back to index
ML Lecture 21-1: Recurrent Neural Network (Part I)
link |
好,那接下來呢,我們來講一下這個recurrent neural network。
link |
那recurrent neural network呢,它其實也可以做到我們在前一堂課裡面講的sequence laboring的task。
link |
那最後呢,我們再來說它們有什麼樣的不同。
link |
那我們這邊要舉的例子呢,是slot filling。
link |
我們知道說現在很流行呢,做一些智慧客服啊,什麼之類的東西。
link |
那這種智慧的客服或智慧訂票系統裡面呢,你往往需要slot filling這個技術。
link |
那slot filling指的是什麼呢?
link |
slot filling指的是說,那比如說假設有一個人對你的訂票系統說,
link |
I would like to arrive Taipei on November 2nd。
link |
那你的系統要自動知道說,你的系統裡面有一些slot。
link |
比如說在這個訂票系統裡面呢,它會有一個slot叫做destination。
link |
它會有一個slot呢,叫做time of arrival。
link |
那你的系統要自動知道說呢,這邊的每一個詞彙,它屬於哪一個slot。
link |
那你的系統呢,要知道說,台北屬於destination這個slot。
link |
那你的系統要知道說,November 2nd呢,屬於time of arrival這個slot。
link |
那其他的詞彙呢,就不屬於任何slot裡面。
link |
其實這個問題,你當然也可以用一個feedforward的neural network來解。
link |
也就是說,噢,我疊一個feedforward的neural network,然後它的input呢,就是一個詞彙。
link |
比如說你把台北呢,變成一個vector,丟到這個neural network裡面去。
link |
但是你要把一個詞彙丟到neural network裡面去,你必須要先把它呢,用一個向量,vector來表示。
link |
那怎麼把一個詞彙用一個向量來表示呢?
link |
方法實在太多了,最難易的方法呢,就是one-off encoding。
link |
那當然你用one-off vector呢,來表示一個詞彙呢,也是可以的。
link |
那或者是呢,有一些beyond one-off encoding的方法。
link |
比如說,呃,呃,有時候呢,如果你只是用one-off encoding來描述一個詞彙的話,你會遇到一些問題。
link |
因為有很多詞彙,你可能從來都沒有見過。
link |
所以你會需要在one-off encoding裡面多加一個dimension。
link |
這個dimension呢,代表other。
link |
然後,所有的詞彙,如果它不是在我們詞言裡有的詞彙,就歸類到other裡面去。
link |
那比如說,呃,呃,甘道夫不在這個vector,不在我們的vector,不在我們的vocabulary裡面,他就歸類到other。
link |
或者是這個,呃,索,索倫,呃,他不在這個vocabulary裡面,他就歸類到這個vector。
link |
那你也可以用某一個詞彙的字母來表示它的vector。
link |
如果你用某一個詞彙的字母的n-gram來表示那個vector的話呢,你就不會有某一個詞彙不在詞典中的問題。
link |
比如說,你有一個詞彙叫做apple,那apple呢,它裡面有出現app,有出現ppl,有出現poe。
link |
那在這個vector裡面,對應到app的那個dimension就是1,對應到poe的dimension就是1,對應到ppl的dimension就是1,然後其他的都是0。
link |
好,無論如何,假設我們可以把一個詞彙呢,表示成一個vector,那你就可以把這個vector呢,丟到一個feedforward的network裡面去。
link |
那在slot building這個task裡面呢,你就會希望你的output是一個probability distribution。
link |
這個probability distribution代表說我們現在input的這個詞彙,屬於每一個slot的機率。
link |
舉例來說,台北屬於destination的機率,還有台北屬於time of departure的機率等等。
link |
但是呢,光只有這樣是不夠的,feedforward network呢,沒有辦法solve這個problem。
link |
為什麼呢?假設現在有一個使用者說要arrive台北on november 2nd,那arrive是other,台北是destination,on是other,november 2nd都是時間。
link |
但是如果另外一個使用者說leave台北on november 2nd,那台北這個時候它應該是place of departure,它應該是這個出發地而不是目的地。
link |
但是對neural network來說,input一樣的東西,output就是一樣的東西。
link |
而你input台北這個詞彙,它output要嘛就都是destination機率最高,要嘛就都是place of departure的機率最高,要嘛就都是出發地的機率最高。
link |
你沒有辦法讓它有時候出發地的機率最高,有時候目的地的機率最高。
link |
那怎麼辦呢?這個時候我們就希望我們的neural network它是有記憶力的。
link |
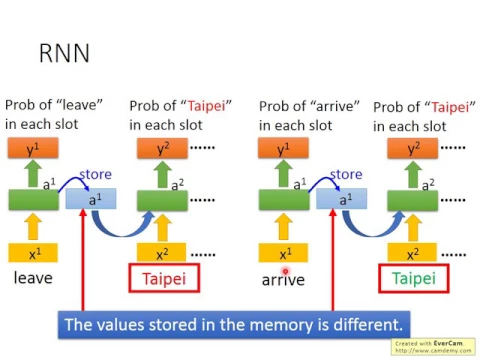
如果今天neural network是有記憶力的,它記得它在看過這個紅色的台北之前,它就已經看過arrive這個詞彙,它記得它在看過綠色的台北之前,它就已經看過leave這個詞彙。
