feature transform,
link |
在feature transform上面,
link |
再去apply linear SVM,
link |
在feature transform以後,
link |
再去apply linear model。
link |
那我們假設feature transform以後的結果是,
link |
我們把final x變成x1的平方,
link |
feature和feature之間,
link |
那如果我要算kernel xz的時候,
link |
x跟z的kernel function,
link |
他們的做完transition form以後,
link |
做inner product的值的話,
link |
都帶到這個feature transform的function裡面,
link |
我們就可以直接做inner product,
link |
x1,z1加x2,z2的平方是什麼?
link |
這兩個vector的inner product。
link |
做feature transform,
link |
等同於他們在原來feature transform之前,
link |
先做inner product以後,
link |
代進kernel function以後的output,
link |
會比先做feature transform,
link |
再做inner product,還要更快速。
link |
那如果你用kernel trick的話,
link |
final x跟final z的inner product
link |
跟final z的inner product
link |
就是x跟z的inner product
link |
把x跟z做inner product
link |
high dimension,再做inner product的話,
link |
在high dimension,這個dimension
link |
是ch2維,如果今天的feature
link |
dimension越大,k值越大的話,
link |
所以,你先做完feature transform
link |
再做inner product,是會比你先
link |
做inner product再取平方,還要
link |
z做完feature transform後的結果。
link |
先做feature transform,再做inner product。
link |
kernel basis的,我把那個
link |
這個式子啊,exponential x-z
link |
兩個high dimensional vector
link |
無窮多維再做inner product,你做不到。
link |
因為無窮多維是什麼樣子,你根本不知道。
link |
空間裡面,去做inner product。
link |
你看,我們可以把這個exponential
link |
好,接下來呢,把x的none跟z的none
link |
這兩項呢,提出來,剩下exponential
link |
x跟z的inner product。
link |
它跟z有關,剩下exponential的x
link |
乘以z。exponential的x乘以z
link |
你不用對它做tiler extension,就變成
link |
cxczx跟z的inner product
link |
x跟z的inner product的平方。
link |
只有一個dimension,一個是cx,
link |
一個是cz的inner product。
link |
inner product在平方,我們已經看過
link |
先做inner product在平方,其實
link |
可以拆成是兩個high dimension
link |
等於兩個high dimension
link |
的vector做inner product的結果。
link |
這個high dimension的vector
link |
都串起來,把它串成一個很長的vector。
link |
串起來,串成一個很長的vector。
link |
無窮長的vector,然後它們做inner product。
link |
有可能蠻容易overfitting的。
link |
所以,如果你用RBFkernel的時候,有時候要小心
link |
你可能會在training data上
link |
但是在testing data上,得到很糟的performance。
link |
Symoy的kernel。Symoy的kernel
link |
做hyperbolic tangent。
link |
那至於,x跟z的inner product做hyperbolic tangent
link |
是哪兩個vector做inner product
link |
的結果,哪兩個highlight major vector
link |
做inner product的結果,你就自己回去用
link |
這個tele-extension展開來看看,你就知道了。
link |
拿來做testing的時候,帶到f裡面的時候,
link |
我其實是聚散x跟我training data
link |
如果當我們用的是Symoy的kernel的時候呢,
link |
所有data裡面的xn跟xn inner product
link |
再去hyperbolic tangent,
link |
ok,你可以把它想成是只有一個hidden layer
link |
的neural network,為什麼?
link |
所有的x都做inner product
link |
再通過hyperbolic tangent,
link |
做inner product這件事情,其實就
link |
當作這個neural的weight,
link |
那筆data拿出來當作第二個neural的weight,
link |
當作這個neural的weight,
link |
然後把它們都通過hyperbolic tangent
link |
neural network,只是它只有一個
link |
neural network裡面,它的每一個
link |
neural的weight,就是某一筆data
link |
就是看你有幾個support vector
link |
有了這個kernel trick以後
link |
設計這個kernel function
link |
你只要有一個kernel function
link |
上的vector inner product的話
link |
有structure的data,比如說
link |
你的每一個sequence長度都還不一樣
link |
直接定它的kernel function
link |
我們知道kernel function其實
link |
投影到高維以後的inner product
link |
所以kernel function往往就是一個類似
link |
所以今天如果你可以定一個function
link |
它是evaluate x跟z的similarity
link |
比如說它是tree structure
link |
只要知道什麼算兩個sequence之間的
link |
你知道知道什麼算兩個tree structure
link |
這個kernel其實是兩個vector
link |
做inner product以後的結果
link |
inner product以後的結果嗎?
link |
但是有一個叫做Merser's theory
link |
我們就是會用一個vector sequence
link |
所以它vector sequence的長度可能都不一樣
link |
但是一段聲音訊號你沒有辦法直接用一個vector
link |
你就不要管一段聲音訊號它變成一個fixed length
link |
這個function的output應該是什麼
link |
用kernel trick apply SVM
link |
怎麼定兩個sequence之間的kernel呢
link |
這個我就把reference留在這邊
link |
support vector regression
link |
我們原來在做regression的時候
link |
我們會希望model的output跟target越近越好
link |
那如果做support vector regression
link |
漸微的距離,但我想說漸微大家不知道是什麼
link |
那就是support vector regression
link |
比如說在final quadrant裡面
link |
不是有一個recommendation的題目嗎
link |
這樣你並沒有直接optimize你的問題
link |
SVM呢,叫做ranking SVM
link |
或許你在你的final quadrant裡面
link |
屬於positive的example都聚成一類
link |
這個都留一些reference給大家參考就好
link |
deep learning跟SVM的差別
link |
那我們說deep learning的前幾個
link |
你就可以看作是一個feature transform
link |
可以看作是一個linear classifier
link |
我們先apply一個kernel function
link |
high dimensional上面
link |
然後在high dimensional上面
link |
我們就可以applylinear classifier
link |
只是在SVM裡面一般linear classifier
link |
我列了一個reference給大家參考
link |
然後你把不同的kernelcombine起來
link |
SVM就好像是只有一個hidden layer
link |
當你把kernel再做linear combination的時候