link |
它就可以根據一段話的上下文產生不同的output。所以如果我們讓我們neural network它是有記憶力的話,它就可以解決input同樣的詞彙,但是output必須是不同的這個問題。
link |
那這種有記憶力的neural network就叫做recurrent neural network,它所寫的是rn。那在recurrent neural network裡面,每一次我們的這個hidden layer裡面的neural產生output的時候,這個output都會被存到memory裡面去。
link |
我們這邊用綠色的方塊來表示memory。當這些hidden layer裡面的neural有output的時候,它就會被存到這個藍色的方塊裡面去。
link |
那下一次如果當有input的時候,這個hidden layer,這些neural它不是只會考慮input的這個x1跟x2,它還會考慮存在這些memory裡面的值。
link |
對它來說,除了x1跟x2以外,這些存在memory裡面的值,a1、a2也是它必須要,也會影響它的output。
link |
那我想直接舉一個例子,大家可能會比較清楚。假設我們現在這個圖上的這個network,它所有的weight都是1,然後所有的neural都沒有任何的bias。然後假設所有的activation function都是linear,這樣可以不要讓計算太複雜。
link |
那現在假設我們的input是一個sequence,我們的input是111122,那我們把111122這個sequence input到這個recurrent neural network裡面去,會發生什麼事呢?
link |
首先,在你開始要使用這個recurrent neural network的時候,你必須要給memory起始值。你必須要給memory在還沒有放進任何東西的時候,你必須要給它一個初始值。
link |
比如說這邊呢,就假設在還沒有放進任何東西之前,memory裡面的值是0。那現在呢,第一個輸入1跟1。那接下來會發生什麼事呢?
link |
對這個neural來說,它接到1,它除了接到input的1跟1以外,它還接到memory的0跟0。那因為我們說所有的weight都是1,所以它的output就是2,這個neural的output也一樣是2。
link |
那接下來呢,因為所有的weight都是1,所以紅色這樣的neural呢,它們的output就是4。所以input1跟1的時候,它的output就是4跟4。
link |
那接下來呢,recurrent neural network會把這個綠色的neural的output存到memory裡面去,所以memory裡面的值就會update成2,這個2會被寫進來。
link |
所以memory裡面的值呢,就update變成2。接下來呢,再輸入1跟1,這個時候綠色的neural會有什麼樣的輸出呢?它的輸入有4個,1跟1跟2跟2,然後weight都是1,所以2加2加1加1。
link |
得到的結果呢,是6。那最後呢,紅色的neural的輸出就是6加6,是12。所以當輸入1跟1的時候,第二次再輸入1跟1的時候,輸出就是12跟12。
link |
所以對recurrent neural network來說,你就算是輸入一樣的東西,你就算給它一模一樣的input,在這個case裡面都是1跟1。它的output是有可能會不一樣的,因為存在memory裡面的值呢,是不一樣的。
link |
那原來的值呢,在這個綠色的neural的output是6跟6,那接下來6跟6呢,就會被存到memory裡面去,就會被存到memory裡面去,所以2就被洗掉,變成6。
link |
接下來呢,我們的input是2跟2,假設input是2跟2,這邊每一個綠色的neural,它考慮了4個input,2跟2跟6跟6,所以6加2加2,是多少呢?得到的值是16。那紅色的neural的output呢,就是32,所以input2跟2的時候,output是32。
link |
那今天在做recurrent neural network的時候呢,有一件很重要的事情就是,這個input的sequence啊,recurrent neural network在考慮它的時候,並不是independent。
link |
所以今天如果你任意調換input sequence的順序,比如說把2跟2挪到最前面來,那output呢,是會完全不一樣,所以在recurrent neural network裡面,它會考慮input這個sequence的order。
link |
所以今天如果我們要用recurrent neural network來處理slot feeding這個問題的話,它看起來就像是這樣,有一個使用者說,arrive Taipei on November 2nd,那arrive呢,就變成一個vector,丟到neural network裡面去。
link |
neural network的hidden layer呢,它的output呢,我們這邊寫成A1,這個A1是一排neuron的output,所以它其實是一個vector。然後呢,根據這個A1呢,我們產生Y1,這個Y1呢,就是arrive屬於每一個slot的機率。
link |
接下來呢,A1呢,會被存到memory裡面去,接下來呢,台北會變成input,那這個hidden layer呢,會同時考慮台北這個input跟存在memory裡面的A1得到A2,然後再根據A2產生Y2,Y2是台北屬於每一個slot的機率。
link |
這個process呢,就以此類推,我們再把A2存到memory裡面,再把on丟進去,那hidden layer同時考慮input on這個詞彙的vector,跟存在memory裡面的A2得到A3,然後A3再得到Y3,它代表on屬於每一個slot的機率。
link |
那這邊要注意的事情是,等有人看到這個圖就說,嗯,這邊有三個network,這個不是三個network,這個是同一個network在三個不同的時間點被使用了三次。
link |
好,我這邊呢,特別把同樣的weight呢,就用同樣的顏色來表示,同樣的weight呢,就用同樣的顏色來表示,希望大家能看得出來。
link |
好,那所以如果我們有了memory以後,剛才我們講的輸入同一個詞彙,我們希望它output不同的這個問題就有可能被解決。比如說,如果同樣是輸入台北這個詞彙,但是因為紅色台北前面接的是leaf,綠色台北前面接的是arrive,所以因為leaf跟arrive它們的vector不一樣,所以hidden layer的output也會不同,所以存在memory裡面的值也會不同。
link |
所以雖然現在x2是一模一樣的,但是因為存在memory裡面的值不同,所以hidden layer的output會不一樣,所以最後的output呢,也就會不一樣。
link |
好,那這個是recurrent neural network的基本概念,當然你這個recurrent neural network架構呢,你是可以任意設計的,比如說它當然可以是deep,我們剛才看到recurrent neural network它只有一個hidden layer,當然它可以是deep的recurrent neural network。
link |
比如說,我們把x1丟進去以後,它可以通過一個hidden layer,再通過第二個hidden layer,以此類推通過很多個hidden layer以後,才得到最後的output。
link |
那每一個hidden layer的output都會被存在memory裡面,在下一個時間點的時候呢,每一個hidden layer會再把前一個時間點存的值再讀出來,最後得到最後的output。
link |
這個process呢,就一直持續下去,這個要deep,你要疊幾層呢,都是可以的。那recurrent neural network有不同的變形,我們剛才講的呢,叫做element network,如果我們今天是把hidden layer的值存起來,在下一個時間點再讀出來,這個叫做element network。
link |
那有另外一種呢,叫做jordan network,jordan network它存的呢,是整個network的output的值,然後它再把output的值在下一個時間點呢,再讀進來,它是把output的值存在memory裡面。
link |
那傳說呢,jordan network可以得到比較好的performance,因為這邊的hidden layer啊,它是沒有target的,所以你有點難控制說它學到什麼樣的hidden information,它學到把什麼東西放在memory裡面。
link |
但是這個y啊,它是有target的,所以我們今天可以比較清楚我們放在memory裡面的是什麼樣的東西。這個recurrent neural network呢,它還可以是雙向的,什麼意思呢?
link |
我們剛才看到recurrent neural network,你input一個句子的話,它就是從句首一直讀到句尾,假設句子裡面的每一個詞彙,我們都用st來表示它的話,它就是先讀st1,再讀st加1,再讀st加2。
link |
但是呢,其實它的讀取方向也可以是反過來的,它可以先讀st加2,再讀st加1,再讀st。你可以同時train一個正向的recurrent neural network,又同時train一個逆向的recurrent neural network。
link |
把這兩個recurrent neural network的hidden layer拿出來,把這兩個recurrent neural network的hidden layer拿出來,都接給一個output layer,得到最後的y。
link |
所以你把正向的network在inputst的時候的output,跟逆向的network在inputst的時候的output,都丟到另外一個hidden layer,都丟給output layer,然後讓output layer產生yt,然後產生yt加1,產生yt加2之類的。
link |
那用bidirectional recurrent neural network的好處呢,是你的network呢,它在產生output的時候,它看的範圍是比較廣。
link |
如果今天你只有這個正向的network,正向的network,在產生yt的時候,在產生yt加1的時候,你的network只看過x1一直到st加1的input。但是,如果我們今天是bidirectional recurrent neural network,在產生yt加1的時候,
link |
你的network不只是看了x1到st加1所有的input,它也看了從句尾一直到st加1的input。
link |
那你的network呢,等於是看了整個input的sequence以後,假設你今天考慮的是slot filling的話,你的network等於是看了整個sentence以後,才決定每一個詞彙的slot應該是什麼。
link |
那這樣當然會比只看句子的一半還要得到更好的performance。
link |
那我們剛才講的recurrent neural network呢,其實只是recurrent neural network的一個最simple的版本。
link |
那我們剛才講的memory呢,是最單純的,就是我們隨時都可以把詞存到memory裡面去,也可以隨時把詞從memory裡面讀出來。
link |
但現在比較常用的memory呢,稱之為long short term的memory。這種long short term的memory呢,它的簡寫是LSTM。這種long short term的memory呢,它是比較複雜的。
link |
這個long short term的memory呢,它有三個gate。當外界,當neural network的其他部分,當某個neural的output想要被寫到memory cell裡面的時候呢,它必須先通過一個閘門,通過一個input gate。
link |
那這個input gate呢,它要被打開的時候,你才能夠把詞呢,寫到memory cell裡面去。如果它被關起來的時候,其他neural就沒有辦法把詞呢,寫進去。
link |
至於這個input gate,它是打開還是關起來,這個是neural network自己學的。所以它可以自己學說,它什麼時候要把input gate打開,什麼時候要把input gate關起來。
link |
那輸出的地方呢,輸出的地方也有一個output gate。那這個output gate會決定說,外界其他的neural可不可以從這個memory裡面把詞讀出來。
link |
那當output gate被關閉的時候,就沒有辦法把詞讀出來,只有output gate被打開的時候,才可以把詞讀出來。那跟input gate一樣,output gate什麼時候是打開,什麼時候是關起來,neural也是自己學到。
link |
那還有第三個gate呢,叫做forget gate。那forget gate是決定說,什麼時候memory cell呢,什麼時候memory呢,要把過去記得的東西忘掉。
link |
那什麼時候要把過去記得的東西呢,做一下format,把它format掉。那這個forget gate呢,什麼時候會把存在memory裡面的詞format掉,什麼時候會把存在memory裡面的詞保留下來,這個也是neural自己學到。
link |
那整個LSTM呢,你可以看成它有四個input,一個output。這四個input是什麼呢,這四個input一個是想要被存到memory cell裡面的詞,但它不一定存的進去,這要depend on input gate,要不要讓這個information過去。
link |
跟操控input gate的訊號,操控output gate的訊號,和操控forget gate的訊號。所以一個LSTM的cell呢,它有這四個input,但它只會得到一個output而已。
link |
那這邊有一個小小的冷知識啊,就是這個dash啊,你覺得它應該被放在哪裡。我投影片把它放在這邊,但並不代表我投影片就是對的,我有可能只是突然發現我寫錯了,想要改一下。
link |
好,你覺得這個dash應該放在long和short之間的同學舉手一下。沒有,好,你覺得它應該放在short跟turn之間的同學舉手一下。
link |
沒錯,它應該放在short跟turn之間,有時候會看到有人放在long跟short之間,那其實這個是比較不make sense,應該是放在short跟turn之間,因為它其實還是一個short term的memory,它只是比較長的short term memory,按照這個字面的意思,它是比較長的short term memory。
link |
因為之前我們看那個recurrent neural network啊,它的memory在每一個時間點都會被洗掉,對不對,每一次有新的input進來,每一個時間點呢,recurrent neural network都會把memory洗掉。
link |
所以它這個short term是非常short的,它只記得前一個時間點的事情,但是如果是long short term的話,它可以記得比較長一點,只要forget gate不要決定要format的話,它的值就會被存起來。
link |
好,那這個memory的cell呢,如果更仔細的來看它的formulation的話,它長得像這樣,這個是外界的input,外界要存到cell裡面的input,這個是input gate,這個是forget gate,這個是off gate。
link |
好,那我們假設呢,現在要被存到cell裡面的input叫做z,操控input gate的signal叫做zi,這個所謂操控input gate的signal,它也就是一個scatter,也是一個數值,那我們等一下會講說那個數值是從哪裡來的。
link |
反正這邊就是有一個數值被當作這個cell的input。好,那這個forget gate有一個操控它的數值是z,off gate也有一個操控它的數值是z。
link |
好,綜合這些東西以後,最後會得到一個output,這邊寫做a。好,假設我們現在cell裡面呢,在輸入這些,在有這個四個輸入之前,它裡面已經存了值c。
link |
那現在呢,假設要輸入的部分呢,輸入z,那三個gate分別是由zi、zf、zo所操控的,那output a會長什麼樣子呢?我們把z呢,通過一個activation function得到g of z,然後我們把zi呢,通過另外一個activation function得到f of zi。
link |
那這邊呢,這三個zi、zf、zo它們通過的這三個activation functionf啊,通常我們會選擇sigmoid function。那選擇sigmoid function它的意義就是sigmoid function的值是介在0到1之間的。
link |
這個0到1之間的值代表了這個gate被打開的程度,如果這個f的output呢,如果這個activation function的output是1,代表這個gate是處於被打開的狀態,反之呢,代表這個gate是被關起來的。
link |
OK,好,那接下來呢,我們就把g of z乘上這個input gate的值,f of zi,得到g of z乘上f of zi。
link |
那這個forget gate的這個zf呢,zf這個signal也通過這個sigmoid activation function得到f of zf。然後接下來呢,我們把存在memory裡面的值c呢,乘上f of zf。
link |
把c乘上f of zf,得到c乘f of zf。然後接下來,把這個c乘上f of zf,加上g of z乘上f of zi,把這兩項加起來,得到c'.
link |
c'呢,就是新的存在memory裡面的值,新的存在memory裡面的值,就是c'.所以,根據到目前為止的運算,可以發現說呢,這個f of zi,就是control這個gz,可不可以輸入的一個關卡。
link |
因為假設f of zi等於0,那gz乘上f of zi就等於0,那就好像是沒有輸入一樣。如果f of zi是等於1,那就等於是直接把gz呢,當作輸入。
link |
那這個f of zf呢,f of zf就是決定說,我們要不要把存在memory裡面的值洗掉。假設f of zf是1,假設f of zf是1,也就是forget gate被開啟的時候,
link |
forget gate被開啟的時候呢,這個時候c呢,會直接通過,c會直接通過,就等於是把之前存的值呢,還是記得。那如果是這個f of zf等於0,也就是forget gate被關閉的時候,0乘上c,過去存在memory裡面的值呢,就會變成0。
link |
然後我們把這兩個值呢,加起來,當作我們把這兩個值加起來,然後就寫到memory裡面,得到c'.
link |
那我覺得forget gate呢,它的開關呢,跟我們的這個直覺的想法呢,是相反的。
link |
而這個forget gate呢,它打開的時候,代表的是記得,它被關閉的時候,代表的是遺忘這樣子。所以它名字我覺得取得有點怪,或許不該叫它forget gate,不過反正習慣上的就是這麼做,就是這麼叫它的。
link |
好,那把這個c'呢,通過h,得到h of c'。OK,然後接下來呢,這邊有一個output gate,這個output gate呢,受z0所操控,z0通過f,得到f of z0。
link |
f of z0如果是1的話,那這邊我們會把這個f of z0跟h of c'乘起來,所以如果f of z0是1,就等於是h of c'可以通過這個output gate,如果f of z0是0,就等於呢,等於這個output就會變成0。
link |
就代表說存在memory裡面的值呢,沒有辦法通過output gate呢,被讀取出來。也許這樣你還是沒有覺得很清楚,所以後面呢,我就打算做一個人體LSTM這樣子。
link |
我從來沒有在其他地方看過人體LSTM,你可以想像我在投影片製作很久。
link |
好,那這個我們先舉一下,我們先講一下我們要舉的例子。等一下我們要舉的例子是這樣子,我們的network裡面只有一個LSTM的cell,那我們的input都是三維的vector,output都是一維的vector。
link |
那這個三維的vector,它跟output還有memory裡面的值的關係是什麼呢?這個關係是這樣子,假設第二個dimension,x2的值是1的時候,x1的值就會被寫到memory裡面去。
link |
假設x2的值是1的時候,x1的值就會被存到memory裡面去。假設x2的值是-1的時候,memory就會被reset。
link |
memory存的值就會被遺忘。假設x3等於1的時候,你才會把output給打開,才能夠看到輸出。所以,假設我們原來存在memory裡面的值是0,當這邊是1的時候,當x2等於1的時候,3會被存到memory裡面去,所以你得到的值就變成3。
link |
這邊又出現一次1,所以4會被存到memory裡面去,所以就得到7。這邊呢,x3等於1,所以output gate,所以這個7會被輸出,所以得到7。
link |
這邊是-1,如果是-1的話就會把memory裡面的值洗掉,所以看到-1下一個時間點memory的值就變成0。然後看到1就會把6存進去,所以得到的值是6。這邊1是輸出,所以得到的值是6。
link |
好,那我們就來實際做一下運算。這個是一個memory cell,這是一個LSTM的memory cell。那我們知道LSTM的memory cell呢,總共有四個input,這四個input都是scatter。
link |
這四個input的scatter是怎麼來的呢?這四個scatter是我們input的那個三維的vector乘上一個linear transform以後所得到的結果。
link |
你就把這三個vector乘上三個值再加上bias,就得到這邊的input。這三個值再乘上三個weight再加上bias,就得到他的input,以此類推。
link |
好,那這些值啊,這些值,就是你的這個input的x1,x2,x3要乘上哪些值?還有那個bias的值應該是多少?這件事情呢,是透過training data,用多一點descendancy學到的。
link |
那麼這邊只是假設說,我已經知道這些值是多少,我已經知道這些值是多少,然後呢,我現在用這樣的輸入,看會得到什麼樣的輸出。好,那我們就實際的來運算一下。
link |
不過在實際運算之前呢,我們先根據他的input呢,根據這些參數呢,來分析一下我們可能會得到的結果。那你看,在這個地方,x1乘1,其他都是乘0。
link |
所以呢,這邊呢,就是直接把x1當作輸入。好,那在我們看input gate的地方,我們看input gate的地方,他是x2乘100,bias呢,是負10。也就是說呢,假設x2沒有值的時候,因為bias是負10,所以通常input gate呢,是被關閉的。
link |
如果bias是負10的話,那通過excavation function以後呢,他會是,通過xigmoid excavation function以後呢,他的值會接近0,所以呢,代表他是被關閉的。
link |
那只有在x2有值的時候,如果x2有值,他就會比bias的這個負10還要大。如果x2帶1的話呢,他就會比bias的這個,這個,這個,這時候input呢,就是一個很大的正值,代表input gate呢,被打開。
link |
那forget gate呢,forget gate呢,forget gate呢,平常呢,都是被打開的。你會發現說,因為他bias是10,所以他平常呢,都是被打開的。所以平常都會一直記的東西,只有在x2給他一個很大的負值的時候,他會壓過這個bias,才會把forget gate關起來。
link |
那offer gate呢,offer gate平常呢,也都是被關閉的,因為他bias是很大的負值。但是如果今天x3有一個很大的正值的話,他就可以壓過bias,把offer gate打開。
link |
好,所以我們就實際的來input一下看看。我們假設g跟h都是linear的,這樣計算比較方便。然後假設呢,存在memory裡面的初始值呢,是0。好,那我們現在input第一個vector310,input310。
link |
那input310會發生什麼事呢?3乘上1,所以這邊進來的值是3,然後1乘上100,減100,所以這邊的input gate呢,約等於1,所以他是被打開的。
link |
那forget gate呢,所以1乘上3,所以通過input gate以後呢,得到的值是3。那forget gate呢,3input是310,所以forget gate是被打開的。然後呢,把0乘上1加上3。
link |
雖然forget gate是被打開的,不過裡面本來就沒有存值,所以沒有什麼影響。0乘上1加上3,所以存在memory裡面的值變成3。然後接下來呢,看offer gate,310offer gate的值呢,offer gate還是被關起來的,所以3無法通過,所以輸出就是0。
link |
好,接下來呢,input410,然後這個input的地方呢,還是4,然後這個410呢,會把input gate呢,打開,然後會把forget gate呢,forget gate呢,也會被打開。
link |
因為forget gate被打開的關係,所以3乘1加4,所以memory裡面存的值呢,會變成7。那offer gate呢,offer gate仍然是被關閉的,所以7呢,就直接沒有辦法被輸出,所以整個memory的輸出呢,仍然是0。
link |
好,接下來呢,input這個200,那input200會發生什麼事呢,input200,所以現在input變成2,然後呢,這個input gate會怎樣呢,input gate現在是200,
link |
所以它activation function的input呢,是-10,所以output呢,是趨近於0,所以0乘上2等於0,等於是input這個2呢,被input gate呢,打住了。
link |
那forget gate呢,200得到的forget gate呢,得到activation function的input呢,是10,所以forget gate呢,還是打開的。
link |
所以7乘上1加上0,原來存在memory裡面的值呢,是不動的,還是7,還是7。那這個7呢,它沒有辦法被輸出,因為offer gate呢,仍然是關閉的,所以整個output仍然是0。
link |
好,接下來呢,input是101,input是101。那input 101會發生什麼事呢,這邊input呢,仍然是1,input仍然是1。
link |
那這個input gate呢,input gate是被關閉的。那forget gate呢,forget gate這個時候呢,仍然跟原來一樣,它是被打開的,所以memory裡面存的值呢,是不變的。
link |
那offer gate呢,當你input 101的時候,你會打開offer gate,就是說activation function的input呢,變成90,通過activation function以後呢,得到1,得到1。
link |
所以你看,1乘上7等於7這樣子。OK,所以output的地方呢,會變成是有值的,由此memory裡面的值呢,存在memory裡面的值7呢,會被讀取出來。
link |
好,最後,讓我們試一下3-10。3-10,這個3呢,就被讀進來。input gate呢,會被關起來。那forget gate呢,因為這個值呢,是-1,這個值是-1。
link |
所以forget gate的activation function的input是-90,activation function的output呢,就是0。所以呢,memory裡面存的值呢,會被洗掉。memory裡面存的值呢,會乘上forget gate的output,會被洗掉,就變成0。
link |
那offer gate呢,這個時候呢,仍然是關起來的,不過它有開有關也沒差,因為反正現在呢,存在memory裡面的值呢,變成0,讀出來的值也是0。
link |
好,那你看到這邊,你可能會有一個問題,這個東西跟我們原來看到的neural network感覺很不像啊,它跟原來的neural network到底有什麼樣的關係呢?
link |
你可以這樣想,在我們原來的neural network裡面,我們會有很多的neural,我們會把input,我們會把input乘上不同的weight,然後當作是不同neural的輸入。
link |
然後每一個neural,它都是一個function,它輸入一個scatter,output,另外一個scatter。但是如果是LSTM的話呢,你其實只要把LSTM的那個memory的cell,想成是一個neural就好,懂嗎?
link |
所以,如果我們今天要用一個LSTM的network,你做的事情,只是把原來的簡單的neural,換成一個LSTM的cell。而現在的input呢,現在的input X1跟X2,它會乘上不同的weight,當作LSTM的不同的輸入。
link |
也就是說,X1、X2乘上某一組weight,變成,假設我們現在只有,這個hidden layer只有兩個neural,也就只有兩個LSTM,但實際上你不會只有兩個neural,通常可能有,比如說一千個neural,有一千個LSTM的memory cell。
link |
現在假設只有兩個neural,那X1、X2乘上某一組weight,會去操控第一個LSTM的output gate,乘上另外一組weight,操控第一個LSTM的input gate,乘上一組weight,當作第一個LSTM的input,乘上另外一組weight,當作另外一個LSTM的forget gate的input。
link |
另外一個,第二個LSTM也是一樣,X1、X2乘上某一組weight,操控它的output,它會操控它的input,操控它的output gate,操控它的input gate,操控它的input,操控它的forget gate,等等。
link |
所以我們剛才講過說LSTM它就是有四個input跟一個output,而對一個LSTM來說,它的這四個input是不一樣的,這四個input都是不一樣的,這四個input都是不一樣的。
link |
在原來的neural network裡面,一個neural就是一個input一個output,在LSTM裡面它需要四個input,它才能夠產生一個output,就好像說有的機器它只要插一個電源線它就可以跑,而在LSTM它要插四個電源線它才能跑。
link |
那所以LSTM因為它需要四個input,而這四個input都是不一樣,所以LSTM需要的參數量,假設你現在用的neural的數目,就是假設LSTM的network跟neural network的,就原來的這個,你用原來的neural的network,它們的這個neural的數目是一樣的時候,LSTM需要的參數量會是一般的neural network的四倍。
link |
從這個圖上你可以很明顯的看出來,一般的neural network只需要這個部分的參數,只需要這個部分的參數,但LSTM還要操控另外三個gate,所以它需要四倍的參數。
link |
不過這樣講,你可能還是沒有辦法很了解,你沒有辦法體會的可能是,這個跟recurrent neural network的關係是什麼呢?這個好像看起來不太像recurrent neural network。
link |
所以呢,我們要畫另外一個圖來表示它,你可以想這個圖也是要畫非常久,假設我們現在有一整排的neural,假設我們現在有一整排的neural,假設一整排的LSTM,那這一整排的LSTM裡面呢,它們每一個人的memory裡面都存了一個值。
link |
每一個LSTM的fill,它裡面都存了一個scatter,把所有的scatter接起來,把這些scatter接起來,它就變成一個vector,這邊寫成ct-1。
link |
你可以想到這邊,每一個memory裡面存的scatter呢,就是代表這個vector裡面的一個dimension。
link |
好,現在在時間點t,input一個vector xt,這個vector呢,它會首先先乘上一個linear的transform,乘上一個matrix,變成另外一個vector z。
link |
你把xt乘上一個matrix,變成z,那這個z呢,也是一個vector,z這個vector代表什麼呢?z這個vector的每一個dimension呢,就代表了操控每一個LSTM的input。
link |
所以這個z它的dimension呢,就正好是LSTM的memory cell的數目,正好就是它的數目。
link |
那這個z的第一維就丟給第一個cell,第二維就丟給第二個cell,以此類推,希望大家知道我的意思。
link |
好,那這個xt呢,會再乘上另外一個transform,得到zi,然後這個zi呢,它的dimension呢,也跟cell的數目一樣,zi的每一個dimension呢,都會去操控一個memory。
link |
所以zi的第一維就是操控它第一個cell的input gate,第二維就是操控第二個cell的input gate,最後一維就是操控最後一個cell的input gate。
link |
那forget gate呢,跟output gate也是一樣,這邊就不再贅述,你把xt呢,乘上一個transform,得到zf,zf會去操控每一個forget gate,然後xt呢,乘上另外一個transform,得到zo,zo會去操控每一個cell的output gate。
link |
好,所以我們把xt乘上四個不同transform,得到四個不同vector,這四個vector的dimension,都跟cell的數目是一樣。
link |
那這四個vector合起來,就會去操控呢,這四個vector合起來呢,就會去操控這些memory cell的運作。
link |
好,那我們知道一個memory cell呢,就是長這樣,現在input分別是z,zi,zf跟zo。
link |
注意一下就是,這四個z其實都是vector,丟到cell裡面的值呢,其實只是每一個vector的一個dimension。
link |
那因為每一個cell他們input的那個dimension都是不一樣的,所以每一個cellinput的值呢,都會是不一樣。但是,所有的cell呢,是可以共同一起被運算。
link |
怎麼共同一起被運算呢?我們說,z要乘上zi,對不對?要把zi先通過activation function,把它跟z相乘。
link |
所以我們就把zi通過activation function,跟z相乘。這個乘呢,是這個element wise的product的意思,element wise的相乘。
link |
好,那這個zf也要通過forget gate的activation function,它跟之前存在cell裡面的值相乘。這件事情,它跟原來存在memory cell裡面的值相乘。
link |
接下來呢,你要把這兩個值加起來,也就是把zi跟z相乘的值,加上zf跟ct-1相乘的值,把它們加起來。
link |
好,那output gate呢,co通過activation function,然後呢,把這個output呢,跟相加以後的結果呢,再相乘。最後,就得到最後的output呢,y。
link |
那這個時候相加以後的結果,就是memory裡面存的值,也就是ct。好,那這個process呢,就反覆的繼續下去。
link |
在下一個時間點,input xt-1,然後呢,你把zi跟input gate相乘,你把forget gate跟存在memory裡面的值相乘,然後再把這個值跟這個值加起來,再乘上output gate的值,然後得到下一個時間點的輸出。
link |
那你可以想說,你可能覺得說,這已經很複雜了。如果你自己做投影片的話,顯然是要做非常久的。但是,這個不是LSTM的最終型態。
link |
這個只是一個simplified version。真正的LSTM會怎麼做呢?它會把這個地方的輸出呢,把它接進來。它會把這個hidden layer的輸出呢,把它接進來,當作下一個時間點的input。
link |
也就是說,下一個時間點呢,操控這些gate的值,不是只看那個時間點的input x,還要看前一個時間點的output h。
link |
然後其實還不只這樣,還會加一個東西呢,叫做peephole。這個peephole是什麼呢?這個peephole呢,就是把存在memory cell裡面的值呢,也拉過來。
link |
所以在操控LSTM的四個gate的時候,你是同時考慮了x,同時考慮了h,同時考慮了c。你把這三個vector併在一起,乘上四個不同的transform,得到這四個不同的vector,再去操控LSTM。
link |
那LSTM通常不會只有一層,現在胡亂到要疊個五六層才算,所以它就長得大概是這個樣子。每一個第一次看到這個東西的人,他的反應都是這個樣子。
link |
我記得,大家知道sequence-to-sequence model嗎?那個是一個Google brand的proposal。我有聽過他的talk,他說他第一次看到LSTM的時候,他的想法就跟這個圖像是一樣的。
link |
他說,太複雜了,這應該不work吧。我認識的每一個人,第一次看到LSTM都覺得說,這個應該不work。但是他現在其實還quite standard。當有一個人告訴你說,當有一個人說,我用RN做了什麼事情的時候,你不要去問他說為什麼你不用LSTM,因為其實他就是用LSTM。
link |
因為現在當你在說RN的時候,其實你指的就是用LSTM,所以它其實是比較standard。那其實Keras裡面有支援LSTM,所以就算是剛才講的這麼複雜的東西你沒聽懂,其實就算了。
link |
在Keras裡面就是打LSTM四個字母,然後就結束了。Keras它其實支援三種neural network,一個是LSTM,一個GRU,GRU是LSTM的一個稍微簡化的版本,它只有兩個Gate。
link |
據說少了一個Gate,但是performance跟LSTM差不多,而且你少了三分之一的參數,所以比較不容易overfitting。如果你要用一般的RN,你要用我們這堂課最開始講的那種最簡單的RN的話,你要說是simple RNN才行。
link |
我想我們今天就上到這邊好了,那我們就下課,謝謝。